База данных
Федеральное агентство по образованию
Кемеровский институт (филиал)
Государственного образовательного учреждения высшего профессионального образования
«Российский государственный
торгово-экономический университет»
Т.Ф. Лебедева
БАЗЫ ДАННЫХ
Учебное пособие
Кемерово
2006 г.
Содержание
Содержание. 4
Глава 1 Концепция баз данных. 6
1.1 Данные и ЭВМ... 6
1.2 Поколения СУБД и направления исследований. 8
1.3 Терминология в СУБД.. 10
1.4 Вопросы для самоконтроля к главе 1. 12
Глава 2 Модели данных. 12
2.1. Классификация моделей данных. 12
2.2 Основные особенности систем, основанных на инвертированных списках. 14
2.2.1 Структуры данных. 14
2.2.2 Манипулирование данными. 14
2.2.3 Ограничения целостности. 15
2.3 Иерархические модели. 15
2.3.1. Иерархические структуры данных. 15
2.4 Сетевые модели. 16
2.4.1 Сетевые структуры данных. 16
2.4.2 Манипулирование данными. 17
2.4.3 Ограничения целостности. 17
2.5 Физические модели организации баз данных. 17
2.5.1 Файловые структуры, используемые для хранения данных в БД.. 19
2.5.2 Модели страничной организации данных в современных БД.. 21
2.5.3 Этапы доступа к БД.. 22
2.6 Вопросы и упражнения для самоконтроля к главе 2. 24
Глава 3 Реляционная модель данных. 24
3.1 Базовые понятия реляционных баз данных. 24
3.1.1. Тип данных. 25
3.1.2. Домен. 25
3.1.3 Схема отношения, схема базы данных. 25
3.1.4 Кортеж, отношение, ключи. 25
3.1.5 Связи в реляционных базах данных. 27
3.2 Фундаментальные свойства отношений. 27
3.2.1 Отсутствие кортежей-дубликатов. 27
3.2.2 Отсутствие упорядоченности кортежей. 27
3.2.3 Отсутствие упорядоченности атрибутов. 28
3.2.4 Атомарность значений атрибутов. 28
3.3. Характеристика реляционной модели данных. 28
3.4 Трехзначная логика (3VL) 29
3.5 Реляционная алгебра. 30
3.6 Особенности операций реляционной алгебры.. 39
3.7 Реляционное исчисление. 40
3.7 Вопросы и упражнения для самоконтроля к главе 3. 42
Глава 4 Элементы языка SQL.. 42
4.1 История языка SQL.. 42
4.2 Структура языка SQL.. 44
4.3 Создание запроса с помощью оператора SELECT. 46
4.3.1 Создание простых запросов. 46
4.3.2. Агрегирование данных в запросах. 48
4.3.3 Формирование запросов на основе соединения таблиц. 50
4.3.4 Формирование структур вложенных запросов. 52
4.3.5 Объединение нескольких запросов в один. 54
4.3.6 Синтаксис оператора SELECT. 55
4.4 Операторы манипулирования данных. 56
4.4.1 Оператор удаления данных DELETE.. 56
4.4.2 Оператор вставки данных INSERT. 56
4.4.3 Оператор обновления данных UPDATE.. 57
4.5 Операторы определения объектов базы данных. 57
4.5.1 Операторы определения таблицы.. 57
4.5.2 Оператор определения представлений CREATE VIEW... 59
4.6 Операторы контроля данных, защиты и управления данными. 60
4.6.1 Операторы управления привилегиями. 60
4.6.2 Операторы управления транзакциями. 62
4.6.3 Проблемы параллельной работы транзакций. 64
4.7 Вопросы и упражнения для самоконтроля к главе 4. 65
Глава 5 Проектирование баз данных. 66
5.1 Проектирование реляционных БД с использованием принципов нормализации. 67
5.2 Проектирование реляционных БД с использованием семантических моделей. 72
5.2.1 Применение семантических моделей при проектировании. 72
5.2.2. Основные понятия модели Entity-Relationship. 74
5.2.3 Пример разработки простой ER-модели. 76
5.3 Практические рекомендации по проектированию БД.. 79
5.4 Вопросы и упражнения для самоконтроля к главе 5. 80
Глава 6 Функции СУБД и системы обработки транзакций. 81
6.1 Основные функции СУБД.. 81
6.2 Системы обработки транзакций. 84
6.2.1 OLTP-системы.. 84
6.2.2 OLAP -системы.. 84
6.2.3 Мониторы транзакций. 85
6.3 Архитектура СУБД.. 87
6.4 Вопросы и упражнения для самоконтроля по главе 6. 88
Глава 7 Технологии, модели и архитектура систем обработки данных. 88
7.2 Распределенная обработка данных. 92
7.2.1 Аспекты сетевого взаимодействия. 92
7.2.2 Технология распределенной БД (технология STAR) 96
7.2.3 Технология тиражирования данных. 97
7.3 Концепция активного сервера в модели DBS. 98
7.4 Вопросы и упражнения для самоконтроля к главе 7. 101
Литература. 101
Глава 1 Концепция баз данных
Данные и ЭВМ
Традиционно фиксация данных осуществляется с помощью конкретного средства общения, например, с помощью естественного языка на конкретном носителе… Нередко данные и интерпретация разделены. Например, «Расписание движения… Таблица 1.1 – Расписание движения самолетов Интерпретация Номер рейса Дни недели …Поколения СУБД и направления исследований
I. Поколение. Сетевые и иерархические системы БД, широко распространенные в 70-е годы, получили название - системы БД первого поколения. Это были… II. Поколение. В 80-е годы системы первого поколения были существенно… В нашей стране представление о реляционных СУБД у большинства программистов сложилось на основе опыта использования…Терминология в СУБД
База данных (БД) - именованная совокупность данных, отражающая состояние объектов и их отношений в рассматриваемой предметной области (ПО). Предметная область (ПО)– часть реального мира, подлежащая автоматизации с… Банк данных (БнД)– это система специальным образом организованных данных – баз данных, программных, технических,…Вопросы для самоконтроля к главе 1
- Что понимается под ведением данных?
- Можно ли использовать термины «база данных» и «банк данных» как эквивалентные?
- Какие функции по отношению к пользователю выполняет СУБД?
- Что включают требования надежности и безопасности БД?
- Чем характеризуются БД первого поколения?
Глава 2 Модели данных
Классификация моделей данных
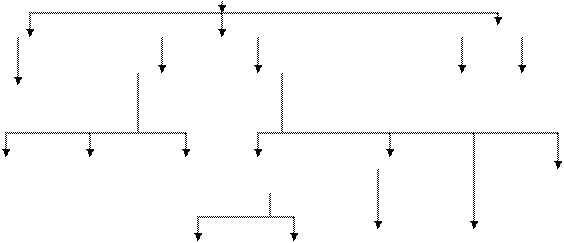
Модель данных - это совокупность структур данных, взаимосвязей и операций их обработки. На рис.2.1 представлена классификация моделей данных в соответствии с рассмотренной ранее трехуровневой архитектурой.
Инфологическая модель отображает реальный мир в некоторые понятные человеку концепции, полностью независимые от параметров среды хранения данных. Инфологическая модель отражает ПО в виде совокупности информационных объектов и их структурных связей. Существует множество подходов к построению таких моделей. Наиболее популярной из них оказалась модель «сущность-связь»(ER - Entity Relationship), которая будет рассмотрена в п.5.2. Инфологическая модель должна быть отображена в компьютеро-ориентированную даталогическую модель, «понятную» СУБД. В процессе развития теории и практического использования баз данных, а также средств вычислительной техники создавались СУБД, поддерживающие различные даталогические модели – документальные и фактографические.
Документальные модели соответствуют представлению о слабо структурированной информации, ориентированной на свободные форматы текста на естественном языке.
Модели, ориентированные на формат документа, связаны прежде всего со стандартным общим языком разметки - SGML, чаще используются HTML и XML
Тезаурусные модели основаны на принципе организации словарей и содержит определенные языковые конструкции и принципы их взаимодействия в заданной грамматике. Эти модели используются в системах - переводчиках, особенно в многоязыковых переводчиках.
Дескрипторные модели – самые простые из документальных моделей и широко использовались на ранних стадиях использования документальных баз данных. В этих моделях каждому документу соответствует дескриптор (описатель), имеющий жесткую структуру. Дескриптор описывал документ в соответствии с теми характеристиками, которые требуются для работы с документами в разрабатываемой БД. Например, для БД с описаниями патентов дескриптор содержал название области, к которой относился патент, номер, дату выдачи патента и еще ряд ключевых характеристик. Обработка информации в таких БД велась исключительно по дескрипторам, а не по самому текстовому описанию патента.
