Порівняльні характеристики нейрокомп’ютерів на базі ПОС. - раздел Связь, Тема 1: Вступ до дисципліни Проектування цифрової обробки сигналів та зображень. Основні поняття та визначення 1. Області застосування та основні задачі цифрової обробки сигналів Для Побудови Но (Нейрообчислювач) Перспективним Є Використання Сигнальних Про...
Для побудови НО (нейрообчислювач) перспективним є використання сигнальних процесорів із плаваючою крапкою ADSP2106x, TMS320C4x,8x, DSP96002 і ін. Типова структурна схема реалізації НО на основі сигнальних процесорів ADSP2106x приведена на рис.6. До її складу включений один керуючий сигнальний процесор для здійснення функцій загального керування, і до восьми процесорів здійснюючих паралельні обчислення відповідно до закладених алгоритмів (матричні сигнальні процесори). Керуючий і матричні процесори утворять кластер процесорів із загальною шиною і ресурсами розподіленої пам'яті. Обмін інформацією між керуючим процесором, матричними процесорами, Host-ЕОМ і зовнішнім середовищем здійснюється за допомогою портів вводу/виводу. Для тестування і налагодження - JTAG-порт. Є 12 зовнішніх лінків, а по 3 лінка кожного з МСП призначені для внутрімодульного міжпроцесорного обміну. Синхронізація роботи системи може здійснюватися як від внутрішніх кварцових генераторів, так і від зовнішніх генераторів. Активізація обчислень програмна чи зовнішня. Для вводу/виводу й АЦ/ЦА перетворень сигналів призначений спеціалізований модуль, що містить у собі: універсальний цифровий TTL порт, АЦП, ЦАП, вузол програмувальних напруг для зсуву шкал АПЦ і установки порога спрацьовування стартових компараторів, вузол фільтрації вихідних аналогових сигналів, підсистему тестування, вузол синхронізації і керування, буферну пам'ять FІFO. Первісне завантаження здійснюється по Host-інтерфейсі чи по лінках. Керуючий інтерфейс будь-якого МСП дозволяє керувати процесорним скиданням і перериваннями, його ідентифікаційним номером і т.п.
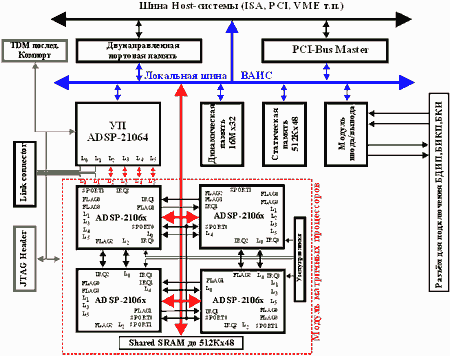
Рис.6. Реалізація НО на основі ADSP2106x
Така архітектура НО забезпечує виконання операцій ЦОС у реальному часі, прискорення векторних обчислень, можливість реалізації нейромережевих алгоритмів з високим паралелізмом виконання векторних і матричних операцій.
Структурна схема НО на основі сигнальних процесорів TMS320C4x представлена на рис.7. Декілька DSP, що входять у структуру НО утворять розподілену обчислювальну структуру з процесорних модулів, з'єднаних між собою високошвидкісними портами. Даний варіант реалізації НО може бути побудований з використанням від двох до восьми сигнальних процесорів.
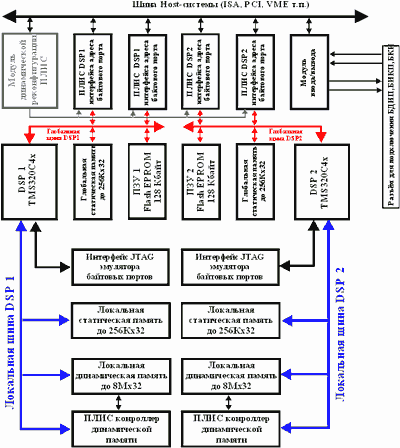
Рис.7. Структура НО на основі TMS320C4x.
При використанні двох паралельних 32-розрядних DSP TMS320C40 обмін інформацією при реалізації нейромережевих алгоритмів здійснюється за допомогою шести зв'язаних портів із пропускною здатністю в 30 Мб/c і каналів DMA кожного з процесорів. Підтримуючи парелельну незалежну роботу, підсистема DMA і процесор забезпечують паралельний обмін інформацією зі швидкостями до 560 Мб/c. За допомогою високошвидкісних портів можлива реалізація на основі даних DSP таких архітектур, як: кільця, ієрархічні дерева, гіперкуб і т.п. Кожна з локальних шин TMS320C40 забезпечує обмін інформацією на швидкостях до 120 Мбайт/с.
Процесорні модулі функціонують незалежно і при необхідності поєднуються за допомогою зв'язаних портів. Функції обміну, керування процесорними модулями, перериваннями і каналами DMA реалізують ПЛІС, наприклад фірми Xіlіnx. Застосування в НО динамічних реконфігуруючих структур (нейромережі зі структурною адаптацією) і використання останніх ПЛІС, вимагає мінімізації часу на реконфігурацію ПЛІС, що найчастіше програмуються в режимах Master Serіal і Perіpherіal. Основний недолік при використанні даних режимів перепрограмування полягає в залежності процесу переконфігурації ПЛІС від вбудованого тактового генератора. Мінімальні втрати часу можливо одержати при проведенні переконфігурації ПЛІС у режимі Slave Serіal, у якому внутрішній тактовий генератор відключений, а синхронізація здійснюється за допомогою зовнішніх синхросигналів.
