рефераты конспекты курсовые дипломные лекции шпоры

- Раздел Программирование
- /
- Вид работы: Лекции
- /
- Лекция 6.
Реферат Курсовая Конспект
Лекция 6.
Лекция 6. - Лекция, раздел Программирование, Основы алгоритмизации и программирования 1. Синтаксис Ассэмблера Программа На Ассемблере Представляет Собой С...
1. Синтаксис Ассэмблера
Программа на ассемблере представляет собой совокупность блоков памяти, называемых сегментами. Программа может состоять из одного или нескольких таких блоков-сегментов. Сегменты программы имеют определенное назначение, соответствующее типу сегментов: кода, данных и стека. Названия типов сегментов отражают их назначение. Деление программы на сегменты отражает сегментную организацию памяти процессоров Intel (архитектура IA-32). Каждый сегмент состоит из совокупности отдельных строк, в терминах теории компиляции называемых предложениями языка. Для языка ассемблера предложения, составляющие программу, могут представлять собой синтаксические конструкции четырех типов.
· Команды (инструкции) представляют собой символические аналоги машинных команд. В процессе трансляции инструкции ассемблера преобразуются в соответствующие команды системы команд процессора.
· Макрокоманды - это оформляемые определенным образом предложения текста программы, замещаемые во время трансляции другими предложениями.
· Директивы являются указанием транслятору ассемблера на выполнение некоторых действий. У директив нет аналогов в машинном представлении.
· Комментарии содержат любые символы, в том числе и буквы русского алфавита. Комментарии игнорируются транслятором.
Для распознавания транслятором ассемблера этих предложений их нужно формировать по определенным синтаксическим правилам. Для формального описания синтаксиса языков программирования используются
сические языки, которые представляют собой совокупность условных знаков, образующих нотацию метасинтаксического языка, и правил формирования из этих знаков однозначных описаний синтаксических конструкций целевого языка.
В учебных целях удобно использовать два метасинтаксических языка – синтаксические диаграммы и нормальные формы Бэкуса-Наура. Оба этих языка, в конечном итоге, предоставляют одинаковый объем информации. Поэтому выбор конкретного языка может определяться исходя из того, что синтаксические диаграммы более наглядны, а расширенные формы Бэкуса-Наура более компактны. В учебнике будут использоваться оба способа.
На рис. 5.1,5.2 и 5.3 показан порядок написания предложений ассемблера с помощью синтаксических диаграмм.
Как использовать синтаксические диаграммы? Очень просто: для этого нужно всего лишь найти и затем пройти путь от входа диаграммы (слева) к ее выходу (направо). Если такой путь существует, то предложение или конструкция являются синтаксически правильными. Если такого пути нет, значит, эту конструкцию компилятор не примет. Иногда на линиях в синтаксических диаграммах присутствуют стрелки. Они говорят о том, что необходимо обратить на направление обхода, указываемое этими стрелками, так как среди путей могут быть и такие, по которым можно идти справа налево. По сути, синтаксические диаграммы отражают логику работы транслятора при разборе входных предложений программы. Далее перечислены термины, представленные на рисунках.
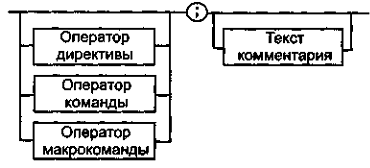
Рис. 5.1. Формат предложений ассемблера
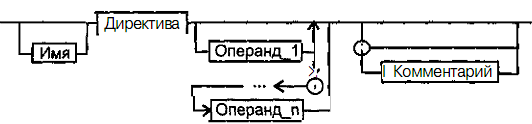
Рис. 5.2. Формат директив
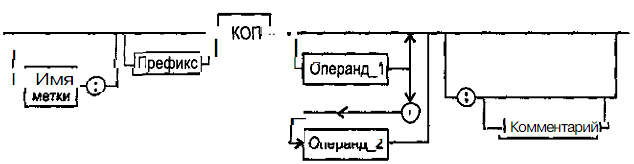
Рис. 5.3. Формат команд и макрокоманд
Имя метки – символьный идентификатор. Значением данного идентификатора является адрес первого байта предложения программы, которому он предшествует.
Префикс – символическое обозначение элемента машинной команды, предназначенного для изменения стандартного действия следующей за ним команды ассемблера.
Имя – идентификатор, отличающий данную директиву от других одноименных директив. В зависимости от конкретной директивы в результате обработки ассемблером этому имени могут быть присвоены определенные характеристики.
Код операции (КОП) и директива – это мнемонические обозначения соответствующей машинной команды, макрокоманды или директивы транслятора.
