Профиль параллелизма программы
Число процессоров многопроцессорной системы, параллельно участвующих в выполнении программы в каждый момент времени t, определяют понятием степень параллелизма D(t) (DOP, Degree Of Parallelism). Графическое представление параметра D(t) как функции времени называют профилем параллелизма программы. Изменения в уровне загрузки процессоров за время наблюдения зависят от многих факторов (алгоритма, доступных ресурсов, степени оптимизации, обеспечиваемой компилятором и т. д.). Типичный профиль параллелизма для алгоритма декомпозиции (divide-and-conquer algorithm) показан на рис. 86.
В дальнейшем будем исходить из следующих предположений: система состоит из п гомогенных процессоров; максимальный параллелизм в профиле равен т и, в идеальном случае, п >> т. Производительность А одиночного процессора системы выражается в единицах скорости вычислений (количество операций в единицу времени) и не учитывает издержек, связанных с обращением к памяти и пересылкой данных. Если за наблюдаемый период загружены i процессоров, то D = i.

Рис. 86. Профиль параллелизма.
Общий объем вычислительной работы W (команд или вычислений), выполненной начиная со стартового момента ts до момента завершения te, пропорционален площади под кривой профиля параллелизма:
 .
.
Интеграл часто заменяют дискретным эквивалентом:
 ,
,
где  – общее время, в течение которого
– общее время, в течение которого 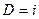 , а
, а  – общее затраченное время.
– общее затраченное время.
Средний параллелизм А определяется как
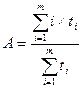 .
.
Профиль параллелизма на рисунке за время наблюдения (ts, te) возрастает от 1 до пикового значения т = 8, а затем спадает до 0. Средний параллелизм А = ( 1 х 5 + 2 x 3 + 3 x 4 + 4 x 6 + 5 x 2 + 6 x 2 + 8 x 3) /(5 + 3 + 4 + 6 + 2 + 2 + 3) = 93/25 = 3,72. Фактически общая рабочая нагрузка и А представляют собой нижнюю границу асимптотического ускорения.
Будем говорить, что параллельная программа выполняется в режиме i, если для ее исполнения задействованы i процессоров. Время, на продолжении которого система работает в режиме i, обозначим через ti, а объем работы, выполненной в режиме i, как  . Тогда, при наличии п процессоров время исполнения Т(п) для двух экстремальных случаев: п = 1(T(1)) и n = ∞(T(∞)) можно записать в виде:
. Тогда, при наличии п процессоров время исполнения Т(п) для двух экстремальных случаев: п = 1(T(1)) и n = ∞(T(∞)) можно записать в виде:
 и
и  .
.
Асимптотическое повышение быстродействия S∞ определяется как отношение T(1) к T(∞):
 .
.
Сравнивая это выражение и предыдущие уравнения, можно констатировать, что в идеальном варианте S∞ = A. В общем случае нужно учитывать коммуникационные задержки и системные издержки. Отметим, что как S∞ так и А были определены в предположении, что n >> m.
В прикладных программах имеется широкий диапазон потенциального параллелизма. М. Кумар в своей статье приводил данные, что в вычислительно интенсивных программах в каждом цикле параллельно могут выполняться от 500 до 3500 арифметических операций, если для этого имеется существующая вычислительная среда. Однако даже правильно спроектированный суперскалярный процессор способен поддерживать выполнение от 2 до 5,8 команды за цикл. Эти цифры дают пессимистическую картину возможного параллелизма.