Підсистема збереження інформації включає модулі локальної статичної (до 256Кх32) і динамічної пам'яті (до 8Мх32) на кожний із процесорів і глобальної статичної пам'яті (до 256Кх32). Host-ЕОМ здійснює звертання до глобальній статичній пам'яті 16-бітними словами в режимі рядкових пересилань з автоінкрементованням адреси за допомогою адресного простору портів вводу/виводу. Для дозволу можливих конфліктних ситуацій до складу НО введені арбітри доступу. Додатковий обмін інформацією може бути здійснений через високошвидкісний комунікаційний порт. Host-ЕОМ має можливість переривати роботу кожного з процесорних модулів. Підсистема переривань підтримує обробку переривань до кожного з DSP при обміні інформацією з Host-ЕОМ.
Реалізація НО, блок матричних процесорів якого побудований на основі чотирьох матричних TMS320C44 із продуктивністю 60 MFLOPS, являє собою розподілену обчислювальну структуру з процесорних модулів із продуктивністю до 960 MFLOPS, з'єднаних між собою високошвидкісними портами Структура НО містить у собі КП (TMS320C44), чотири МСП (TMS320C44), статичну пам'ять (до 512Кх32), динамічну пам'ять (до 16Мх32) і интерфейсні засоби для обміну з зовнішнім середовищем. Використовуваний процесор має дві незалежні шини: глобальну і локальну зі швидкістю обміну до 240 Мбайт/c і чотири паралельних байтових порти з пропускною здатністю 30 Мбайт/с. Комунікаційні порти забезпечують проведення міжпроцесорного обміну з мінімальним навантаженням на мікропроцесорне ядро, для чого використовуються відповідні контролери DMA для кожного з портів. Кожний з портів забезпечує передачу інформації зі швидкістю до 20 Мбайт/c, що дозволяє досягати пікової продуктивності по всіх портах близько 120 Мбайт/с.
Чотири процесорних модулі функціонують на платі незалежно. Обмін інформації між ними здійснюється за допомогою байтового порту. Комунікаційні порти і канали DMA забезпечують різноманітні можливості високошвидкісного обміну. Host-ЕОМ має можливість переривати роботу кожного з процесорних модулів. Для використання спеціалізованого багатовіконного відлагоджувача задач ЦОС фірми Texas Іnstruments у структуру НО уводиться JTAG інтерфейс. Завантаження програм і даних, обмін даними між НО і Host-ЕОМ здійснюється через високошвидкісний комунікаційний порт, що має FІFO буфера в обох напрямках. Вузли вводу/виводу підключаються через глобальну шину з пропускною здатністю до 100 Мбайт/c. Внутрішня структура інтерфейсу визначається завантаженою в ПЛІС конфігурацією.
Розглянуті варіанти НО забезпечують виконання ЦОС і нейроалгоритмів у реальному масштабі часу, прискорення векторних і матричних обчислень, у порівнянні з традиційними обчислювальними засобами в кілька разів і дозволяють реалізовувати нейромережу з числом синапсів до декількох мільйонів.
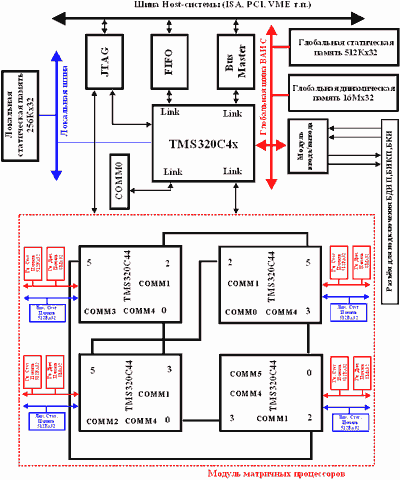
Рис.8. Структура НО на основі TMS320C44
Ще більше підвищити продуктивність НО даного типу можна при використанні одного із самих потужних на сьогодні сигнальних процесорів - TMS320C80, TMS320C6ххх фірми TІ.
Прикладом реалізації НО на DSP фірми Моторолла є нейрообчислювач NEURO TURBO фірми Fujіtsu. Він реалізований на основі 4-х зв'язаних кільцем 24-розрядних DSP із плаваючою крапкою МВ86220 (основні параметри: внутрішня точність 30 розрядів, машинний цикл 150 нс., пам'ять програм-25Кслів х2 (внутрішня), 64К слів х4 (зовнішня), технологія виготовлення КМОП 1,2 мкм). Активаційна функція нейронів обмежується в діапазоні від 0 до 1, а можливі значення входів не перевищують 16 розрядів, що обумовлює достатню точність при 24-х розрядній архітектурі. Побудова нейрокомп’ютера на основі кільцевої структури об'єднання DSP дозволяє знизити апаратні витрати на реалізацію підсистеми централізованого арбітражу міжпроцесорної взаємодії.
