рефераты конспекты курсовые дипломные лекции шпоры

- Раздел Психология
- /
- Математические методы психологического исследования. Анализ и интерпретация данных. Учебное пособие
Реферат Курсовая Конспект
Математические методы психологического исследования. Анализ и интерпретация данных. Учебное пособие
Математические методы психологического исследования. Анализ и интерпретация данных. Учебное пособие - раздел Психология, Ббк 88.36 Н31 Рецензенты: В.м. А/иахвердов, Доктор Психологич...
ББК 88.36 Н31
Рецензенты: В.М. А/иахвердов, доктор психологических наук, профессор кафедры
общей психологии СПбГУ;
В. М. Буре, кандидат физико-математических наук, доцент факультета приклаnдной математики — процессов управления СПбГУ
Рекомендовано
Ученым советом факультета психологии СПбГУ в качестве учебного пособия
Наследов А. Д.
Н31 Математические методы психологического исследования. Анализ и интерпретация данных. Учебное пособие. — СПб.: Речь, 2004. — 392 с.
ISBN 5-9268-0275-7
В данной книге многообразие математико-статистических методов представлено is виде упорядоченной, логически и иерархически взаимосвязанной системы с ориентацией на читателя, не имеющего основательной математической подготовки. Описаны основы применения этих методов, алгоритмы их выбора в зависимости от исследовательской ситуации — от исходных данных и задач исследования. При изложении методов основное внимание уделяется границам их применения, возможным альтернативам, особенностям интерпретации результатов. Применение каждого метода сопровождается простыми примерами и пошаговыми алгоритмами вычислений — как «вручную», так и на компьютере.
Книга адресована студентам психологических и педагогических специальностей, но может быть полезна и широкому кругу исследователей как справочник и руководство по обработке данных.
ББК 88.36
ISBN 5-9268-0275-7
© А. Д. Наследов, 2004
© М. Г. Филиппова, рисунки., 2004
© Издательство «Речь», 2004
© П. В. Борозсиец, обложка, 2004
КРАТКОЕ СОДЕРЖАНИЕ
Часть I
ОСНОВЫ ИЗМЕРЕНИЯ И КОЛИЧЕСТВЕННОГО ОПИСАНИЯ ДАННЫХ
Глава 2. Измерения и шкалы.................................................................. ...23 Глава 3. Таблицы и… Глава 4. Первичные описательные статистики......................................... 40Часть II
МЕТОДЫ СТАТИСТИЧЕСКОГО ВЫВОДА: ПРОВЕРКА ГИПОТЕЗ
Глава 8. Выбор метода статистического вывода.................................... 111 Глава 9. Анализ номинативных… Глава 10. Корреляционный анализ........................................................... 147Часть III МНОГОМЕРНЫЕ МЕТОДЫ И МОДЕЛИ
Глава 15. Множественный регрессионный анализ.................................. 240 Глава 16. Факторный… Глава 17. Дискриминантный анализ......................................................... 282ОГЛАВЛЕНИЕ
ПРЕДИСЛОВИЕ.............................
ПСИХОЛОГИЯ И МАТЕМАТИКА
Часть I
ОСНОВЫ ИЗМЕРЕНИЯ И КОЛИЧЕСТВЕННОГО ОПИСАНИЯ ДАННЫХ
Глава 1. ГЕНЕРАЛЬНАЯ СОВОКУПНОСТЬ И ВЫБОРКА..................... 1<
Глава 2. ИЗМЕРЕНИЯ И ШКАЛЫ............................................................ Г:
Что такое измерение.............................................................................. 2:
Измерительные шкалы.......................................................................... 24
Как определить, в какой шкале измерено явление .............................. 27
Задачи и упражнения............................................................................. 2S
Глава 3. ТАБЛИЦЫ И ГРАФИКИ............................................................. ЗС
Таблица исходных данных.................................................................... 30
Таблицы и графики распределения частот........................................... 31
Применение таблиц и графиков распределения частот....................... 35
Таблицы сопряженности номинативных признаков............................. 36
Задачи и упражнения............................................................................. 37
Обработка на компьютере..................................................................... 38
Глава 4. ПЕРВИЧНЫЕ ОПИСАТЕЛЬНЫЕ СТАТИСТИКИ...................... 40
Меры центральной тенденции ............................................................. 40
Выбор меры центральной тенденции.................................................... 42
Квантили распределения....................................................................... 43
Меры изменчивости............................................................................... 44
Задачи и упражнения............................................................................. 47
Обработка на компьютере..................................................................... 48
Глава 5. НОРМАЛЬНЫЙ ЗАКОН РАСПРЕДЕЛЕНИЯ И ЕГО
ПРИМЕНЕНИЕ.................................................................................... 49
Нормальное распределение как стандарт............................................. 51
ОГЛАВЛЕНИЕ
Разработка тестовых шкал..................................................................... 54
Проверка нормальности распределения............................................... 59
Задачи и упражнения............................................................................. 62
Обработка на компьютере..................................................................... 62
Глава 6. КОЭФФИЦИЕНТЫ КОРРЕЛЯЦИИ............................................ 64
Понятие корреляции.............................................................................. 65
Коэффициент корреляции г-Пирсона.................................................... 67
Корреляция, регрессия и коэффициент детерминации........................ 72
Частная корреляция............................................................................... 75
Ранговые корреляции............................................................................. 77
Коэффициент корреляции /•-Спирмена............................................ 77
Коэффициент корреляции /-Кендалла.............................................. 78
Проблема связанных (одинаковых) рангов...................................... 80
Корреляция бинарных данных.............................................................. 82
Величина корреляции и сила связи....................................................... 84
Какой коэффициент корреляции выбрать............................................. 88
Обработка на компьютере..................................................................... 90
Часть II
МЕТОДЫ СТАТИСТИЧЕСКОГО ВЫВОДА: ПРОВЕРКА ГИПОТЕЗ
Глава 7. ВВЕДЕНИЕ В ПРОБЛЕМУ СТАТИСТИЧЕСКОГО ВЫВОДА.. 93
Гипотезы научные и статистические.................................................... 93
Идея проверки статистической гипотезы............................................. 96
Уровень статистической значимости.................................................... 98
Статистический критерий и число степеней свободы......................... 99
Проверка гипотез с помощью статистических критериев ................ 100
Статистическое решение и вероятность ошибки............................... 103
Направленные и ненаправленные альтернативы................................ 106
Содержательная интерпретация статистического решения.............. 108
Глава 8. ВЫБОР МЕТОДА СТАТИСТИЧЕСКОГО ВЫВОДА................ 111
Классификация методов статистического вывода............................. 112
Методы корреляционного анализа...................................................... 114
Методы анализа номинативных данных............................................. 114
Методы сравнения выборок по уровню выраженности признака...... 117
Глава 9. АНАЛИЗ НОМИНАТИВНЫХ ДАННЫХ................................. 123
Анализ классификации: сравнение эмпирического и теоретического
распределений................................................................................. 125
Две градации.................................................................................... 125
Обработка на компьютере: биномиальный критерий.................... 128
Более двух градаций ...................................................................... 129
МАТЕМАТИЧЕСКИЕ МЕТОДЫ ПСИХОЛОГИЧЕСКОГО ИССЛЕДОВАНИЯ
Обработка на компьютере: критерий согласия у}.......................... 131
Анализ таблиц сопряженности............................................................ 132
Число градаций больше двух......................................................... 133
Таблицы сопряженности 2x2........................................................... 135
Обработка на компьютере: таблицы сопряженности.................... 141
Анализ последовательности: критерий серий..................................... 142
Обработка на компьютере: анализ последовательности .............. 145
Глава 10. КОРРЕЛЯЦИОННЫЙ АНАЛИЗ.............................................. 147
Корреляция метрических переменных................................................ 148
Частная корреляция.............................................................................. 150
Проверка гипотез о различии корреляций.......................................... 151
Сравнение корреляций для независимых выборок........................ 151
Сравнение корреляций для зависимых выборок............................ 152
Корреляция ранговых переменных..................................................... 153
Анализ корреляционных матриц......................................................... 156
Обработка на компьютере................................................................... 160
Глава 11. ПАРАМЕТРИЧЕСКИЕ МЕТОДЫ СРАВНЕНИЯ ДВУХ
ВЫБОРОК............................................................................................. 162
Сравнение дисперсий........................................................................... 162
Критерий /-Стьюдента для одной выборки......................................... 164
Критерий /-Стьюдента для независимых выборок............................. 165
Критерий /-Стьюдента для зависимых выборок................................. 167
Обработка на компьютере................................................................... 169
Глава 12. НЕПАРАМЕТРИЧЕСКИЕ МЕТОДЫ СРАВНЕНИЯ
ВЫБОРОК............................................................................................. 172
Общие замечания ................................................................................ 172
Сравнение двух независимых выборок............................................... 173
Обработка на компьютере: критерий [/-Манна-Уитни.................. 175
Сравнение двух зависимых выборок................................................... 176
Обработка на компьютере: критерий Г-Вилкоксона..................... 178
Сравнение более двух независимых выборок..................................... 179
Обработка на компьютере: критерий //-Краскала-Уоллеса........... 181
Сравнение более двух зависимых выборок........................................ 182
Обработка на компьютере: критерий %2-Фридмана...................... 184
Глава 13. ДИСПЕРСИОННЫЙ АНАЛИЗ (ANOVA)............................... 185
Назначение и общие понятия ANOVA................................................ 185
Однофакторный ANOVA..................................................................... 189
Обработка на компьютере............................................................... 195
Множественные сравнения в ANOVA................................................. 197
Обработка на компьютере............................................................... 199
ОГЛАВЛЕНИЕ
Многофакторный ANOVA................................................................... 202
Обработка на компьютере............................................................... 212
AN OVA с повторными измерениями................................................. 214
Обработка на компьютере............................................................... 222
Многомерный ANOVA (MANOVA).................................................... 226
Обработка на компьютере............................................................... 228
Часть III МНОГОМЕРНЫЕ МЕТОДЫ И МОДЕЛИ
Глава 14. НАЗНАЧЕНИЕ И КЛАССИФИКАЦИЯ МНОГОМЕРНЫХ
МЕТОДОВ............................................................................................. 235
Глава 15. МНОЖЕСТВЕННЫЙ РЕГРЕССИОННЫЙ АНАЛИЗ.............. 240
Назначение........................................................................................... 240
Математико-статистические идеи метода.......................................... 242
Исходные данные, процедура и результаты....................................... 245
Обработка на компьютере................................................................... 247
Глава 16. ФАКТОРНЫЙ АНАЛИЗ........................................................... 251
Назначение............................................................................................ 251
Математико-статистические идеи и проблемы метода..................... 254
Анализ главных компонент и факторный анализ........................... 254
Проблема числа факторов.............................................................. 259
Проблема общности........................................................................ 260
Методы факторного анализа........................................................... 261
Проблема вращения и интерпретации............................................ 263
Проблема опенки значений факторов............................................ 267
Последовательность факторного анализа........................... ,.............. 268
Пример.................................................................................................. 273
Обработка на компьютере................................................................... 277
Глава 17. ДИСКРИМИНАНТНЫЙ АНАЛИЗ.......................................... 282
Назначение........................................................................................... 282
Математико-статистические идеи метода.......................................... 284
Исходные данные и основные результаты......................................... 289
Обработка на компьютере................................................................... 29!
Глава 18. МНОГОМЕРНОЕ ШКАЛИРОВАНИЕ..................................... 299
Назначение........................................................................................... 299
Меры различия..................................................................................... 306
Неметрическая модель........................................................................ 311
Обработка на компьютере............................................................... 314
Модель индивидуальных различий..................................................... 317
Обработка на компьютере............................................................... 321
МАТЕМАТИЧЕСКИЕ МЕТОДЫ ПСИХОЛОГИЧЕСКОГО ИССЛЕДОВАНИЯ
Модель субъективных предпочтений................................................. 324
Обработка на компьютере............................................................... 326
Глава 19. КЛАСТЕРНЫЙ АНАЛИЗ......................................................... 329
Назначение........................................................................................... 329
Методы кластерного анализа.............................................................. 333
Обработка на компьютере: кластерный анализ объектов............. 336
Кластерный и факторный анализ........................................................ 338
Обработка на компьютере: кластерный анализ корреляций......... 340
Кластерный анализ результатов социометрии................................... 342
Обработка на компьютере: кластерный анализ различий............. 346
Кластерный анализ и многомерное шкалирование............................ 347
Приложения ОСНОВНЫЕ СТАТИСТИЧЕСКИЕ ТАБЛИЦЫ
Приложение 1. Стандартные нормальные вероятности......................... 353
Приложение 2. Критические значения критерия /-Стыодента............... 355
Приложение 3. Критические значения критерия /-"-Фишера для проверки
направленных альтернатив.................................................................. 357
Приложение 4. Критические значения критерия у} ............................... 359
Приложение 5. Критические значения для числа серий......................... 361
Приложение 6. Критические значения коэффициентов корреляции
/•-Пирсона (г-Спирмена)...................................................................... 363
Приложение 7. Значения Z-преобразования Фишера для коэффициентов
корреляции .......................................................................................... 365
Приложение 8. Критические значения критерия /^-Фишера
для проверки ненаправленных альтернатив ...................................... 366
Приложение 9. Критические значения критерия (/-Манна-Уитни......... 368
Приложение 10. Критические значения критерия 7-Вилкоксона........... 370
Приложение 11. Критические значения критерия G знаков.................. 371
Приложение 12. Критические значения критерия //-Краскала-Уоллеса 372
Приложение 13. Критические значения критерия х2-Фридмана............ 375
Англо-русский терминологический Словарь.......................................... 377
Предметный указатель............................................................................. 382
Дополнительная литература..................................................................... 389
ПСИХОЛОГИЯ И МАТЕМАТИКА
Более 200 лет назад великий И. Кант со свойственной ему убедительностью обосновывал несостоятельность психологии как науки исходя из того, что психические явления не поддаются измерению, а следовательно, к ним не применимы математические методы. Его соотечественник И. Гербарт противопоставил позиции И. Канта свою точку зрения в книге с названием «Психология как наука, заново обоснованная на опыте, метафизике и математике» (1824-1825). В ней он выражает свое мнение о связи психологии и математики: «Всякая теория, которая желает быть согласованной с опытом, прежде всего должна быть продолжена до тех пор, пока не примет количественных определений, которые являются в опыте или лежат в его основании. Не достигнув этого пункта, она висит в воздухе, подвергаясь всякому ветру сомнений и будучи неспособной вступить в связь с другими уже окрепшими воззрениями»'. Идеи И. Гер-барта к концу XIX столетия воплощаются в жизнь отцами-основателями экспериментальной психологии. С тех пор возможность применения математических методов в психологии перестает вызывать сомнения. Но вопрос о_не-^ обходимости их применения до сих пор вызывает дискуссии. Между тем проблема может быть решена признанием того, что психология — это и наука и искусство. Действительно, искусству практического консультирования или терапии вряд ли необходимо математическое обеспечение. Другое дело область познания, в том числе — того, что лежит в основе различных практических приемов. И здесь уже не достаточно обыденного понимания на уровне здравого смысла, необходим особый инструмент — научный метод, опирающийся на «количественные определения». Почему научное познание не довольствуется здравым смыслом, зачем необходимы математические методы?
Значение математических методов можно понять, сопоставляя обыденное и научное познание. На уровне обыденного познания действительности основным инструментом является здравый смысл. Результат познания — наше мнение (частное, субъективное). Мнение, или точка зрения по поводу той или иной проблемы, необходимо нам для прогноза или интерпретации грядущих реальных событий. Если прогнозы или интерпретации состоятельны, мы укрепляемся в своем мнении, если нет — мы вновь обращаемся к здравому смыслу и корректируем свое мнение, и т. д. Таким образом, продукт обыденного познания — мнение — прежде всего характеризуется как частное, субъек-
 1 Цитируется по кн.: Корнилов К. Н. Учение о реакциях человека с психологической точки прения («Реактология»). М., 1923. С. 3.
1 Цитируется по кн.: Корнилов К. Н. Учение о реакциях человека с психологической точки прения («Реактология»). М., 1923. С. 3.
МАТЕМАТИЧЕСКИЕ МЕТОДЫ ПСИХОЛОГИЧЕСКОГО ИССЛЕДОВАНИЯ
тивное. И все мы хорошо знаем, насколько тяжело бывает переубедить другого человека или отстоять свое мнение. Произведение искусства — это тоже продукт обыденного познания, мнение творца, облеченное в специфическую форму. Эстетические переживания способствуют восприятию и принятию нами авторского мнения. Таким образом, обыденное познание, его продукт — мнение, его инструмент — здравый смысл лежат в основе наших представлений о действительности. А само понятие «обыденное» приобретает смысл в противовес альтернативному — «научному» познанию.
Научное познание по своей конечной цели — совершенству прогнозов и интерпретаций реальных событий — принципиально не отличается от обыденного познания. Более того, научное познание не отменяет и не заменяет обыденного, но добавляет кое-что для совершенствования его результатов — знаний и прогнозов. Наука стремится выйти за пределы частного мнения, сделать знания общезначимыми. В стремлении к общезначимости ученый обосновывает свое мнение эмпирически, при помощи принятых в науке процедур, возводя свое мнение в ранг научной теории. При этом предполагается (и практика это доказывает), что научное познание гарантирует нам более совершенные предсказания и интерпретации действительности.
Научное познание добавляет к инструменту обыденного познания — здравому смыслу — ряд дополнительных процедур, обеспечивая не только убедительность, но и объективность получаемых знаний. Рассмотрим их подробнее. Первый шаг любого (научного) исследования — выражение сомнения в истинности мнения, формулировка мнения как гипотезы — утверждения, допускающего проверку на фактах. Например, я могу поставить под сомнение свою точку зрения о том, что женщины более искусны в общении, чем мужчины. Но чтобы сделать гипотезу доступной проверке при помощи эмпирики, необходимо представить ее в форме математической модели, согласованной со способом регистрации наблюдений. Таким образом, гипотеза содержит указание на математическую модель, форма которой уточняется в соответствии с тем, как будет измерено то, что нас интересует. Моя содержательная гипотеза о большей искусности женщин в общении может быть представлена в форме математической модели: М„ <МЖ (мужчины в среднем менее искусны в общении, чем женщины) или/м </ж (среди мужчин искусные в общении встречаются реже, чем среди женщин). В первом случае предполагается, что я могу вычислить среднюю «искусность в общении» для женщин и для мужчин по результатам ее количественного измерения при помощи некоторой специальной шкалы. Во втором случае достаточно определить частоту встречаемости «искусных в общении» среди мужчин и женщин.
Итак, научное познание начинается с нуждающегося в эмпирической проверке утверждения — гипотезы. Проверка гипотезы предполагает измерение интересующего исследователя явления и обобщение результатов измерения в виде, позволяющем сделать вывод в отношении гипотезы. Измерение и описание предполагает применение различных, хоть и взаимосвязанных, математических моделей и соответствующих им процедур. В процессе измерения мы предстаь-.яем реальные события, явления, свойства в виде чисел, в соответствии
МЕТОДОЛОГИЧЕСКОЕ ВСТУПЛЕНИЕ
с принятой математической моделью измерения. Например, приписываем испытуемому число, обозначающее его пол (1 — мужской, 2 — женский), или ранг, соответствующий успешности выполнения задания (1 — лучше всех, 2 — второе место, и т. д.). Затем множество подобных результатов измерения мы должны представить в виде, доступном интерпретации с точки зрения выдвинутой гипотезы. Для этого используются математические модели описания для обобщения результатов измерения: менее сложные (частоты, средние значения и др.) или более сложные (корреляционный или факторный анализ и др.).
Помимо описания и измерения, существует и третье направление использования математики в психологии — статистическая проверка гипотез. Последнее направление тесно связано с общенаучными канонами экспериментального метода, основанными на статистическом выводе. Отдавая дань истории, отметим, что одним из первых примеров испытания статистической гипотезы была работа Дж. Арбутнота «Довод в пользу божественного провидения, выведенный из постоянной регулярности, наблюдаемой в рождении обоих полов» (1710—1712 гг.)1. Основываясь на том факте, что в течение 82 лет подряд мальчиков каждый год рождалось больше, чем девочек, автор показал, что эти данные опровергают гипотезу о равновероятном рождении мужчин и женщин. Если вероятность рождения мальчика точно равна 0,5, то вероятность того, что на протяжении 82 лет подряд мальчиков будет рождаться больше, чем девочек, равна (У2)82, т. е. она очень мала. По мнению Арбутнота, данный факт — результат вмешательства божественного Провидения, поскольку жизнь муж-чипы находится в большей опасности, чем жизнь женщины.
Общая логика статистической проверки гипотез, или определения статистической достоверности эмпирического результата, сохранилась в общих чертах и до настоящего времени. Возвращаясь к проверке моего мнения о женской искусности в общении, предположим, что я измерил ее при помощи 10-балльной шкалы у 32 женщин и 28 мужчин. Среднее значение для мужчин оказалось равным Л/м = 4,6, а для женщин Мж = 5,1. Здравый смысл мне подсказывает, что факт подтверждает мое мнение. Однако тут же возникает сомнение: достаточно ли столь малого различия в средних значениях, чтобы утверждать, что вообще все женщины в среднем более искусны в общении, чем все мужчины? Какова вероятность, что это все-таки не так? Для ответа на этот вопрос мне и необходимо обратиться к моделям статистического вывода. Если различия статистически значимы, то мое мнение приобретает статус научно обоснованного утверждения.
Таким образом, научное познание, в дополнение к здравому смыслу (но не вместе него!), обязательно предполагает применение математических методов, которые мы представили в виде трех классов моделей: измерения, описания и статистического вывода. Соотношение этих моделей в структуре познания схематично представлено на рис. 1.
Научное познание начинается с формулировки гипотезы — следствия теории или частного мнения по поводу некоторого аспекта реальности. Гипотеза
 Кендалл М., Стьюарт А. Статистические выводы и связи. М., 1973. С. 681.
Кендалл М., Стьюарт А. Статистические выводы и связи. М., 1973. С. 681.