 Модели данных
Модели данных
Инфологические Даталогические Физические
модель документальные фактографические основанные основанные сущность-связь (ER) на файловых на странично- структурах сегментнойОсновные особенности систем, основанных на инвертированных списках
К числу наиболее известных и типичных представителей таких систем относятся Datacom/DB компании Applied Data Research, Inc. (ADR), ориентированная на компьютеры фирмы IBM, и Adabas компании Software AG.
Организация доступа к данным на основе инвертированных списков используется практически во всех современных реляционных СУБД, но в этих системах пользователи не имеют непосредственного доступа к инвертированным спискам (индексам).
Структуры данных
- строки таблиц упорядочены системой в некоторой физической последовательности; - физическая упорядоченность строк всех таблиц может определяться и для всей… - для каждой таблицы можно определить произвольное число ключей поиска, для которых строятся индексы. Эти индексы…Манипулирование данными
2. Операторы над адресуемыми записями Примеры операторов: LOCATE FIRST - найти первую запись таблицы T в…Ограничения целостности
Общие правила определения целостности БД отсутствуют. В некоторых системах поддерживаются ограничения уникальности значений некоторых полей, но в основном все возлагается на прикладную программу.
Иерархические модели
Типичным представителем (наиболее известным и распространенным) является Information Management System (IMS) фирмы IBM. Первая версия появилась в 1968 г.
Иерархические структуры данных
Иерархическая древовидная структура, ориентированная от корня (выделенная вершина или узел) определяется условиями: · иерархия начинается с корневого узла, который находится на первом уровне… · на нижних уровнях находятся порожденные (зависимые) узлы;Манипулирование данными
Примерами типичных операторов манипулирования иерархически организованными данными могут быть следующие операторы:
- найти указанное дерево БД;
- перейти от одного дерева к другому;
- перейти от одной записи к другой внутри дерева (например, от группы - к первому студенту);
- перейти от одной записи к другой в порядке обхода иерархии;
- вставить новую запись в указанную позицию;
- удалить текущую запись.
Ограничения целостности
Автоматически поддерживается целостность ссылок между предками и потомками. Основное правило: никакой потомок не может существовать без своего родителя.
Сетевые модели
Типичным представителем является Integrated Database Management System (IDMS) компании Cullinet Software, Inc. Архитектура системы основана на предложениях Data Base Task Group (DBTG) Комитета по языкам программирования (Conference on Data Systems Languages - CODASYL). Отчет DBTG был опубликован в 1971 г., а в 70-х годах появилось несколько систем, среди которых IDMS.
Сетевые структуры данных
Сетевая БД состоит из набора записей, соответствующих каждому экземпляру объекта предметной области, и набора связей между этими записями. Простой пример сетевой схемы БД приведен на рис.2.4. Для сетевых моделей… Циклом называется ситуация, в которой исходный узел является в то же время порожденным узлом.Манипулирование данными
Ограничения целостности
Достоинства ранних СУБД: развитые средства управления данными во внешней… Недостатки дореляционных СУБД: слишком сложно пользоваться; фактически необходимы знания о физической…Физические модели организации баз данных
Можно выделить следующие аспекты проблемы физического представления данных: I. Как найти нужную запись? Необходимо установить соответствие между… II. Каким образом организовать данные, чтобы их поиск был эффективным, а выборку можно было осуществить по…Файловые структуры, используемые для хранения данных в БД
Файлы с постоянной длиной записи, расположенные на устройствах прямого доступа (магнитные, оптические диски), являются файлами прямого доступа. В… Для файлов с постоянной длиной записи адрес размещения записи с номером NZ… BA+( NZ -1)*LZ+1,Модели страничной организации данных в современных БД
Хранение данных во внешней памяти в известных СУБД (Oracle, IBM DB2, Microsoft SQL Server, Sybase и Informix и др.) организовано очень похожим… Размер блока оказывает большое влияние на производительность базы данных — при… Пространством внешней памяти, отведенным администратором, СУБД управляет с помощью экстентов (extent), т.е.…Этапы доступа к БД
Опишем последовательность действий при доступе к БД (см. рис. 2.7): Сначала в СУБД определяется искомая запись, а затем для ее извлечения… С точки зрения СУБД база данных выглядит как набор записей, которые могут… ДД часто бывает компонентом ОС, с помощью которого выполняются все операции ввода/вывода, используя физические адреса…Вопросы и упражнения для самоконтроля к главе 2
Глава 3 Реляционная модель данныхБазовые понятия реляционных баз данных
Атрибут – это наименьшая поименованная единица данных, к которой СУБД может адресоваться непосредственно, и с помощью которой выполняется построение… Для начала покажем смысл этих понятий на примере отношения СОТРУДНИКИ,…Тип данных
Домен
Домен – допустимое потенциальное множество значений простого типа данных Понятие домена более специфично для баз данных, хотя и имеет некоторые аналогии с подтипами в некоторых языках программирования. В самом общем виде домен определяется заданием некоторого базового типа данных, к которому относятся элементы домена, и произвольного логического выражения, применяемого к элементу типа данных. Если вычисление этого логического выражения дает результат «истина», то элемент данных является элементом домена.
Например, домен «Имена» в нашем примере определен на базовом типе строк символов, но в число его значений могут входить только те строки, которые могут представлять имя (в частности, такие строки не могут начинаться с мягкого знака).
Следует отметить также семантическую нагрузку понятия домена: данные считаются сравнимыми только в том случае, когда они относятся к одному домену. В нашем примере значения доменов «Номера пропусков» и «Номера отделов» относятся к типу целых чисел, но не являются сравнимыми. Заметим, что в большинстве реляционных СУБД понятие домена не используется, хотя в Oracle V.7 оно уже поддерживается.
Схема отношения, схема базы данных
Схема отношения - это именованное множество пар {имя атрибута – имя домена (или типа, если понятие домена не поддерживается)}. Степень или "арность" схемы отношения - мощность этого множества. Степень отношения СОТРУДНИКИ равна четырем, то есть оно является 4-арным. Если все атрибуты одного отношения определены на разных доменах, осмысленно использовать для именования атрибутов имена соответствующих доменов (не забывая, конечно, о том, что это является всего лишь удобным способом именования и не устраняет различия между понятиями домена и атрибута).
Схема БД (в структурном смысле) - это набор именованных схем отношений
Кортеж, отношение, ключи
Отношение - это множество кортежей, соответствующих одной схеме отношения. Иногда, чтобы не путаться, говорят «отношение-схема» и… Однако в реляционных базах данных это не принято. Имя схемы отношения в таких… Обычным представлением отношения является таблица, заголовком которой является схема отношения, а строками - кортежи…Связи в реляционных базах данных
1. Один-к-одному. Одной записи таблицы А соответствует одна запись таблицы Б, и наоборот. Этот тип связи применяется достаточно редко. Единственный… 2. Один-ко-многим. Одной записи таблицы А (главной) соответствует несколько… 3. Многие-ко-многим. При этом типе связи многим записям из таблицы А может соответствовать много записей из таблицы Б…Фундаментальные свойства отношений
Остановимся теперь на четырех важных свойствах отношений, которые следуют из приведенных ранее определений.