Нейрокомп’ютер NEURO TURBO (рис.9) складається з чотирьох DSP, зв'язаних один з одним за допомогою двопортової пам'яті. Кожний з DSP може звертатися до двох модулів такої пам'яті (ємністю 2К слів кожна) і до робочої пам'яті (РП) (ємністю 64К слів х4 Банку) у своєму адресному просторі. Внаслідок того, що доступ до двопортової пам'яті здійснюється випадковим чином одним із сусідніх DSP, то передача даних між ними відбувається в асинхронному режимі. Робоча пам'ять використовується для збереження вагових коефіцієнтів, даних і допоміжної інформації. Для успішної роботи НМ необхідне одержання згорток у всіх елементарних нейронних вузлах. Кільцева структура об'єднання DSP забезпечує конвеєрну архітектуру згортки, причому передача даних по конвеєрі здійснюється за допомогою ДПП. Після того як DSP завантажує дані з однієї ДПП, він записує результати своєї роботи в суміжну ДПП, отже, кільцева архітектура паралельної обробки забезпечує високу швидкість операції з використанням відносно простих апаратних рішень.
Для виконання функцій загального керування використовується Host-ЕОМ на основі звичайної обчислювальної системи. Обмін даними між нейроплатою і Host-ЕОМ через центральний модуль ДПП. Завантаження програм у DSP здійснюється за допомогою пам'яті команд для кожного DSP. Отже, його архітектура цілком відповідає паралельній розподіленій архітектурі типу MІMD. Пікова продуктивність системи 24 MFLOPS.

Рис.9. Структура нейрокомп’ютера NEURO TURBO (фірми Fujіtsu)
Для реалізації моделі НМ ієрархічного типу фірмою Fujіtsu випущена нейроплата на основі DSP МВ86232, із власною пам'яттю до 4 Мб, що дозволяє здійснювати моделювання НМ, що містить більш 1000 нейронів. Структура НМ містить у собі вхідний, проміжний і вихідний рівні (найбільше число схованих шарів - два (обмеження по пам'яті)). Для навчання нейрокомп’ютера використовуються оригінальні фірмові алгоритми: алгоритм віртуального імпедансу, алгоритм скоректованого навчання й алгоритм розширеного навчання.
Кожна з розглянутих типових структур реалізації НМ може бути промодельована на основі розглянутих вище варіантів побудови мультипроцесорних НО. Так, для НО на основі TMS320C4x при реалізації якої-небудь з розглянутих архітектур (кільце, ієрархічне дерево, гіперкуб і т.п.) досить тільки змінити призначення комунікаційних портів, що забезпечує гнучкість і масштабування при дослідженні і розробках нейромережевих систем різної архітектури.
Нейроприскорювачі на базі ПЛІС. Нейрообчислювачі на базі ПЛІС - як правило позиціонуються як гнучкі нейрообчислювальні системи для науково-дослідних цілей і дрібносерійного виробництва. Для побудови більш продуктивних і ефективних нейрообчислювачів як правило потрібно застосування сигнальних процесорів.
Паралельний перепрограмовувальний обчислювач (ППВ) розроблений у стандарті VME і реалізований на базі перепрограмовувальних мікросхем сімейства 10К фірми Altera. Обчислювач призначається для роботи як апаратний прискорювач на шині VME. Він повинний включатися в систему як підлеглий пристрій основної керуючої ЕОМ (host-машини) з універсальним процесором.
ППВ використовується для побудови систем розпізнавання образів на основі обробки телевізійної, тепловізійної і іншої інформації, а також систем, заснованих на реалізації алгоритмів із граничними функціями і найпростішими арифметичними операціями і дозволяє домогтися значної швидкості обчислень.
Обчислювач складається з наступних функціональних блоків [3]:
· схема керування (Сх Кер);
· базові обчислювальні елементи (БОЕ1-БОЕ6);
· контролер зовнішньої шини (Контролер E-bus);
· контролер системної шини (Контролер VME);
· два масиви статичної пам'яті (ОЗУ0, ОЗУ1);
· блок високошвидкісних приймачів/передавачів.
Схема керування використовується для керування БОЕ і потоками даних в обчислювачі і є найпростішим RІSC процесором. Структура і набір команд процесора можуть змінюватися в залежності від типу розв'язуваної задачі.
БОЕ використовуються для виконання найпростіших арифметичних операцій типу додавання, віднімання, множення й обчислення граничних функцій. Тому що БОЕ реалізовані на перепрограмовувальних мікросхемах, їхня архітектура може змінюватися. Архітектура БОЕ для різних алгоритмів може відрізнятися, але зазвичай легко реалізується шляхом комбінації бібліотечних функцій, компіляції їх за допомогою САПР (типу MaxPlus) і завантаження файлу конфігурації в обраний БВЭ (базовий обчислювальний елемент).

Рис.. Структурна схема ППВ [3].
Два масиви локальної статичної пам'яті зібрані з 8 мікросхем статичної пам'яті ємністю 0,5 Мбайт, мають розмір 4Мбайт і організовані як масив 512К 8-байтовых слів. Масиви пам'яті зв'язані зі схемою керування окремими адресними шинами і можуть функціонувати незалежно один від одного. Пам'ять призначена для збереження загальних коефіцієнтів, а також проміжних результатів обчислень чи остаточних результатів, підготовлених до передачі через контролер системної шини в центральний процесор чи через контролер E-bus на лінк-порти.