Операнды — части команды, макрокоманды или директивы ассемблера, обозначающие объекты, над которыми производятся действия. Операнды ассемблера описываются выражениями с числовыми и текстовыми константами, метками и идентификаторами переменных с использованием знаков операций и некоторых зарезервированных слов.
Другой способ описания синтаксиса языка - нормальные (расширенные) формы Бэкуса-Наура. С помощью форм Бэкуса-Наура целевой язык представляется в виде объектов трех типов.
Основные символы языка, в теории компиляции называемые — это имена операторов, регистров и т. п., то есть это те символьные объекты, из которых строится, в частности, исходный текст ассемблерной программы.
Имена конструкций языка, в теории называемые нетерминальными символами, обычно заключаются в угловые скобки <> или пишутся строчными буквами.
Правила (формы) описывают порядок формирования конструкций, в том числе предложений, целевого языка.
Каждая форма состоит из трех частей — левой, правой и связки:
левая часть - всегда нетерминальный символ, который обозначает одну из конструкций языка;
связка — символ стрелки =>, который можно трактовать как словосочетание «определяется как»;
правая часть описывает один или несколько вариантов построения конструкции, определяемой левой частью.
Несколько форм Бэкуса-Наура могут быть связаны между собой по нетерминальным символам, то есть одна форма определяется через другую. Для построения конструкции целевого языка необходимо взять одну или несколько форм Бэкуса-Наура, в каждой из которых выбрать нужный вариант для подстановки. В конечном итоге должна получиться конструкция (предложение) целевого языка, состоящая только из терминальных символов.
Для примера рассмотрим описание и использование форм Бэкуса-Наура для построения десятичных чисел со знаком. Вначале опишем эти формы (правила):
<десятичное_знаковое_целое>=><число_без_знака>|+<число_6ез_знака>|<число_без_знака>
<число_без_знака>=><дес_цифра> | <число_6ез_знакахдес_цифра>
<дес_цифра>=>0|1|2|3|4|5|6|7|8|9
<десятичное_знаковое_целое>,<число_без_знака>,<дес_цифра:> — нетерминальные символы (в исходной программе на ассемблере таких объектов нет);
+|-|0|1|2|3|4|5|6|7|8|9 — терминальные символы (их можно найти в исходном тексте программы), из терминальные символов по приведенным ранее трем правилам строится любое десятичное число;
символ вертикальной черты (|) означает альтернативу при выборе варианта некоторого правила.
Для примера выведем число 501, используя формы Бэкуса-Наура:
<десятичное_знаковое_целое> => <число_без_знака> =>
<число_без_знака><дес_цифра> => <число_без_знака>1 =>
<число_без_знака><дес_цифра>1 => <число_без_знака>01 => <дес_цифра>01 => 501
Предложения ассемблера (см. рис. 5.1-5.3) формируются из лексем, представляющих собой синтаксически неразделимые последовательности допустимых символов языка, имеющие смысл для транслятора.
Вначале определим алфавит ассемблера, то есть допустимые для написания текста программ символы:
· ASCII_символ_буква — все латинские буквы А - Z, а - z, причем прописные и строчные буквы считаются эквивалентными;
· decdigit - цифры от 0 до 9;
· специальные знаки _, ?, @, $, &;
· разделители: „ [,],(,), <, >, {, }, +,/,*,%, !,",", ?, , = #,^.
Лексемами языка ассемблера являются ключевые слова, идентификаторы, цепочки символов и целые числа.
Ключевые слова — это служебные символы языка ассемблера. По умолчанию регистр символов ключевых слов не имеет значения. К ключевым словам относятся:
· названия регистров(AL, АН, ВЦ ВН, CL, СН, DL.DH, АХ, ЕАХ, ВХ, ЕВХ, СХ, ЕСХ, DX, EDX, BP, EBP, SP, ESP, DI, EDI, SI, ESI, CS, DS, ES, FS, GS, SS, CRO, CR2, CR3, DRO, DRl, DR2, DR3, DR6, DR7);
· операторы (BYTE.SBVTE, WORD, SWORD, DWORD, SDWORD, FWORD, QWORD, TBYTE, REAL4, REAL8, REAL10, NEAR16, NEAR32, FAR16, FAR32, AND, NOT, HIGH, LOW, HIGHWORD, LOWWORD, OFFSET, SEG, LROFFSET, TYPE, THIS, PTR, WIDTH, MASK, SIZE, SIZEOF, LENGTH, LENGTHOF, ST, SHORT, TYPE, OPATTR, MOD, NEAR, FAR, OR, XOR, EQ, NE, LT, LE, GT, GE, SHR, SHL и др.);
· названия команд (КОП) ассемблера, префиксов.
