рефераты конспекты курсовые дипломные лекции шпоры

- Раздел Маркетинг
- /
- Тема 4. Маркетинговые исследования
Реферат Курсовая Конспект
Тема 4. Маркетинговые исследования
Тема 4. Маркетинговые исследования - раздел Маркетинг, Тема 1. Сущность маркетинга и его современная концепция Задание 8 Для Расчета Доли Рынка Продукта Питания Марки «Х» Производ...
Задание 8
Для расчета доли рынка продукта питания марки «Х» производителю необходимо знать среднее значение объема его потребления одной семьей за год в натуральном выражении с точностью ± 0,25 кг и уровнях значимости 5% и 1%.
При этом известно, что объемы потребления продукта семьями с разным уровнем доходов (низким, средним и высоким) отличаются из-за различий в финансовых возможностях потребления. Данные о количестве семей с разным уровнем доходов в общей совокупности потребителей, а также о максимальном и минимальном объеме покупок ими продукта приведены в таблице.
Таблица
Количество семей с разным уровнем доходов и объемы их покупок
| Уровень доходов | Количество семей | Минимальный объем покупок, кг. | Максимальный объем покупок, кг. |
| Низкий | 0,4 | 5,7 | |
| Средний | 2,8 | 6,3 | |
| Высокий | 2,5 | 8,4 |
Наличие этих данных позволяет использовать для оценки среднего значение объема потребления продукта одну из видов случайных выборок: простую, стратифицированную пропорциональную, стратифицированную непропорциональную.
Используя имеющиеся данные, определите
размер выборки каждого из видов, необходимый для оценки среднего значения объема потребления продукта с заданной точностью и достоверностями, сравните их размеры и сделайте выводы;
определите размеры подвыборок, которые необходимо сделать из каждой страты при формировании пропорциональной и непропорциональной стратифицированных выборок.
Методические рекомендации к выполнению задания 8
Простая случайная выборка (Simple Random Sampling — SRS) - вероятностный метод выборки, согласно которому каждый элемент генеральной совокупности имеет известную и равную вероятность отбора. Каждый элемент выбирается независимо от каждого другого элемента, и выборка формируется произвольным отбором элементов из основы выборки. При простой случайной выборке исследователь сначала формирует основу выборочного наблюдения, в которой каждому элементу присваивается уникальный идентификационный номер. Затем генерируются случайные числа, чтобы определить номера элементов, которые будут включены в выборку. Эти случайные числа могут генерироваться компьютерной программой.
Простая случайная выборка не часто используется в маркетинговых исследованиях. Более популярен метод систематической выборки.
Систематическая выборка (systematic sampling) – сначала задают произвольную отправную точку, а затем из основы выборочного наблюдения последовательно выбирают каждый i-й элемент. Интервал выборки i определяется как отношение объема совокупности N к объему выборки п, с округлением результата до ближайшего целого числа. Например, совокупность состоит из 100 тысяч элементов, а желательный объем выборки равен тысяче респондентов. В этом случае интервал выборки i равен 100. Выбирается случайное число между 1 и 100. Если, например, это число равно 23, то выборка состоит из элементов 23, 123, 223, 323, 423, 523 и т.д.
Размер простой случайной выборки рассчитывается следующим образом:
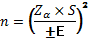
| (1) |
где, n – размер выборки, ед.;
Zα – константа, отражающая уровень погрешности (значимости) результатов;
S – среднеквадратическое отклонение в выборке или генеральной совокупности (макс – мин/6);
Е – допустимая ошибка оцениваемого параметра в единицах измерения этого параметра.
| α | 1% | 5% | 10% | 20% |
| Zα | 2,57 | 1,96 | 1,64 | 1,28 |
Часто некоторая совокупность может быть разделена на подсовокупности, отличающиеся между собой уровнем значений изучаемой переменной. Простая выборка, к сожалению, не гарантирует хорошую представительность в ней всех отличающихся подсовокупностей, существующих внутри генеральной совокупности. Поэтому простая случайная выборка не исключает возможность получить оценку изучаемого параметра очень далекую от его истинного значения.
