Автоматизированные системы поддержки разработки рациональных управленческих решений
Определяют 12 правил, которым должен удовлетворять программный продукт класса OLAP.
1. Многомерное концептуальное представление данных. Концептуальное представление модели данных в продукте OLAP должно быть многомерным по своей природе, то есть позволять аналитикам выполнять интуитивные операции “анализа вдоль и поперек” (“slice and dice”), вращения (rotate) и размещения (pivot) направлений консолидации.
2. Прозрачность. Пользователь не должен знать о том, какие конкретные средства исполь-зуются для хранения и обработки данных, как данные организованы и откуда берутся.
3. Доступность. Аналитик должен иметь возможность выполнять анализ в рамках общей концептуальной схемы, то есть инструментарий OLAP должен накладывать свою логическую схему на массивы данных, выполняя все преобразования, требующиеся для обеспечения единого, согласованного и целостного взгляда пользователя на информацию.
4. Устойчивая производительность. С увеличением числа измерений и размеров базы данных аналитики не должны столкнуться с каким бы то ни было уменьшением производительности. Устойчивая производительность необходима для поддержания простоты использования и свободы от усложнений, которые требуются для доведения OLAP до конечного пользователя.
5. Клиент – серверная архитектура. Большая часть данных, требующих оперативной анали-тической обработки, хранится на главных (корпоративных) ЭВМ, а извлекается с персональных компьютеров. Поэтому одним из требований является способность продуктов OLAP работать в среде клиент-сервер. Главной идеей здесь является то, что серверный компонент инструмента OLAP должен быть достаточно интеллектуальным и обладать способностью строить общую концептуальную схему на основе обобщения и консолидации различных корпоративных баз данных для обеспечения эффекта прозрачности.
6. Равноправие измерений. Все измерения данных должны быть равноправны. Дополнитель-ные характеристики могут быть предоставлены отдельным измерениям, но поскольку все они симметричны, данная дополнительная функциональность может быть предоставлена любому измерению. Базовая структура данных, формулы и форматы отчетов не должны опираться на какое-то одно измерение.
7. Динамическая обработка разреженных матриц. Инструмент OLAP должен обеспечивать оптимальную обработку разреженных матриц. Скорость доступа должна сохраняться вне зависимости от расположения ячеек данных и быть постоянной величиной для моделей, имеющих разное число измерений и различную разреженность данных.
8. Поддержка многопользовательского режима. Зачастую несколько аналитиков имеют необходимость работать одновременно с одной аналитической моделью или создавать различные модели на основе одних корпоративных данных. Инструмент OLAP должен предоставлять им конкурентный доступ, обеспечивать целостность и защиту данных.
9. Неограниченная поддержка кроссмерных операций. Вычисления и манипуляция данными по любому числу измерений не должны запрещать или ограничивать любые отношения между ячейками данных. Преобразования, требующие произвольного определения, должны задаваться на функционально полном формульном языке.
10. Интуитивное манипулирование данными. Переориентация направлений консолидации, детализация данных в колонках и строках таблиц, агрегация и другие манипуляции, свойственные структуре иерархии направлений консолидации, должны выполняться в максимально удобном, естественном и комфортном пользовательском интерфейсе.
11. Гибкий механизм генерации отчетов. Должны поддерживаться различные способы визуа-лизации данных, то есть отчеты должны представляться в любой возможной ориентации.
12. Неограниченное количество измерений и уровней агрегации. Настоятельно рекомендуется допущение в каждом серьезном OLAP-инструменте, как минимум, пятнадцати, а лучше двадцати, измерений в аналитической модели. Более того, каждое из этих измерений должно допускать практически неограниченное количество определенных пользователем уровней агрегации по любому направлению консолидации.
Набор этих требований, послуживших фактическим определением OLAP, следует рассматривать как рекомендательный, а конкретные продукты оценивать по степени приближения к идеально полному соответствию всем требованиям.
Интеллектуальный анализ данных (ИАД) – это процесс поддержки принятия решений, осно-ванный на поиске в данных скрытых закономерностей (шаблонов информации). При этом накоп-ленные сведения автоматически обобщаются до информации, которая может быть охарактери-зована как знания.
В общем случае процесс ИАД состоит из трех стадий (рисунок 8):
– выявления закономерностей (свободный поиск);
– использования выявленных закономерностей для предсказания неизвестных значений (прог-ностическое моделирование);
– анализа исключений, предназначенный для выявления и толкования аномалий в найденных закономерностях.
Все методы ИАД подразделяются на две большие группы по принципу работы с исходными обучающими данными.
В первом случае исходные данные могут храниться в явном детализированном виде и непосредственно использоваться для прогностического моделирования и/или анализа исключений – это так называемые методы рассуждений на основе анализа прецедентов. Главной проблемой этой группы методов является затрудненность их использования на больших объемах данных, хотя именно при анализе больших хранилищ данных методы ИАД приносят наибольшую пользу.
