Проверка количественных характеристик выборки - раздел Математика, Доклады по дисциплине Дополнительные главы математической статистики . Регрессионный анализ. 4 В §1 Были Определены Характеристики Генеральной Совокупности, Т.е. Принадлежн...
В §1 были определены характеристики генеральной совокупности, т.е. принадлежность к одной генеральной выборке, а также среднее и первый момент.
На данном этапе имеется функция распределения, которая визуально похожа на некоторое уже известное распределение. Но необходимо описать эту близость математически.
Итак , начнем с рассмотрения критериев согласия.
Критерий Согласияприменяется в задаче проверки согласия, суть которой заключается в следующем. Пусть X1, Х2, ..., Хn -независимые случайные величины, подчиняющиеся одному и тому же вероятностному закону, функция распределения которого F(x) неизвестна. В таком случае задача статистической проверки гипотезы Н0, согласно которой F(x) = F0(x), где F0(x) - некоторая заданная функция распределения, называемая задачей проверки согласия. Например, если F0(x) - непрерывная функция распределения, то в качестве критерия согласия для проверки гипотезы Н0 можно воспользоваться критерием Колмогорова или Смирного.
Предположим, что выборка произведена из генеральной совокупности с неизвестной теоретической функцией распределения, относительно которой имеются две непараметрические гипотезы: простая основная : F(x) = F0(x) и сложная конкурирующая : FF, где F(x) — известная функция распределения. Иными словами, мы хотим проверить, согласуются эмпирические данные с нашим гипотетическим предположением относительно теоретической функции распределения или нет. Поэтому критерии для проверки гипотез Ни Нносят название критериев согласия.
Пример. Гипотезу о том, что числа представляют собой независимые значения случайной величины, равномерно распределенной на отрезке , можно проверять с помощью критерия Колмогорова, основанного на статистике
,
где - эмпирическая функция распределения выборки. Соответствующая детерминистическая задача: можно ли с заданной точностью оценить интеграл произвольной функции f(x) из , усредняя значения . Формула
показывает, что это возможно тогда и только тогда, когда величина х достаточно мала.
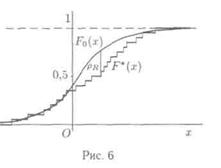
Критерий согласия Колмогорова. Уже говорилось (параграф 3 гл. 1), что в силу теоремы Гливенко-Кантелли эмпирическая функция распределения F*(x) представляет собой состоятельную оценку теоретической функции распределения F(x). Поэтому можно сравнить эмпирическую функцию распределения F*(x) с гипотетической F0(x) и, если мера расхождения между ними мала, то считать справедливой гипотезу H0.
Наиболее естественной и простой из таких мер (будем предполагать, что F(x) — непрерывная функция) является равномерное расстояние
(рис. 6). Однако при построении критерия
Колмогорова более удобно пользоваться нормированным расстоянием .
Итак, рассмотрим статистику
Критерий Колмогорова предписывает принять гипотезу H0, если <С, и отвергнуть в противном случае, где С — критическое значение критерия.
Если гипотеза Hсправедлива, то распределение статистики не зависит от гипотетической функции распределения F0(x) (доказательство этого факта следует из инвариантности статистики критерия Колмогорова относительно монотонных преобразований, в частности преобразования g(x)=F(x), где F(x) — обратная к F(x) функция; преобразование g(х) приводит выборку Х,...,Хк равномерно распределенной на отрезке (0,1)). Поэтому можно рассчитать таблицы, которые по заданному объему выборки и и критическому значению С позволяют определить уровень значимости критерия а. Поскольку на практике обычно, наоборот, считают известными уровень значимости а и объем выборки п, а затем по ним определяют критическое значение С.
При —> распределение статистики сходится к распределению Колмогорова [1, табл. 6.1], и критическое значение С при большом объеме выборки практически совпадает с (1-)-квантилью распределения Колмогорова.
При практической реализации критерия Колмогорова сначала по выборке Х,...,Хсоставляют вариационный ряд Х,…,Х. Затем находят F(X) и определяют значения статистики р по формуле
Наконец, сравнивают полученное значение с критическим значением С для заданного уровня значимости и принимают или отвергают гипотезу H.
