рефераты конспекты курсовые дипломные лекции шпоры

- Раздел Социология
- /
- Повторные измерения
Реферат Курсовая Конспект
Повторные измерения
Повторные измерения - раздел Социология, ВВЕДЕНИЕ В ПРОБЛЕМУ СТАТИСТИЧЕСКОГО ВЫВОДА Структура Исходных Данных Соответствует Ситуации, Когда Одна Выборка Объектов...
Структура исходных данных соответствует ситуации, когда одна выборка объектов классифицирована на две группы дважды по одному и тому же основанию. Рассмотрим проверку гипотезы в отношении таких данных на примере.
ПРИМЕР 9,6___________________________________________________________
Исследовалось влияние убедительной лекции о введении моратория на смертную казнь. Число респондентов 7V= 60. Подсчитывалось число тех, кто «за», и тех, кто «против» смертной казни до и после лекции. Одна переменная — «до лекции» («за», «против»), другая — «после лекции» («за», «против»).

|
| Для таких данных х2-Пирсона с поправкой на непрерывность не применим! |
| 1 См. там же. |
В таблице исходных данных в таких случаях каждой строке (объекту выборки) соответствуют два значения (в двух столбцах — «до», «после») одной и той же бинарной номинативной переменной («за», «против»). Таблица сопряженности для таких данных (например, построенная при помощи компьютерной программы):
ЧАСТЬ II. МЕТОДЫ СТАТИСТИЧЕСКОГО ВЫВОДА: ПРОВЕРКА ГИПОТЕЗ
Действительно, применяя этот метод, мы будем проверять гипотезу о связи классификации ответов до лекции с классификацией ответов после лекции, а нас интересует влияние лекции («до» — «после») на распределение ответов («за» — «против»). Тем не менее, попробуем применить %2-Пирсона с поправкой на непрерывность к этой таблице. Получим: xl =0,93, df— 1,/?>0,1-
В подобных случаях применяется метод Мак-Нимара. Этот метод позволяет сопоставить долю тех, кто не обладал некоторой характеристикой (0) до воздействия, но стал обладать ею после воздействия (1), с долей тех, кто обладал этой характеристикой до воздействия (1) и перестал обладать ею после воздействия (0). Иначе говоря, метод позволяет сопоставить диагональные элементы таблицы сопряженности 2x2 (0,1 и 1,0 или 0,0 и 1,1), построенной непосредственно по дважды проведенной дихотомической классификации одной и той же выборки. Речь идет о таблице 2x2, построенной непосредственно по результатам дихотомической классификации двух зависимых выборок (одной и той же выборки — дважды):

|
Метод Мак-Нимара позволяет по этой таблице проверить две гипотезы: о соотношении а и ^/(0,1 и 1,0); о соотношении си b (0,0 и 1,1).
Проверка гипотезы проводится по г-критерию по формулам для эмпири-
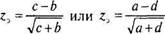
|
ческого значения
(9.5)
где с и Ъ — одна пара диагональных элементов таблицы, для проверки одной гипотезы; а и d — другая пара диагональных элементов, для проверки другой гипотезы. Для определения р-уровня значимости эмпирическое значение z3 сравнивается с теоретическим — единичным нормальным распределением.
Ограничение на применение метода Мак-Нимара: сумма сравниваемых частот не должна быть меньше 10.
ПРИМЕР 9.6 (продолжение)
 Рассмотрим применение метода Мак-Нимара на примере проверки содержательной гипотезы о влиянии лекции на мнение респондентов (данные примера 9.6).
Рассмотрим применение метода Мак-Нимара на примере проверки содержательной гипотезы о влиянии лекции на мнение респондентов (данные примера 9.6).
Ш а г 1. Построение таблицы 2x2.
| До: | |||
| «За» | «Против» | ||
| После: | «За» | а — 16 | Ь= 10 |
| «Против» | с-26 | d=% |
 1 Данная реализация метода заимствована из: Гласе Дж., Стенли Дж. Статистические методы в педагогике и психологии. М., 1976. В программе SPSS используется критерий х2-
1 Данная реализация метода заимствована из: Гласе Дж., Стенли Дж. Статистические методы в педагогике и психологии. М., 1976. В программе SPSS используется критерий х2-
ГЛАВА 9. АНАЛИЗ НОМИНАТИВНЫХ ДАННЫХ
Ш а г 2. Формулировка статистической гипотезы.
Проверим Но: с = b (ненаправленная гипотеза), при а = 0,05.
Отметим, что проверка гипотезы относительно других диагональных элементов
(Но: a =d) в данном случае не имеет смысла.