Цель стратифицированных выборок состоит в том, чтобы повысить точность оценки, выделяя «слои» (страты), более однородные внутри себя и отличающиеся друг от друга с точки зрения диапазона возможных значений исследуемой переменной. Из–за внутренней однородности каждой из страт в них будет наблюдаться меньшая вариация изучаемого признака, чем общая вариация в генеральной совокупности. Это, в свою очередь, будет является причиной меньшей общей вариации, учитываемой при расчете размера выборки.
При составлении пропорциональной стратифицированной выборки генеральная совокупность подразделяется на взаимоисключающие и исчерпывающие подсовокупности. Критерий деления на страты должен быть выбран таким образом, чтобы изучаемые объекты были однородны внутри каждой страты с точки зрения изучаемой переменной и отличались от объектов других страт. В исследованиях массового потребителя классическим критерием стратификации является уровень доходов.
Размер пропорциональной стратифицированной выборки (n), обеспечивающей желаемую точность измерения (E) исследуемого параметра с заданным уровнем значимости (a) может быть определен по формуле:
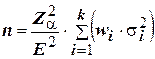 , (4)
, (4)
где wi – значимость (удельный вес) i –й страты в генеральной совокупности;
si – вариация значений исследуемой переменной в i –й страте;
k – количество страт.
Для определения параметра (si) можно использовать один из уже известных подходов.
Для составления пропорциональной стратифицированной выборки из каждой страты делаются простые случайные выборки таким образом, чтобы они были пропорциональны размерам страт в генеральной совокупности.
Удельный вес страты в генеральной совокупности не обязательно является наилучшим, особенно тогда, когда в каждой страте вариация изучаемой переменной существенно отличается. В стратах, где вариация небольшая можно было бы довольствоваться подвыборкой намного меньших размеров, чем это диктуется удельным весом страты. И, наоборот, там, где вариация значительна принять непропорционально бóльшую выборку, позволяющую улучшить точность оценки.
Размер непропорциональной стратифицированной выборки можно рассчитать по формуле:
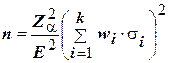 . (5)
. (5)
Распределение общего рассчетного числа респондентов между стратами в непропорциональной стратифицированной выборке делается с использованием следующего уравнения:
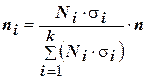 , (6)
, (6)
где Ni - размер i-й страты, чел.;
ni - размер выборки из i-й страты, чел.;
si - cреднеквадратическое отклонение значений исследуемого признака в i-й страте.
Задание 9
В таблице 2 представлены данные о полученных в результате опроса значениях двух дихотомических переменных - «Пол» и «Регулярность покупки продукта «А». Каждая из них принимает только одно из двух возможных значений. Переменная «Пол» принимает значения:
«Мужчина»;
«Женщина».
Переменная «Регулярность покупки продукта «А» принимает значения:
«Регулярно»;
«Иногда».
Таблица 2
Регулярность покупки продукта потребителями разного пола
| «Регулярно» | «Иногда» | ||
| Вариант 1 | Мужчины | ||
| Женщины | |||
| Вариант 2 | Мужчины | ||
| Женщины | |||
| Вариант 3 | Мужчины | ||
| Женщины | |||
| Вариант 4 | Мужчины | ||
| Женщины | |||
| Вариант 5 | Мужчины | ||
| Женщины |
Используя приведенные данные, сделайте вывод с уровнем достоверности не менее 5%,
существует ли связь между анализируемыми переменными;
если связь существует, то какова ее сила.
Методические рекомендации к выполнению задания 9
Для анализа связи между двумя дихотомическими (бинарными) переменными строятся таблицы частот, с которыми «пересекаются» градации обеих переменных (таблицы сопряженности, перекрестные таблицы). Такие таблицы имеют вид таблицы 3.