Идентификаторы — последовательности допустимых символов, использующиеся для обозначения имен переменных и меток. Правило записи идентификаторов можно описать следующими формами
<id> => АSCII_символ_буква | АSCII_символ_буква | <id> АSCII_символ_буква
<id> <decdigit> | <znak> <decdigit> <id> | <znak> <id>
<decdigit> => 0| 1 | 2 | 3 |4| 5 | 6| 7| 8| 9
<znak> => _|=> _|?|@l$|_|&
Приведенные формы говорят о том, что идентификатор может состоять из одного или нескольких символов. В качестве символов можно использовать буквы латинского алфавита, цифры и некоторые специальные знаки — _, ?, $, @. Идентификатор не может начинаться символом цифры. Длина идентификатора может составлять до 255 символов (247 в MASM), хотя транслятор воспринимает лишь первые 32, а остальные игнорирует.
Цепочки символов — это последовательности символов, заключенные в одинарные или двойные кавычки. Правила формирования:
<string> => <quote> [[ <stext> ]] <quote>
<stext> =» <StringChar> | <stext> <stringChar>
<stringChar> => <quote> <quote> | любой_символ_кроме_кавычки
<quote> => " | '
Целые числа могут указываться в двоичной, десятичной или шестнадцатеричной системах счисления. Отождествление чисел при записи их в программах на-ассемблере производится по определенным правилам. Десятичные числа не требуют для своего отождествления указания каких-либо дополнительных символов. Для отождествления в исходном тексте программы двоичных и ных чисел используются следующие правила:
<шестнадц_число> => <дес_шестнадц_число>h | 0<сим_шестнадц_число>h
<дес_шестнадц_число> => <decdigit><сим_шестнадц_число> | <decdigit>
<сим_шестнадц_число> =>
<hexdigit><сим_шестнадц_число>| <дес_шестнадц_число> | <decdigit> | <hexdigit>
<decdigit> => 0| 1 | 2 | 3|4|5 |6| 7|8|9
<hexdigit> =>a|b|c|d|e|f|A|B|C|D|E| F
Важно отметить наличие символов после (h) и перед (0) записью шестнадцатеричного числа. Это сделано для того, чтобы транслятор мог отличить в программе одинаковые по форме записи десятичные и шестнадцатеричные числа. К примеру, числа 1578 и 1578h выглядят одинаково, но имеют разные значения. С другой стороны, какое значение в тексте исходной программы может иметь лексема
Это может быть и некоторый идентификатор, и, судя по набору символов, шестнадцатеричное число. Для того чтобы однозначно описать в тексте программы на ассемблере число, начинающееся с буквы, его дополняют ведущим нулем «0» и в конце ставят символ «h». Для данного примера правильная запись шестнадцатиричного числа — 0fe023h:
<двоичн_число> => <bindigit>b| <bindigit><двоичн_число>b
<bindigit> => 0|1
Для двоичных чисел все просто — после записи нулей и единиц, входящих в их состав, необходимо поставить латинскую букву «b».
Пример: 100110101b
Что касается комментария, то это самый простой элемент предложения ассемблера. Любая комбинация символов ASCII, расположенная в строке за символом точки с запятой (;), транслятором игнорируется, то есть является комментарием (см. рис. 5.1-5.3).
2. Директивы сегментации
В ходе предыдущего обсуждения были приведены основные правила записи команд и операндов в программе на ассемблере. Открытым остался вопрос о том, как правильно оформить последовательность команд, чтобы транслятор мог их обработать, а процессор — выполнить. Мы знаем, что сегмент имеет шесть сегментных регистров, посредством которых может одновременно работать:
o с одним сегментом кода;
o с одним сегментом стека;
o с одним сегментом данных;
o с тремя дополнительными сегментами данных.
Еще раз вспомним, что физически сегмент представляет собой область памяти, занятую командами и/или данными, адреса которых вычисляются относительно значения в соответствующем сегментном регистре.
Синтаксическое описание сегмента на ассемблере представляет собой конструкцию, представленную на рис. 5.14.

