рефераты конспекты курсовые дипломные лекции шпоры

- Раздел Транспорт
- /
- Бинарные деревья
Реферат Курсовая Конспект
Бинарные деревья
Бинарные деревья - раздел Транспорт, От автора В Этом Разделе Мы Рассмотрим Различные Алгоритмы Обхода...
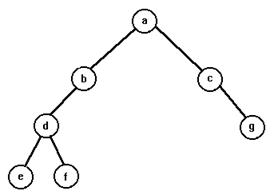
В этом разделе мы рассмотрим различные алгоритмы обхода бинарного дерева. К алгоритмам создания бинарного дерева мы обратимся несколько позже, а пока будем считать, что дерево уже создано и хранится в динамической памяти именно как древовидная структура (хотя это и не обязательно, можно хранить дерево в массиве, такой способ называется линейной проекцией дерева). Обойти дерево - значит обработать в заданном порядке все его вершины. В простейшем случае достаточно просто вывести значения всех элементов, записанных в вершинах дерева, тогда мы получим линейную запись дерева. Различают три различных способа обхода: префиксный, постфиксный и инфиксный. Префиксный обход осуществляется в последовательности корень - левое поддерево в префиксном порядке - правое поддерево в префиксном порядке. Обход в постфиксном порядке - это левое поддерево в постфиксном порядке - правое поддерево в постфиксном порядке - корень. Инфиксный обход - это обход в последовательности левое поддерево в инфиксном порядке - корень - правое поддерево в инфиксном порядке. Пусть, например, дерево имеет вид:

Тогда его префиксная запись - abdecfg, постфиксная запись - debfgca и инфиксная запись - dbeafcg. Часто используют скобочные постфиксную, префиксную и инфиксную записи дерева. В скобочной линейной записи запись каждого поддерева заключается в скобки. Так, в нашем примере скобочная префиксная запись имеет вид (a(b(d)(e))(c(f)(g))), скобочная постфиксная запись - (((d)(e)b)((f)(g)c)a), скобочная инфиксная запись - (((d)b(e))a((f)c(g))). Иногда опускают внешнюю пару скобок. Бесскобочные линейные записи дерева пригодны только для работы со строго бинарными деревьями, в которых все уровни заполнены и количество вершин равно 2h-1, где h - высота дерева, тогда по линейной бесскобочной записи можно однозначно восстановить структуру дерева, но если дерево не является строго бинарным, то различные деревья могут иметь одинаковые линейные записи. Пусть, например, дерево имеет вид:
В его скобочных линейных записях необходимо обозначать отсутствующие поддеревья всех вершин, кроме листьев; например, префиксная запись поддерева с корнем в c в виде c(g) недостаточна, так как неясно, каким именно потомком является g - левым или правым. Это поддерево необходимо записать в виде c()(g). Полные скобочные записи этого дерева имеют вид: префиксная - (a(b(d(e)(f))())(c()(g))) , постфиксная - ((((e)(f)d)()b)(()(g)c)a) , инфиксная - ((((e)d(f))b())a(()c(g))).
Известно много различных алгоритмов обхода бинарного дерева. Самый простой из них - это рекурсивный обход. Пусть дерево размещается в хипе и описано в программе в виде:
Type
PTree = ^TTree;
TTree = Record
I : Char;
L,R : PTree;
End;
Запишем рекурсивную процедуру префиксного обхода.
Procedure Prefix_Pass1(p:PTree);
Begin
Write(p^.I); {выводим корень поддерева}
If p^.L<>Nil Then Prefix_Pass1(p^.L);
{если есть левое поддерево, то обойдем его в префиксном порядке}
If p^.R<>Nil Then Prefix_Pass1(p^.R);
{если есть правое поддерево, то обойдем его в префиксном порядке}
End;
Не составляет никакого труда записать аналогичные процедуры для инфиксного и постфиксного обходов, а также получить с их помощью скобочные записи (просто вставив в нужные места операторы Write('('); и Write(')');). Этот алгоритм легко записать и нерекурсивной процедурой, используя стек отложенных заданий:
Procedure Prefix_Pass2(Root:PTree);
Var
Stack : Array[1..20] Of PTree;
Top : Byte;
p : PTree;
Begin
Top:=1;
Stack[Top]:=Root;
While Top>0 Do Begin
p:=Stack[Top];
Dec(Top);
Write(p^.I);
If p^.R<>Nil Then Begin Inc(Top); Stack[Top]:=p^.R; End;
If p^.L<>Nil Then Begin Inc(Top); Stack[Top]:=p^.L; End;
End;
End;
Другой алгоритм называют алгоритмом полного обхода дерева, он записывается практически одинаково для префиксного, инфиксного и постфиксного обходов и отличается лишь расположением операторов Write. В этом алгоритме каждая вершина дерева (кроме листьев) посещается трижды: в первый раз мы попадаем туда, двигаясь сверху, во второй раз - слева и в третий раз - справа. Так для дерева, изображенного на первом рисунке, полный обход будет выполняться в последовательности abdbebacfcgca, а для дерева, показанного на втором рисунке, - в последовательности abdedfdbbaccgca. Последовательность выполнения алгоритма такова: начиная с корня дерева двигаемся влево, пока это возможно, находясь в вершине, не имеющей левого потомка, делаем один шаг вправо и снова начинаем двигаться влево, если же вершина не имеет правого потомка (то есть является листом), то, двигаясь вверх, находим ближайшую вершину, имеющую правое поддерево, в левом поддереве которой находится данный лист, делаем шаг вправо и вновь продолжаем движение влево. Алгоритм заканчивается, когда для некоторого листа при движении вверх не найдена вершина с левым поддеревом, очевидно, что это самый правый лист дерева и поиск будет завершен в корне.
Разберем этот не вполне тривиальный алгоритм на примере второго из наших деревьев. Мы начинаем обход в вершине a. Двигаясь все время влево, посещаем вершины b,d,e. Вершина e - лист, поэтому начинаем движение вверх. Вершина d нам подходит, так как e принадлежит ее левому поддереву и у d есть правое поддерево, поэтому, находясь в d делаем шаг вправо: f. Вершина f - лист, начинаем движение вверх, d не подходит, b не подходит, a - подходящая вершина, делаем шаг вправо: с. Продолжаем движение влево, но у c нет левого поддерева, поэтому сразу же возвращаемся обратно: c -и делаем шаг вправо: g. Вершина g - лист, начинаем движение вверх, c не подходит, a не подходит, но дальше двигаться некуда, следовательно, обход завершен. Программная реализация алгоритма полного обхода возможна многими различными способами, самый простой из них, по мнению автора, использует дополнительное адресное поле U - адрес верхнего элемента. Опишем дерево в виде:
Type
Ptree = ^TTree;
Ttree = Record
I : Char;
L,R,U : PTree;
End;
предполагая, что все адресные поля при создании дерева были заполнены правильно, в частности, в поле U корневого элемента записан Nil.
Procedure Prefix_Pass3(Root:PTree);
Var p,pp : PTree;
Begin
p:=Root;
While True Do Begin
Write(p^.I);
{поместив этот оператор в другое место, получим другой способ обхода}
If p^.L<>Nil Then Begin p:=p^.L; Continue; End;
{движемся влево, если нет левого потомка - делаем шаг вправо}
If p^.R<>Nil Then Begin p:=p^.R; Continue; End;
{нет правого потомка - поднимаемся вверх, пока не достигнем вершины, имеющей правого потомка, в левом поддереве которой находится данная вершина, после чего делаем шаг вправо}
While True Do Begin
pp:=p^.U;
If pp=Nil Then Exit; {обход закончен}
If (pp^.L=p)And(pp^.R<>Nil) Then Begin
p:=pp^.R;
Break;
End;
p:=pp;
End;
End;
End;
В случае, если поле U отсутствует, можно использовать стек, добавляя в него адрес вершины при движении влево или вправо и извлекая адрес при движении вверх, в остальном алгоритм останется без изменений. Существуют и другие варианты записи алгоритма полного обхода.
Еще один способ обхода бинарного дерева - это обход сверху вниз, когда сначала обрабатывается корень, затем вершины первого уровня, затем все вершины второго уровня и так далее. Для дерева, изображенного на втором рисунке, обход сверху вниз выполняется в последовательности abcdgef. Рекурсивный алгоритм, реализованный в процедуре Prefix_Pass1, здесь не годится, алгоритм полного обхода также не подходит. Зато в этой задаче очень удобно использовать очередь. Запишем в очередь адрес корневого элемента дерева. Пока очередь не пуста, будем извлекать из нее адрес вершины, выводить ее и помещать в очередь адреса ее левого и правого потомков. Все вершины старшего уровня будут выведены раньше, чем вершины младшего уровня, так как они были записаны в очередь раньше. Стек для хранения адресов в этой задаче не годится. Очередь в процедуре Up_Down_Pass хранится в массиве, этот способ организации очередей уже обсуждался нами.
Procedure Up_Down_Pass(Root:PTree);
Const L_max=200;
Var
Q : Array[0..L_max-1] Of PTree;
Top,Len : Byte;
Procedure Empty;
Begin
Len:=0; Top:=0;
End;
Procedure Put(p:PTree);
Begin
Q[(Top+Len) Mod L_max]:=p; Inc(Len);
End;
Procedure Get(Var p:PTree);
Begin
p:=Q[Top]; Top:=(Top+1)Mod L_max; Dec(Len);
End;
Function EoQ : Boolean;
Begin
EoQ:=Len=0;
End;
Var p : PTree;
Begin
If Root=Nil Then Exit;
Empty; Put(Root);
While Not EoQ Do Begin
Get(p);
Write(p^.I);
If p^.L<>Nil Then Put(p^.L);
If p^.R<>Nil Then Put(p^.R);
End;
End;
– Конец работы –
Эта тема принадлежит разделу:
От автора
B r... Теперь мы можем присвоить переменным их значения...
Если Вам нужно дополнительный материал на эту тему, или Вы не нашли то, что искали, рекомендуем воспользоваться поиском по нашей базе работ: Бинарные деревья
Что будем делать с полученным материалом:
Если этот материал оказался полезным ля Вас, Вы можете сохранить его на свою страничку в социальных сетях:
| Твитнуть |
Хотите получать на электронную почту самые свежие новости?

Подпишитесь на Нашу рассылку
Реклама





Информация в виде рефератов, конспектов, лекций, курсовых и дипломных работ имеют своего автора, которому принадлежат права. Поэтому, прежде чем использовать какую либо информацию с этого сайта, убедитесь, что этим Вы не нарушаете чье либо право.
© copyright 1999 - 2024 allRefs.net. Все права защищены. Страница сгенерирована за: 0.023 сек.
Новости и инфо для студентов