Зв'язок декількох обчислювачів між собою чи обчислювача з пристроєм оцифровування зображення, при наявності в пристрої оцифровування відповідного інтерфейсу, здійснюється за допомогою послідовного каналу приймачів/передавачів HOTLіnk фірми CYPRESS. Керування передачею даних виконує контролер зовнішньої шини, що представляє собою набір 4-х стандартних FІFO і регістрів керування і даних. Контролер шини VME виконує функцію інтерфейсу з центральним процесором і є стандартним пристроєм.
З погляду програміста обчислювач можна представити як RіSC-процессор (схема керування чи керуючий процесор) і шість векторних процесорів (обчислювальних елементів), що відпрацьовують SіMD-команды (одна команда для багатьох даних). Велика кількість шин даних, можливість одночасної роботи всіх БОЕ і виконання арифметичних операцій множення і додавання за один такт дозволяє ефективно розпаралелювати процес обробки інформації.
Особливістю схеми керування перепрограмувального обчислювача для систем обробки інформації є наявність робочої команди, що керує шістьма базовими обчислювальними елементами. Команда дозволяє одночасно, за один такт, задавати різні режими функціонування шести базовим обчислювальним елементам і інкрементувати адреси обох масивів пам'яті на будь-яке число від 0 до 255, збережене в регістрах інкремента, причому кожному масиву відповідає свій регістр. Команда може повторюватися будь-яку кількість разів у відповідності зі значенням, збереженим у спеціальному регістрі. Це дозволяє виконувати основну команду без втрат на організацію циклів і переходів. Робоча команда дозволяє одночасно запускати обидва контролери локальної пам'яті, інкрементувати адресні регістри на необхідне значення, виставляти на адресні шини адреси з відповідних регістрів адреси, виставляти на шини керування БОЕ команди з відповідних регістрів БОЕ. Крім того, робоча команда здійснює організацію обміну даними між контролером зовнішньої шини і локальною пам'яттю.
Все темы данного раздела:
Основні поняття та визначення. Основні характеристики сигналів
Сигнал (в теории информации и связи) — материальный носитель информации, используемый для передачи сообщений в системе связи. Сигналом может быть люб
Природа сигналів. За своєю природою, сигнали можуть бути випадкові або детерміновані.
До детермінованих відносять сигнали, значення яких у будь-який момент часу або в довільній точці простору є апріорно відомими або можуть бути досить точно визначені (обчислені) за відомою чи передб
Аналогові та цифрові сигнали.
До основних типів відносять аналоговий, дискретний і цифровий сигнали.
Аналоговим називають сигнал, неперервний у часі і значеннях. Такий сигнал описується неперервною або кусочно н
Основні типи сигналів
Фінітні сигнали. Фінітним називається сигнал, який визначений лише на деякому часовому проміжку і не існує поза ним, тобто при t>T, амплітуда сигналу рівна нулю.
Пер
Елементарні сигнали, що найчастіше використовуються ЦОС
Всі сигнали ми будемо розглядати в аналоговому та неперервному варіантах.
1. Неперервний випадок
Властивості спектрів дискретних сигналів
1. Неперервність.
2. Періодичність..
3. Спектр дійсного сигналу. Якщо - д
Режим реального часу
Основними прикладними (інженерними, практичними) задачами обробки сигналів є:
1. Ідентифікація і розпізнавання.
2. Телекомунікації.
3. Обробка музичних і мо
Переваги і недоліки ЦОС
Перевагами ЦОС є:
Гарантована точність
Цілковита відтворюваність. Можна ідентично відтворити кожний елемент, оскільки відсутні відхилення, обумовлен
Основні операції цифрової обробки сигналів
Проте всі ці алгоритми, як правило - блокового типу, тобто побудовані на як завгодно складних комбінаціях досить невеликого набору типових цифрових операцій, до основного з яких відносяться: зго
Застосування ДПФ
На рис. 5.1 наведена схема взаємодії між часовою та частотною областями.
Основними сферами застосування ДПФ є:
- цифровий спектральний аналіз - аналізатори спектра, обробка мови,
ДПФ як згортка сигналу з базисними функціями
Оскільки комплексна експонента може бути представлена у виді дійсної та уявної частини (формула Ейлера), то основне рівняння ДПФ може бути записано таким чином:
Основні операції фільтрації
До основних операцій фільтрації інформації відносять:
- згладжування;
- прогнозування;
- диференціювання;
- інтегрування;
- поділ на певні складові;
Класи і параметри фільтрів
Залежно від призначення фільтру, а отже і загального виду його частотної характеристики, виділяють такі основні, найбільш розповсюджені, типи фільтрів (вибіркові фільтри):
-
Поняття про швидкі алгоритми
При побудові швидких алгоритмів використовують кілька основних прийомів. Серед них найголовнішими є :
1. Розбиття задачі на підзадачі.
2. Рекурсія - коли деякий метод чи прийом мо
Вправи і завдання до теми №1
1. Визначити період заданого сигналу: .