Научное познание Рис. 1. Соотношение обыденного и научного познания
формулируется так, чтобы ее можно было проверить по результатам измерения, то есть в форме описательной математической модели. Описательная математическая модель согласуется с доступной измерительной моделью. Далее модель измерения применяется к интересующим нас аспектам действительности для регистрации результатов наблюдения (как правило — в числовой форме). Результаты измерения обобщаются при помощи описательной математической модели — для представления результатов измерения в доступном для интерпретации виде. Мы обращаемся к здравому смыслу и интерпретируем результаты применения описательных математических моделей. Однако чаще мы этим не ограничиваемся и обосновываем достоверность результатов при помощи соответствующей модели статистического вывода.
Изложенная логика аргументации характерна для науки в целом, в любых ее отраслях, в том числе для психологии. И гуманитарная специфика психологии вовсе не означает принципиального отличия научного метода психологии от методов других наук. Однако такая специфика предмета накладывает свой отпечаток на особенности применения математических методов. Это проявляется, в частности, в применяемых моделях измерения, в том, каким образом мы фиксируем результаты наблюдения непосредственно не видимого и не измеримого (способностей, тревожности и т. д.). Специфика измерительных моделей сказывается на применяемых описательных моделях, а те, в свою очередь — и на моделях статистического вывода.
Иногда можно слышать утверждения, что научный подход с применением математических методов необходим для академических научных исследований, а в практической работе вполне достаточно здравого смысла. Да, практическая деятельность психолога — это прежде всего искусство применения практических методов. Но здравого смысла недостаточно для профессиональной работы. Профессионал отличается тем, что может обосновать свою точку зрения, скажем, проверить эффективность того или иного практического метода или состоятельность организационного решения. При этом он будет опираться на научно обоснованные аргументы, а не только на собственное субъективное мнение.
Глава 1
ГЕНЕРАЛЬНАЯ СОВОКУПНОСТЬ И ВЫБОРКА
ПРИМЕР______________________________________________________________ Исследователь может предположить, что женщины в среднем более тревожны, чем… Для проверки подобных предположений на фактах необходимо измерить соответствующие свойства у их носителей. Но…ИЗМЕРЕНИЯ И ШКАЛЫ
Любое эмпирическое научное исследование начинается с того, что исследователь фиксирует выраженность интересующего его свойства (или свойств) у… Измерение в терминах производимых исследователем операций— это приписывание… В обыденном сознании, как правило, нет необходимости разделять свойства вещей и их признаки: такие свойства…ПРИМЕР
 Мы можем разделить всех наших испытуемых на две группы по сообразительности: сообразительные и не очень. И далее приписать каждому испытуемому символ (например, 1 и 0) в зависимости от его принадлежности к той или другой группе. А можем упорядочить всех испытуемых по степени выраженности сообразительности, приписывая каждому его ранг, от самого сообразительного (1 ранг), самого сообразительного из оставшихся (2 ранг) и т. д. до последнего испытуемого. В каком из этих двух случаев измеренный признак будет точнее отражать различия между испытуемыми по измеряемому свойству, догадаться нетрудно.
Мы можем разделить всех наших испытуемых на две группы по сообразительности: сообразительные и не очень. И далее приписать каждому испытуемому символ (например, 1 и 0) в зависимости от его принадлежности к той или другой группе. А можем упорядочить всех испытуемых по степени выраженности сообразительности, приписывая каждому его ранг, от самого сообразительного (1 ранг), самого сообразительного из оставшихся (2 ранг) и т. д. до последнего испытуемого. В каком из этих двух случаев измеренный признак будет точнее отражать различия между испытуемыми по измеряемому свойству, догадаться нетрудно.
ЧАСТЬ I. ОСНОВЫ ИЗМЕРЕНИЯ И КОЛИЧЕСТВЕННОГО ОПИСАНИЯ ДАННЫХ
В зависимости от того, какая операция лежит в основе измерения признака, выделяют так называемые измерительные шкалы. Они еще называются шкалами С. Стивенса, по имени ученого-психолога, который их предложил. Эти шкалы устанавливают определенные соотношения между свойствами чисел и измеряемым свойством объектов. Шкалы разделяют на метрические (если есть или может быть установлена единица измерения) и неметрические (если единицы измерения не могут быть установлены).
ИЗМЕРИТЕЛЬНЫЕ ШКАЛЫ
Номинативная шкала (неметрическая),или шкала наименований (номинальное измерение). В ее основе лежит процедура, обычно не ассоциируемая с измерением. Пользуясь определенным правилом, объекты группируются по различным классам так, чтобы внутри класса они были идентичны по измеряемому свойству. Каждому классу дается наименование и обозначение, обычно числовое. Затем каждому объекту присваивается соответствующее обозначение.
ПРИМЕРЫ______________________________________________________
Примеры номинативных признаков: «пол» (1 — мужской, 0 — женский), «национальность» (1 — русский, 2 — белорус, 3 — украинец), «предпочтение домашних животных» (1 — собаки, 2 — кошки, 3 — крысы, 0 — никакие) и т. д. В последнем случае если одному испытуемому присвоена 1, а другому 2, то это обозначает только то, что у них разные предпочтения: у первого — собаки, у второго — кошки. Из того, что 1 < 2, нельзя делать вывод, что у второго предпочтение выражено больше, чем у первого, и т. д.
Заметим, что в этом случае мы учитываем только одно свойство чисел — то, что это разные символы. Остальные свойства чисел не учитываются. Привычные операции с числами — упорядочивание, сложение-вычитание, деление — при измерении в номинативной шкале теряют смысл. При сравнении объектов мы можем делать вывод только о том, принадлежат они к одному или разным классам, тождественны или нет по измеренному свойству. Несмотря на такие ограничения, номинативные шкалы широко используются в психологии, и к ним применимы специальные процедуры обработки и анализа данных.
Ранговая,или порядковая шкала (неметрическая)(как результат ранжирования). Как следует из названия, измерение в этой шкале предполагает приписывание объектам чисел в зависимости от степени выраженности измеряемого свойства.
ПРИМЕР
 Мы можем ранжировать всех испытуемых по интересующему нас свойству на основе экспертной оценки или по результатам выполнения некоторого задания и при-
Мы можем ранжировать всех испытуемых по интересующему нас свойству на основе экспертной оценки или по результатам выполнения некоторого задания и при-
ГЛАВА 2. ИЗМЕРЕНИЯ И ШКАЛЫ
писать каждому испытуемому его ранг. Или предложить испытуемым самим определить выраженность изучаемого свойства, пользуясь предложенной шкалой (5-, 7- или 10-балльной).
Существует множество способов получения измерения в порядковой шкале. Но суть остается общей: при сравнении испытуемых друг с другом мы можем сказать, больше или меньше выражено свойство, но не можем сказать, насколько больше или насколько меньше оно выражено, а уж тем более — во сколько раз больше или меньше. При измерении в ранговой шкале, таким образом, из всех свойств чисел учитывается то, что они разные, и то, что одно число больше, чем другое.
ПРИМЕР_______________________________________________________
Четверым бегунам присвоены ранги в соответствии с тем, кто раньше достиг «финиша» (ранг 1 — самый быстрый):
| Бегун | Ранг |
| А | |
| В | |
| С | |
| D |
Основываясь только на этих данных, мы можем судить о том, кто раньше прибежал, а кто позже. Но мы не можем судить, насколько каждый из них пробежал быстрее или медленнее другого. Глядя на эти ранги, можно было бы предположить, что бегуны А и В различаются меньше, чем бегуны В и D, так как 2-1 = 1, а 4-2 = 2. Однако такой вывод — следствие «пленяющей магии чисел»: бегун А мог быть тренированным спортсменом, пробежавшим дистанцию в 2 раза быстрее, чем бегуны В, С и D — «увальни», пришедшие к «финишу» с минимальными различиями во времени.
При ранжировании «вручную»', а не при помощи компьютера, следует иметь в виду два обстоятельства:
1. Установите для себя и запомните порядок ранжирования. Вы можете
ранжировать испытуемых по их «месту в группе»: ранг 1 присваивается тому,
у которого наименьшая выраженность признака, и далее — увеличение ранга
по мере увеличения уровня признака. Или можно ранг 1 присваивать тому, у
которого 1-е место по выраженности данного признака (например, «самый
быстрый»). Строгих правил выбора здесь нет, но важно помнить, в каком на
правлении производилось ранжирование.
2. Соблюдайте правило ранжирования для связанных рангов, когда двое
или более испытуемых имеют одинаковую выраженность измеряемого свой
ства. В этом случае таким испытуемым присваивается один и тот же, средний
ранг. Например, если вы ранжируете испытуемых по «месту в группе» и двое
имеют одинаковые самые высокие исходные оценки, то обоим присваивает
ся средний ранг 1,5: (1+2)/2= 1,5. Следующему за этой парой испытуемому
присваивается ранг 3, и т. д. Это правило основано на соглашении соблюде-
ЧАСТЬ I. ОСНОВЫ ИЗМЕРЕНИЯ И КОЛИЧЕСТВЕННОГО ОПИСАНИЯ ДАННЫХ
ния одинаковой суммы рангов для связанных и несвязанных рангов. В соответствии с этим правилом сумма всех присвоенных рангов для группы численностью N должна равняться N(N+)/2, вне зависимости от наличия или отсутствия связей в рангах.
Интервальная шкала (метрическая).Это такое измерение, при котором числа отражают не только различия между объектами в уровне выраженности свойства (характеристика порядковой шкалы), но и то, насколько больше или меньше выражено свойство. Равным разностям между числами в этой шкале соответствуют равные разности в уровне выраженности измеренного свойства. Иначе говоря, измерение в этой шкале предполагает возможность применения единицы измерения (метрики). Объекту присваивается число единиц измерения, пропорциональное выраженности измеряемого свойства. Важная особенность интервальной шкалы — произвольность выбора нулевой точки: ноль вовсе не соответствует полному отсутствию измеряемого свойства. Произвольность выбора нулевой точки отсчета обозначает, что измерение в этой шкале не соответствует абсолютному количеству измеряемого свойства. Следовательно, применяя эту шкалу, мы можем судить, насколько больше или насколько меньше выражено свойство при сравнении объектов, но не можем судить о том, во сколько раз больше или меньше выражено свойство.
ПРИМЕР_______________________________________________________
Наиболее типичный пример измерения в интервальной шкале — температура по шкале Цельсия (°С). Важная особенность такого измерения заключается в том, что нулевая точка на шкале не соответствует полному отсутствию измеряемого свойства (0°С — это точка замерзания воды, но не отсутствия температуры, тепла). И если сегодня +5 °С, а вчера было + 10°С, то можно сказать, что сегодня на 5 градусов холоднее, но неверно утверждать, что сегодня холоднее в два раза.