|
Шаг 3, Вычисление эмпирического значения критерия.
с-Ь 26-10
Ш а г 4. Определение /ьуровня (приложение 1).
Воспользуемся таблицей единичного нормального распределения:
а) находим в таблице теоретическое значение z, ближайшее меньшее к абсолютно
му (без учета знака) эмпирическому значению гэ: ZT ~ 2,65;
б) определяем площадь под кривой справа от z?- P= 0,004;
в) вычисляем/^-уровень по формуле/) < 2Р: р < 0,008.
Ш а г 5. Принятие статистического решения и статистический вывод. На уровне а = 0,05 гипотеза Нц отклоняется. Содержательный вывод: доля лиц, выступающих против смертной казни после лекции статистически значимо увеличилась (z = 2,67; р < 0,008).
Обработка на компьютере: таблицы сопряженности (кросстабуляции)
Последовательность шагов не зависит от количества градаций и зависимости выборок. Указанные обстоятельства влияют только на то, какие из результатов следует принимать во внимание.
Исходные данные: значения двух номинативных переменных (2 и более градации), с одинаковым или разным числом градаций, определены на одной выборке объектов и представлены двумя столбцами — по одному для каждой из переменных.
Выбираем: Analyze(Метод) > Descriptive Statistics(Описательные статистики) > Crosstabs...(Таблицы сопряженности). В открывшемся окне диалога переносим одну из переменных справа в окно Строки (Row(s)), другую — в окно Столбцы (Column(s)),нажимаем кнопку Статистики (Statistics...).
Решаем: Если выборки независимые (без повторных классификаций), выбираем у}, отмечая его «флажком» (Chi-square).Если выборки зависимые: одна и та же номинативная переменная (2 градации) измерена дважды на данной выборке, то выбираем метод Мак-Нимара, отмечая его «флажком» (McNemar).Нажимаем (Continue).Нажимаем ОК.
Результаты
A) Сводка по обработанным объектам (Case Processing Summary) — сколь
ко обработано (Valid), сколько пропущено (Missing), сколько всего (Total).
Б) Таблица сопряженности (Crosstabulation).
B) Таблица статистических результатов (Chi-Square Tests):
ЧАСТЬ 11. МЕТОДЫ СТАТИСТИЧЕСКОГО ВЫВОДА: ПРОВЕРКА ГИПОТЕЗ
□ эмпирические значения критериев (Value);
П двусторонний /ьуровень для х2-Пирсона без поправки (с поправкой) на непрерывность (Pearson Chi-Square (Continuity Correction) — Asymp. Sig. (2-sided));
□ односторонний /^-уровень для направленных гипотез по Фишеру
(Fisher's Exact Test — Exact Sig. (1-sided));
О двусторонний /^-уровень для критерия Мак-Нимара (McNemar Test — Exact Sig. (2-sided)).
Примечание. Если обрабатываются таблицы 2x2 с независимыми классификациями, то при проверке направленных гипотез значение ^-уровня для //-Пирсона (Pearson Chi-Square — Asymp. Sig. (2-sided)) делится на два, либо берется односторонний/^-уровень (Exact Sig. (I-sided)) для точного критерия Фишера (Fisher's Exact Test).
АНАЛИЗ ПОСЛЕДОВАТЕЛЬНОСТИ: КРИТЕРИЙ СЕРИЙ
Как следует из названия, метод применяется для анализа последовательности объектов (явлений, событий), упорядоченных во времени или в порядке возрастания (убывания) значений измеренного признака. Кроме того, метод требует представления последовательности в виде бинарной переменной — как чередования событий 0 и 1. Поэтому исходные донные, как правило, требуют преобразования: упорядочивания (по времени или по уровню) и приведения к бинарному виду.
Математическая идея критерия основана на подсчете числа серий в упорядоченной последовательности событий двух типов, например, 0 и 1. Серия — это последовательность однотипных событий, непосредственно перед и после которой произошли события другого типа. Гипотеза Но о случайном распределении событий 1 среди событий 0 может быть отклонена, если количество серий либо слишком мало, либо слишком велико.
ПРИМЕР 9,7___________________________________________________________
Предположим, было получено две последовательности успехов (1) и неудач (0) для двух игроков. Каждый из них играл 20 раз с равным количеством выигрышей (п = 10) и проигрышей (т = 10): п + т = 20.
Игрок № 1: 100000000111111011! 0 —число серий W= 6 Игрок №2: 01010010101011010011- число серий W= 16 В отношении первого игрока Но будет отклонена, если число серий слишком мало, а в отношении второго игрока — если число серий слишком велико. При отклонении Но для первого игрока может быть сделан вывод о том, что достоверно чаще после успеха следует успех, а после проигрыша — проигрыш, а для второго игрока, что после проигрыша достоверно чаще следует выигрыш, и наоборот.
ГЛАВА 9. АНАЛИЗ НОМИНАТИВНЫХ ДАННЫХ
Проблема направленности гипотезы Но должна решаться еще до проведения исследования. Понятно, что исследователя может интересовать любое отклонение от Но — как в сторону слишком малого, так и слишком большого числа серий W, Тогда необходима проверка ненаправленной гипотезы. Если же исследователя интересуют только малые значения Жили только слишком большие значения W, то необходима проверка направленной гипотезы. Важность предварительного определения направленности гипотезы обусловлена тем, что при одном и том же числе серий Wр-уровень для направленной гипотезы будет в два раза меньше, чем для ненаправленной гипотезы. Любые сомнения в направленности гипотезы необходимо решать в пользу выбора ненаправленной альтернативы.
Предположим, что для исследователя, получившего данные из примера 9.7, заранее не было известно, какая альтернатива будет приниматься в случае отклонения Но. Следовательно, должна проверяться ненаправленная Но, допускающая отклонение Но как в случае слишком малого, так и в случае слишком большого числа серий W.
Точное распределение числа серий Жпри выполнении Но, следовательно, и точное значение р-уровня значимости для конкретного ^(при конкретных значениях тип) может быть получено с помощью комбинаторного анализа, например, при помощи компьютера.
При вычислениях на компьютере точное значение /j-уровня может быть вычислено при выборе опции Exact... (Точно...) в диалоге анализа Runs... (Серии...) с последующим заданием метода Monte Carlo. Так, для примера 9.7 точные значения^-уров-ня (для ненаправленных Но, двусторонние): для игрока № 1 р = 0,035; для игрока