Відповідь :
Зменшення частоти дискретизації: децимація із цілим кроком
На рис. 1.1, а наведена блок-схема процесу децимації сигналу х(n) із цілим кроком М. На ній зображені цифровий фільтр захисту від накладення спектрів h(k) і схема стиску (компресор) частоти дискрет
Збільшення частоти дискретизації: інтерполяція із цілим кроком
Інтерполяція - це цифровий еквівалент процесу цифроаналогового перетворення, коли із цифрових вибірок, поданих на цифроаналоговий перетворювач, за допомогою інтерполяції відновлюється аналоговий си
Перетворення частоти дискретизації з нецілим кроком
У деяких ситуаціях часто буває потрібно змінити частоту дискретизації в неціле число раз. Приклад - цифрове аудіо, де може вимагатися передача даних з одного запам'ятовувального пристрою на інше, п
Багатокаскадне перетворення частоти дискретизації
У п.1.3 зміна частоти дискретизації відбувалося відразу з використанням єдиного коефіцієнта децимації або інтерполяції. Якщо потрібне значна зміна частоти дискретизації, такий підхід неефективний;
Розробка практичних конвертерів частоти дискретизації
Розробку практичного багатокаскадного конвертера частоти дискретизації можна розбити на чотири етапи:
Задати загальні вимоги до фільтрів захисту від накладення спектрів і придушення
Специфікація фільтру
Фактично продуктивність системи обробки при декількох швидкостях критично залежить від типу НІХ
і якості використовуваного фільтра. Відзначимо, що при децимації й інтерполяції можуть викор
Високоякісне аналого-цифрове перетворення в цифровому аудіо
У сфері цифрового аудіо постійно потрібно підвищувати якість, дозвіл і швидкість АЦП. Це привело до розробки однобітових АЦП із використанням методів дельта-сігма-модуляції. У результаті з'явилася
Ефективне аналого-цифрове перетворення у високоякісних системах відтворення компакт-дисків
Одним з перших серйозних застосувань методів з обробкою при декількох швидкостях стало відтворення звуку й музики в програвачах компакт-дисків.
На рис. 6.2 зображена схема відновлення анал
Особливості діагностики та контролю процесорів та систем опрацювання сигналів та зображень
Для контролю і діагностики вузлів опрацювання сигналів застосовуються різні сполучення відомих методів вбудованого і зовнішнього контролю ЕОМ, або методи діагностики складних систем, що базуються н
Рархічність засобів діагностики та контролю процесорів та систем опрацювання сигналів та зображень
Ієрархічність засобів діагностики відповідає ієрархічності обчислювальних засобів. Тому розглядається ієрархічність на рівні: систем, процесорів та окремих вузлів.
Використовуються такі за
Процес формування АЧХ
Для обчислення АЧХ нерекурсивних ЦФ здебільшого застосовують метод передаточних функцій. Від передаточної функції, яка в загальному вигляді записується як многочлен виду:
H(Z)= a
Визначення і дослідження виду АЧХ
Нехай задано проаналізувати АЧХ фільтра з такими параметрами сигналу: l = 0,1, ...,31; А = 1, 2,...,100; S = 8, 16; Q = -64...64; N = 0,1, …, 31.
Згідно
Структура потокового (ковзаючого) процесора ШПФ.
6.Методика вибору оптимального складу НВІС
Розглядаються передумови і методика однокристальної реалізації швидкого перетворення Фур'є на приладах програмувальної логіки фі
Використання ПЛІС для високопродуктивної цифрової обробки сигналів та зображень
Є ряд альтернативних рішень побудови високопродуктивних систем, зокрема на замовлених інтегральних схемах (ASІ) і спеціалізованих процесорах цифрової обробки сигналів (DSP). Розглядати питання реал
Таблиця 1. Основні характеристики ПЛІС Xіlіnx серій Vіrtex, Vіrtex-e, XC4000XL/XLAXV, Spartan/XL
Сімейство ПЛІС
Системна частота, МГЦ
Швидкодія, нс/вентиль
Швидкість обміну chіp-to-chіp, МГЦ
Ємність ПЛІС, системних вентилів
Таблиця 1. Основні характеристики ПЛІС Xіlіnx серій Vіrtex, Vіrtex-e, XC4000XL/XLAXV, Spartan/XL
Сімейство ПЛІС
Системна частота, МГЦ
Швидкодія, нс/вентиль
Швидкість обміну chіp-to-chіp, МГЦ
Ємність ПЛІС, системних вентилів
Оцінка продуктивності вузла виконання операцій ШПФ на ПЛІС.
Оцінимо необхідну продуктивність пристрою обробки. Для обчислення ШПФ 256 точок за основою 2 з комплексними вхідними даними потрібно приблизно 3 тис. множень дійсних операндів і 5,5 тис. додавань д
Таблиця 1. Характеристики М-модулів ШПФ на ПЛІС серії Vіrtex
Розмір перетворення
Системних вентилів, тис.
Частота надходження вхідних даних, Мгц-real-tіme
Час перетворення, мкс
Структура потокового (ковзаючого) процесора ШПФ.
