Имитация непрерывных случайных величин
Если событие Х принимает значения в некоторой области непрерывных величин, то для аналитического моделирования непрерывных событий применяют функцию распределения вероятностей F(Х<х) или плотность распределения вероятностей f(х). Функция распределения вероятностей F(Х<х) определяет вероятность того, что событие (случайная величина) Х меньше либо равна некоторому значению х, т.е.
F(Х<х)=Р{Х<х}.
Вид функции распределения вероятностей приведен на рис. 4.16. Это монотонно возрастающая (неубывающая) функция в диапазоне от нуля до единицы, не имеющая разрывов на интервале значений от +¥до +¥.
Плотность распределения вероятностей f(х), называемая еще дифференцированным распределением вероятностей, определяется по формуле
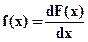 , причем
, причем 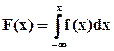 .
.
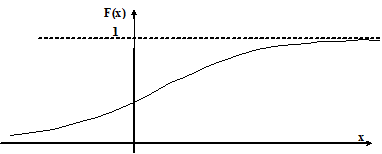
Рис. 4.16
Гипотетический вид плотности распределения вероятностей f(х) приведен на рис. 4.17.

Рис. 4.17
Известны функции и плотности распределения вероятностей, имеющие аналитическое задание, например:
- экспоненциальное распределение
F(х)=1-e-lх;
- распределение Пуассона, определяющее вероятность появления k событий за время t по формуле
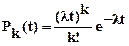 ,
,
где l - математическое ожидание;
- распределение Эрланга r-го порядка, плотность распределения вероятностей для которого определится по формуле
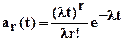 ;
;
- нормальное (гауссово) распределение, плотность распределения вероятностей для которого определится по формуле
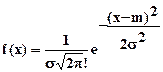 ,
,
где m – математическое ожидание, s - среднеквадратичное отклонение, а также другие распределения.
Задача имитации непрерывных случайных величин, описываемых тем или иным аналитическим распределением вероятностей, основана на преобразованиях равномерно распределенных случайных чисел в числа с заданным законом распределения.
4.5.1. Метод обратной функции. Пусть случайная величина Х определена функцией распределения вероятностей F(х) и плотностью распределения вероятностей f(х).
Если Р - случайная величина, равномерно распределенная на отрезке [0,1], то случайная величина Х может быть получена из решения следующего уравнения:
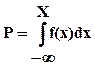 . (4.10)
. (4.10)
На рис. 4.18 приведена иллюстрация метода обратных функций. Как следует из рис. 4.18, выполняется как бы обратное преобразование вероятности Р в случайную величину Х, поэтому данный метод и получил наименование метода обратных функций.

Рис. 4.18
Метод обратных функций позволяет вывести правило генерирования случайной величины, имеющей произвольную функцию распределения вероятностей F(х) и плотность распределения вероятностей f(х):
- вырабатывается датчиком случайной равномерной последовательности случайное число Р;
- случайная величина (случайное число) Х, имеющее распределение f(х), находится из решения уравнения (4.10).
Рассмотрим пример.
Пусть случайная величина Х определена функцией распределения вероятностей F(х)=1-e-lх. Плотность распределения вероятностей f(х)= le-lх.При известной вероятности Р значение случайной величины Х определится по формуле
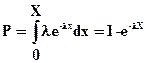 .
.
Таким образом, получили трансцендентное уравнение Р=1-e-lХ с одним неизвестным Х. Решение этого уравнения:
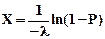 .
.
В силу того, что Р – число, равномерно распределенное на отрезке [0,1], то и 1-Р – число, равномерно распределенное на отрезке [0,1], поэтому случайную величину Х находят по формуле
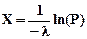 .
.
На рис. 4.19 приведена схема алгоритма метода обратных функций для рассмотренного случая.
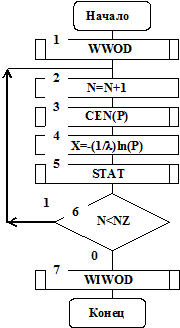
Рис. 4.19
Подпрограммы WWOD и WIWOD предназначены для реализации интерфейса пользователя и инициализации программного модуля. Блоками 2 и 6 организован цикл по переменной N. В подпрограмме GEN генерируется число Р, равномерно распределенное на отрезке [0,1]. В блоке 4 определяется случайная величина Х, определенная функцией распределения вероятностей F(х)=1-e-lх.Подпрограмма STAT предназначена для набора и обработки статистических данных о значениях случайной величины Х.
4.5.2. Метод ступенчатой аппроксимации. Метод обратных функций применим для моделирования непрерывных случайных величин Х в том случае, если существует функция распределения вероятностей F(х), т.е. уравнение 10 имеет аналитическое решение. Однако известны распределения случайных величин, например, нормальное распределение, для которых функция распределения вероятностей F(х) аналитически не определяется.