 |
Интервальные измерения широко используются в психологии. Примером могут являться тестовые шкалы, которые специально вводятся при обосновании равноинтервальности (метричности) тестовой шкалы (IQ Векслера, стены, /"-шкала и т. д.).
ГЛАВА 2. ИЗМЕРЕНИЯ И ШКАЛЫ
Абсолютная шкала, или шкала отношений (метрическая).Измерение в этой шкале отличается от интервального только тем, что в ней устанавливается нулевая точка, соответствующая полному отсутствию выраженности измеряемого свойства.
ПРИМЕР_______________________________
В отличие от температуры по Цельсию, температура по Кельвину представляет собой измерение в абсолютной шкале. Более привычные примеры измерения в этой шкале — это измерения роста, веса, времени выполнения задачи и т. д. Общим в этих примерах является применение единиц измерения и то, что нулевой точке соответствует полное отсутствие измеряемого свойства.
В силу абсолютности нулевой точки, при сравнении объектов мы можем сказать не только о том, насколько больше или меньше выражено свойство, но и о том, во сколько раз (на сколько процентов и т. д.) больше или меньше оно выражено. Измерив время решения задачи парой испытуемых, мы можем сказать не только о том, кто и на сколько секунд (минут) решил задачу быстрее, но и о том, во сколько раз (на сколько процентов) быстрее.
Следует отметить, что, несмотря на привычность и обыденность абсолютной шкалы, в психологии она используется не часто. Из редких примеров можно привести измерение времени реакции (обычно в миллисекундах) и измерение абсолютных порогов чувствительности (в физических единицах свойств стимула).
Перечисленные шкалы полезно характеризовать еще и по признаку их дифференцирующей способности (мощности). В этом отношении шкалы по мере возрастания мощности располагаются следующим образом: номинативная, ранговая, интервальная, абсолютная. Таким образом, неметрические шкалы заведомо менее мощные — они отражают меньше информации о различии объектов (испытуемых) по измеренному свойству, и, напротив, метрические шкалы более мощные, они лучше дифференцируют испытуемых. Поэтому, если у исследователя есть возможность выбора, следует применить более мощную шкалу. Другое дело, что чаще такого выбора нет, и приходится использовать доступную измерительную шкалу. Более того, часто исследователю даже трудно определить, какую шкалу он применяет.
КАК ОПРЕДЕЛИТЬ, В КАКОЙ ШКАЛЕ ИЗМЕРЕНО ЯВЛЕНИЕ
Определение того, в какой шкале измерено явление (представлен признак), — ключевой момент анализа данных: любой последующий шаг, выбор любого метода зависит именно от этого.
 ЧАСТЬ I. ОСНОВЫ ИЗМЕРЕНИЯ И КОЛИЧЕСТВЕННОГО ОПИСАНИЯ ДАННЫХ
ЧАСТЬ I. ОСНОВЫ ИЗМЕРЕНИЯ И КОЛИЧЕСТВЕННОГО ОПИСАНИЯ ДАННЫХ
Обычно идентификация номинативной шкалы, ее дифференциация от ранговой, а тем более от метрической шкалы не вызывает особых проблем.
ПРИМЕР_______________________________________________________
Рассмотрим вопрос анкеты, для ответа на который испытуемые выбирают один из предложенных вариантов: «Насколько Вы уверены в своих силах...
1) Совершенно уверен
2) Затрудняюсь ответить
3) Совершенно неуверен»
Если исследователя интересует, в какой степени испытуемые уверены или не уверены в своих силах, то логично предполагать, что признак представлен в ранговой шкале. Если же исследователя интересует то, как распределились ответы по вариантам или чем характеризуется каждая из 3 соответствующих групп, то разумнее рассматривать этот признак как номинативный.
Значительно сложнее определить различие между порядковой и метрической шкалами. Проблема связана с тем, что измерения в психологии, как правило, косвенные. Непосредственно мы измеряем некоторые наблюдаемые явления или события: количество ответов на вопросы, или заданий, решенных за отведенное время, или время решения набора заданий и т. д. Но при этом выносим суждения о некотором скрытом, латентном свойстве, недоступном прямому наблюдению: об агрессивности, общительности, способности и т. д.
Количество заданий, решенных за отведенное время, — это, конечно, измерение в метрической шкале. Но само по себе это количество нас интересует лишь в той мере, в какой оно отражает некоторую изучаемую нами способность. Соответствуют ли равные разности решенных задач равным разностям выраженности изучаемого свойства (способности)? Если ответ «да» — шкала метрическая (интервальная), если «нет» — шкала порядковая.
Конечно, проще всего в подобных ситуациях согласиться с тем, что признак представлен в порядковой шкале. Но при этом мы существенно ограничиваем себя в выборе методов последующего анализа. Более того, переход к менее мощной шкале обрекает нас на утрату части столь ценной для нас эмпирической информации об индивидуальных различиях испытуемых. Следствием этого может являться падение статистической достоверности результатов исследования. Поэтому исследователь стремится все же найти свидетельства того, что используемая шкала — более мощная, метрическая. То, какие обоснования метричности шкалы обычно учитываются, мы рассмотрим несколько позднее — в разделе о нормальном распределении.
ГЛАВА 2. ИЗМЕРЕНИЯ И ШКАЛЫ
Задачи и упражнения
Определите, в какой шкале представлено каждое из приведенных ниже измерений: наименований, порядка, интервалов, абсолютной.
1. Порядковый номер испытуемого в списке (для его идентификации).
2. Количество вопросов в анкете как мера трудоемкости опроса.
3. Упорядочивание испытуемых по времени решения тестовой задачи.
4. Академический статус (ассистент, доцент, профессор) как указание на
принадлежность к соответствующей категории.
5. Академический статус (ассистент, доцент, профессор) как мера продви
жения по службе.
6. Телефонные номера.
7. Время решения задачи.
8. Количество агрессивных реакций за рабочий день.
9. Количество агрессивных реакций за рабочий день как показатель агрес
сивности.
Глава 3
ТАБЛИЦЫ И ГРАФИКИ
Обычно в ходе исследования интересующий исследователя признак измеряется не у одного-двух, а у множества объектов (испытуемых). Кроме того, каждый… ПРИМЕР_______________________________________________________________ Предположим, психолога интересует социальная сплоченность двух параллельных классов, различие в этом отношении…Таблица частот, сгруппированных по интервалам времени решения тестовой задачи
Еще одной разновидностью таблиц распределения являются таблицы распределения накопленных частот. Они показывают, как накапливаются частоты по мере возрастания значений признака. Напротив каждого значения (интервала) указывается сумма частот встречаемости всех тех наблюдений, величина признака у которых не превышает данного значения (меньше верхней границы данного интервала). Накопленные частоты содержатся в правых столбцах табл. 3.2 и 3.3.
Для более наглядного представления строится график распределения частот или график накопленных частот — гистограмма или сглаженная кривая распределения.
ЧАСТЬ I. ОСНОВЫ ИЗМЕРЕНИЯ И КОЛИЧЕСТВЕННОГО ОПИСАНИЯ ДАННЫХ
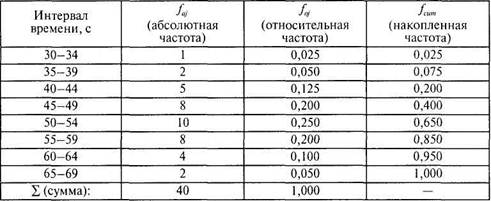
Гистограмма распределения частот— это столбиковая диаграмма, каждый столбец которой опирается на конкретное значение признака или разрядный интервал (для сгруппированных частот). Высота столбика пропорциональна частоте встречаемости соответствующего значения. На рис. 3.1 изображена гистограмма распределения частот для примера из табл. 3.2.
Гистограмма накопленных частот отличается от гистограммы распределения тем, что высота каждого столбика пропорциональна частоте, накопленной к данному значению (интервалу). На рис. 3.2 изображена гистограмма накопленных частот для данных табл. 3.2.