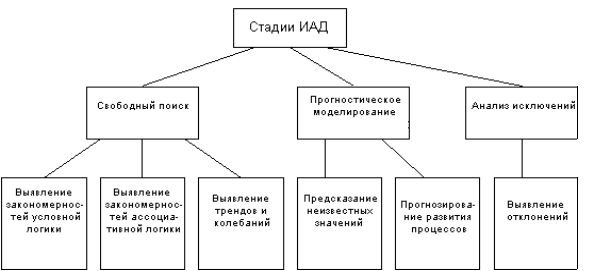
Рисунок 8. Стадии процесса интеллектуального анализа данных
Во втором случае информация вначале извлекается из первичных данных и преобразуется в некоторые формальные конструкции. Согласно предыдущей классификации, этот этап выпол-няется на стадии свободного поиска, которая у методов первой группы в принципе отсутствует. Таким образом, для прогностического моделирования и анализа исключений используются результаты этой стадии, которые гораздо более компактны, чем сами массивы исходных данных. При этом полученные конструкции могут быть либо “прозрачными” (интерпретируемыми), либо “черными ящиками”.
Две эти группы и входящие в них методы представлены на рисунке 9.
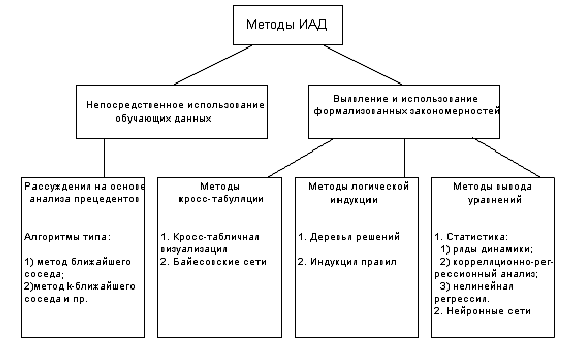
Рисунок 9. Классификация технологических методов ИАД
Оперативная аналитическая обработка и интеллектуальный анализ данных – две составные части процесса поддержки принятия решений. Но сегодня большинство систем OLAP заостряет внимание только на обеспечении доступа к многомерным данным, а большинство средств ИАД, работающих в сфере закономерностей, имеют дело с одномерными перспективами данных. Эти два вида анализа должны быть тесно объединены, то есть системы OLAP должны фокусироваться не только на доступе, но и на поиске закономерностей.
Ряд авторов вводят составной термин “OLAP Data Mining” (многомерный интеллектуальный анализ) для обозначения такого объединения и предлагают несколько вариантов интеграции двух технологий:
– возможность выполнения интеллектуального анализа должна обеспечиваться над любым результатом запроса к многомерному концептуальному представлению;
– подобно данным, извлеченным из хранилища, результаты интеллектуального анализа долж-ны представляться в специальной форме для последующего многомерного анализа;
– гибкий способ интеграции должен позволять автоматически активизировать однотипные механизмы интеллектуальной обработки над результатом каждого шага многомерного анализа.
В заключение приведем ряд рекомендаций по выбору инструментальных средств для построения OLAP-систем.
1. Удобство и богатство возможностей средств администрирования. Работа администратора баз данных является самой важной и самой сложной частью эксплуатации OLAP-системы. Поэтому следует обращать внимание на удобство интерфейса администрирования, а также на спектр его функциональных возможностей.
2. Гибкость настройки и наглядность форм демонстрации результатов. Интуитивность представления информации – главное достоинство OLAP. Насколько качественно и удобно формируются отчеты? Наглядны ли графические возможности? Налажены ли механизмы экспорта результатов в стандартные форматы?
3. Наличие методов постобработки данных, доступность средств интеллектуального анализа. Богаты ли аналитические возможности инструмента? Есть ли в нем элементы ИАД, и если есть, то какие преимущества они могут обеспечить при использовании?
4. Возможность обработки больших хранилищ данных с приемлемой производительностью. Если необходим планомерный непрерывный анализ большого хранилища данных организации, требуется выяснить объективные ограничения продукта с точки зрения предельных размеров исходных баз данных.
5. Возможность увязки OLAP-инструментария со всеми СУБД, используемыми в организации. Как показывает практика, интеграция разнородных продуктов в устойчиво работающую систему – один из наиболее важных вопросов, и его решение в ряде случаев может быть связано с большими проблемами. Необходимо разобраться, насколько просто и надежно можно интегрировать средства OLAP с существующими в организации СУБД.
В качестве примеров доступных на современных рынках систем OLAP и ИАД можно назвать следующие:
– продукт компании IBM называется А Data Warehouse Plus, где основой хранилищ данных является семейство СУБД DB2;
– система компании NCR называется Enterprise Information Factory;
– система Oracle Express Server компании Oracle;
– программный комплекс ИнфоВизор, разработанный в Ивановском государственном энерге-тическом университете и др.