Отсутствие кортежей-дубликатов
Из этого свойства вытекает наличие у каждого отношения так называемого первичного ключа - набора атрибутов, значения которых однозначно определяют…Отсутствие упорядоченности кортежей
Отсутствие упорядоченности атрибутов
Атомарность значений атрибутов
Характеристика реляционной модели данных
В структурной части реляционной модели данных фиксируется, что единственной структурой данных, используемой в реляционных БД, является… В манипуляционной части реляционной модели данных утверждаются два… В целостной части реляционной модели данных фиксируются два базовых требования целостности, которые должны…Трехзначная логика (3VL)
Таким образом, в ситуации, когда возможно появление неопределенных, неизвестных или неполных данных, разработчик имеет на выбор два варианта. Первый вариант состоит в том, чтобы не использовать null-значения, а вместо… Второй вариант состоит в использовании null-значений вместо неизвестных данных. За кажущейся естественностью такого…Реляционная алгебра
В реализациях конкретных реляционных СУБД сейчас не используется в чистом виде ни реляционная алгебра, ни реляционное исчисление. Фактическим… В данной главе будут рассмотрены основы реляционной алгебры. Реляционная алгебра представляет собой набор операторов, использующих отношения в качестве аргументов, и возвращающие…Особенности операций реляционной алгебры
Начнем с операции объединения (все, что будет говориться по поводу объединения, переносится на операции пересечения и взятия разности). Смысл… Все эти соображения приводят к появлению понятия совместимости отношений по… Если два отношения совместимы по объединению, то при обычном выполнении над ними операций объединения, пересечения и…Реляционное исчисление
Если бы для формулировки такого запроса использовалась реляционная алгебра, то мы получили бы алгебраическое выражение, которое читалось бы,… Мы четко сформулировали последовательность шагов выполнения запроса, каждый из… Во второй формулировке мы указали лишь характеристики результирующего отношения, но ничего не сказали о способе его…Вопросы и упражнения для самоконтроля к главе 3
2. Что такое степень отношения? 3. В чем отличие схемы отношения от отношения? 4. Можно ли считать любую прямоугольную таблицу данных отношением?История языка SQL
Разрабатываемые в начале 80-х языки запросов можно отнести к двум классам: 1. Алгебраические языки, позволяющие выражать запросы средствами… 2. Языки исчисления предикатов представляют собой набор правил для записи выражения, определяющего новое отношение из…Структура языка SQL
DDL (Data Definition Language) - операторы определения объектов базы данных: CREATE SCHEMA - создать схему базы данных; DROP SHEMA - удалить… DML (Data Manipulation Language) - операторы манипулирования данными: … DCL (Data Control Language) - операторы контроля данных, защиты и управления данными: CREATE ASSERTION - создать …Создание запроса с помощью оператора SELECT
Создание простых запросов
Оператор SELECT всегда выполняется над некоторыми таблицами, входящими в базу данных. Результатом выполнения оператора SELECT всегда является… Замечание. Каждый оператор интерактивного SQL представляет собой одну команду,… Рассмотрим сначала простые конструкции оператора SELECT, постепенно усложняя его запись:Агрегирование данных в запросах
COUNT - число значений в столбце; SUM - сумма значений в столбце; AVG - среднее значение в столбце;Формирование запросов на основе соединения таблиц
Результат запроса: cname cname city Хофман Пил ЛондонФормирование структур вложенных запросов
Очень удобным средством, позволяющим формулировать запросы более понятным образом, является возможность использования подзапросов, вложенных в… Подзапрос - это запрос, который может входить в предикаты условия выборки… Существуют простые и коррелированные (соотнесенные) вложенные подзапросы. Они включаются в WHERE (HAVING) фразу с…Простые подзапросы
Замечание. Результат выполнения запроса будет эквивалентен результату следующей последовательности действий: выполнить один раз вложенный … Замечание. При использовании подзапросов необходимо убедиться, что подзапрос… Любой подзапрос, использующий агрегатную функцию без предложения GROUP BY, будет возвращать одиночное значение для…Объединение нескольких запросов в один
Синтаксис оператора SELECT
Приведем общий синтаксис оператора SELECT:SELECT * | { [ DISTINCT | ALL] <список выбора >,….} FROM { < имя_таблицы> [ < псевдоним > ] }.,.. [ WHERE <предикат>] [ GROUP BY <имя_столбца>.,..] [ HAVING <предикат>] [ ORDER BY <имя_столбца>.,. | <номер_столбца>.,..] [ { UNION [ALL] SELECT * | { [DISTINCT | ALL] < < выражение >.,..}FROM .] } ] ...;
Элементы, используемые в команде SELECT:
< список выбора > - выражения, включающее имена столбцов, функции, знаки операций
<предикат>::=< выражение1 > < оператор> < выражение2> | [NOT] EXISTS< выражение2 >
< оператор> ::= > | < | >= | <= | <> | = | IN | LIKE | BETWEEN …AND | OR | AND | NOT
< выражение2 >::= < выражение1> | [ANY | SOME | ALL ] <подзапрос>
<подзапрос>::= (SELECT * | { [ DISTINCT | ALL] < выражение >,….} FROM { < имя_таблицы> [ < псевдоним > ] }.,.. [ WHERE <предикат>] …)
Операторы манипулирования данных
Модификация данных может выполняться с помощью операторов DELETE (удалить), INSERT (вставить) и UPDATE (обновить). Подобно оператору SELECT они могут оперировать как базовыми таблицами, так и представлениями. Однако по ряду причин не все представления являются обновляемыми.
Оператор удаления данных DELETE
Оператор DELETE имеет формат:
DELETE FROM <базовая таблица | представление> [WHERE <предикат>];и позволяет удалить содержимое всех строк указанной таблицы (при отсутствии WHERE фразы) или тех ее строк, которые выделяются WHERE фразой.
Пример 4.42 Удалить все содержимое таблицы Продавцы:
DELETE FROM Продавцы;
Теперь, когда таблица пуста, ее можно окончательно удалить командой DROP TABLE. Обычно, нужно удалить только некоторые определенные строки из таблицы. Чтобы определить, какие строки будут удалены, используется предикат, так же как и для запросов.
Пример 4.43 Удалить продавца Аксельрода из таблицы Продавцы:
DELETE FROM Продавцы WHERE snum = 1003;
Замечание. Рекомендуется сначала выполнить оператор SELECT, имеющий такое же предложение WHERE, чтобы убедиться те ли строки будем удалять.
Пример 4.44 Если закрыто ведомство в Лондоне, то чтобы удалить всех заказчиков назначенных, к продавцам в Лондоне, используем следующий оператор: DELETE FROM Заказчики WHERE snum = ANY ( SELECT snum FROM Продавцы WHERE city = 'Лондон' ); Эта команда удалит из таблицы Заказчики строки с заказчиками Хофман и Клеменс(назначенных для Пила), и Перера (назначенного к Мотика).Оператор вставки данных INSERT
Оператор INSERT имеет один из следующих форматов:
INSERT INTO <базовая таблица | представление> [(<столбец> [,<столбец>] ...)]VALUES (<константа>|<переменная> [,<константа>| <переменная>] ...);или
INSERTINTO <базовая таблица | представление> [(<столбец> [,<столбец>] ...)] <подзапрос>;В первом формате в таблицу вставляется строка со значениями полей, указанными в перечне фразы VALUES (значения), причем i-е значение соответствует i-му столбцу в списке столбцов (столбцы, не указанные в списке, заполняются NULL-значениями). Если в списке VALUES фразы указаны все столбцы модифицируемой таблицы и порядок их перечисления соответствует порядку столбцов в описании таблицы, то список столбцов в предложении INTO можно опустить.
Пример 4.45 Добавить нового продавца:
INSERT INTO Продавцы VALUES (1009, 'Вильсон', 'Лондон', 0.12);
Замечание. Команды DML не производят никакого вывода, но СУБД должна дать некоторое подтверждение того, что данные были использованы. Имя таблицы (в нашем случае - Продавцы) должно быть предварительно определено в команде CREATE TABLE (см. п.4.5 ), а каждое значение, заданное в предложении значений VALUES, должно совпадать с типом данных столбца, в который оно вставляется.
Во втором формате сначала выполняется подзапрос, т.е. по предложению SELECT в памяти формируется рабочая таблица, а потом строки рабочей таблицы загружаются в модифицируемую таблицу. При этом i-й столбец рабочей таблицы (i-й элемент списка выбора SELECT) соответствует i-му столбцу в списке столбцов модифицируемой таблицы. Здесь также при выполнении указанных выше условий может быть опущен список столбцов фразы INTO.
Можно также использовать команду INSERT, чтобы выбирать значения из одной таблицы и помещать их в другую. Чтобы сделать это, вы просто заменяете предложение VALUES (из предыдущего примера) на соответствующий запрос:
Пример 4.46 INSERT INTO Лондон_1 SELECT * FROM Продавцы WHERE city = 'Лондон';
Здесь выбираются все значения, произведенные запросом - все строки из таблицы Продавцы со значениями city = ‘Лондон’ - и помещаются в таблицу, называемую Лондон_1. Эта таблица должна отвечать следующим условиям:
· она должна уже быть создана командой CREATE TABLE.;
· она должна иметь четыре столбца, которые совпадают с таблицей Продавцы по типу данных.
Оператор обновления данных UPDATE
Оператор UPDATE имеет формат:
UPDATE <базовая таблица | представление>SET <столбец>= <значение> [,<столбец>= <значение>] ...[WHERE <предикат>];где <значение>::=<столбец> |< выражение> | <константа> | <переменная>
и может включать столбцы лишь из обновляемой таблицы, т.е. значение одного из столбцов модифицируемой таблицы может заменяться на значение ее другого столбца или выражения, содержащего значения нескольких ее столбцов, включая изменяемый.
При отсутствии WHERE фразы обновляются значения указанных столбцов во всех строках модифицируемой таблицы. WHERE фраза позволяет сократить число обновляемых строк, указывая условия их отбора.
