ТАБЛИЦЫ И ГРАФИКИ
ТАБЛИЦА ИСХОДНЫХ ДАННЫХ
Обычно в ходе исследования интересующий исследователя признак измеряется не у одного-двух, а у множества объектов (испытуемых). Кроме того, каждый объект характеризуется не одним, а целым рядом признаков, измеренных в разных шкалах. Одни признаки представлены в номинативной шкале и указывают на принадлежность испытуемых к той или иной группе (пол, профессия, контрольная или экспериментальная группа и т. д.). Другие признаки могут быть представлены в порядковой или метрической шкале. Поэтому результаты измерения для дальнейшего анализа чаще всего представляют в виде таблицы исходных данных. Каждая строка такой таблицы обычно соответствует одному объекту, а каждый столбец — одному измеренному признаку. Таким образом, исходной формой представления данных является таблица типа «объект — признак». В ходе дальнейшего анализа каждый признак выступает в качестве переменной величины, или просто — переменной, значения которой меняются от объекта к объекту.
ПРИМЕР_______________________________________________________________
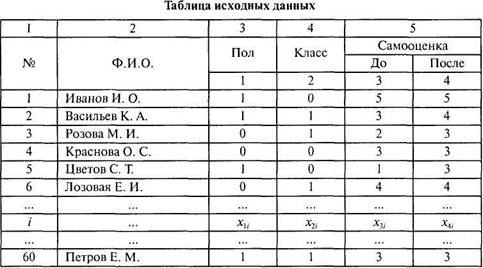
Предположим, психолога интересует социальная сплоченность двух параллельных классов, различие в этом отношении мальчиков и девочек и эффективность проведенного в одном из этих классов социально-психологического тренинга. Для измерения социальной сплоченности исследователь задавал каждому ученику до и после тренинга один и тот же вопрос: «Как часто твое мнение совпадает с мнением твоих одноклассников?». Для ответа ученикам предлагалось выбрать один из пяти вариантов: 1 — никогда, 2 — редко, 3 — затрудняюсь ответить, 4 — часто, 5 — всегда. Исходные данные исследования представлены в табл. 3.1. Общая численность всех испытуемых N=60. Численность класса, с которым проводился тренинг, TV] = 30; численность другого класса — N2~ 30. Первые два столбца таблицы— порядковый номер испытуемого (№) иФ. И. О. Далее следуют четыре столбца, соответствующие четырем интересующим исследователя признакам: хи — пол (номинативный), Хц— класс (номинативный),
|
| ГЛАВА 3. ТАБЛИЦЫ И ГРАФИКИ |
| Та блица 3.1 |
х3,-— самооценка до тренинга (порядковый),
х4, — самооценка после тренинга (порядковый),
где / — текущий номер испытуемого (меняется от 1 до N=60).
Обратите внимание на то, что нумерация испытуемых в таблице исходных данных (табл. 3.1) — сквозная, вне зависимости от принадлежности к той или иной группе. То, к какой группе принадлежит испытуемый, определяется значением соответствующей номинативной переменной (пол, класс).
ТАБЛИЦЫ И ГРАФИКИ РАСПРЕДЕЛЕНИЯ ЧАСТОТ
Как правило, анализ данных начинается с изучения того, как часто встречаются те или иные значения интересующего исследователя признака (переменной) в имеющемся множестве наблюдений. Для этого строятся таблицы и графики распределения частот. Нередко они являются основой для получения ценных содержательных выводов исследования.
Если признак принимает всего лишь несколько возможных значений (до 10-15), то таблица распределения частот показывает частоту встречаемости каждого значения признака. Если указывается, сколько раз встречается каждое значение признака, то это — таблица абсолютных частот распределения, если указывается доля наблюдений, приходящихся на то или иное значение признака, то говорят об относительных частотах распределения.
ЧАСТЬ I. ОСНОВЫ ИЗМЕРЕНИЯ И КОЛИЧЕСТВЕННОГО ОПИСАНИЯ ДАННЫХ
ПРИМЕР
 Предположим, исследователя в нашем примере (табл. 3.1) интересует, как распределяются ответы всех учеников до проведения тренинга. Для этого он подсчитает частоту встречаемости каждого из ответов и составит таблицу распределения частот (табл. 3.2). Таблица показывает, что чаще встречаются средние значения выраженности признака и реже — крайние значения.
Предположим, исследователя в нашем примере (табл. 3.1) интересует, как распределяются ответы всех учеников до проведения тренинга. Для этого он подсчитает частоту встречаемости каждого из ответов и составит таблицу распределения частот (табл. 3.2). Таблица показывает, что чаще встречаются средние значения выраженности признака и реже — крайние значения.
Таб л и ца 3.2 Таблица распределения частот

Абсолютная и относительная частоты связаны соотношением:
(3.1)
где fa — абсолютная частота некоторого значения признака, N — число наблюдений, /0 — относительная частота этого значения признака. Очевидно, что сумма всех абсолютных частот равна числу наблюдений — М, а сумма всех относительных частот равна 1. Нередко относительная частота применяется для оценки вероятности встречаемости значения.
Во многих случаях признак может принимать множество различных значений, например, если мы измеряем время решения тестовой задачи. В этом случае о распределении признака позволяет судить таблица сгруппированных частот, в которых частоты группируются по разрядам или интервалам значений признака.
ПРИМЕР_______________________________________________________________
Предположим, в группе испытуемых численностью 40 человек измерено время решения тестовой задачи. Максимальное время составило 67 секунд, минимальное — 32 секунды. Построение таблицы распределения частот в этом случае производится поэтапно. Построение таблицы сгруппированных частот.
1. Определение размаха: 67-32 = 35.
2. Выбор желаемого числа разрядов и интервала разрядов. Определяется произволь
но. Обычное число разрядов — от 6 до 15. Удобным интервалом разрядов в на
шем случае может быть 5. 35 делим на 5, получаем число разрядов — 7. Учиты
вая, что начинать лучше с 30 или с 31 и заканчивать на 69 или 70, уточняем размах
(70-30 = 40) и число разрядов (40/5 = 8).
ГЛАСА 3. ТАБЛИЦЫ И ГРАФИКИ
3. Определение границ разрядов. Если мы начнем с 30, то первый разряд будете 30
до 34, второй — с 35 до 49 и т. д., до восьмого — с 65 до 69. Границы соседних
разрядов не должны совпадать!
4. Подсчет частот встречаемости значений признака для каждого интервала.
Табл. 3.3 содержит результат подсчета сгруппированных таким образом частот по разрядам (интервалам) значений признака — времени решения тестовой задачи.
Таблица 3.3