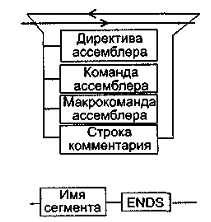
Рис. 5.14. Синтаксис описания сегмента
Важно отметить, что функциональное назначение сегментации несколько шире, чем простое разбиение программы на блоки кода, данных и стека. Сегментация является частью более общего механизма, связанного с концепцией модульного программирования. Она предполагает унификацию формата объектных модулей, создаваемых компилятором, в том числе компилируемых с разных языков программирования. Это позволяет объединять программы, написанные на разных языках. Именно для реализации различных вариантов такого объединения и предназначены операнды в директиве SEGMENT. Рассмотрим их подробнее.
Атрибут выравнивания сегмента (тип выравнивания) сообщает компоновщику о том, что нужно обеспечить размещение начала сегмента на заданной границе. Это важно, поскольку при правильном выравнивании доступ к данным в процессорах i80x86 выполняется быстрее. Допустимые значения этого атрибута приведены далее. По умолчанию тип выравнивания имеет значение PARA:
BYTE — выравнивание не выполняется. Сегмент может начинаться с любого адреса памяти;
WORD — сегмент начинается по адресу, кратному двум, то есть последний (младший) значащий бит физического адреса равен 0 (выравнивание по границе слова);
DWORD — сегмент начинается по адресу, кратному четырем, то есть два последних (младших) значащих бита равны 0 (выравнивание по границе двойного слова);
PARA – сегмент начинается по адресу, кратному 16, то есть последняя шестнадцатеричная цифра адреса должна быть Оh (выравнивание по границе параграфа);
PAGE – сегмент начинается по адресу, кратному 256, то есть две последние шестнадцатеричные цифры должны быть OOh (выравнивание по границе страницы размером 256 байт);
MEMPAGE – сегмент начинается по адресу, кратному 4 Кбайт, то есть три последние шестнадцатеричные цифры должны быть OOOh (адрес следующей страницы памяти размером 4 Кбайт).
Атрибут комбинирования сегментов (комбинаторный тип) сообщает компоновщику, как нужно комбинировать сегменты различных модулей, имеющие одно и то же имя. По умолчанию атрибут комбинирования принимает значение PRIVATE. Возможные значения атрибута комбинирования сегмента перечислены далее:
PRIVATE – сегмент не будет объединяться с другими сегментами с тем же именем вне данного модуля;
PUBLIC – заставляет компоновщик объединить все сегменты с одинаковым именем. Новый объединенный сегмент будет целым и непрерывным. Все адреса (смещения) объектов, а это могут быть, в зависимости от типа сегмента, команды или данные, будут вычисляться относительно начала этого нового сегмента;
COMMON – располагает все сегменты с одним и тем же именем по одному адресу, то есть все сегменты с данным именем перекрываются. Размер полученного в результате сегмента будет равен размеру самого большого сегмента;
AT xxxx – располагает сегмент по абсолютному адресу параграфа (параграф – область памяти, объем которой кратен 16, потому последняя шестнадцате-ричная цифра адреса параграфа равна 0). Абсолютный адрес параграфа задается выражением ххх. Компоновщик располагает сегмент по заданному адресу памяти (это можно использовать, например, для доступа к видеопамяти или области ПЗУ), учитывая атрибут комбинирования. Физически это означает, что сегмент при загрузке в память будет расположен начиная с этого абсолютного адреса параграфа, но для доступа к нему в соответствующий сегментный регистр должно быть загружено заданное в атрибуте значение. Все метки и адреса в определенном таким образом сегменте отсчитываются относительно заданного абсолютного адреса;
STACK – определение сегмента стека. Заставляет компоновщик объединить все одноименные сегменты и вычислять адреса в этих сегментах относительно регистра SS. Комбинированный тип STACK (стек) аналогичен комбинированному типу PUBLIC за исключением того, что регистр SS является стандартным сегментным регистром для сегментов стека. Регистр SP устанавливается на конец объединенного сегмента стека. Если не указано ни одного сегмента стека, компоновщик выдаст предупреждение, что стековый сегмент не найден. Если сегмент стека создан, а комбинированный тип STACK не используется, программист должен явно загрузить в регистр SS адрес сегмента (подобно тому, как это делается для регистра DS).
Атрибут класса сегмента (тип класса) – это заключенная в кавычки строка, помогающая компоновщику определить нужный порядок следования сегментов при сборке программы из сегментов нескольких модулей. Компоновщик объединяет вместе в памяти все сегменты с одним и тем же именем класса (имя класса в общем случае может быть любым, но лучше, если оно отражает функциональное назначение сегмента). Типичным примером использования имени класса (обычно класса code) является объединение в группу всех сегментов кода программы. С помощью механизма типизации класса можно группировать так же сегменты инициализированных и неинициализированных данных.