Пример 4.47 Предположим, что продавец Мотика ушел на пенсию, и необходимо переназначить его номер новому продавцу:
UPDATE Продавцы SET sname = 'Гибсон', city = 'Бостон', comm = .10 WHERE snum = 1004;
Эта команда передаст новому продавцу Гибсону, всех текущих заказчиков бывшего продавца Мотика и их порядки.
Пример 4.48 Можно, используя коррелированный подзапрос, увеличить комиссионные всех продавцов, которые были назначены по крайней мере двум заказчикам: UPDATE Продавцы SET comm = comm + .01 WHERE 2 < = (SELECT COUNT (cnum) FROM Заказчики WHERE Заказчики.snum = Продавцы.snum); Теперь продавцы Пил и Серенс, имеющие нескольких заказчиков, получат повышение своих комиссионных.Операторы определения объектов базы данных
Операторы определения таблицы
Базовые таблицы описываются в SQL с помощью предложения CREATE TABLE (создать таблицу). Рассмотрим синтаксис этого предложения:
CREATE TABLE <имя_таблицы> (<элемент_таблицы> [,<элемент_таблицы >...] [ограничения_целостности_таблицы]);< элемент_таблицы > ::= <определение_столбца>< определение_столбца > ::= <имя_столбца> <тип_данных> [DEFAULT <значение>] [<ограничения_ целостности_столбца>...]< ограничения_ целостности_столбца > ::= NULL | NOT NULL [UNIQUE <спецификация>] | REFERENCES <спецификация> | CHECK (<проверочное_ограничение>)|PRIMARY KEY|FOREIGN KEYКроме имени таблицы, в операторе специфицируется список элементов таблицы, каждый из которых служит либо для определения столбца, либо для определения ограничения целостности определяемой таблицы. Требуется наличие хотя бы одного определения столбца. Для столбца задается имя и его тип данных, а также два необязательных раздела: раздел значения столбца по умолчанию и раздел ограничений целостности столбца.
Ограничение – это свойство, назначенное столбцу или таблице, которое запрещает ввод в указанный столбец (или столбцы) недопустимых значений. Основные виды ограничений: NULL, NOT NULL, DEFAULT, PRIMARY KEY, FOREIGN KEY, REFERENCES, CHECK, UNIQUE. Ограничения могут быть без имени или с именем, тогда перед ограничением вставляется слово CONSTRAINT <имя_ограничения>. Наличие имени ограничения позволяет ссылаться на него в операторе изменения таблицы, например:
ALTER TABLE Tab1 ADD CONSTRAINT col1 CHECK (col1 BETWEEN 0 AND 1);
В разделе значения по умолчанию DEFAULT указывается значение, которое должно быть помещено в строку, заносимую в данную таблицу, если значение данного столбца явно не указано. Значение по умолчанию может быть указано в виде литеральной константы с типом, соответствующим типу столбца, или путем задания ключевого слова NULL, означающего, что значением по умолчанию является неопределенное значение. Если значение столбца по умолчанию не специфицировано, и в разделе ограничений целостности столбца указано NOT NULL, то попытка занести в таблицу строку с NULL-значением данного столбца приведет к ошибке.
Указание в разделе ограничений целостности NOT NULL приводит к неявному порождению проверочного ограничения целостности для всей таблицы «CHECK (C IS NOT NULL)» (где C - имя данного столбца). Если ограничение NOT NULL не указано, и раздел умолчаний отсутствует, то неявно порождается раздел умолчаний DEFAULT NULL. Если указана спецификация уникальности, то порождается соответствующая спецификация уникальности для таблицы.
Если в разделе ограничений целостности указано ограничение по ссылкам данного столбца (REFERENCES <спецификация>), то порождается соответствующее определение ограничения по ссылкам для таблицы:
FOREIGN KEY(C) REFERENCES <спецификация> Пример 4.49 Создать таблицу: CREATE TABLE Заказчики ( cnum integer NOT NULL PRIMARY KEY, cname char (10) NOT NULL, city char (10) DEFAULT = 'Лондон', rating integer, snum integer NOT NULL, UNIQUE (cnum, snum));UNIQUE (cnum, snum) – это ограничение целостности таблицы, утверждающее, что комбинация номеров должна быть уникальной, т.е. у каждого заказчика только один продавец.Пример 4.50 В следующем примере для задания составного первичного ключа используется ограничение целостности таблицы PRIMARY KEY для пар: CREATE TABLE Имена ( firstname char (10) NOT NULL, lastname char (10) NOT NULL city char (10), PRIMARY KEY ( firstname, lastname ));Пример 4. 51 В данном примере использовано ограничение по ссылкам:CREATE TABLE Продавцы (snum integer NOT NULL PRIMARY KEY, sname char(10) NOT NULL, city char(10), comm decimal, cnum integer REFERENCES Customers);Существующую базовую таблицу можно в любой момент уничтожить с помощью предложения:
DROP TABLE <имя_таблицы>;по которому удаляется описание таблицы, ее данные, связанные с ней представления и индексы, построенные для столбцов таблицы.
В SQL существует также предложение ALTER TABLE (изменить таблицу), которое позволяет добавить справа к таблице новый столбец, изменить или удалить столбец, т.е. модифицировать описание таблицы.
Для построения индекса в SQL существует предложение CREATE INDEX (создать индекс), имеющее формат:CREATE [UNIQUE] INDEX <имя_индекса> ON < имя_таблицы >
(<столбец >[[ASC] | DESC] [, <столбец> [[ASC] | DESC]] ...);
где UNIQUE (уникальный) указывает, что никаким двум строкам в индексируемой базовой таблице не позволяется принимать одно и то же значение для индексируемого столбца (или комбинации столбцов) в одно и то же время.
Для удаления индекса используется предложение:
DROP INDEX <имя_индекса>;
Замечание. Так как индексы могут создаваться или уничтожаться в любое время, то перед выполнением запросов целесообразно строить индексы лишь для тех столбцов, которые используются в WHERE и ORDER BY фразах запроса, а перед модификацией большого числа строк таблиц с индексированными столбцами эти индексы следует уничтожить.
Оператор определения представлений CREATE VIEW
Представление - это виртуальная таблица, которая сама по себе не существует, но для пользователя выглядит таким образом, как будто она существует. Представление не поддерживаются его собственными физическими хранимыми данными. Вместо этого в каталоге таблиц хранится определение, оговаривающее, из каких столбцов и строк других таблиц оно должно быть сформировано. Механизм представлений (view) является мощным средством языка SQL, позволяющим скрыть реальную структуру БД от некоторых пользователей за счет определения представления БД, которое реально является некоторым хранимым в БД запросом с именованными столбцами, а для пользователя ничем не отличается от базовой таблицы БД (с учетом технических ограничений). Любая реализация должна гарантировать, что состояние представляемой таблицы точно соответствует состоянию базовых таблиц, на которых определено представление. Синтаксис предложения CREATE VIEW имеет вид:
CREATE VIEW <имя_представления> [(<столбец>[,<столбец>] ...)] AS подзапрос [WITH CHECK OPTION];где подзапрос, следующий за AS и являющийся определением данного представления, не исполняется, а просто сохраняется в каталоге;
необязательная фраза «WITH CHECK OPTION» (с опцией проверки) указывает, что для операций INSERT и UPDATE над этим представлением должна осуществляться проверка, обеспечивающая удовлетворение WHERE фразы подзапроса;
список имен столбцов должен быть обязательно определен лишь в тех случаях, когда:
а) хотя бы один из столбцов подзапроса не имеет имени (создается с помощью выражения, SQL-функции или константы);
б) два или более столбцов подзапроса имеют одно и то же имя;
если же список отсутствует, то представление наследует имена столбцов из подзапроса.
Пример 4.52 Например, создадим представление Лондон_продавцы, которое может рассматриваться пользователем как новая таблица в базе данных:
CREATE VIEW Лондон_продавцы AS SELECT * FROM Продавцы WHERE city = 'Лондон';Пример 4. 53 Следующее представление содержит данные о количестве заказчиков с каждым значением рейтинга: CREATE VIEW Оценка (rating, number) AS SELECT rating, COUNT (*) FROM Заказчики GROUP BY rating;Пример 4. 54 Предположим, что компания предусматривает премию для тех продавцов, которые имеют заказчика с самым высоким порядком для любой указанной даты. Можно проследить эту информацию с помощью представления: CREATE VIEW Максимум AS SELECT b.odate, a.snum, a.sname, FROM Продавцы a, Порядки b WHERE a.snum = b.snum AND b.amt = (SELECT MAX (amt) FROM Порядки c WHERE c.odate = b.odate);Представляемая таблица V является модифицируемой (т.е. по отношению к V можно использовать операторы DELETE, UPDATE, INSERT) в том и только в том случае, если выполняются следующие условия для спецификации запроса:
- в списке выборки не указано ключевое слово DISTINCT;
- каждое арифметическое выражение в списке выборки представляет собой одну спецификацию столбца, и спецификация одного столбца не появляется более одного раза (не должно быть агрегатных функций и выражений);
- в разделе FROM указана только одна таблица, являющаяся либо базовой таблицей, либо модифицируемым представлением;
- в условии выборки раздела WHERE не используются подзапросы;
- отсутствуют разделы GROUP BY и HAVING.