Пример. Проверим с помощью критерия Колмогорова гипотезу Но том, что проекция X вектора скорости молекулы водорода на ось координат (см. пример 1 из гл. 1) распределена по нормальному закону. Проверку произведем для уровня значимости = 0,05. Параметры нормального закона не заданы, значит, мы имеем дело со сложной гипотезой Ни сначала должны оценить среднее и дисперсию - Поскольку мы будем пользоваться критерием Колмогорова, хотелось бы оценки и неизвестных параметров и выбрать таким образом, чтобы они доставляли минимальное значение статистики критерия Колмогорова
где — вариационный ряд выборки , приведенный в табл. 3 гл. 1, а — функция распределения
нормального закона с параметрами . Однако искать минимум
как функции от и — весьма сложная в вычислительном плане
задача, так как Ф(х) даже не выражается в элементарных функциях-
Поэтому в качестве оценок и используем оценки максимального правдоподобия и (см. примеры 8 из гл. 1 и 15 из гл.2). Теперь с помощью критерия Колмогорова будем проверять простую гипотезу . Вычислив сначала и воспользовавшись равенством последовательно находим затем значения (1, c. 112-117), b (табл.2). Наконец, определяя значение статистики критерия Колмогорова
(максимальное значение равно 0,06) и сравнивая его с 0,95-квантилью распределения Колмогорова , видим, что <.Значит, мы должны принять гипотезу Ни считать распределение проекции вектора скорости молекулы водорода нормальным.
Критерий Шапиро-Уилка. Базируется на анализе линейной комбинации разностей порядковых статистик, используют при объемах выборки 8££50. Рекомендуют применять при отсутствии априорной информации о типе возможного отклонения от нормальности. Критерий Шапиро-Уилкаhttp://www.ami.nstu.ru/%7Eheadrd/Kurs_projekt.htm - _ftn5 используют в тех случаях, когда в качестве альтернативы можно выбрать гипотезу следующего вида: примерно симметричное распределение с <1/2 и <3 или асимметричное распределение (например, >1/2). В противном случае рекомендуют критерий Эппса-Палли. Для вариационного ряда , построенного по наблюдаемой выборке , вычисляют величину
(159)
где индекс изменяется от 1 до или от 1 до при четном и нечетном соответственно. Статистика критерия имеет вид
. (160)
Гипотеза о нормальности отвергается при малых значениях статистики .
Критерий Эппса-Палли. Базируется на сравнении эмпирической и теоретической характеристических функциях, применяют при 8200. По наблюдаемой выборке вычисляют статистику критерия
, (161)
где , .
Гипотезу о нормальности отвергают при больших значениях статистики.
Модифицированный критерий Шапиро-Уилка. Применяется для нескольких независимых выборок одинакового объема 850, когда отдельная выборка слишком мала, чтобы обнаружить отклонения от нормальности. Предполагается, что выборок одного и того же объема взято из одной генеральной совокупности. Для каждой выборки в соответствии с соотношением (160) подсчитывают значения , . Вычисляют значения
, (161)
где
, (162)
а коэффициенты , и табулированы. Если наблюдаемое распределение нормальное, то переменные приблизительно подчиняются стандартному нормальному закону. В качестве статистики критерия используется величина
, (163)
где
. (164)
Гипотеза о нормальности отклоняется, при уровне значимости , если
< , (165)
где – соответствующий квантиль стандартного нормального распределения.
Содержание... Регрессионный анализ Теоретическая часть работы...
Если Вам нужно дополнительный материал на эту тему, или Вы не нашли то, что искали, рекомендуем воспользоваться поиском по нашей базе работ:
Проверка количественных характеристик выборки
Что будем делать с полученным материалом:
Если этот материал оказался полезным ля Вас, Вы можете сохранить его на свою страничку в социальных сетях:
Виды регрессионного анализа
Многошаговая регрессия (ШРА) — последовательность шагов РА, выполняемая в направлении увеличения или уменьшения количества учитываемых коэффициентов линейной модели регрессии.