|
Рис. 3.2. Гистограмма накопленных относительных частот самооценки (по данным табл. 3.2)
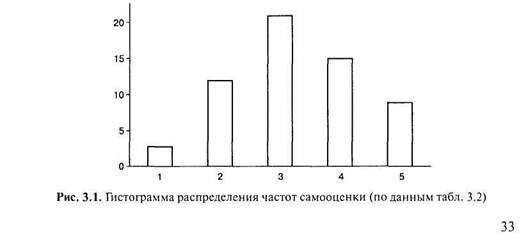
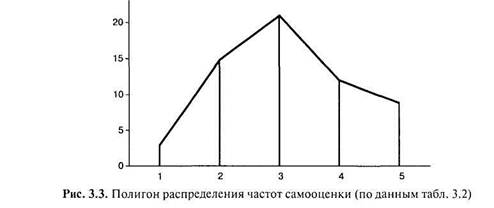
Построение полигона распределения частот напоминает построение гистограммы. В гистограмме вершина каждого столбца, соответствующая частоте встречаемости данного значения (интервала) признака, — отрезок прямой. А для полигона отмечается точка, соответствующая середине этого отрезка. Далее все точки соединяются ломаной линией (рис. 3.3).
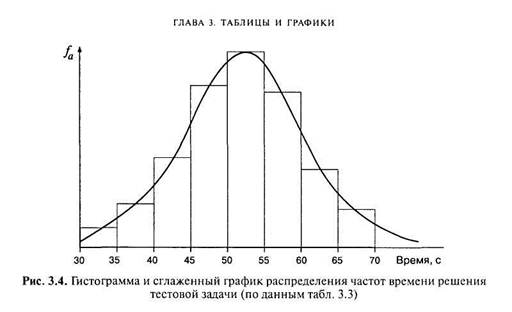
Вместо гистограммы или полигона часто изображают сглаженную кривую распределения частот. На рис. 3.4 изображена гистограмма распределения для примера из табл. 3.3 (столбики) и сглаженная кривая того же распределения частот.
ПРИМЕНЕНИЕ ТАБЛИЦ И ГРАФИКОВ РАСПРЕДЕЛЕНИЯ ЧАСТОТ
Таблицы и графики распределения частот дают важную предварительную информацию о форме распределения признака: о том, какие значения встречаются реже, а какие чаще, насколько выражена изменчивость признака. Обычно выделяют следующие типичные формы распределения. Равномерное распределение — когда все значения встречаются одинаково (или почти одинаково) часто. Симметричное распределение — когда одинаково часто встречаются крайние значения. Нормальное распределение — симметричное распределение, у которого крайние значения встречаются редко и частота постепенно повышается от крайних к серединным значениям признака. Асимметричные распределения — левосторонние (с преобладанием частот малых значений), правосторонние (с преобладанием частот больших значений). К понятию формы распределения мы еще не раз вернемся, прежде всего — в связи с использованием в психологии нормального распределения как особого эталона — стандарта.
Уже сами по себе таблицы и графики распределения признака позволяют делать некоторые содержательные выводы при сравнении групп испытуемых между собой. Сравнивая распределения, мы можем не только судить о том, какие значения встречаются чаще в той или иной группе, но и сравнивать группы по степени выраженности индивидуальных различий — изменчивости по данному признаку.
Таблицы и графики накопленных частот позволяют быстро получить дополнительную информацию о том, сколько испытуемых (или какая их доля) имеют выраженность признака не выше определенного значения.
ЧАСТЬ I. ОСНОВЫ ИЗМЕРЕНИЯ И КОЛИЧЕСТВЕННОГО ОПИСАНИЯ ДАННЫХ
Следует отметить, что для сравнения групп разной численности следует использовать таблицы и графики относительных частот.
ПРИМЕР______________________________________________________________
В группе юношей и группе девушек измерена тревожность при помощи тестовой шкалы. По результатам измерений построены сглаженные графики распределения относительных частот отдельно для юношей и девушек (рис. 3.5). Сравнивая графики, можно сделать содержательные выводы как по уровню выраженности, так и по индивидуальной изменчивости тревожности у юношей и девушек. Так, юноши в среднем менее тревожны, чем девушки. Но индивидуальные различия — изменчивость — по тревожности выше у юношей, чем у девушек: девушки в этом отношении более похожи друг на друга.