Если численность т{п) < 20, то для проверки Но применяются таблицы критических значений для числа серий (приложение 5).
ПРИМЕР 9.7 (продолжение)_______________________________________________
Проверим ненаправленную Но в отношении двух игроков с использованием таблицы критических значений числа серий для а = 0,05 (приложение 5). Для этого достаточно соотнести эмпирическое значение числа серий с табличными значениями (нижним Жо 025и верхним ¥0 0975). Если эмпирическое значение меньше или равно 1^0025 или больше или равно ¥0(>975, T0 Но отклоняется.
Шаг 1. Принимаем статистические решения. Для т= 10, п= 10: И^з^б; Н^ 0975 — 16. Для игрока №1: (Сэ = 6, Но отклоняется. Для игрока № 2: W3 - 16, Но отклоняется.
Шаг 2. Формулируем содержательные выводы. Для игрока № 1: достоверно чаще после успеха следует успех, а после проигрыша — проигрыш (р< 0,05). Для игрока № 2: после проигрыша достоверно чаще следует выигрыш, а после выигрыша — проигрыш.
Альтернативным способом определения р-уровня является применение Z-критерия серий, основанного на том факте, что число серий Wпри выпол-
ЧАСТЬ П. МЕТОДЫ СТАТИСТИЧЕСКОГО ВЫВОДА: ПРОВЕРКА ГИПОТЕЗ
нении Но распределено приблизительно нормально с известными Mw и aw. Формула для определения эмпирического значения Z-критерия серий1:

|
Ограничение на применение Z-критерия серий: т > 20, п > 20; т и п несущественно различаются. Если тип существенно различаются, то следует воспользоваться комбинаторным методом (например, Монте Карло в программе SPSS).
ПРИМЕР9.8____________________________________________________________
Предположим, исследуется динамика научения в игровом задании. Исследователь предполагает частые повторы проигрышей в начале и выигрышей — в конце последовательности игр (предполагается проверка направленной гипотезы). Игроком сыграно 40 партий, из них проиграно 20, выиграно 20, число серий 15. К концу последовательности игр наблюдается преобладание выигрышей. Проверим гипотезу с применением Z-критерия серий.
Шаг 1. Формулируем Но: число серий соответствует случайному распределению выигрышей в последовательности проигрышей (альтернативная Н,: число серий достаточно мало, чтобы говорить о неслучайном преобладании выигрышей в конце последовательности игр). Принимаем а = 0,05.