Линейная регрессия
Регрессионный анализ - раздел математической статистики, объединяющий практические методы исследования регрессионной зависимости между величинами по статистическим данным. Проблема
Описание объекта
В нашем случае объектом исследования является совокупность наблюдений за посещаемостью WEB сайта Комитета по делам семъи и молодежи Правительства г. Москвы www.telekurs.ru/ismm. Тематика сайта – эт
Факторы формирующие моделируемое явление
Отбор факторов для модели осуществляется в два этапа. На первом идет анализ, по результатам которого исследователь делает вывод о необходимости рассмотрения тех или иных явлений в качестве переменн
Построение уравнения регрессии
Используя программное обеспечение «ОЛИМП» (которое в свою очередь использует для расчетов указанные выше принципы и формулы чем значительно облегчает нам жизнь), найдем искомое урав
Смысл модели
При увеличении количества вакансий в день, количество посетивших сайт людей будет увеличиваться . Это означает что в настоящий момент сайт не полностью удовлетворяет запросы пользователей, что необ
Общее назначение
Любой закон природы или общественного развития может быть выражен в конечном счете в виде описания характера или структуры взаимосвязей (зависимостей), существующих между изучаемыми явлениями или
Оценивание линейных и нелинейных моделей
Формально говоря, Нелинейное оценивание является универсальной аппроксимирующей процедурой, оценивающей любой вид зависимости между переменной отклика и набором независимых переменных. В общ
Регрессионные модели с линейной структурой
Полиномиальная регрессия. Распространенной “нелинейной” моделью является модель полиномиальной регрессии. Термин нелинейная заключен в кавычки, поскольку эта модель линейна
Существенно нелинейные регрессионные модели
Для некоторых регрессионных моделей, которые не могут быть сведены к линейным, единственным способом для исследования остается Нелинейное оценивание. В приведенном выше примере для скорости
Регрессионные модели с точками разрыва
Кусочно - линейная регрессия. Нередко вид зависимости между предикторами и переменной отклика различается в разных областях значений независимых переменных. Например,
Методы нелинейного оценивания
Метод наименьших квадратов Функция потерь Метод взвешенных наименьших квадратов Метод максимума правдоподобия Максимум правдоподобия и логит/пробит мод
Начальные значения, размеры шагов и критерии сходимости.
Общим моментом всех методов оценивания является необходимость задания пользователем некоторых начальных значений, размера шагов и критерия сходимости алгоритма. Все методы начинают свою работу с ос
Оценивание пригодности модели
После оценивания регрессионных параметров, существенной стороной анализа является проверка пригодности модели в целом. Например, если вы определили линейную регрессионную модель, а реальная зависим
Распределения Вейбулла - Гнеденко
Экспоненциальные распределения - частный случай так называемых распределений Вейбулла - Гнеденко. Они названы по фамилиям инженера В. Вейбулла, введшего эти распределения в практику анализа результ
Распределение Рэлея
Распределение Рэлея введено Дж. У. Рэлеем (1880) в связи с задачей сложения гармонических колебаний со спиральными фазами. Закон Рэлея применяется для описания неотрицательных величин, в частности,
Факторный анализ как метод редукции данных
Под редукцией понимается переход от многих исходных количественных признаков к пространству факторов, число которых значительно меньше числа исходных количественных признаков. Например, от исходных
Общий обзор методов факторного анализа
В основе каждого метода факторного анализа лежит математическая модель, описывающая соотношения между исходными признаками и обобщенными факторами. Перейдем к краткой характеристике этих моделей дл
Метод главных компонент
В основе модели для выражения исходных признаков через факторы здесь лежит предположение о том, что число факторов равно числу исходных признаков (k=m), а характерные факторы вообще отсутств
Центроидный метод
Этот метод основан на предположении о том, что каждый из исходных признаков aj(j = 1...m) может быть представлен как функция небольшого числа
общих факторов F1
Метод экстремальной группировки параметров
Данный метод также основан на обработке матрицы коэффициентов корреляции между исходными признаками. В основе этого метода лежит гипотеза о том, что совокупность исходных признаков может быть разби
Критерии рационального выбора числа факторов
Сколько факторов следует выделять?Напомним, что анализ главных компонент является методом сокращения или редукции данных, т.е. методом сокращения числа переменных. Возникает естест
Проверка качественных характеристик выборки
Будем рассматривать критерии однородности.
Любой статистически критерий проверки гипотез представляет собой средство измерения. Поэтому пользоваться им следует также квалифицированно, как
Метод минимального расстояния
Равномернаяметрика,или метрика Колмогорова, - одна из наиболее старых и наиболее часто используемых вероятностных метрик. Термин «метрика Колмогорова» в отечественной литературе ис
Иерархические методы кластерного анализа
Суть иерархической кластеризации состоит в последовательном объединении меньших кластеров в большие или разделении больших кластеров на меньшие.
Иерархические аглом
Меры сходства
Для вычисления расстояния между объектами используются различные меры сходства (меры подобия), называемые также метриками или функциями расстояний.