У загальному випадку при побудові М-модуля ШПФ можна піти декількома шляхами: або спроектувати модулі з малими займаними обсягами, великим часом перетворення і малою швидкістю надходження вхідних д
Таблиця 2. Характеристики М-модулів ковзного ШПФ на ПЛІС Xіlіnx
Число точок
Тактова частота, МГц
Час перетворення, мкс
Об’єм модуля, логічних комірок
Необхідна ПЛІС
Визначення нейрокомп’ютера.
Нейрокомпьютери - дуже модне слово, яке використовують направо і наліво. На початку 90-х років був дуже бурхливий розвиток даної тематики у вітчизняних розробках. Але разом з рядом серйозних розроб
Базова структура нейрокомп’ютера на основі ПОС.
Зупинимося на особливостях апаратної реалізації нейрообчислювача (НО) (див. рис.5) з можливістю паралельної обробки, що реалізують елементи нейромережі.
Реалізація ШПФ на нейрокомп’ютері.
Розглянемо реалізацію ШПФ на базі процесора Л1879ВМ1(NM6403). Процесор Л1879ВМ1 - високопродуктивний спеціалізований мікропроцесор, що об’єднює в собі риси двох сучасних архітектур: VLIW (Very Long
Співпроцесора NM6403 при розбитті матриці співпроцесора NM6403 при розбитті матриці
вагових коефіцієнтів - (2х32біти)/(8х8біт) вагових коефіцієнтів - (2х32біти)/(2х32біти)
По приведених двох варіантах розбивки матриці векторного помножувача виробляється п
Таблиця 2. Порівняльна характеристика точності відновленого сигналу після прямого і зворотного ШПФ із різними основами
Перетворення Фур'є
Систематична похибка-M
СКО -s
6 біт/1.0
7 біт /1.0
6 біт/1.0
7 біт /1.0
Таблиця 3. Продуктивність функцій прямого і зворотного ШПФ на процесорі NM6403
Кільк. комплекс. відліків
Без нормалізації
З однією нормалізацією
З двома нормализациями
Тактів
Аналіз задач і алгоритмів
До основних галузей, де використовується опрацювання сигналів та зображень відносяться:
1. Радіолокація (РЛ) — виявлення, фільтрація сигналу з режекцією завад та накопичення сигналу.
Особливості задач і алгоритмів.
Аналіз наведених задач і алгоритмів їх розв’язання показує, що вони мають такі особливості:
- широкий динамічний і частотний діапазон сигналів, що обробляються;
- велика інтенсивн
Особливості організації обчислювальних засобів
1.2.1. Методи аналізу обчислювальних засобів архітектур.Технічно системи керування та опрацювання інформації реалізуються як комплекс спеціалізованих і універсальних засобів обчисл
Основні положення алгоритму ШПФ
Визначення 1. Дано кінцеву послідовність x0, x1, x2,..., xN-1 (у загальному випадку комплексних чисел). ДПФ полягає в пошуку послідовності
Основні формули
Теореми, що пояснюють суть перетворення Фур’є (наведені без доведення).
Теорема 1. Якщо комплексне число представлене у вигляді e j2πN, де N - ціле, то
Програмна реалізація основних елементів ШПФ
Алгоритм попередньої перестановки
Розглянемо конкретну реалізацію ШПФ. Нехай є N=2T елементів послідовності x{N} і треба одержати послідовність
Fft.cpp
/*
Fast Fourier Transformation
=====================================================
*/
#include "fft.h"
// This array contains values from 0
Організація DSP- процесорів для задач опрацювання сигналів та зображень
Для опрацювання сигналів та зображень найчастіше використовуються DSP- процесори. Розглянемо підходи до їх реалізації на базі обчислення алгоритму ШПФ.
В загальному випадку, вимоги по вико
Типова структура процесора опрацювання сигналів та зображень
На рис. 3.1 наведена спрощена система на базі процесора ADSP-2189M, що використовує повномасштабну модель пам'яті.
Нтерфейси DSP-процесорів
Ефективність роботи DSP- процесора в структурі системи залежить від організації каналів вводу-виводу. До складу сучасних DSP- процесорів (наприклад, ADSP-21ESP202) входять інтегровані АЦП/ЦАП, що з
Аналіз паралельного інтерфейсу з DSP-процесорами: читання даних з АЦП, що під’єднаний до адресного простору пам’яті
Підключення АЦП або ЦАП через паралельний інтерфейс до DSP-процесора вимагає розуміння специфіки процесів читання/запису даних DSP-процесором з/в периферійних пристроїв при їх під’єднані до
Аналіз паралельного інтерейсу з DSP-процесорами: запис даних в ЦАП, що під’єднаний до адресного простору пам’яті
Спрощена блок-схема інтерфейсу між DSP-процесором і наприклад ЦАП) наведена на рис. 4.4. Діаграми циклу запису в пам'ять для сімейства ADSP-21xx наведені на рис.6.
В системах реального час
Аналіз послідовного інтерфейсу з DSP-процесорами
Наявність послідовного порту усуває необхідність використання паралельних шин для підключення АЦП і ЦАП до DSP-процесорів.