Таблица 3
Пример таблицы сопряженности градаций дихотомических переменных
| Значения переменной В(j) | |||
| B1 | B2 | ||
| Значения переменной А(i) | A1 | A1 B1 | A1 B2 |
| A2 | A2 B1 | A2 B2 |
Ai Bj – количество наблюдений выборки, в которых совпадают i-е свойство переменной A с j-м свойством переменной B.
Вывод о существовании связи (или ее отсутствии) между двумя номинальными (в частном случае дихотомическими) переменными могут служить результаты расчета значения статистики c2.
Схема формулировки вывода о наличии (отсутствии) связи между переменными будет следующей: «Отклонить нулевую гипотезу об отсутствии связи с вероятностью ошибки (a), если расчетное значение c2 > критического».
Формула для определения расчетного значения статистики c2 выглядит следующим образом:
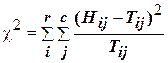 , (7)
, (7)
где Нij – наблюдаемые в выборке частоты совпадений свойств переменных (Ai Bj );
Тij – теоретические частоты, с которыми должны совпадать свойства переменных (Ai Bj ), если справедлива гипотеза об отсутствии связи между ними;
r – число строк таблицы сопряженности (2);
c – число колонок таблицы сопряженности (2).
Теоретические частоты (Тij) совпадения свойств двух дихотомических переменных (частоты на пересечении строк i и колонок j) могут быть рассчитаны по формуле:
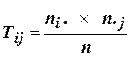 , (8)
, (8)
где 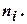 – сумма наблюдаемых частот в каждой i-й строке;
– сумма наблюдаемых частот в каждой i-й строке;
 – суммы наблюдаемых частот в каждой j-й колонке;
– суммы наблюдаемых частот в каждой j-й колонке;
n – число наблюдений в выборке.
Число степеней свободы (k) для определения критического значения стратистики c2 рассчитывается по формуле:
k = (r – 1)×(c–1). (9)
Если значение стратистики c2, превышает критическое, что свидетельствует о наличии статистически значимой связи между двумя дихотомическими переменными, то желательно иметь коэффициент, характеризующий тесноту (силу, степень) этой связи. Такая информация может быть получена путем расчета ряда коэффициентов.
Если известно значение статистики c2, то можно рассчитать значение следующих коэффициентов:
коэффициента сопряженности (С);
коэффициента корреляции (j)
Значение коэффициента сопряженности (С) определяется по следующей формуле:
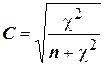 . (10)
. (10)
Когда ассоциативная связь между переменными отсутствует значение коэффициента сопряженности (С) тоже будет равно 0. Максимальное же значение коэффициента сопряженности при равенстве числа градаций исследуемых переменных (r = c) задается выражением:
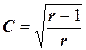 . (11)
. (11)
Степень связи между переменными оценивается путем сравнения расчетного значения коэффициента сопряженности с его максимально возможным значением.
С использованием данных таблицы 3, значение коэффициента корреляции (j)[1] определяется по формуле:
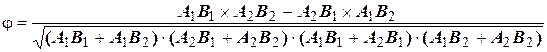 . (12)
. (12)
То же самое значение коэффициента можно получить, используя зависимость между значениями (j) и c2, которая определяется следующим выражением:
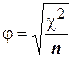 . (13)
. (13)
Коэффициент (j) может принимать значения от –1 до +1. Значение (0) означает отсутствие какой-либо связи. Значения (-1 или + 1), независимо от знака, означают наличие абсолютной (функциональной) связи между одними и теми же градациями анализируемых переменных, но зависит от способа представления частот их совпадения в таблице сопряженности. Например, знак (+) свидетельствует об одновременном (совместном) изменении частот совпадений градаций переменных, отражаемых в ячейках Aи D таблицы 4. Если же способ представления градаций тех же дихотомических переменных в таблице сопряженности будет изменен, как показано в таблице 5, то абсолютное значение коэффициента (j) не изменится, но он будет иметь знак (–), что не влияет на интерпретацию результатов расчета.