Атрибут размера сегмента. Для процессоров i80386 и выше сегменты могут быть 16- или 32-разрядными. Это влияет прежде всего на размер сегмента и порядок формирования физического адреса внутри него. Далее перечислены возможные значения атрибута:
USE16 – сегмент допускает 16-разрядную адресацию. При формировании физического адреса может использоваться только 16-разрядное смещение. Соответственно, такой сегмент может содержать до 64 Кбайт кода или данных;
USE32 – сегмент должен быть 32-разрядным. При формировании физического адреса может использоваться 32-разрядное смещение. Поэтому такой сегмент может содержать до 4 Гбайт кода или данных.
Все сегменты сами по себе равноправны, так как директивы SEGMENT и ENDS не содержат информации о функциональном назначении сегментов. Для того чтобы использовать их как сегменты кода, данных или стека, необходимо предварительно сообщить транслятору об этом с помощью специальной директивы ASSUME, формат которой показан на рис. 5.15. Эта директива сообщает транслятору, какой сегмент к какому сегментному регистру привязан. В свою очередь, это позволяет транслятору корректно связывать символические имена, определенные в сегментах.
Привязка сегментов к сегментным регистрам осуществляется с помощью операндов этой директивы, в которых имя_сегмента должно быть именем сегмента, определенным в исходном тексте программы директивой SEGMENT или ключевым словом NOTHING. Если в качестве операнда используется только ключевое слово NOTHING, то предшествующие назначения сегментных регистров аннулируются, причем сразу для всех шести-сегментных регистров. Ключевое слово NOTHING можно также использовать вместо аргумента имя сегмента; в этом случае будет выборочно разрываться связь между сегментом с именем имя сегмента и соответствующим сегментным регистром.
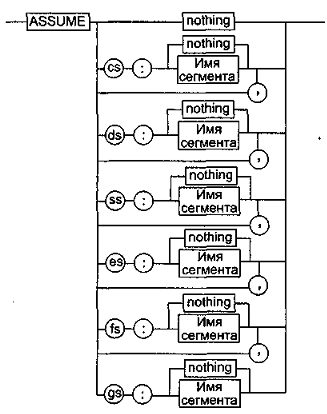
Рис. 5.15. Директива ASSUME
Рассмотренные ранее директивы сегментации используются для оформления программы в трансляторах MASM и TASM. Поэтому их называют стандартными директивами сегментации.
Для простых программ, содержащих по одному сегменту для кода, данных и стека, хотелось бы упростить их описание. Для этого в трансляторы MASM и TASM была введена возможность использования упрощенных директив сегментации. При этом возникла проблема, связанная с тем, что необходимо было как-то компенсировать невозможность напрямую управлять размещением и комбинированием сегментов. Для этого совместно с упрощенными директивами сегментации стали использовать директиву указания модели памяти MODEL, которая частично стала управлять размещением сегментов и выполнять функции директивы ASSUME (поэтому при введении в программу упрощенных директив сегментации директиву ASSUME можно не указывать). Директива MODEL связывает сегменты, которые при наличии упрощенных директив сегментации имеют предопределенные имена, с сегментными регистрами (хотя все равно придется явно инициализировать регистр DS).
[Для сравнения приведем два листинга с программами на ассемблере. Функционально они одинаковы и выводят на консоль сообщение: «Hello World! No war and bomb! Let's live friendly and learn assembler language.». Листинг 5.1 содержит программу со стандартными директивами сегментации, а листинг 5.2, соответственно, — с упрощенными.]
– Конец работы –
Эта тема принадлежит разделу:
Основы алгоритмизации и программирования
Основы алгоритмизации и программирования... Литература В И Юров Ассемблер Учебник для вузов Н И Голубь Искусство программирования на Ассемблере Лекции и упражнения...
Если Вам нужно дополнительный материал на эту тему, или Вы не нашли то, что искали, рекомендуем воспользоваться поиском по нашей базе работ: Лекция 6.
Что будем делать с полученным материалом:
Если этот материал оказался полезным ля Вас, Вы можете сохранить его на свою страничку в социальных сетях:
| Твитнуть |
Хотите получать на электронную почту самые свежие новости?

Подпишитесь на Нашу рассылку
Реклама





Информация в виде рефератов, конспектов, лекций, курсовых и дипломных работ имеют своего автора, которому принадлежат права. Поэтому, прежде чем использовать какую либо информацию с этого сайта, убедитесь, что этим Вы не нарушаете чье либо право.
© copyright 1999 - 2024 allRefs.net. Все права защищены. Страница сгенерирована за: 0.034 сек.
Новости и инфо для студентов