Методические указания.
ППП Excel предлагает пользователям встроенный инструмент Регрессия, который позволяет проводить полный регрессионный анализ. Чтобы воспользоваться этим инструментом, необходимо активизировать Пакет анализа (команда Сервис – Надстройки). Далее из меню Сервис вызвать диалоговое окно Анализ данных и выбрать инструмент анализа Регрессия. В диалоговое окно Регрессия ввести в поле Входной интервал Y диапазон со значениями зависимых переменных, в поле Входной интервал X -диапазон со значениями независимых переменных. В поле Уровень надежности введите значение 95% и результаты представьте в новом рабочем листе (рис 1).
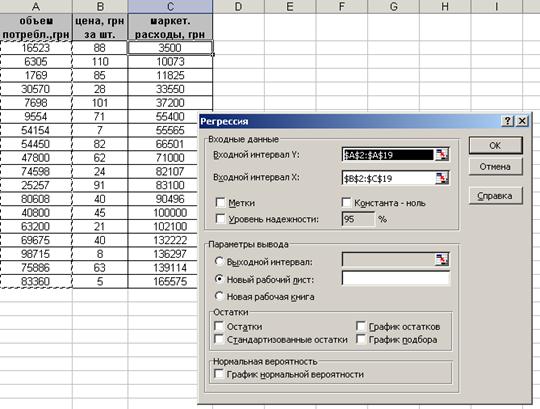
Рис.1 – Диалоговое окно Регрессия
Результаты, которые вы получите с использованием инструмента Регрессия, представлены на рис. 2.
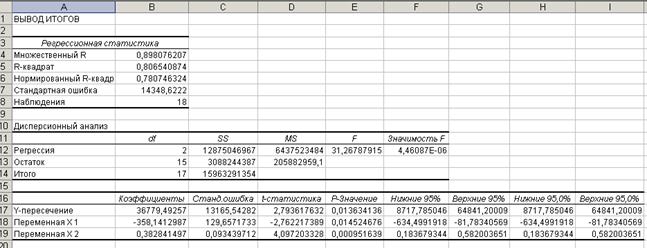
Рис. 2 – Результаты обработки данных инструментом Регрессия
Проанализируем полученные результаты.
R-квадрат (R2 – коэффициент детерминации) выражает долю дисперсии в объеме продаж в единицах продукции, связанную с дисперсией в расходах на рекламу в денежном выражении и продажной цены.
Значение R2 означает, что приблизительно 80% меры изменчивости объемов продаж связан с мерой изменчивости расходов на рекламу и ценой.
Коэффициент детерминации R2 используется для анализа общего качества оцененной линейной регрессии и характеризует долю вариации (разброса) зависимой переменной, в качестве меры разброса зависимой переменной используется ее дисперсия.
Множественный R представляет собой квадратный корень из дисперсии R2. Это значение является коэффициентом корреляции и выражает корреляцию между объемом продаж и полученной комбинацией предсказуемых переменных.
Нормированный R-квадратучитывает количество результатов наблюдений и предсказуемых переменных. При проведении множественного регрессионного анализа (если по сравнению с количеством предсказуемых переменных число результатов незначительно) R2 имеет тенденцию отклоняться в сторону повышения. Нормированный обеспечивает информацией о том, какое значение мы могли бы получить в другом наборе данных, который был бы намного больше, чем анализируемый в данном случае. Если бы рассматриваемый пример был основан на 100 результатах наблюдений, то нормированный R2 имел бы очень незначительное отличие от фактического R2.
Стандартная ошибка — это мера ошибки предсказанного значения зависимой переменной для отдельного значения независимой переменной.
Третий раздел представляет детальную информацию о членах уравнения регрессии – отрезке на оси ординат (Y-пересечение), коэффициентах (переменных) и стандартных погрешностях. Уравнение регрессии будет иметь вид: 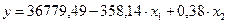 .
.
Этот результат имеет следующий экономический смысл: если цена увеличиться на одну денежную единицу, то объемы продаж уменьшаться на 358 штук, при всех других неизменных условиях. Если расходы на маркетинг увеличатся на одну денежную единицу, то объемы продаж увеличатся на 0,4 штуки при всех других неизменных условиях. То есть для продажи дополнительных 4 единиц продукции затраты на маркетинг следует увеличить на 5 денежных единиц.
Формально значимость оцененного коэффициента регрессии может быть проверена с помощью анализа его отношения к своему стандартному отклонению. Эта величина в случае выполнения исходных предпосылок модели имеет t-распределение Стьюдента с определенным числом степеней свободы (степень свободы представляет собой количество наблюдений минус число членов уравнения) и называется t-статистикой.
Для t-статистики проверяется нулевая гипотеза, то есть гипотеза о равенстве ее нулю. Очевидно, что если умножить нуль на число значений связанной с ним предсказуемой переменной, как это делается в уравнении регрессии, то необходимо будет прибавить нуль к прогнозируемому значению переменной-критерия, что делает совершенно бесполезной предсказываемую переменную.
ППП Excel возвращает значение параметра t для отрезка и для каждого коэффициента регрессии и показывает долю каждого члена уравнения в его стандартной погрешности. Положительный знак t-статистики свидетельствует о наличии положительной связи между переменной и критерием, т.е. чем выше цена на продукцию, тем ниже объемы продаж.
Распределение Фишера – двухпараметрическое распределение неотрицательной случайной величины, являющейся в частном случае, квадратом случайной величины, распределенной по Стьюденту.
И, наконец, выводятся значения верхнего и нижнего пределов 95-процентного уровня надежности, как для отрезка, так и для каждого коэффициента.