Задание 10
Полагая, что объемы продаж продукта зависят от размера затрат на рекламу, предприятие в течение ряда месяцев фиксировало значение этих показателей. Результаты наблюдений приведены в таблице 10. Используя эти результаты,
представьте в виде графика зафиксированные соответствия между размерами затрат на рекламу и объемами продаж;
рассчитайте коэффициенты (b и b) линейной регрессионной модели, отражающей зависимость между этими показателями и отобразите линию регрессии на том же графике; определите степень точности полученной регрессионной модели;
определите силу (тесноту) связи между анализируемыми показателями.
Методические рекомендации к выполнению задания 10
Линейная регрессионная модель зависимости между двумя переменными в общем виде может быть представлена следующим образом:
 ,
,
где Y– зависимая переменная (в задании - объемы продаж)
X– независимая переменная (размеры затрат на рекламу);
а – постоянный коэффициент, отражающий значение Y, которое имеет место при отсутствии влияния на нее переменной X;
b – коэффициент регрессии, который количественно характеризует степень влияния изменений независимой переменной X на зависимую переменную Y (в масштабе реальных единиц их измерения).
Значения этих коэффициентов рассчитываются по формулам:
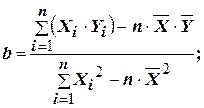
 ,
,
где Xi, Yi– наблюдаемые значения переменных X и Y;
n – число наблюдений соответствующих друг другу пар значений переменных;
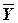 ,
, 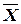 – средние арифметические значения наблюдаемых переменных, соответственно Y и X. Определяются по формулам:
– средние арифметические значения наблюдаемых переменных, соответственно Y и X. Определяются по формулам:
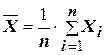 ;
;  .
.
Таблица 10
Результаты наблюдений объемов продаж и размеров затрат на рекламу
| Наблюдение | Варианты | |||||||||||||||||||
| Объем продаж | Затраты на рекламу | Объем продаж | Затраты на рекламу | Объем продаж | Затраты на рекламу | Объем продаж | Затраты на рекламу | Объем продаж | Затраты на рекламу | Объем продаж | Затраты на рекламу | Объем продаж | Затраты на рекламу | Объем продаж | Затраты на рекламу | Объем продаж | Затраты на рекламу | Объем продаж | Затраты на рекламу | |
Коэффициент b в регрессионной модели количественно отражает влияние уровня независимой переменной X на формирование уровня зависимой переменной Y с учетом реальных единиц их измерения. С изменением единиц измерения любой из переменных значения b - коэффициентов в регрессионной модели также изменятся.
Вместе с тем, часто бывает необходимо определить долю влияния независимой переменной на уровень зависимой переменной, которая остается одинаковой при любых единицах измерения переменных и для удобства интерпретации может быть выражена в процентах.
Долю влияния (в долях единицы) переменной X на формирование уровня зависимой переменной Y характеризует стандартизованный коэффициент регрессии, или b - коэффициент. Он связан с коэффициентом (b) следующим соотношением:
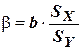 ,
,
где b – стандартизованный коэффициент регрессии;
– Конец работы –
Эта тема принадлежит разделу:
Тема 1. Сущность маркетинга и его современная концепция
Задание... В таблице приведены данные о годовых объемах продаж конкурирующих марок на рынке грузовиков Таблица...
Если Вам нужно дополнительный материал на эту тему, или Вы не нашли то, что искали, рекомендуем воспользоваться поиском по нашей базе работ: Тема 4. Маркетинговые исследования
Что будем делать с полученным материалом:
Если этот материал оказался полезным ля Вас, Вы можете сохранить его на свою страничку в социальных сетях:
| Твитнуть |
Хотите получать на электронную почту самые свежие новости?

Подпишитесь на Нашу рассылку
Реклама





Информация в виде рефератов, конспектов, лекций, курсовых и дипломных работ имеют своего автора, которому принадлежат права. Поэтому, прежде чем использовать какую либо информацию с этого сайта, убедитесь, что этим Вы не нарушаете чье либо право.
© copyright 1999 - 2024 allRefs.net. Все права защищены. Страница сгенерирована за: 0.035 сек.
Новости и инфо для студентов