Таким образом, могут быть модифицируемые представления (пример 4.52) и представления только для чтения, которые разрешается использовать только в команде SELECT (примеры 4.53, 4.54). С помощью представлений можно создать библиотеку сложных запросов и работать с сохраненными представлением как с таблицами.
Возможна ситуация, когда в модифицируемое представление добавляются данные, которые «проглатываются» (swallowed) в базовой таблице.Пример 4. 55 Рассмотрим такое представление: CREATE VIEW Рейтинг AS SELECT cnum, rating FROM Заказчики WHERE rating = 300; Это - представление модифицируемое. Оно просто ограничивает доступ к определенным строкам и столбцам в таблице. Предположим, что вы вставляете (INSERT) следующую строку: INSERT INTO Рейтинг VALUES (2018, 200); Это - допустимая команда INSERT в этом представлении. Строка будет вставлена с помощью представления Рейтинг в таблицу Заказчики. Однако когда она появится там, она исчезнет из представления, поскольку значение оценки не равно 300. Это - обычная проблема. Пользователь не сможет понять, почему введя строку, он не может ее увидеть, и будет неспособен при этом удалить ее. Вы можете быть гарантированы от модификаций такого типа с помощью предложения WITH CHECK OPTION в определение представления. Пример 4. 56 Добавим это предложение в команду примера 4.55: CREATE VIEW Рейтинг AS SELECT cnum, rating FROM Заказчики WHERE rating = 300 WITH CHECK OPTION;Вышеупомянутая вставка будет отклонена.Замечание. Требование WITH CHECK OPTION в определении представления имеет смысл только в случае определения модифицируемой представляемой таблицы.
Для удаления представления используется оператор:
DROP VIEW <имя_представления>;
Операторы контроля данных, защиты и управления данными
Операторы управления привилегиями
В контексте баз данных термин «безопасность» означает защиту данных от несанкционированного раскрытия, изменения или уничтожения. SQL позволяет индивидуально защищать как целые таблицы, так и отдельные их поля. Для этого имеются две более или менее независимые возможности:
· механизм представлений, рассмотренный ранее и используемый для скрытия засекреченных данных от пользователей, не обладающих правом доступа;
· подсистема санкционирования доступа, позволяющая предоставить указанным пользователям определенные привилегии на доступ к данным и дать им возможность избирательно и динамически передавать часть выделенных привилегий другим пользователям, отменяя впоследствии эти привилегии, если потребуется.
Каждый пользователь в среде SQL , имеет специальное идентификационное имя или номер. Команда, посланная в базе данных, ассоциируется с определенным пользователем, или иначе, специальным идентификатором доступа. Команда интерпретируется и разрешается (или запрещается) на основе информации, связанной с идентификатором (ID) доступа пользователя, подавшего команду.Обычно при установке СУБД в нее вводится какой-то идентификатор, который должен далее рассматриваться как идентификатор наиболее привилегированного пользователя - системного администратора. Каждый, кто может войти в систему с этим ID (и может выдержать тесты на достоверность), будет считаться системным администратором до выхода из системы. Системный администратор может создавать БД и имеет все привилегии на их использование. Эти привилегии или их часть могут предоставляться другим пользователям (пользователям с другими ID). В свою очередь, пользователи, получившие привилегии от системного администратора, могут передать их (или их часть) другим пользователям, которые могут их передать следующим и т.д.
Определение привилегий производится в следующем синтаксисе:
GRANT <привилегии> ON < объект> TO < субъект >
[{,<субъект >}...] [WITH GRANT OPTION];
<привилегии>::= ALL [PRIVILEGES] | <действие> [{,<действие> }...]
<действие>::= SELECT | INSERT | DELETE | UPDATE [(<список столбцов>)]
| REFERENCES [(<список столбцов>)]
[(<список столбцов>)]::= <имя_столбца> [{,<имя_столбца> }...]
<субъект> ::= PUBLIC | <идентификатор_доступа_пользователя>
<привилегии> - список, состоящий из одной или нескольких привилегий, разделенных запятыми, либо фраза ALL PRIVILEGES (все привилегии); <объект> - имя и, если надо, тип объекта (база данных, таблица, представление, индекс и т.п.); <субъекты> - список, включающий один или более идентификаторов доступа, разделенных запятыми, либо специальное ключевое слово PUBLIC (общедоступный).
Замечание. Привилегией REFERENCES по отношению к указанным столбцам таблицы T1 необходимо обладать, чтобы иметь возможность при определении таблицы T определить ограничение по ссылкам между этой таблицей и существующей к этому моменту таблицей T1.
Замечание. Когда вы предоставляете привилегии для публикации, все пользователи автоматически их получают. Наиболее часто, это применяется для привилегии SELECT в определенных базовых таблицах или представлениях, которые вы хотите сделать доступными для любого пользователя.
Пример 4. 57 GRANT SELECT, INSERT ON Порядки TO Адриан, Диана;
Пример 4. 58 GRANT ALL ON Заказчики TO Стефан;Пример 4. 59 GRANT SELECT ON Orders TO PUBLIC; Пользователь должен иметь возможность передать привилегии (или их часть) другим пользователям. Обычно это делается в системах, где один или более пользователей создают несколько (или все) базовые таблицы в БД, а затем передают ответственность за них тем, кто будет фактически с ними работать. SQL позволяет делать это с помощью предложения WITH GRANT OPTION. Пример 4. 60 Если Диана хотела бы, чтобы Адриан имел право предоставлять привилегию SELECT в таблице Заказчики другим пользователям, она дала бы ему привилегию SELECT с использованием предложения WITH GRANT OPTION: GRANT SELECT ON Заказчики TO Адриан WITH GRANT OPTION; После выполнения этой команды Адриан получил право передавать привилегию SELECT третьим лицамЕсли пользователь USER_1 предоставил какие-либо привилегии другому пользователю USER_2, то он может впоследствии отменить все или некоторые из этих привилегий. Отмена осуществляется с помощью предложения REVOKE (отменить), общий формат которого очень похож на формат предложения GRANT:
REVOKE <привилегии> ON < объект> FROM < субъект > [{,<субъект >}...];
Пример 4. 61 REVOKE INSERT, DELETE ON Заказчики FROM Адриан, Стефан.
Операторы управления транзакциями
Транзакция - это неделимая, с точки зрения воздействия на СУБД, последовательность операций манипулирования данными. Для пользователя транзакция выполняется по принципу «все или ничего», т.е. либо транзакция выполняется целиком и переводит базу данных из одного целостного состояния в другое целостное состояние, либо, если по каким-либо причинам, одно из действий транзакции невыполнимо, или произошло какое-либо нарушение работы системы, БД возвращается в исходное состояние, которое было до начала транзакции (происходит откат транзакции). С этой точки зрения, транзакции важны как в многопользовательских, так и в однопользовательских системах. В однопользовательских системах транзакции - это логические единицы работы, после выполнения которых БД остается в целостном состоянии. Транзакции также являются единицами восстановления данных после сбоев - восстанавливаясь, система ликвидирует следы транзакций, не успевших успешно завершиться в результате программного или аппаратного сбоя. Эти два свойства транзакций определяют атомарность (неделимость) транзакции. В многопользовательских системах, кроме того, транзакции служат для обеспечения изолированной работы отдельных пользователей - пользователям, одновременно работающим с одной базой данных, кажется, что они работают как бы в однопользовательской системе и не мешают друг другу.
Транзакция или логическая единица работы БД, - это в общем случае последовательность ряда таких операций, которые преобразуют некоторое непротиворечивое состояние базы данных в другое непротиворечивое состояние, но не гарантируют сохранения непротиворечивости во все промежуточные моменты времени.
Транзакция обладает четырьмя важными свойствами, известными как свойства АСИД:
- (А) Атомарность. Транзакция выполняется как атомарная операция - либо выполняется вся транзакция целиком, либо она целиком не выполняется.