Тревожность
Рис. 3.5. Графики распределения относительных частот тревожности юношей (1)
и девушек (2)
ТАБЛИЦЫ СОПРЯЖЕННОСТИ НОМИНАТИВНЫХ ПРИЗНАКОВ
Таблицы сопряженности,или кросстабуляции — это таблицы совместного распределения частот двух и более номинативных признаков, измеренных на одной группе объектов. Эти таблицы позволяют сопоставить два или более
ГЛАВА 3. ТАБЛИЦЫ И ГРАФИКИ
распределения. Столбцы такой таблицы соответствуют категориям (градациям) одного номинативного признака, а строки — категориям (градациям) другого номинативного признака. Если номинативные признаки внесены в электронную таблицу исходных данных, то таблицу сопряженности можно построить, воспользовавшись функцией «Кросстабуляция» одного из стандартных статистических пакетов (например, Crosstabs — в SPSS).
ПРИМЕР_________________________________________________________________________
Водном из исследований изучалась склонность людей передавать плохие или хорошие новости. На ветровых стеклах автомобилей, припаркованных у почтовых ящиков, были оставлены почтовые открытки с указанием адресата (всего — 180 шт.), содержащие либо нейтральные (хорошие), либо плохие новости. В качестве плохой новости использовалось сообщение о супружеской неверности супруга (супруги) — получателя сообщения. В процессе исследования подсчиты-валось количество отправленных открыток, дошедших до указанного адреса. Результаты представлены в табл. 3.4 — в виде таблицы сопряженности частот двух номинативных признаков: новость (две градации: плохая — хорошая), сообщение (две градации: отправлено — не отправлено). Как видите, таблица дает основание делать вывод о том, что люди с меньшей охотой отправляли открытки, содержащие плохие новости.
Таб л и ца 3.4
Зависимость распределения оставленных и полученных открыток от их содержания
Конечно, таблицы сопряженности могут включать номинативные признаки, имеющие и более двух градаций. Например, по табл. 3.1 для изучения различий в… Задачи и упражнения На трех разных, достаточно больших группах испытуемых изучалась диагностическая ценность методики измерения…Та б л и ца 3.5 Таблица распределения результатов измерения креативности в трех группах

1. Для какой из групп задания были слишком легкие, а для какой — слиш
ком трудные?
2. В какой группе наблюдается наибольшая, а в какой — наименьшая ин
дивидуальная изменчивость результатов?
3. В отношении какой группы, на ваш взгляд, методика может иметь наи
большую диагностическую ценность — точнее измерять индивидуаль
ные различия?
ОБРАБОТКА НА КОМПЬЮТЕРЕ
1. Таблица исходных данных.Может быть образована в среде SPSS двумя
способами. А) Данные можно предварительно набрать в среде программы
Excel (строки — испытуемые, столбцы — признаки). Затем путем простого
копирования блока данных в таблице Excel перенести при помощи команды
«вставка» (Past...) этот блок данных в предварительно открытую пустую таб
лицу SPSS и сохранить ее. Б) Данные можно набирать сразу в программе SPSS.
Полезно затем каждой переменной присвоить имя, вместо принятого в SPSS
по умолчанию (varOOOl...). Начиная пользоваться программой SPSS, убеди
тесь, что в качестве разделителя целой и дробной частей установлен единый
символ для всех программ — точка (Панель управления > Языки и стандарты >«
Числа > Разделитель целой и дробной частей числа— установить точку)! I
2. Таблицы распределения частот.Выбираем Analyze > Descriptive Statistics >
Frequencies... Воткрывшемся диалоговом окне (Frequencies)переносим из ле
вой в правую часть интересующие нас переменные. После этого нажимаем
ОК. В окне результатов (Output...)для каждой переменной получаем таблицу
ГЛАВА 3. ТАБЛИЦЫ И ГРАФИКИ
распределения с предварительным указанием объема выборки (Valid)и числа пропущенных значений (Missing).В таблице распределения каждая строка соответствует отдельному значению, для которого указаны (столбцы): абсолютная частота (Frequency),относительная частота в процентах от объема выборки — без учета пропусков (Percent),относительная частота действительного числа наблюдений — с учетом пропусков (Valid Percent),накопленная относительная частота в процентах (Cumulative Percent).
3. Графики распределения частот.А) При построении таблиц распределе
ния частот (см. предыдущий пункт) в открывшемся диалоговом окне после
выбора переменных нажать кнопку Charts...(графики). Задать тип графика
(Chart Type)— гистограммы (Histograms).Нажать Continue,затем ОК. Вместе
с таблицей распределения частот вы получите гистограмму распределения
каждого выбранного признака. Б) Выбираем Graphs > Histogram...В открыв
шемся диалоговом окне переносим из левой в правую часть интересующую
нас переменную, нажимаем ОК. Получаем гистограмму распределения этой
переменной.
Таблицы сопряженности (кросстабуляции).Выбираем Analyze > DescriptiveStatistics > Crosstabs... Воткрывшемся окне диалога выбираем интересующие нас номинативные переменные: одну для строк (Row(s)), другую — для стол бцов (Column(s)).После нажатия ОК получаем таблицу кросстабуляции (со пряженности) в абсолютных значениях частот. Если в окне диалога нажать кнопку Cells...(Ячейки), то в открывшемся окне можно установкой флажков задать вывод относительных частот в процентах (Percentages)по строкам (Row),столбцам (Columns)или в целом по таблице (Total).
Глава 4
ПЕРВИЧНЫЕ ОПИСАТЕЛЬНЫЕ СТАТИСТИКИ
МЕРЫ ЦЕНТРАЛЬНОЙ ТЕНДЕНЦИИ Мера центральной тенденции{Central Tendency) — это число, характеризующее… Существуют три способа определения «центральной тенденции», каждому из которых соответствует своя мера: мода, медиана…Л

 Общительность
Общительность
Рис. 4.3. Графики распределения относительных частот общительности юношей (1) и девушек (2)
ОБРАБОТКА НА КОМПЬЮТЕРЕ
Способ 1.Выбираем Analyze > Descriptive Statistics > Frequencies... Воткрывшемся диалоговом окне (Frequencies)переносим из левой в правую часть интересующие нас переменные. Если таблица распределения частот нас не интересует, снимаем флажок Display frequency tables(Показывать таблицы частот). Нажимаем кнопку Statistics...Выбираем интересующие нас статистики и отмечаем их флажком: центральной тенденции (Central Tendency)— среднее (Mean), моду (Mode),медиану (Median);изменчивости (Dispersion)— стандартное отклонение (Std. deviation),дисперсию (Variance); распределения — асимметрию (Skewness) и эксцесс (Kurtosis). После этого нажимаем Continue,затем ОК и получаем результат.
Способ 2.Выбираем Analyze> Descriptive Statistics> Descriptives... Воткрывшемся диалоговом окне переносим из левой в правую часть интересующие нас переменные. Нажимаем кнопку Options...и отмечаем флажком те статистики, которые нас интересуют (см. выше). Нажимаем Continue,затем ОК и получаем результат.
Глава 5
НОРМАЛЬНЫЙ ЗАКОН РАСПРЕДЕЛЕНИЯ И ЕГО ПРИМЕНЕНИЕ
История применения закона нормального распределения в социальных и биологических науках начинается, по-видимому, с работы бельгийского ученого А.… ЧастотаВсех случаев располагается в диапазоне значений М+ 2,58с.
ПРИМЕРЫ_______________________________________________________ 1. Значение IQ по шкале Векслера (Л/= 100; а = 15) некоторого тестируемого… ЧАСТЬ I. ОСНОВЫ ИЗМЕРЕНИЯ И КОЛИЧЕСТВЕННОГО ОПИСАНИЯ ДАННЫХK/f с/ .— A/f /т
о где Xj — искомая граница интервала «сырых» оценок, stt — граница интервала в… Эмпирическая нормализацияприменяется, когда распределение «сырых» баллов отличается от нормального. Она заключается в…1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
Рис.5.6. Распределение «сырых» оценок (по данным табл. 5.2)
Изложенные основы психодиагностики позволяют сформулировать математически обоснованные требования к тесту. Тестовая методика должна содержать:
ГЛАВА 5. НОРМАЛЬНЫЙ ЗАКОН РАСПРЕДЕЛЕНИЯ И ЕГО ПРИМЕНЕНИЕ
□ описание выборки стандартизации;
□ характеристику распределения «сырых» баллов с указанием среднего и
стандартного отклонения;
□ наименование, характеристику стандартной шкалы;
□ тестовые нормы — таблицы пересчета «сырых» баллов в шкальные.
ПРОВЕРКА НОРМАЛЬНОСТИ РАСПРЕДЕЛЕНИЯ
Для проверки нормальности используются различные процедуры, позволяющие выяснить, отличается ли от нормального выборочное распределение измеренной переменной. Необходимость такого сопоставления возникает, когда мы сомневаемся в том, в какой шкале представлен признак — в порядковой или метрической. А сомнения такие возникают очень часто, так как заранее нам, как правило, не известно, в какой шкале удастся измерить изучаемое свойство (исключая, конечно, случаи явно номинативного измерения).
Важность определения того, в какой шкале измерен признак, трудно переоценить, по крайней мере, по двум причинам. От этого зависит, во-первых, полнота учета исходной эмпирической информации (в частности, об индивидуальных различиях), во-вторых, доступность многих методов анализа данных. Если исследователь принимает решение об измерении в порядковой шкале, то неизбежное последующее ранжирование ведет к потере части исходной информации о различиях между испытуемыми, изучаемыми группами, о взаимосвязях между признаками и т. д. Кроме того, метрические данные позволяют использовать значительно более широкий набор методов анализа и, как следствие, сделать выводы исследования более глубокими и содержательными.
Наиболее весомым аргументом в пользу того, что признак измерен в метрической шкале, является соответствие выборочного распределения нормальному. Это является следствием закона нормального распределения. Если выборочное распределение не отличается от нормального, то это значит, что измеряемое свойство удалось отразить в метрической шкале (обычно — интервальной).
Существует множество различных способов проверки нормальности, из которых мы кратко опишем лишь некоторые, предполагая, что эти проверки читатель будет производить при помощи компьютерных программ.
Графический способ(Q-Q Plots, Р-Р Plots). Строят либо квантильные графики, либо графики накопленных частот. Квантильные графики (Q-Q Plots) строятся следующим образом. Сначала определяются эмпирические значения изучаемого признака, соответствующие 5, 10, ..., 95-процентилю. Затем по таблице нормального распределения для каждого из этих процентилей определяются z-значения (теоретические). Два полученных ряда чисел задают координаты точек на графике: эмпирические значения признака от-
ЧАСТЬ I. ОСНОВЫ ИЗМЕРЕНИЯ И КОЛИЧЕСТВЕННОГО ОПИСАНИЯ ДАННЫХ
кладываются на оси абсцисс, а соответствующие им теоретические значения — на оси ординат. Для нормального распределения все точки будут лежать на одной прямой или рядом с ней. Чем больше расстояние от точек до прямой линии, тем меньше распределение соответствует нормальному. Графики накопленных частот (Р-Р Plots) строятся подобным образом. На оси абсцисс через равные интервалы откладываются значения накопленных относительных частот, например 0,05; 0,1; ...; 0,95. Далее определяются эмпирические значения изучаемого признака, соответствующие каждому значению накопленной частоты, которые пересчитываются в z-значения. По таблице нормального распределения определяются теоретические накопленные частоты (площадь под кривой) для каждого из вычисленных г-зна-чений, которые откладываются на оси ординат. Если распределение соответствует нормальному, полученные на графике точки лежат на одной прямой.
Критерии асимметрии и эксцесса.Эти критерии определяют допустимую степень отклонения эмпирических значений асимметрии и эксцесса от нулевых значений, соответствующих нормальному распределению. Допустимая степень отклонения — та, которая позволяет считать, что эти статистики существенно не отличаются от нормальных параметров. Величина допустимых отклонений определяется так называемыми стандартными ошибками асимметрии и эксцесса. Для формулы асимметрии (4.10) стандартная ошибка определяются по формуле:

|
где N — объем выборки.
Выборочные значения асимметрии и эксцесса значительно отличаются от нуля, если не превышают значения своих стандартных ошибок. Это можно считать признаком соответствия выборочного распределения нормальному закону. Следует отметить, что компьютерные программы вычисляют показатели асимметрии, эксцесса и соответствующие им стандартные ошибки по другим, более сложным формулам.
Статистический критерий нормальности Колмогорова-Смирновасчитается наиболее состоятельным для определения степени соответствия эмпирического распределения нормальному. Он позволяет оценить вероятность того, что данная выборка принадлежит генеральной совокупности с нормальным распределением. Если эта вероятность р< 0,05, то данное эмпирическое распределение существенно отличается от нормального, а если р > 0,05, то делают вывод о приблизительном соответствии данного эмпирического распределения нормальному.
ГЛАВА 5. НОРМАЛЬНЫЙ ЗАКОН РАСПРЕДЕЛЕНИЯ И ЕГО ПРИМЕНЕНИЕ
Причины отклонения от нормальности.Общей причиной отклонения формы выборочного распределения признака от нормального вида чаще всего является особенность процедуры измерения: используемая шкала может обладать неравномерной чувствительностью к измеряемому свойству в разных частях диапазона его изменчивости.
ПРИМЕР
 Предположим, выраженность некоторой способности определяется количеством выполненных заданий за отведенное время. Если задания простые или время слишком велико, то данная измерительная процедура будет обладать достаточной чувствительностью лишь в отношении части испытуемых, для которых эти задания достаточно трудны. И слишком большая доля испытуемых будет решать все или почти все задания. В итоге мы получим распределение с выраженной правосторонней асимметрией. Можно, конечно, впоследствии повысить качество измерения путем эмпирической нормализации, добавив более сложные задания или сократив время выполнения данного набора заданий. Если же мы чрезмерно усложним измерительную процедуру, то возникнет обратная ситуация, когда большая часть испытуемых будет решать малое количество заданий и эмпирическое распределение приобретет левостороннюю асимметрию.
Предположим, выраженность некоторой способности определяется количеством выполненных заданий за отведенное время. Если задания простые или время слишком велико, то данная измерительная процедура будет обладать достаточной чувствительностью лишь в отношении части испытуемых, для которых эти задания достаточно трудны. И слишком большая доля испытуемых будет решать все или почти все задания. В итоге мы получим распределение с выраженной правосторонней асимметрией. Можно, конечно, впоследствии повысить качество измерения путем эмпирической нормализации, добавив более сложные задания или сократив время выполнения данного набора заданий. Если же мы чрезмерно усложним измерительную процедуру, то возникнет обратная ситуация, когда большая часть испытуемых будет решать малое количество заданий и эмпирическое распределение приобретет левостороннюю асимметрию.
Таким образом, такие отклонения от нормального вида, как право- или левосторонняя асимметрия или слишком большой эксцесс (больше 0), связаны с относительно низкой чувствительностью измерительной процедуры в области моды (вершины графика распределения частот).
Последствия отклоненияот нормальности.Следует отметить, что задача получения эмпирического распределения, строго соответствующего нормальному закону, нечасто встречается в практике исследования. Обычно такие случаи ограничиваются разработкой новой измерительной процедуры или тестовой шкалы, когда применяется эмпирическая или нелинейная нормализация для «исправления» эмпирического распределения. В большинстве случаев соответствие или несоответствие нормальности является тем свойством измеренного признака, который исследователь должен учитывать при выборе статистических процедур анализа данных.
| Заметно ли "на глаз" отличие распределения от нормального вида? |
| X |
 В общем случае при значительном отклонении эмпирического распределения от нормального следует отказаться от предположения о том, что признак измерен в метрической шкале. Но остается открытым вопрос о том, какова мера существенности этого отклонения? Кроме того, разные методы анализа данных обладают различной чувствительностью к отклонениям от нормальности. Обычно при обосновании перспективности этой проблемы приводят принцип Р. Фишера, одного из «отцов-основателей» современной статистики: «Отклонения от нормально-
В общем случае при значительном отклонении эмпирического распределения от нормального следует отказаться от предположения о том, что признак измерен в метрической шкале. Но остается открытым вопрос о том, какова мера существенности этого отклонения? Кроме того, разные методы анализа данных обладают различной чувствительностью к отклонениям от нормальности. Обычно при обосновании перспективности этой проблемы приводят принцип Р. Фишера, одного из «отцов-основателей» современной статистики: «Отклонения от нормально-
ЧАСТЬ I. ОСНОВЫ ИЗМЕРЕНИЯ И КОЛИЧЕСТВЕННОГО ОПИСАНИЯ ДАННЫХ
го вида, если только они не слишком заметны, можно обнаружить лишь для больших выборок; сами по себе они вносят малое отличие в статистические критерии и другие вопросы»1. К примеру, при малых, но обычных для психологических исследований выборках (до 50 человек) критерий Колмогорова-Смирнова недостаточно чувствителен при определении даже весьма заметных «на глаз» отклонений от нормальности. В то же время некоторые процедуры анализа метрических данных вполне допускают отклонения от нормального распределения (одни — в большей степени, другие — в меньшей). В дальнейшем при изложении материала мы при необходимости будем оговаривать меру жесткости требования нормальности.
Задачи и упражнения
1. Некоторое свойство измеряется при помощи тестовой шкалы СЕЕВ
(Л/=500, о= 100). Какая приблизительно доля генеральной совокупно
сти имеет балл от 600 до 700?
2. В генеральной совокупности значения IQ в шкале Векслера распределе
ны приблизительно нормально со средним 100 и стандартным отклоне
нием 15. С помощью таблиц определите следующие вероятности:
а) вероятность того, что случайно выбранный человек будет иметь IQ
между 79 и 121;
б) вероятность того, что случайно выбранный человек будет иметь IQ
выше 127; ниже 73.
3. Определите при помощи квантильного графика, соответствует ли нор
мальному виду распределение переменной со следующими значениями
процентилей:

В области каких значений шкала, в которой измерен признак, обладает большей дифференцирующей способностью (чувствительностью), а в какой — меньшей?
ОБРАБОТКА НА КОМПЬЮТЕРЕ
Критерии асимметрии и эксцесса. Выбираем Analyze > Descriptive Statistics > Descriptives... В окне диалога переносим из левого окна в правое интересующие нас переменные. Нажимаем кнопку Options..., ставим флажок Distribution >
1 Цит. по: Справочник по прикладной статистике: В 2 т. / Под ред. Э. Ллойда, У. Ледермана. М., 1989. Т. 1.С. 270.
ГЛАВА 5. НОРМАЛЬНЫЙ ЗАКОН РАСПРЕДЕЛЕНИЯ И ЕГО ПРИМЕНЕНИЕ
Kurtosis, Skewness,нажимаем Continue,затем ОК. В таблице результатов столбцы Kurtosisи Skewnessсодержат значения асимметрии (Kurtosis)и эксцесса (Skewness) и соответствующие им стандартные ошибки (Std. Error).Распределение соответствует нормальному виду, если для соответствующей переменной абсолютные значения асимметрии и эксцесса не превышают свои стандартные ошибки.
Графический способ.Выбираем Graphs> РР...— графики накопленных частот (или Graphs> QQ...— квантильные графики). Открывается диалог Р-Р Plots (Q-Q Plots).Переносим из левого в правое окно интересующие нас переменные. Нажимаем ОК. В окне результатов просматриваем графики Normal Р-Р Plot... (Normal Q-Q Plot...),на которых по горизонтальной оси отложены соответствующие эмпирические значения, а по вертикальной оси — теоретические значения. Чем ближе точки графиков к прямой линии, тем меньше отличие распределения от нормального вида.
Критерий нормальности Колмогорова-Смирнова.Выбираем Analyze > Nonpa-rametric Tests > 1-Sample K-S...Открывается диалог One-Sample Kolmogorov-Smirnov Test.Переносим из левого в правое окно интересующие нас переменные. Нажимаем ОК. В соответствующем переменной столбце находим Kolmogorov-SmirnovZ(значение критерия) и Asymp. Sig. (2-tailed)(вероятность того, что распределение соответствует нормальному виду). Если значение Asymp. Sig.меньше или равно 0,05, то распределение существенно отличается от нормального вида. Если Asymp. Sig.больше 0,05, то существенного отличия от нормальности не обнаружено.
Глава 6
КОЭФФИЦИЕНТЫ КОРРЕЛЯЦИИ
Коэффициент корреляции— двумерная описательная статистика, количественная мера взаимосвязи (совместной изменчивости) двух переменных. История разработки и применения коэффициентов корреляции для исследования… К настоящему времени разработано великое множество различных коэффициентов корреляции, проблеме измерения взаимосвязи…X
Рис. 6.2. Примеры диаграмм рассеивания и соответствующих коэффициентов корреляции
Коэффициент корреляции— это количественная мера силы и направления вероятностной взаимосвязи двух переменных; принимает значения в диапазоне от-1 до +1.
Сила связи достигает максимума при условии взаимно однозначного соответствия: когда каждому значению одной переменной соответствует только одно значение другой переменной (и наоборот), эмпирическая взаимосвязь при этом совпадает с функциональной линейной связью. Показателем силы связи является абсолютная (без учета знака) величина коэффициента корреляции.
Направление связи определяется прямым или обратным соотношением значений двух переменных: если возрастанию значений одной переменной соответствует возрастание значений другой переменной, то взаимосвязь называется прямой (положительной); если возрастанию значений одной переменной соответствует убывание значений другой переменной, то взаимосвязь является обратной (отрицательной). Показателем направления связи является знак коэффициента корреляции.
КОЭФФИЦИЕНТ КОРРЕЛЯЦИИ г-ПИРСОНА
r-Пирсона (Pearson r) применяется для изучения взаимосвязи двух метрических переменных, измеренных на одной и той же выборке. Существует множество ситуаций, в которых уместно его применение. Влияет ли интеллект на успеваемость на старших курсах университета? Связан ли размер заработной платы работника с его доброжелательностью к коллегам? Влияет ли настроение
ЧАСТЬ I. ОСНОВЫ ИЗМЕРЕНИЯ И КОЛИЧЕСТВЕННОГО ОПИСАНИЯ ДАННЫХ
школьника на успешность решения сложной арифметической задачи? Для ответа на подобные вопросы исследователь должен измерить два интересующих его показателя у каждого члена выборки. Данные для изучения взаимосвязи затем сводятся в таблицу, как в приведенном ниже примере.
ПРИМЕР 6.1___________________________________________________________
В таблице приведен пример исходных данных измерения двух показателей интеллекта (вербального и невербального) у 20 учащихся 8-го класса.