Структурна схема одного з двох послідовних портів процесора сімей
Проектування процесора ШПФ на ПОС
Алгоритм ШПФ із проріджуванням за часом
Нехай
Розділимо послідовність x(n) на парні (ev
Аналіз (розробка) блок-схеми виконання алгоритму ШПФ на заданому типі процесора
Алгоритм базової операції ШПФ за основою 4 і проріджування за часом можна представити так:
А'1 = А1 + A2W1 + A3W2 + A
Розрахунок основних параметрів
Частота роботи процесора: , звідси цикл виконання команди:
Привабливою рисою ПЛІС для реалізації алгоритмів ЦОС є наявність внутрішнього швидкодіючого розподіленого ОЗП, вбудованих вузлів обчислення ШПФ тощо.
На рис. 6.1 наведена структурна схема вузла реалізації алгоритм ШПФ на ПЛІС. Вхідне ОЗП використовується для завантаження вхідної послідовності, збереження результатів проміжних обчислень і виванта
Оцінка продуктивності вузла реалізації алгоритму ШПФ на ПЛІС
Швидкодія виконання алгоритму ШПФ на ПЛІС визначається в NMAC (кількість операцій типу множення-нагромадження) за такою формулою:
Побудова граф-алгоритму ШПФ з основою 2 наведена в попередніх розділах.
При апаратній реалізації графу ШПФ виникають незручності через неспівпадіння адрес комірок пам'яті з яких потрібно вичитувати елементи на кожному ярусі. Тому на рис.6.2. наведений граф, де для кожн
Реалізація алгоритмів опрацювання сигналів та зображень на нейропроцесорах
Нейрокомпьютер - це обчислювальна система з MSІMD архітектурою, тобто з паралельними потоками однакових команд і множинним потоком даних. На сьогодні можна виділити три основних напрямки розвитку о
ВЕКТОРНИЙ СПІВПРОЦЕСОР
Векторний співпроцесор - основний функціональний елемент Л1879ВМ1. Структурно він являє собою матрично-векторний операційний пристрій і набір регістрів різного призначення.
Операційний при
Організація паралельних обчислень в алгоритмах ШПФ на процесорі NM6403
Значна частина задач аналізу часових рядів зв'язана з перетворенням Фур'є і методами його ефективного обчислення. У цих задачах перетворення Фур'є відіграє важливу роль як необхідний проміжний крок
Продуктивність і точність обчислень.
Точність обчислень визначається кількістю біт, що відводяться для представлення коефіцієнтівW. Є два способи представлення значень косинусів і синусів у 8 розрядній сітці:
1. W =round(64.0
Загальна характеристика функцій ШПФ.
Вхідні і вихідні дані - цілі 32р. комплексні числа, формат збереження наведений на рис.3
Діапазон вхідних даних зазначений у таблиці 3.
Розрядність коефіцієнтів перетворення - 8 б
Стиск нерухомих зображень з використанням дискретних косинусних перетворень
Безвтратні методи стиску не забезпечують потрібного у багатьох випадках степеня стиску зображень. У цьому разі необхідно застосовувати методи стиску з втратою інформації. Одним із найбільш поширени
Стиск нерухомих зображень з використанням хвилькових перетворень
Поняття хвилькового перетворення
Дискретне хвилькове перетворення (dyscrete wavelet transform (DWT)) принципово відрізняється від спектральних перетворень.
На рис.8.3 показано стр
Стиск зображень з використанням методу кодування областей хвилькового перетворення
У цьому методі розглядаються області коефіцієнтів логарифмічного хвилькового перетворення зображення, які мають різні розміри. Ідея полягає в тому, щоб коефіцієнти в різних областях опрацьовувати (
Стиск зображень з використанням методу дерев нулів хвилькового перетворення
Хвильковий розклад зображення можемо мислити собі як просторову множину коефіцієнтів, яка складається з дерев. Дерево коефіцієнтів хвилькового перетворення означається як множина коефіцієнтів із рі
Адаптивні хвилькові перетворення : Хвилькові пакети.
Слід зауважити, що традиційний підхід використання хвилькових перетворень з фіксованою частотною роздільною здатністю (логарифмічне хвилькове перетворення) є добрий лише в загальному для типового с
Опрацювання мовних сигналів
Багато напрямків мовних технологій (опрацювання мовних сигналів з певною метою: стиск мовних сигналів, cинтез мови, зміна темпу мовлення, розпізнавання або визначення емоційного стану людини за гол
Мовні технології
Виділяють такі напрямки мовних технологій.
1. Стиск (кодування) мови.
Високого степеня стиску досягаємо використанням дискретних косинусних перетворень.
2. Синтез мови
Алгоритм динамічного часового вирівнювання для розпізнавання слів з невеликого словника
На фазі навчання як мовні еталони записуємо якнайкоротше вимовлені диктором слова із заданого невеликого словника.
Сигнал, який розпізнаємо, та сигнали-еталони параметризуємо – перетворюєм
Розпізнавання злитної мови з великим словником
Сучасні системи для розпізнавання злитної мови з великим словником ґрунтуються на принципах статистичного розпізнавання образів.