- (С) Согласованность. Транзакция переводит базу данных из одного согласованного (целостного) состояния в другое согласованное (целостное) состояние. Внутри транзакции согласованность базы данных может нарушаться.
- (И) Изоляция. Транзакции разных пользователей не должны мешать друг другу (например, как если бы они выполнялись строго по очереди).
- (Д) Долговечность. Если транзакция выполнена, то результаты ее работы должны сохраниться в базе данных, даже если в следующий момент произойдет сбой системы.
Транзакция обычно начинается автоматически с момента присоединения пользователя к СУБД и продолжается до тех пор, пока не произойдет одно из следующих событий:
- подана команда COMMIT (зафиксировать транзакцию);
- подана команда ROLLBACK (откатить транзакцию);
- произошло отсоединение пользователя от СУБД;
- произошел сбой системы.
Свойства АСИД транзакций не всегда выполняются в полном объеме. Особенно это относится к свойству И (изоляция). В идеале, транзакции разных пользователей не должны мешать друг другу, т.е. они должны выполняться так, чтобы у пользователя создавалась иллюзия, что он в системе один. Простейший способ обеспечить абсолютную изолированность состоит в том, чтобы выстроить транзакции в очередь и выполнять их строго одну за другой. Очевидно, при этом теряется эффективность работы системы. Поэтому реально одновременно выполняется несколько транзакций (смесь транзакций). Различается несколько уровней изоляции транзакций. На низшем уровне изоляции транзакции могут реально мешать друг другу, на высшем - они полностью изолированы. За большую изоляцию транзакций приходится платить большими накладными расходами системы и замедлением работы. Пользователи или администратор системы могут по своему усмотрению задавать различные уровни изоляции всех или отдельных транзакций. Более подробно изоляция транзакций рассматривается в п. 4.6.3.
Свойство Д (долговечность) также не является абсолютными свойством, т.к. некоторые системы допускают вложенные транзакции. Если транзакция Б запущена внутри транзакции А, и для транзакции Б подана команда COMMIT, то фиксация данных транзакции Б является условной, т.к. внешняя транзакция А может откатиться. Результаты работы внутренней транзакции Б будут окончательно зафиксированы только, если будет зафиксирована внешняя транзакция А.
Свойство (С) - согласованность транзакций определяется наличием понятия согласованности базы данных. База данных находится в согласованном (целостном) состоянии, если выполнены (удовлетворены) все ограничения целостности, определенные для базы данных.
Ограничение целостности (бизнес-правило) - это некоторое утверждение, которое может быть истинным или ложным в зависимости от состояния базы данных.
Примерами ограничений целостности могут служить следующие утверждения:
Пример 4.62. У каждого заказчика только один продавец.
Пример 4.63. Каждый сотрудник имеет уникальный табельный номер.
Пример 4.64 Сотрудник обязан числиться в только одном отделе.
Пример 4.65. Сумма денег накладной обязана равняться сумме произведений цен товаров на количество товаров для всех товаров, входящих в накладную.
Как видно из этих примеров, некоторые из ограничений целостности являются ограничениями реляционной модели данных (см. гл. 3). Пример 4.63 представляет ограничение, реализующее целостность сущности. Примеры 4.62, 4.64 представляют ограничения, реализующие ссылочную целостность. Другие ограничения являются достаточно произвольными утверждениями, утверждениями связанными с правилами в конкретной предметной области (пример 4.65). Любое ограничение целостности является семантическим понятием, т.е. появляется как следствие определенных свойств объектов предметной области и/или их взаимосвязей.
Вместе с понятием целостности базы данных возникает понятие реакции системы на попытку нарушения целостности. Система должна не только проверять, не нарушаются ли ограничения в ходе выполнения различных операций, но и должным образом реагировать, если операция приводит к нарушению целостности. Имеется два типа реакции на попытку нарушения целостности:
- Отказ выполнить "незаконную" операцию.
- Выполнение компенсирующих действий.
Работа системы по проверке ограничений изображена на рисунке 4.1.
Каждая система обладает своими средствами поддержки ограничений целостности. Ограничения целостности классифицируются несколькими способами:
- по способам реализации;
- по времени проверки;
- по области действия.
По способам реализации различают:
- декларативную поддержку ограничений целостности - средствами языка определения данных (DDL);
- процедурную поддержку ограничений целостности - посредством триггеров и хранимых процедур.
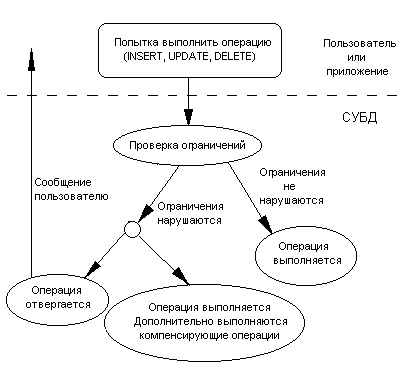
Рисунок 4.1 Работа системы по проверке ограничений
По времени проверки ограничения делятся на:
- немедленно проверяемые ограничения;
- ограничения с отложенной проверкой.
По области действия ограничения делятся на:
- ограничения домена;
- ограничения атрибута;
- ограничения кортежа;
- ограничения отношения;
- ограничения базы данных.
Стандарт языка SQL поддерживает только декларативные ограничения целостности, реализуемые как:
- ограничения домена;
- ограничения, входящие в определение таблицы;
- ограничения, хранящиеся в базе данных в виде независимых утверждений (assertion).
Проверка ограничений допускается как после выполнения каждого оператора, могущего нарушить ограничение, так и в конце транзакции. Во время выполнения транзакции можно изменить режим проверки ограничения.
Стандарт SQL не предусматривает процедурных ограничений целостности, реализуемых при помощи триггеров и хранимых процедур. В стандарте SQL 92 отсутствует понятие «триггер», хотя триггеры имеются во всех промышленных СУБД SQL-типа. Таким образом, реализация ограничений средствами конкретной СУБД обладает большей гибкостью, нежели с использованием исключительно стандартных средств SQL.
Проблемы параллельной работы транзакций
Имеются три основные следствия проблемы параллелизма: проблема потери результатов обновления; проблема незафиксированной зависимости… Решение проблем параллелизма состоит в нахождении такой стратегии запуска… Под сериализаций параллельно выполняющихся транзакций понимается такой порядок планирования их работы, при котором…Вопросы и упражнения для самоконтроля к главе 4
2. Используется ли в какой-либо СУБД язык SQL в том виде, как он описан в стандарте? 3. Что означает символ «*» в операторе SELECT? 4. Как организуется вывод данных с группированием по какому-либо полю (столбцу) таблицы?Проектирование реляционных БД с использованием принципов нормализации
В теории реляционных баз данных обычно выделяется следующая последовательность нормальных форм: первая нормальная форма (1NF); вторая… Основные свойства нормальных форм: каждая следующая нормальная форма в… В основе процесса проектирования лежит метод нормализации, декомпозиция отношения, находящегося в предыдущей…Проектирование реляционных БД с использованием семантических моделей
Применение семантических моделей при проектировании
При этом проявляется ограниченность реляционной модели данных в следующих аспектах: · Модель не предоставляет достаточных средств для представления смысла… · Для многих приложений трудно моделировать предметную область на основе плоских таблиц. В ряде случаев на самой…Основные понятия модели Entity-Relationship
Опишем работу с ER-диаграммами близко к нотации Баркера, как довольно легкой в понимании основных идей.
Определение 1. Сущность - это класс однотипных объектов, информация о которых должна быть учтена в модели.
Каждая сущность должна иметь наименование, выраженное существительным в единственном числе. Примерами сущностей могут быть такие классы объектов как «Поставщик», «Сотрудник», «Накладная».
Каждая сущность в модели изображается в виде прямоугольника с наименованием (рис.5.1).

Рисунок 5.1 Пример сущности
Определение 2. Экземпляр сущности - это конкретный представитель данной сущности.
Например, представителем сущности «Сотрудник» может быть «Сотрудник Иванов».
Экземпляры сущностей должны быть различимы, т.е. сущности должны иметь некоторые свойства, уникальные для каждого экземпляра этой сущности.
Определение 3. Атрибут сущности - это именованная характеристика, являющаяся некоторым свойством сущности.
Наименование атрибута должно быть выражено существительным в единственном числе (возможно, с характеризующими прилагательными). Примерами атрибутов сущности «Сотрудник» могут быть такие атрибуты как «Табельный номер», «Фамилия», «Имя», «Отчество», «Должность», «Зарплата» и т.п.