Для имитации случайных величин Х, определяемых только плотностью распределения вероятностей f(х) применяется метод ступенчатой аппроксимации. Рассмотрим суть этого метода. Зависимость плотности распределения f(х) представляется графически в интервале изменения случайной величины Х от a до b.
Если случайная величина задана на [-¥,+¥], то достаточно ограничиться минимально и максимально возможными числами, воспринимаемыми ЭВМ.
Суть метода ступенчатой аппроксимации показана на рис. 4.20.
Разобьем [a,b] на n интервалов таким образом, чтобы площади под кривой f(х) внутри каждого интервала были равны, как это показано на рис. 4.20, т.е.
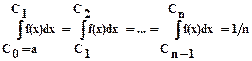 ,
,
где Сi (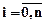 ) - координаты точек разбиения.
) - координаты точек разбиения.
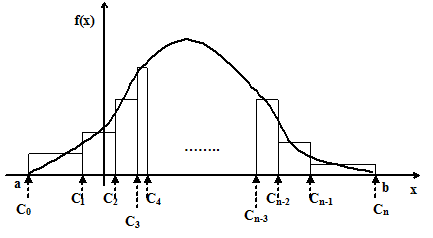 Рис. 4.20
Рис. 4.20
Вероятность того, что случайная величина Хпопадет в любой из интервалов [Сi-1, Сi], 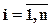 , определится по формуле
, определится по формуле
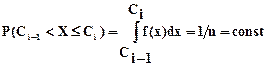 ,
,
т.е. попадание на любой отрезок равновероятно.
Если внутри интервала распределение случайной величины Х также равномерное, то значение случайной величины Х на оси х может быть определено, как Х=Сi-1+h, где h- равномерно распределенная случайная величина на интервале [Сi-1, Сi], представляющая собой расстояние от левого конца (Сi-1) i–го интервала. На рис. 4.21 приведена схема алгоритма генерации случайных величин Х с применением метода ступенчатой аппроксимации.
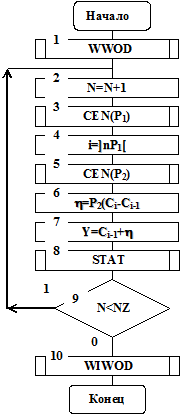
Рис. 4.21
Правило имитации случайных величин Y сводится к следующему:
- получаем от генератора равномерно распределенных чисел случайное число Р1 (см. блок 3);
- из значения числа Р1 находим индекс i=]nР1[ интервала [Сi-1, Сi], где ]nР1[ - целая часть числа nР1, причем ]nР1[<nР1 (см. блок 4);
- получаем от генератора равномерно распределенных чисел случайное число Р2 (см. блок 5);
- из значения числа Р2 находим случайную величину h=Р2(Сi-Сi-1), т.е. значение числа Р2 «приводится» к величине интервала [Сi-1, Сi] (см. блок 6;
- находим случайную величину Х, имеющую заданную плотность распределения вероятностей f(х), по формуле (см. блок 7)
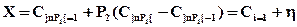 .
.
Подпрограмма STAT предназначена, как и в алгоритме метода обратных функций, для набора и обработки статистических данных о значениях случайной величины Х.
4.5.3. Использование предельных теорем. Для имитации случайной величины Х, имеющей нормальный закон распределения вероятностей, используют свойство сходимости независимых величин к нормальному распределению. Для получения нормального распределения чисел с параметрами: математическое ожидание mХ=0, среднеквадратичное отклонениеsХ=1 удобен искусственный прием, основанный на центральной предельной теореме теории вероятностей. На рис. 4.22 приведен алгоритм получения случайный величин Х с применением свойств центральных предельных теорем.
Согласно центральной предельной теореме при достаточно большом значении n величина Z может считаться нормально распределенной с параметрами
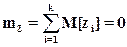 ,
, 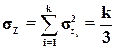 .
.
Для имитации случайной величины Х в качестве исходных чисел возьмем k равномерно распределенных на отрезке [1,-1] случайных чисел, получаемых из интервала [0,1] по правилу zi=2Рi-1 (см. блоки 5,6).
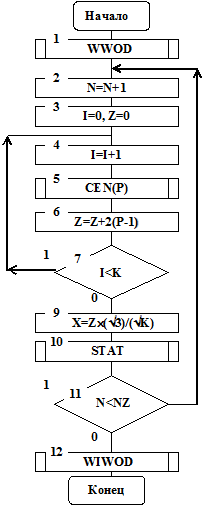
Рис. 4.22
Сформируем величину Z согласно следующей формуле (см. блоки 3 – 7):
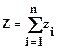 .
.
Выполним нормирование величины Z и получим (см. блок 9)
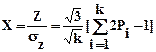 . (4.11)
. (4.11)
Случайная величина Х будет иметь нормальное распределение с mХ=0, sХ=1.
Установлено, что при k>8 формула (4.11) дает хорошие результаты.