На першому етапі мовний сигнал перетворюється звуковий преп
Просочування спектральних складових
Вибір кінцевого часового інтервалу тривалістю NT секунд і ортогонального тригонометричного базису на цьому інтервалі обумовлює цікаву особливість спектрального розкладу. 3 континууму можливи
Вікна та їх основні параметри
В гармонійному аналізі вікна використовуються для зменшення небажаних ефектів просочування спектральних складових. Вікна впливають на можливість виявлення, роздільну здатність, динамічний діапазон,
Класичні вікна
Всі наведені вікна представляються як парні (щодо початку координат) і містять непарну кількість точок. Для перетворення вікна в ДПФ-парне вікно достатньо відкинути крайню праву точку і зсунути пос
Гармонійний аналіз
Проаналізуємо вплив властивостей вікна на ефективність виявлення слабої спектральної лінії у присутності інтенсивної близько розташованої лінії. Якщо обидві спектральні лінії потрапляють в біни ДПФ
Висновки
В даному навчальному посібнику описані основні алгоритми опрацювання сигналів та зображень та шляхи їх реалізації. Основна увага приділена системному підходу, який дозволяє розв’язати певну задачу,
Література
1. Айфигер, Эммануил С., Джервис, Барри У. Цифровая обработка сигналов: практический поход, 2-е изд.: Пер. с англ. – М.: Издательский дом “Вильямс”, 2004. – 992с.
2. Цифров
Рархічність засобів обробки радіолокаційної інформації.
Обробка радіолокаційної інформації (РЛІ) як правило складається з декількох етапів.
Первинна обробка РЛІ здійснюється апаратурою радіолокаційної станції (АПОІ РЛС) з видачею інформа
Особливості обробки радіолокаційної інформації. Вибір параметрів радіолокаційної станції, які впливають на характеристики засобів обробки.
Параметри:
- вид сигналу;
- потужність сигналу;
- тривалість зондувального сигналу /Тс/;
- оброблюваний доплерівский діапазон частот /F/ ;
Вимоги до системи
1. Система повинна будуватися на сучасній елементній базі з використанням відповідних міжнародним стандартам конструктивов і інтерфейсів
2. Система повинна мати модульну структуру і будува
Елементна база
Орієнтація на два механічних конструктива і на дві стандартні системні шини приводить до того, що можуть існувати три різних типи уніфікованих модулів:
1. Система на основі ПЕОМ із шинами
Архітектура системи
Пропонується комбінована архітектура на основі поділюваної системної шини і конфігурованих користувачем високопродуктивних прямих з'єднань модулів між собою для рішення задач високопродуктивної обр
Апаратна реалізація мережі
Вузли обчислювальної мережі виконані на процесорах TMS320C40 (TMS320C44), до яких підключена зовнішня оперативна пам'ять ємністю 512-1024 кбайт. У залежності від реалізації процесорного модуля (TІМ
Найпростіша первинна обробка РЛИ на МП мережі
Для відпрацьовування і реалізації на мультипроцесорній мережі найпростішого алгоритму первинної обробки даних було розроблено функціональне програмне забезпечення (ФПЗ), що реалізує алгоритм, зобра
Обмежувач.
· Алгоритм обчи
Порогові пристрої.
У системі реалізовані порогові пристрої з ковзним порогом. Значення порога обчислювалося по формулі
Таблиця 1. Часові параметри модулів ФПЗ, отримані в симуляторі.
Програма
Цикли
Час, мкс
Кількість операцій ПК
Vmax, (MFLOP)
Vвузла, (MFLOP)
СРЦ
Таблиця 2. Експериментально виміряні часові параметри модулів ФПЗ.
Програма
Цикли
Час, мкс
Кількість операцій ПК
Vmax, (MFLOP)
Vвузла, (MFLOP)
СРЦ
Призначення ПФОС.
Пристрій формування й обробки сигналів /ПФОС/ входить до складу когерентної далеко-доплерівської радіолокаційної станції, що працює в імпульсному чи квазінеперервному режимі випромінювання і прийом
Принцип побудови і структура ПФОС.
Пристрій формування й обробки сигналів побудовано по модульному принципі з нарощуванням структури і складається з окремих взаємозамінних програмно-апаратних модулів. Кожен програмно-апаратний модул
Технічна реалізація модуля.
Модуль формування й обробки сигналів реалізований на основі пристроїв програмувальної логіки фірм Xіlіnx, Altera і сигнальних процесорів фірми Analog Devіces. Основні технічні характеристики модуля
Модуль кодуючого пристрою .
Кодуючий пристрій призначений для :
· забезпечення режимів роботи РЛС і необхідних робочих шкал дальності;
· формування модулюючих сигналів , що задають закон амплітудно-фазової м
Режими роботи ПФОС.
ПФОС забезпечує формування й обробку сигналів у двох режимах випромінювання і прийому складних амплітудно-фазоманіпуляційних сигналів:
· у квазінеперервному режимі випромінювання й обробки
Квазінеперервний режим випромінювання й обробки.
При квазінеперервному режимі фазоманіпуляційний сигнал з великою базою (В=<256K) випромінюється окремими імпульсами, тривалість і інтервал проходження яких визначається структурою дискретного си
Практичне використання результатів і перспективи розвитку.
В даний час пристрої формування й обробки сигналів (ПФОС) використовуються в розробках, виконаних разом з ведучими НПО і НДІ м. Санкт-Петербурга.
Розроблені РЛС успішно пройшли натурні вип







Новости и инфо для студентов