Атрибуты изображаются в пределах прямоугольника, определяющего сущность (рис.5.2).

Рисунок 5.2 Пример сущности с указанием атрибутов
Определение 4. Ключ сущности - это неизбыточный набор атрибутов, значения которых в совокупности являются уникальными для каждого экземпляра сущности. Неизбыточность заключается в том, что удаление любого атрибута из ключа нарушается его уникальность.
Сущность может иметь несколько различных ключей.
Ключевые атрибуты изображаются на диаграмме подчеркиванием (рис.5.3).

Рисунок 5.3 Пример сущности с указанием ключа
Определение 5. Связь - это графически изображаемая ассоциация, устанавливаемая между двумя сущностями. Эта ассоциация всегда является бинарной и может существовать между двумя разными сущностями или между сущностью и ей же самой (рекурсивная связь).
Связи позволяют по одной сущности находить другие сущности, связанные с нею.
Например, связи между сущностями могут выражаться следующими фразами – «СОТРУДНИК может иметь несколько ДЕТЕЙ», «каждый СОТРУДНИК обязан числиться ровно в одном ОТДЕЛЕ».
Графически связь изображается линией, соединяющей две сущности (рис.5.4).

Рисунок 5.4 Пример связи двух сущностей
Каждая связь имеет два конца и одно или два наименования. Наименование обычно выражается в неопределенной глагольной форме: "иметь", "принадлежать" и т.п. Каждое из наименований относится к своему концу связи. Иногда наименования не пишутся ввиду их очевидности.
Каждая связь может иметь один из следующих типов связи (рис.5.5.:
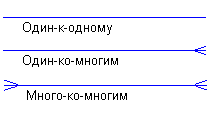
Рисунок 5.5 Графическое изображение типов связей
Связь типа один-к-одному означает, что один экземпляр первой сущности (левой) связан с одним экземпляром второй сущности (правой). Связь один-к-одному чаще всего свидетельствует о том, что на самом деле мы имеем всего одну сущность, неправильно разделенную на две.
Связь типа один-ко-многим означает, что один экземпляр первой сущности (левой) связан с несколькими экземплярами второй сущности (правой). Это наиболее часто используемый тип связи. Левая сущность (со стороны "один") называется родительской, правая (со стороны "много") - дочерней. Характерный пример такой связи приведен на рис.5.4.
Связь типа много-ко-многим означает, что каждый экземпляр первой сущности может быть связан с несколькими экземплярами второй сущности, и каждый экземпляр второй сущности может быть связан с несколькими экземплярами первой сущности. Тип связи много-ко-многим является временным типом связи, допустимым на ранних этапах разработки модели. В дальнейшем этот тип связи должен быть заменен двумя связями типа один-ко-многим путем создания промежуточной сущности.
Каждая связь может иметь одну из двух модальностей связи (рис.5.6).
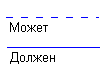
Рисунок 5.6 Графическое изображение модальностей связи
Модальность «может» означает, что экземпляр одной сущности может быть связан с одним или несколькими экземплярами другой сущности, а может быть и не связан ни с одним экземпляром.
Модальность «должен» означает, что экземпляр одной сущности обязан быть связан не менее чем с одним экземпляром другой сущности. Связь может иметь разную модальность с разных концов (как на рис. 5.4).
Описанный графический синтаксис позволяет однозначно читать диаграммы, пользуясь следующей схемой построения фраз:
<Каждый экземпляр СУЩНОСТИ 1> <МОДАЛЬНОСТЬ СВЯЗИ> <НАИМЕНОВАНИЕ СВЯЗИ> <ТИП СВЯЗИ> <экземпляр СУЩНОСТИ 2>.
Каждая связь может быть прочитана как слева направо, так и справа налево. Связь на рис. 5.4 читается так:
Слева направо: «каждый сотрудник может иметь несколько детей».
Справа налево: «Каждый ребенок обязан принадлежать ровно одному сотруднику».
Как и в реляционных схемах баз данных, в ER-схемах вводится понятие нормальных форм, причем их смысл очень близко соответствует смыслу реляционных нормальных форм. Заметим, что формулировки нормальных форм ER-схем делают более понятным смысл нормализации реляционных схем. Приведем только очень краткие и неформальные определения трех первых нормальных форм.
В первой нормальной форме ER-схемы устраняются повторяющиеся атрибуты или группы атрибутов, т.е. производится выявление неявных сущностей, «замаскированных» под атрибуты.
Во второй нормальной форме устраняются атрибуты, зависящие только от части уникального идентификатора. Эта часть уникального идентификатора определяет отдельную сущность.
В третьей нормальной форме устраняются атрибуты, зависящие от атрибутов, не входящих в уникальный идентификатор. Эти атрибуты являются основой отдельной сущности
Пример разработки простой ER-модели
При разработке ER-моделей мы должны получить следующую информацию о предметной области:
- Список сущностей предметной области.
- Список атрибутов сущностей.
- Описание взаимосвязей между сущностями.
ER-диаграммы удобны тем, что процесс выделения сущностей, атрибутов и связей является итерационным. Разработав первый приближенный вариант диаграмм, мы уточняем их, опрашивая экспертов предметной области. При этом документацией, в которой фиксируются результаты бесед, являются сами ER-диаграммы.
Предположим, что перед нами стоит задача разработать информационную систему по заказу некоторой оптовой торговой фирмы. В первую очередь мы должны изучить предметную область и процессы, происходящие в ней. Для этого мы опрашиваем сотрудников фирмы, читаем документацию, изучаем формы заказов, накладных и т.п.
Например, в ходе беседы с менеджером по продажам, выяснилось, что он (менеджер) считает, что проектируемая система должна выполнять следующие действия:
- Хранить информацию о покупателях.
- Печатать накладные на отпущенные товары.
- Следить за наличием товаров на складе.
Выделим все существительные в этих предложениях - это будут потенциальные кандидаты на сущности и атрибуты, и проанализируем их (непонятные термины будем выделять знаком вопроса):
- Покупатель - явный кандидат на сущность.
- Накладная - явный кандидат на сущность.
- Товар - явный кандидат на сущность
- (?)Склад - а вообще, сколько складов имеет фирма? Если несколько, то это будет кандидатом на новую сущность.
- (?)Наличие товара – это, скорее всего, атрибут, но атрибут какой сущности?
Сразу возникает очевидная связь между сущностями – «покупатели могут покупать много товаров» и «товары могут продаваться многим покупателям». Первый вариант диаграммы выглядит так (рис.5.7).

Рисунок 5.7 Первый вариант диаграммы
Задав дополнительные вопросы менеджеру, мы выяснили, что фирма имеет несколько складов. Причем, каждый товар может храниться на нескольких складах и быть проданным с любого склада. Куда поместить сущности «Накладная» и «Склад» и с чем их связать? Как связаны эти сущности между собой и с сущностями «Покупатель» и «Товар»? Пока известно, что:
· Покупатели покупают товары, получая при этом накладные, в которые внесены данные о количестве и цене купленного товара.
· Каждый покупатель может получить несколько накладных.
· Каждая накладная обязана выписываться на одного покупателя.
· Каждая накладная обязана содержать несколько товаров (не бывает пустых накладных).
· Каждый товар, в свою очередь, может быть продан нескольким покупателям путем оформления нескольких накладных.
· Каждая накладная должна быть выписана с определенного склада, и с любого склада может быть выписано много накладных.
Таким образом, после уточнения, диаграмма будет выглядеть следующим образом (рис.5.8).
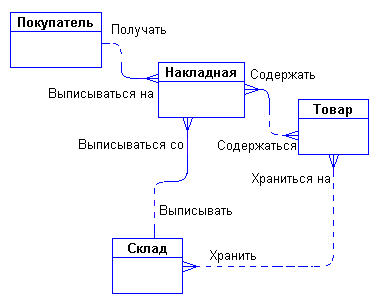
Рисунок 5.8 Второй вариант диаграммы
Пора подумать об атрибутах сущностей. Беседуя с сотрудниками фирмы, мы выяснили следующее:
· Каждый покупатель является юридическим лицом и имеет наименование, адрес, банковские реквизиты.
· Каждый товар имеет наименование, цену, а также характеризуется единицами измерения.
· Каждая накладная имеет уникальный номер, дату выписки, список товаров с количествами и ценами, а также общую сумму накладной. Накладная выписывается с определенного склада и на определенного покупателя.
· Каждый склад имеет свое наименование.