Для придания больших весов более отдале
Методы объединения или связи
Когда каждый объект представляет собой отдельный кластер, расстояния между этими объектами определяются выбранной мерой. Возникает следующий вопрос — как определить расстояния между кластерами? С
Иерархический кластерный анализ в SPSS
Рассмотрим процедуру иерархического кластерного анализа в пакете SPSS (SPSS). Процедура иерархического кластерного анализа в SPSS предусматривает группировку как объектов (строк матрицы данных), т
Определение количества кластеров
Существует проблема определения числа кластеров. Иногда можно априорно определить это число. Однако в большинстве случаев число кластеров определяется в процессе агломерации/разделения множества об
Итеративный процесс.
Вычисляются центры кластеров, которыми затем и далее считаются покоординатные средние кластеров. Объекты опять перераспределяются.
Процесс вычисления центров и перераспределения объектов п
Проверка качества кластеризации
После получений результатов кластерного анализа методом k-средних, следует проверить правильность кластеризации (т.е. оценить, насколько кластеры отличаются друг от друга). Для этого рассчитывают
Алгоритм BIRCH
(Balanced Iterative Reducing and Clustering using Hierarchies)
Алгоритм предложен Тьян Зангом и его коллегами.
Благодаря обобщенным представлениям кластеров, скорость кластеризаци
Алгоритм WaveCluster
WaveCluster представляет собой алгоритм кластеризации на основе волновых преобразований . В начале работы алгоритма данные обобщаются путем наложения на пространство данных многомерной решетки. Н
Алгоритмы Clarans, CURE, DBScan
Алгоритм Clarans (Clustering Large Applications based upon RANdomized Search) формулирует задачу кластеризации как случайный поиск в графе. В результате работы этого алгоритма совокупность узлов гр
Многофакторный дисперсионный анализ
Следует сразу же отметить, что принципиальной разницы между многофакторным и однофакторным ДА нет. Многофакторный анализ не меняет общую логику ДА, а лишь несколько усложняет ее, поскольку, кроме у
Биотестирование почвы
Многообразные загрязняющие вещества, попадая в агроценоз, могутпретерпевать в нем различные превращения, усиливая при этом свое токсическое действие. По этой причине оказались необх
Дисперсионный анализ в химии
ДА – совокупность методов определения дисперсности, т. е. характеристики размеров частиц в дисперсных системах. ДА включает различные способы определения размеров свободных частиц в жидких и газовы
Хотите получать на электронную почту самые свежие новости?
Подпишитесь на Нашу рассылку
Наша политика приватности обеспечивает 100% безопасность и анонимность Ваших E-Mail

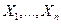
 произведена из генеральной совокупности с неизвестной теоретической функцией распределения, относительно которой имеются две непараметрические гипотезы: простая основная
произведена из генеральной совокупности с неизвестной теоретической функцией распределения, относительно которой имеются две непараметрические гипотезы: простая основная  : F(x) = F0(x) и сложная конкурирующая
: F(x) = F0(x) и сложная конкурирующая  : F
: F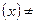 F
F
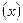
 , где F
, где F носят название критериев согласия.
носят название критериев согласия. представляют собой независимые значения случайной величины, равномерно распределенной на отрезке
представляют собой независимые значения случайной величины, равномерно распределенной на отрезке  , можно проверять с помощью критерия Колмогорова, основанного на статистике
, можно проверять с помощью критерия Колмогорова, основанного на статистике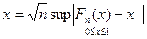 ,
, - эмпирическая функция распределения выборки
- эмпирическая функция распределения выборки , усредняя значения
, усредняя значения 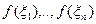 . Формула
. Формула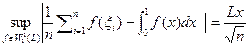
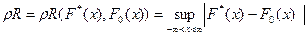
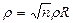 .
.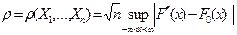
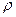 <С, и отвергнуть в противном случае, где С — критическое значение критерия.
<С, и отвергнуть в противном случае, где С — критическое значение критерия.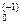 (x), где F
(x), где F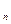 к равномерно распределенной на отрезке (0,1)). Поэтому можно рассчитать таблицы, которые по заданному объему выборки и и критическому значению С позволяют определить уровень значимости критерия а. Поскольку на практике обычно, наоборот, считают известными уровень значимости а и объем выборки п, а затем по ним определяют критическое значение С.