|
 |
Связь между этими переменными можно изобразить при помощи диаграммы рассеивания (см. рис. 6.3). Диаграмма показывает, что существует некоторая взаимосвязь измеренных показателей: чем больше значения вербального интеллекта, тем (преимущественно) больше значения невербального интеллекта.
Прежде чем дать формулу коэффициента корреляции, попробуем проследить логику ее возникновения, используя данные примера 6.1. Положение каждой /-точки (испытуемого с номером /) на диаграмме рассеивания относительно остальных точек (рис. 6.3) может быть задано величинами и знаками отклонений соответствующих значений переменных от своих средних величин: (xj — MJ и (у, —Му). Если знаки этих отклонений совпадают, то это свидетельствует в пользу положительной взаимосвязи (большим значениям

|
9 10 11
Вербальный IQ
Рис. 6.3. Диаграмма рассеивания для данных примера 6.1
по х соответствуют большие значения по у или меньшим значениям по х соответствуют меньшие значения по у).
ПРИМЕР______________________________________________________________
Для испытуемого № 1 отклонение от среднего по х и по у положительное, а для испытуемого № 3 и то и другое отклонения отрицательные. Следовательно, данные того и другого свидетельствуют о положительной взаимосвязи изучаемых признаков. Напротив, если знаки отклонений от средних по х и по у различаются, то это будет свидетельствовать об отрицательной взаимосвязи между признаками. Так, для испытуемого № 4 отклонение от среднего по х является отрицательным, по у — положительным, а для испытуемого № 9 — наоборот.
Таким образом, если произведение отклонений (х,— Мх) х (у, — Му) положительное, то данные /-испытуемого свидетельствуют о прямой (положительной) взаимосвязи, а если отрицательное — то об обратной (отрицательной) взаимосвязи. Соответственно, если х w у ъ основном связаны прямо пропорционально, то большинство произведений отклонений будет положительным, а если они связаны обратным соотношением, то большинство произведений будет отрицательным. Следовательно, общим показателем для силы и направления взаимосвязи может служить сумма всех произведений отклонений для данной выборки:
ЧАСТЬ I. ОСНОВЫ ИЗМЕРЕНИЯ И КОЛИЧЕСТВЕННОГО ОПИСАНИЯ ДАННЫХ
При прямо пропорциональной связи между переменными эта величина является большой и положительной — для большинства испытуемых отклонения совпадают по знаку (большим значениям одной переменной соответствуют большие значения другой переменной и наоборот). Если же х и у имеют обратную связь, то для большинства испытуемых большим значениям одной переменной будут соответствовать меньшие значения другой переменной, т. е. знаки произведений будут отрицательными, а сумма произведений в целом будет тоже большой по абсолютной величине, но отрицательной по знаку. Если систематической связи между переменными не будет наблюдаться, то положительные слагаемые (произведения отклонений) уравновесятся отрицательными слагаемыми, и сумма всех произведений отклонений будет близка к нулю.
Чтобы сумма произведений не зависела от объема выборки, достаточно ее усреднить. Но мера взаимосвязи нас интересует не как генеральный параметр, а как вычисляемая его оценка — статистика. Поэтому, как и для формулы дисперсии, в этом случае поступим также, делим сумму произведений отклонений не на N, а на TV— 1. Получается мера связи, широко применяемая в физике и технических науках, которая называется ковариацией (Covahance):

|
13 психологии, в отличие от физики, большинство переменных измеряются в произвольных шкалах, так как психологов интересует не абсолютное значение признака, а взаимное расположение испытуемых в группе. К тому же ковариация весьма чувствительна к масштабу шкалы (дисперсии), в которой измерены признаки. Чтобы сделать меру связи независимой от единиц измерения того и другого признака, достаточно разделить ковариацию на соответствующие стандартные отклонения. Таким образом и была получена формула коэффициента корреляции К. Пирсона:

|
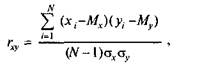 (6.1) или, после подстановки выражений для ох и gv:
(6.1) или, после подстановки выражений для ох и gv:
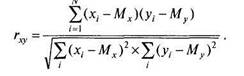
|
Уравнение (6.1) является основной формулой коэффициента корреляции Пирсона. Эта формула вполне осмысленна, но не очень удобна для вычислений «вручную» или на калькуляторе. Поэтому существуют производные фор-
ГЛАВА 6. КОЭФФИЦИЕНТЫ КОРРЕЛЯЦИИ
мулы — более громоздкие по виду, менее доступные осмыслению, но упрощающие расчеты. Мы не будем их здесь приводить, так как один раз в жизни можно в учебных целях посчитать корреляцию Пирсона и по исходной формуле «вручную», а в дальнейшем для обработки реальных данных все равно придется воспользоваться компьютерными программами.
ПРИМЕР 6.2_____________________________________________________________
Для расчета коэффициента корреляции воспользуемся данными примера 6.1 о вербальном и невербальном IQ, измеренном у 20 учащихся 8-го класса. К двум столбцам с исходными данными добавляются еще 5 столбцов для дополнительных расчетов, и внизу — строка сумм.
| № | X | Y | {х,-Мх) | (х, - A/V)(.y, - Му) | |||
| 3,2 | 1,6 | 10,24 | 2,56 | 5,12 | |||
| -0,8 | 0,6 | 0,64 | 0,36 | -0,48 | |||
| -1,8 | -2,4 | 3,24 | 5,76 | 4,32 | |||
| -0,8 | 1,6 | 0,64 | 2,56 | -1,28 | |||
| -2,8 | -1,4 | 7,84 | 1,96 | 3,92 | |||
| -0,8 | 0,6 | 0,64 | 0,36 | -0,48 | |||
| -1,8 | -1,4 | 3,24 | 1,96 | 2,52 | |||
| 3,2 | 2,6 | 10,24 | 6,76 | 8,32 | |||
| 1,2 | -1,4 | 1,44 | 1,96 | -1,68 | |||
| 2,2 | -0,4 | 4,84 | 0,16 | -0,88 | |||
| -1,8 | -1,4 | 3,24 | 1,96 | 2,52 | |||
| -0,8 | -2,4 | 0,64 | 5,76 | 1,92 | |||
| 0,2 | -0,4 | 0,04 | 0,16 | -0,08 | |||
| 0,2 | 1,6 | 0,04 | 2,56 | 0,32 | |||
| 2,2 | -0,4 | 4,84 | 0,16 | -0,88 | |||
| 0,2 | -0,4 | 0,04 | 0,16 | -0,08 | |||
| -1,8 | 0,6 | 3,24 | 0,36 | -1,08 | |||
| -0,8 | -0,4 | 0,64 | 0,16 | 0,32 | |||
| 0,2 | 0,6 | 0,04 | 0,36 | 0,12 | |||
| 1,2 | 2,6 | 1,44 | 6,76 | 3,12 | |||
| X | 0,00 | 0,00 | 57,2 | 42,8 | 25,6 |
На первом шаге подсчитываются суммы всех значений одного, затем — другого признака для вычисления соответствующих средних значений Мх и Му: Мх = 9,8; Л/, = 10,4.
Далее для каждого испытуемого вычисляются отклонения от среднего: для Х для Y. Каждое отклонение от среднего возводится в квадрат. В последнем столбике записывается результат перемножения двух отклонений от среднего для каждого испытуемого.
Суммы отклонений от среднего для каждой переменной должны быть равны нулю (с точностью до погрешности вычислений). Сумма квадратов отклонений необходима для вычисления стандартных отклонений по известной формуле (4.7):
ЧАСТЬ I. ОСНОВЫ ИЗМЕРЕНИЯ И КОЛИЧЕСТВЕННОГО ОПИСАНИЯ ДАННЫХ

Сумма произведений отклонений дает нам значение числителя, а произведение стандартных отклонений и (./V— 1) — значение знаменателя формулы коэффициента корреляции:
- - 25'6 - = 0,517.
" 1,735 1,501 19
Если значения той и другой переменной были преобразованы в г-значения по формуле:

|
то формула коэффициента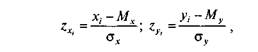 корреляции r-Пирсона выглядит проще:
корреляции r-Пирсона выглядит проще:
N
39 N-l '
Отметим еще раз: на величину коэффициента корреляции не влияет то, в каких единицах измерения представлены признаки. Следовательно, любые линейные преобразования признаков (умножение на константу, прибавление константы: у; = хр + а) не меняют значения коэффициента корреляции. Исключением является умножение одного из признаков на отрицательную константу: коэффициент корреляции меняет свой знак на противоположный.
На рис. 6.2 приведены примеры диаграмм рассеивания для различных значений коэффициента корреляции. Обратите внимание: на последнем рисунке визуально наблюдается нелинейная взаимосвязь между переменными, однако коэффициент корреляции равен нулю. Таким образом, коэффициент корреляции Пирсона есть мера прямолинейной взаимосвязи; он не чувствителен к криволинейным связям.
КОРРЕЛЯЦИЯ, РЕГРЕССИЯ И КОЭФФИЦИЕНТ ДЕТЕРМИНАЦИИ
Корреляция Пирсона есть мера линейной связи между двумя переменными. Она позволяет определить, насколько пропорциональна изменчивость двух переменных. Если переменные пропорциональны друг другу, то графически связь между ними можно представить в виде прямой линии с положительным (прямая пропорция) или отрицательным (обратная пропорция) наклоном. Кроме того, если известна пропорция между переменными, заданная уравнением графика прямой линии:
ГЛАВА 6. КОЭФФИЦИЕНТЫ КОРРЕЛЯЦИИ
то по известным значениям переменной ЛГможно точно предсказать значения переменной Y.
На практике связь между двумя переменными, если она есть, является вероятностной и графически выглядит как облако рассеивания эллипсоидной формы. Этот эллипсоид, однако, можно представить (аппроксимировать) в виде прямой линии, или линии регрессии. Линия регрессии(Regression Line) — это прямая, построенная методом наименьших квадратов: сумма квадратов расстояний (вычисленных по оси У) от каждой точки графика рассеивания до прямой является минимальной:
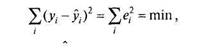
|

|
где у, — истинное /-значение Y, у, — оценка /-значения Кпри помощи линии (уравнения) регрессии, е, = .у,— yt— ошибка оценки (см. рис. 6.4). Уравнение регрессии имеет вид:

|
у-, = bXj+а, (6.2)
где b — коэффициент регрессии (Regression Coefficient), задающий угол наклона прямой; а — свободный член, определяющий точку пересечения прямой оси Y. Если известны средние, стандартные отклонения и корреляция гху, то сумма квадратов ошибок минимальна, если:

|
О
b = r —^-,а = М„—ЬМг (f, i.
у *. (6.3)
Таким образом, если на некоторой выборке измерены две переменные, которые коррелируют друг с другом, то, вычислив коэффициенты регрессии,

Рис. 6.4. Диаграмма рассеивания и линия регрессии (е,- — ошибка оценки для одного из
объектов)
ЧАСТЬ I. ОСНОВЫ ИЗМЕРЕНИЯ И КОЛИЧЕСТВЕННОГО ОПИСАНИЯ ДАННЫХ
мы получаем принципиальную возможность предсказания неизвестных значений одной переменной (У— «зависимая переменная») по известным значениям другой переменной (X — «независимая переменная»). Например, предсказываемой «зависимой переменной» может быть успешность обучения, а предиктором, «независимой переменной» — результаты вступительного теста.
С какой степенью точности возможно такое предсказание?
Понятно, что наиболее точным предсказание будет, если гху = 1. Тогда каждому значению Сбудет соответствовать только одно значение У, а все ошибки оценки будут равны 0 (все точки на графике рассеивания будут лежать на прямой регрессии). Если же гху — О, то b = О и у, = Му, т. е. при любом Xоценка переменной Убудет равна ее среднему значению и предсказательная ценность регрессии ничтожна.
Особое значение для оценки точности предсказания имеет дисперсия оценок зависимой переменной. Отметим, что дисперсия оценок равна нулю, если гху = 0 — все оценки равны среднему значению, прямая регрессии параллельна оси X. А если гху = 1, то дисперсия оценок равна истинной дисперсии переменной У, достигая своего максимума:

|
Lt; о) < а] .
Неизвестную дисперсию оценок У можно выразить через другие, известные статистики, зная рассмотренные ранее свойства дисперсии: так как прибавление константы а к каждому значению переменной не меняет дисперсию, а умножение на константу b —…Ш
6 8 10
Вербальный IQ
Рис. 6.5. Демонстрация влияния экстремальных значений признаков («выброса») на коэффициент корреляции Пирсона
Пример 6.8 демонстрирует, что даже одно наблюдение с экстремально большими или малыми значениями переменных может изменить знак корреляции на противоположный. Точно так же немногочисленные выбросы могут обусловить и появление корреляции.
Существенно меньшему влиянию выбросов подвержены ранговые корреляции. Поэтому один из способов борьбы с выбросами — переход к рангам и применение ранговых коэффициентов корреляции.
Для примера 6.8 ранговые коэффициенты корреляции (Спирмена и Кендалла) для первых 20 испытуемых (без выброса) составляют, соответственно: rs = 0,505; х = 0,390. При добавлении выбросов: rs = 0,294; т = 0,239. Значения корреляций уменьшилось, но не столь существенно, как л-Пирсона.
Другой подход к выбросам подразумевает «чистку» данных. Можно для каждой переменной установить определенное ограничение на диапазон ее изменчивости. Например, исключать те наблюдения, которые выходят за пределы диапазона М±2а (или даже М± 1,5а).
ЧАСТЬ I. ОСНОВЫ ИЗМЕРЕНИЯ И КОЛИЧЕСТВЕННОГО ОПИСАНИЯ ДАННЫХ
Часто такая «чистка» совершенно необходима. Например, при исследовании времени реакции, когда основная масса наблюдений находится в диапазоне 250-700 мс, исключение нескольких «странных» значений меньше 50 мс и больше 1000 мс может существенно изменить общую картину.
По сути, наличие выбросов означает отклонение распределений одной или обеих переменных от нормального вида. В общем случае, если распределения переменных сильно скошены (асимметричны), это может существенно снижать значение корреляции даже при сильной связи между соответствующими свойствами или, наоборот, обусловить появление «ложной» корреляции. Особенно сильно асимметричность распределений влияет на г-Пирсона. Поэтому при существенном отклонении формы распределения хотя бы одной переменной от нормального вида желательно перейти к рангам и воспользоваться ранговым коэффициентом корреляции.
Влияние «третьей» переменной
Иногда корреляция между двумя переменными обусловлена не связью между соответствующими свойствами, а влиянием некоторой общей причины совместной изменчивости этих переменных, которая зачастую выпадает из поля зрения исследователя. Эта общая причина может быть измерена как некоторая «третья» переменная, представленная либо в номинативной шкале, либо в количественной (ранговой или метрической) шкале.
Если истинная причина корреляции представляет собой номинативную переменную, то это проявляется в характерной неоднородности выборки: в ней можно обнаружить различные группы, для которых согласованно меняются средние двух переменных, в то время как внутри групп эти переменные не коррелируют. Если подобное явление возможно и существует способ содержательно интерпретируемого деления выборки на группы, необходимо вычислить корреляцию не только для всей выборки, но и для каждой группы в отдельности.
ПРИМЕР_______________________________________________________
Если мы возьмем достаточно большую группу людей — мужчин и женщин, то обнаружим существенную отрицательную корреляцию роста и длины волос: чем больше рост, тем короче волосы. Однако, рассматривая график рассеивания роста и длины волос с выделением групп мужчин и женщин, мы обнаружим истинную причину этой корреляции — пол (рис. 6.6). Корреляции роста и длины волос отдельно для мужчин и отдельно для женщин будут близки к нулю.
Другой случай «ложной» корреляции — когда «третья» переменная может быть представлена в числовой шкале.
ПРИМЕР_______________________________________________________
Число церквей и количество увеселительных заведений в городах, как известно, сильно коррелируют, так же, впрочем, как рост и навык чтения у детей. Нетрудно
Рис. 6.6. График рассеивания для роста и длины волос. Темные точки — мужчины, светлые треугольники — женщины
догадаться, что в первом случае «третьей» переменной является численность городского населения, а во втором — возраст детей. (См. также пример 6.3 из раздела «Частная корреляция».)
Если истинная причина корреляции между двумя переменными Хп YИзмерена как количественная переменная Z, то предположение о том, что именно она является причиной корреляции, можно проверить, вычислив частную корреляцию rxy_z по формуле 6.5. Если частная корреляция Хп Ус учетом Z (rxy-z) существенно меньше г^, то весьма вероятно, что именно Zявляeтcя истинной причиной корреляции Хп Y.
Следует отметить, что за редким исключением факт наличия или отсутствия корреляции может быть объяснен влиянием некоторой «третьей» переменной, упущенной из поля зрения исследователя. Таким образом, всегда остается возможность альтернативной интерпретации обнаруженной корреляции.
Нелинейные связи
Еще одним источником низкой эффективности корреляций являются возможный нелинейный характер связи между переменными. То, какой характер имеет связь между переменными, можно заметить, рассматривая график двумерного рассеивания. Это свидетельствует о важности визуального анализа связи с помощью таких графиков во всех случаях применения корреляций.
К отклонениям от прямолинейной зависимости любого рода наиболее чувствителен коэффициент корреляции r-Пирсона. Однако если нелинейная
ЧАСТЬ I. ОСНОВЫ ИЗМЕРЕНИЯ И КОЛИЧЕСТВЕННОГО ОПИСАНИЯ ДАННЫХ
связь оказывается монотонной, то возможен переход к рангам и применение ранговых корреляций.
Довольно часто в исследованиях встречаются немонотонные связи — когда связь меняет свое направление (с прямого на обратное, или наоборот) при увеличении или уменьшении значений одной из переменной.
ПРИМЕРЫ_______________________________________________________________________
Наиболее типичный пример — это связь тревожности и результатов тестирования, или в общем случае — связь уровня активации (X) и продуктивности деятельности (Y). Связь таких переменных напоминает перевернутую (инвертированную) U (рис. 6.7). Любой из рассмотренных коэффициентов корреляции будет в этом случае иметь значение, близкое к нулю.
Продуктивность

Если наблюдается немонотонная нелинейность связи, то можно поступить двояко. В первом случае сначала надо найти точку перегиба по графику рассеивания и разделить выборку на две группы, различающиеся направлением связи между переменными. После этого можно вычислять корреляции отдельно для каждой группы. Второй способ предполагает отказ от применения коэффициентов корреляции. Необходимо ввести дополнительную номинативную переменную, которая делит исследуемую выборку на контрастные группы по одной из переменных. Далее можно изучать различия между этими группами по уровню выраженности (например, по средним значениям) другой переменной.
В приведенном примере (рис. 6.7) можно по переменной «активация» выделить 3 группы (низкий, средний и высокий уровень) и далее изучать различия между этими группами по продуктивности деятельности.
КАКОЙ КОЭФФИЦИЕНТ КОРРЕЛЯЦИИ ВЫБРАТЬ
При изучении связей между переменными наиболее предпочтительным является случай применения r-Пирсона непосредственно к исходным данным. В любом случае, обнаружена корреляция или нет, необходим визуальный ана-
ГЛАВА 6. КОЭФФИЦИЕНТЫ КОРРЕЛЯЦИИ
лиз графиков распределения переменных и графика двумерного рассеивания, если исследователя действительно интересует связь между соответствующими переменными. Применяя /•-Пирсона, необходимо убедиться, что: П обе переменные не имеют выраженной асимметрии;
□ отсутствуют выбросы;
□ связь между переменными прямолинейная.
Если хотя бы одно из условий не выполняется, можно попытаться применить ранговые коэффициенты корреляции: r-Спирмена или х-Кендалла. Но и ранговые корреляции имеют свои ограничения. Они применимы, если:
□ обе переменные представлены в количественной шкале (метрической
или ранговой);
□ связь между переменными является монотонной (не меняет свой знак с
изменением величины одной из переменных).
Применение ранговых коэффициентов корреляции при расчете «вручную» требует предварительного ранжирования переменных. Если при этом встречаются одинаковые значения признаков (связи в рангах), применяется формула r-Пирсона для предварительно ранжированных переменных (в случае с r-Спирмена) либо вводятся поправки на связанные ранги (в случае с т-Кен-далла).
Если есть предположение, что корреляция обусловлена влиянием третьей переменной, и все три переменные допускают применение r-Пирсона для вычисления корреляции между ними, возможна проверка этого предположения путем вычисления коэффициента частной корреляции этих переменных (при фиксированных значениях третьей переменной). Если значение частной корреляции двух переменных по абсолютной величине заметно меньше, чем их парная корреляция, то парная корреляция обусловлена влиянием третьей переменной.
Применяя коэффициенты корреляции, особое внимание следует уделять графикам двумерного рассеивания. Они позволяют выявить случаи, когда корреляция обусловлена неоднородностью выборки по той и другой переменной. Кроме того, эти графики позволяют определить характер связи: ее линейность и монотонность. Если связь является криволинейной и не монотонной (например, имеет форму U), то коэффициенты корреляции не подходят. 13 этом случае можно разделить выборку на группы по одной из переменных, для сравнения этих групп по выраженности другой переменной.
Если обе переменные представлены в бинарной шкале (0,1), для изучения связи между ними можно применять ф-коэффициент сопряженности, если для каждой переменной количество 0 и 1 приблизительно одинаковое.
Во всех случаях, когда исследователя интересует связь между переменными, а коэффициенты корреляции для этого не подходят, изучение этой связи возможно при помощи сравнения групп, выделяемых по одной из переменных. Если другая переменная метрическая или ранговая, то группы сравниваются по уровню ее выраженности, если номинативная — то по ее распределению.
ЧАСТЬ I. ОСНОВЫ ИЗМЕРЕНИЯ И КОЛИЧЕСТВЕННОГО ОПИСАНИЯ ДАННЫХ
ОБРАБОТКА НА КОМПЬЮТЕРЕ
1. Графики двумерного рассеивания.Выбираем Graphs... > Scatter... > Simple.
Нажимаем Define. Впоявляющемся окне назначаем осям переменные: выде
ляем слева одну переменную, нажимаем > напротив «X Axis» (Ось X), выделя
ем другую переменную, нажимаем > напротив «Y Axis». Нажимаем ОК. По
лучаем график рассеивания назначенных переменных.
2. Вычисление парных корреляций.Выбираем Analyze> Correlate > Bivariate...
В открывшемся окне диалога переносим интересующие переменные из ле
вой части в правую при помощи кнопки > (переменных должно быть как
минимум две). По умолчанию стоит флажок «Pearson» (корреляция г-Пирсо-
на). Если интересует корреляция r-Спирмена или т-Кендалла, необходимо
поставить соответствующие флажки внизу. Нажимаем ОК. В появившейся
таблице строки и столбцы соответствуют выделенным ранее переменным.
В ячейке на пересечении строки и столбца, соответствующих интересующим
нас переменным, видим три числа: верхнее соответствует коэффициенту кор
реляции, нижнее — численности выборки N, среднее — уровню значимости.
3. Вычисление частной корреляции.Выбираем Analyze> Correlate > Partial...
В открывшемся окне диалога переносим интересующие переменные из ле
вой части в правое верхнее окно (Variables:)при помощи верхней кнопки >
(переменных должно быть как минимум две). Затем при помощи нижней
кнопки > из левой части в правое нижнее окно (Controlling for:)переносим
переменную, значения которой хотим фиксировать. Нажимаем ОК. Получа
ем таблицу, аналогичную таблице парных корреляций, но верхнее число в
каждой ячейке — значение частной корреляции соответствующих двух пере
менных при фиксированном значении указанной третьей переменной. Ниж
нее число — уровень значимости, а посередине — число степеней свободы.
– Конец работы –
Используемые теги: Математические, Методы, психологического, исследования, анализ, Интерпретация, данных, Учебное, пособие0.113
Если Вам нужно дополнительный материал на эту тему, или Вы не нашли то, что искали, рекомендуем воспользоваться поиском по нашей базе работ: Математические методы психологического исследования. Анализ и интерпретация данных. Учебное пособие
Что будем делать с полученным материалом:
Если этот материал оказался полезным для Вас, Вы можете сохранить его на свою страничку в социальных сетях:
| Твитнуть |
Хотите получать на электронную почту самые свежие новости?

Подпишитесь на Нашу рассылку
Реклама





Информация в виде рефератов, конспектов, лекций, курсовых и дипломных работ имеют своего автора, которому принадлежат права. Поэтому, прежде чем использовать какую либо информацию с этого сайта, убедитесь, что этим Вы не нарушаете чье либо право.
© copyright 1999 - 2024 allRefs.net. Все права защищены. Страница сгенерирована за: 0.206 сек.
Новости и инфо для студентов