Снова выпишем все существительные, которые будут потенциальными атрибутами, и проанализируем их:
· юридическое лицо - термин ненужный, т.к.фирма не работает с физическими лицами. Не обращаем внимания;
· наименование покупателя - явная характеристика покупателя;
· адрес - явная характеристика покупателя;
· банковские реквизиты - явная характеристика покупателя;
· наименование товара - явная характеристика товара;
· (?)цена товара - похоже, что это характеристика товара. Отличается ли эта характеристика от цены в накладной?
· единица измерения - явная характеристика товара;
· номер накладной - явная уникальная характеристика накладной;
· дата накладной - явная характеристика накладной;
· (?)список товаров в накладной - список не может быть атрибутом. Вероятно, нужно выделить этот список в отдельную сущность;
· (?)количество товара в накладной - это явная характеристика, но характеристика чего? Это характеристика не просто «товара», а «товара в накладной»;
· (?)цена товара в накладной - опять же это должна быть не просто характеристика товара, а характеристика товара в накладной. Но цена товара уже встречалась выше - это одно и то же?
· сумма накладной - явная характеристика накладной. Эта характеристика не является независимой. Сумма накладной равна сумме стоимостей всех товаров, входящих в накладную;
· наименование склада - явная характеристика склада.
В ходе дополнительной беседы с менеджером удалось прояснить различные понятия цен. Оказалось, что каждый товар имеет некоторую текущую цену. Эта цена, по которой товар продается в данный момент. Естественно, что эта цена может меняться со временем. Цена одного и того же товара в разных накладных, выписанных в разное время, может быть различной. Таким образом, имеется две цены - цена товара в накладной и текущая цена товара.
С возникающим понятием «Список товаров в накладной» все довольно ясно. Сущности «Накладная» и «Товар» связаны друг с другом отношением типа много-ко-многим. Такая связь, как мы отмечали ранее, должна быть расщеплена на две связи типа один-ко-многим. Для этого требуется дополнительная сущность. Этой сущностью и будет сущность «Список товаров в накладной». Связь ее с сущностями «Накладная» и «Товар» характеризуется следующими фразами:
· каждая накладная обязана иметь несколько записей из списка товаров в накладной;
· каждая запись из списка товаров в накладной обязана включаться ровно в одну накладную;
· каждый товар может включаться в несколько записей из списка товаров в накладной;
· каждая запись из списка товаров в накладной обязана быть связана ровно с одним товаром.
Атрибуты «Количество товара в накладной» и «Цена товара в накладной» являются атрибутами сущности «Список товаров в накладной».
Точно также поступим со связью, соединяющей сущности «Склад» и «Товар». Введем дополнительную сущность «Товар на складе». Атрибутом этой сущности будет «Количество товара на складе». Таким образом, товар будет числиться на любом складе и количество его на каждом складе будет свое.
Теперь можно внести все это в диаграмму «Оптовая фирма» (рис. 5.9).
Замечание. Утверждения, которые были сформулированы в ходе бесед с сотрудниками фирмы, например: «Каждый покупатель может получить несколько накладных», являются бизнес-правилами. Бизнес-правила описывают правила работы данной организации и для БД это, по сути, ограничения целостности.
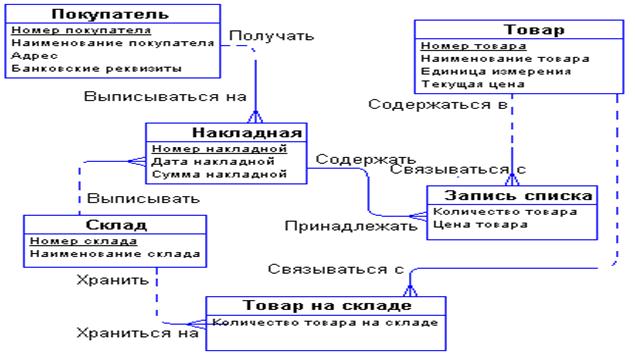
Рисунок 5.9 Диаграмма «Оптовая фирма»
Практические рекомендации по проектированию БД
Отдельные БД могут объединять все данные, необходимые для решения одной или нескольких прикладных задач, или данные, относящиеся к какой-либо… Предметные БД позволяют обеспечить поддержку любых текущих и будущих… Основывая же проектирование БД на текущих и предвидимых приложениях, можно существенно ускорить создание…Вопросы и упражнения для самоконтроля к главе 5
Глава 6 Функции СУБД и системы обработки транзакцийОсновные функции СУБД
К основным функция СУБД принято относить следующие:
Непосредственное управление данными во внешней памяти
Управление буферами оперативной памяти
Замечание. Существует отдельное направление СУБД, которое ориентировано на постоянное присутствие в оперативной памяти всей БД. Это направление…Управление транзакциями
То свойство, что каждая транзакция начинается при целостном состоянии БД и оставляет это состояние целостным после своего завершения, делает очень… С управлением транзакциями в многопользовательской СУБД связаны важные понятия…Журнализация
Под надежностью хранения понимается то, что СУБД должна быть в состоянии восстановить последнее согласованное состояние БД после любого аппаратного… · мягкие сбои, которые можно трактовать как внезапную остановку работы… · жесткие сбои, характеризуемые потерей информации на носителях внешней памяти. Примерами программных сбоев могут…Поддержка языков БД
В современных СУБД обычно поддерживается единый интегрированный язык, содержащий все необходимые средства для работы с БД, начиная от ее создания, и… Язык SQL сочетает средства SDL и DML, т.е. позволяет определять схему… Так, в каждой строке системной таблицы SYSTABLES хранится описание одной из таблиц пользовательских или системной баз…Системы обработки транзакций
Среди фактографических информационных систем важное место занимают два класса: системы оперативной обработки данных и системы, ориентированные на анализ данных и поддержку принятия решений
OLTP-системы
1) транзакций очень много; 2) выполняются они одновременно (к системе может быть подключено несколько… 3) при возникновении ошибки, транзакция должна целиком откатиться и вернуть систему к состоянию, которое было до…OLAP -системы
· Добавление в систему новых данных происходит относительно редко крупными блоками (например, раз в квартал загружаются данные по итогам… · Данные, добавленные в систему, обычно никогда не удаляются. · Перед загрузкой данные проходят различные процедуры «очистки», связанные с тем, что в одну систему могут поступать…Мониторы транзакций
· динамическое распределение запросов в системе (выравнивание нагрузки); · оптимизация числа выполняемых серверных приложений. Кратко рассмотрим реализацию этих функций. Если в системе функционирует несколько серверов, предоставляющих одинаковый…Сервер 1 Сервер 2
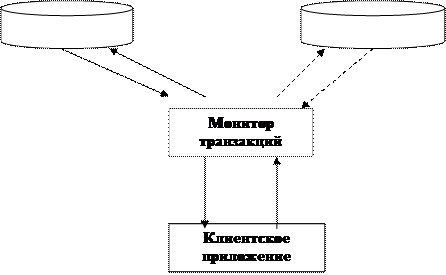 |
Ответ запрос ответ
Ответ запрос
Рисунок 6.1 Упрощенная схема работы монитора транзакций Клиентские приложения не знают, какой системе будут направлены их запросы, предлагается ли нужный сервис одним или…Архитектура СУБД
Пользователи БД
Главными потребителями информационного ресурса являются конечные пользователи, т.е. специалисты, ведущие различные участки работы с БД. Их состав… Специальную группу пользователей БД образуют прикладные программисты. Их…Вопросы и упражнения для самоконтроля по главе 6
2. Какова последовательность действий по восстановлению БД при жестком сбое? 3. Что содержится в системных таблицах БД? 4. Какие требования предъявляются к OLTP-системам?Клиент Сервер
Технология: выделяется файл-сервер для хранения и обработки файлов других узлов сети, а в остальных узлах функционирует приложение, в кодах которого… Недостатки: высокий сетевой трафик (передача множества файлов); небольшой… 2 RDA-модель (модель удаленного доступа). Коды компонента представления и прикладного совмещены и выполняются на…Данные
Клиент Сервер
Технология: клиентский запрос направляется на сервер, где ядро СУБД обрабатывает запрос и возвращает результат (набор данных) клиенту. Ядро СУБД… Достоинства: уменьшается загрузка сети, так как по сети передаются запросы… Недостатки: удовлетворительное администрирование приложений невозможно из-за совмещения в одной программе различных по…Процедур
Данные
Клиент Сервер
Технология: компонент представления выполняется на компьютере-клиенте, а прикладной компонент и ядро СУБД на компьютере-сервере БД. Процедуры… Достоинства: · возможность централизованного администрирования прикладных функций;Запуск
Процедур
Данные SQL
Клиент Сервер приложений Сервер БД
Рисунок 7.4 Модель сервера приложений