к равномерно распределенной на отрезке (0,1)). Поэтому можно рассчитать таблицы, которые по заданному объему выборки и и критическому значению С позволяют определить уровень значимости критерия а. Поскольку на практике обычно, наоборот, считают известными уровень значимости а и объем выборки п, а затем по ним определяют критическое значение С.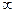 распределение статистики
распределение статистики  )-квантилью
)-квантилью  распределения Колмогорова.
распределения Колмогорова. ,…,Х
,…,Х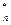 . Затем находят F
. Затем находят F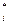 ) и определяют значения статистики р по формуле
) и определяют значения статистики р по формуле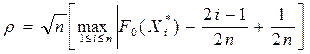
 и дисперсию
и дисперсию  - Поскольку мы будем пользоваться критерием Колмогорова, хотелось бы оценки
- Поскольку мы будем пользоваться критерием Колмогорова, хотелось бы оценки 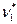 и
и  неизвестных параметров
неизвестных параметров 
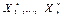 — вариационный ряд выборки
— вариационный ряд выборки  — функция распределения
— функция распределения . Однако искать минимум
. Однако искать минимум 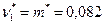 и
и 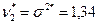 (см. примеры 8 из гл. 1 и 15 из гл.2). Теперь с помощью критерия Колмогорова будем проверять простую гипотезу
(см. примеры 8 из гл. 1 и 15 из гл.2). Теперь с помощью критерия Колмогорова будем проверять простую гипотезу  . Вычислив сначала
. Вычислив сначала  и воспользовавшись равенством
и воспользовавшись равенством  последовательно находим затем значения
последовательно находим затем значения  (1, c. 112-117),
(1, c. 112-117),  b
b 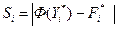 (табл.2). Наконец, определяя значение статистики критерия Колмогорова
(табл.2). Наконец, определяя значение статистики критерия Колмогорова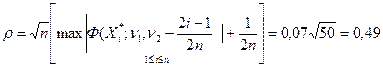
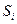 равно 0,06) и сравнивая его с 0,95-квантилью распределения Колмогорова
равно 0,06) и сравнивая его с 0,95-квантилью распределения Колмогорова  , видим, что
, видим, что  .Значит, мы должны принять гипотезу Н
.Значит, мы должны принять гипотезу Н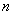 £50. Рекомендуют применять при отсутствии априорной информации о типе возможного отклонения от нормальности. Критерий Шапиро-Уилкаhttp://www.ami.nstu.ru/%7Eheadrd/Kurs_projekt.htm - _ftn5 используют в тех случаях, когда в качестве альтернативы можно выбрать гипотезу следующего вида: примерно симметричное распределение с
£50. Рекомендуют применять при отсутствии априорной информации о типе возможного отклонения от нормальности. Критерий Шапиро-Уилкаhttp://www.ami.nstu.ru/%7Eheadrd/Kurs_projekt.htm - _ftn5 используют в тех случаях, когда в качестве альтернативы можно выбрать гипотезу следующего вида: примерно симметричное распределение с  <1/2 и
<1/2 и 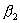 <3 или асимметричное распределение (например,
<3 или асимметричное распределение (например, 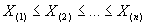 , построенного по наблюдаемой выборке
, построенного по наблюдаемой выборке 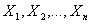 , вычисляют величину
, вычисляют величину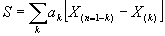 (159)
(159)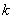 изменяется от 1 до
изменяется от 1 до 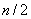 или от 1 до
или от 1 до 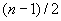 при четном и нечетном
при четном и нечетном  . (160)
. (160) .
. , (161)
, (161)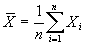 ,
,  .
.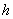 выборок одного и того же объема
выборок одного и того же объема  ,
, 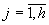 . Вычисляют значения
. Вычисляют значения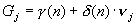 , (161)
, (161)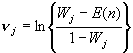 , (162)
, (162) ,
,  и
и 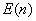 табулированы. Если наблюдаемое распределение нормальное, то переменные
табулированы. Если наблюдаемое распределение нормальное, то переменные 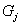 приблизительно подчиняются стандартному нормальному закону. В качестве статистики критерия используется величина
приблизительно подчиняются стандартному нормальному закону. В качестве статистики критерия используется величина , (163)
, (163)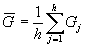 . (164)
. (164) о нормальности отклоняется, при уровне значимости
о нормальности отклоняется, при уровне значимости  , если
, если , (165)
, (165)





Новости и инфо для студентов