|
Ш а г 2. Вычислим эмпирическое значение Z-критерия для т = 20; п = 20; И^ =15:
Mw= + 2nm/(n+m)=2;
Ш а г З. Определим/ьуровень. Для этого воспользуемся таблицей стандартных нормальных вероятностей (приложение 1). При использовании Z-распределения для проверки направленной гипотезыр-уровень равен площади Рпод нормальной кривой справа от +Z, (слева от -Z,). Z, = 1,76 соответствует площадь Р= 0,039. Следовательно, р < 0,04.
Ш а г 4. Принимаем статистическое решение и формулируем содержательный вывод. Отклоняем Но: число серий статистически значимо мало. Содержательный вывод: к концу последовательности игр статистически достоверно возрастает частота выигрышей (р < 0,04).
Отметим, что если бы проверялась ненаправленная гипотеза, то найденное значение вероятности Р = 0,039 следовало бы умножить на 2: р < 2Р. Следовательно, р < 0,078, и Но на уровне а = 0,05 не отклоняется.
Критерий серий применим для решения двух классов задач. Помимо исследования временной последовательности событий Хи Y, или динамики изменения количественного признака, метод может применяться и для провер-
 1 По Ллойду Э., Ледерману У, с. 131. 144
1 По Ллойду Э., Ледерману У, с. 131. 144
ГЛАВА 9. АНАЛИЗ НОМИНАТИВНЫХ ДАННЫХ
ки гипотез о различии между двумя выборками по уровню и изменчивости признака, измеренного в количественной шкале. В связи с этим применение метода требует решения проблемы преобразования исходных данных.
Проблема преобразования исходных данных. Как было отмечено, для применения метода данные необходимо представить в виде одной бинарной переменной. В зависимости от задачи исследования и вида исходных данных это может быть сделано разными способами.
1. Если изучается динамика изменчивости количественного признака, то
после упорядочивания значений признака в соответствии с временной после
довательностью выбирается один из способов перехода к бинарной шкале. Для
метрических данных точкой деления (Cut point) обычно выступает среднее, а
для ранговых данных — медиана. Значениям ниже точки деления присваива
ется 0, а значениям выше нее — 1. После такого преобразования возможно
применение к переменной критерия серий.
2. Если изучается различие между выборками по уровню и (или) изменчи
вости количественного признака, то сначала объекты упорядочиваются по
уровню выраженности изучаемой переменной. Затем объектам одной выбор
ки присваивается 0, а объектам другой — 1. Критерий серий применяется к
полученной таким образом последовательности нулей и единиц. Преимуще
ство критерия серий, по сравнению с другими методами сравнения выборок,
проявляется в том, что он позволяет выявить не только уровневые различия
(в этом его чувствительность не очень высока), но и соотношение распреде
лений. Например, одно распределение может быть более компактным, чем
другое.
Обработка на компьютере: анализ последовательности
Исходные данные: изучаемый признак (столбец) представляет собой упорядоченную последовательность значений (по времени или по уровню выраженности). Если это последовательность во времени, то допустимы количественные значения. Если значения не количественные, то они должны представлять собой последовательность 0 и 1.
Выбираем: Analyze(Метод) > Nonparametric tests...(Непараметрические методы) > Runs...(Серии). В открывшемся окне диалога переносим необходимую переменную из левого вправое окно (Test Variable List),переменных может быть несколько.
Решаем: Выбираем точку деления (Cut point).Если переменная бинарная (0,1), то ставим флажок только в окошко Пользовательская и задаем «1» (Custom: 1).Если переменная количественная, то выбираем либо медиану (Median),либо среднее (Mean).Здесь же можем выбрать расчет точного значения /ьуровня: нажимаем Exact...(Точно...) и отмечаем Monte Carlo.Нажимаем Continue.Нажимаем ОК.
ЧАСТЬ II. МЕТОДЫ СТАТИСТИЧЕСКОГО ВЫВОДА: ПРОВЕРКА ГИПОТЕЗ
Результаты:
□ Заданная точка деления (Test Value).
□ Количество объектов ниже (выше) точки деления (Cases <(>=) Test
Value).
□ Общее число объектов (Total Cases).
□ Число серий (Number of Runs).
□ Z-значение (Z).
□ Приблизительное значение двустороннего р-уровня (Asymp. Sig. (2-tiled)).
О Точное значение двустороннего р-уровня (Monte Carlo Sig. (2-tiled)).
Примечание. Если проверяется направленная гипотеза, то значение р-уровня делится на 2.
Глава 10
– Конец работы –
Эта тема принадлежит разделу:
ВВЕДЕНИЕ В ПРОБЛЕМУ СТАТИСТИЧЕСКОГО ВЫВОДА
ВВЕДЕНИЕ В ПРОБЛЕМУ СТАТИСТИЧЕСКОГО ВЫВОДА ГИПОТЕЗЫ НАУЧНЫЕ И СТАТИСТИЧЕСКИЕ ПРИМЕР Исходя из... ПРИМЕР... Первым примером применения такой логики для проверки статистической ги потезы по видимому является работа врача...
Если Вам нужно дополнительный материал на эту тему, или Вы не нашли то, что искали, рекомендуем воспользоваться поиском по нашей базе работ: Повторные измерения
Что будем делать с полученным материалом:
Если этот материал оказался полезным ля Вас, Вы можете сохранить его на свою страничку в социальных сетях:
| Твитнуть |
Хотите получать на электронную почту самые свежие новости?

Подпишитесь на Нашу рассылку
Реклама





Информация в виде рефератов, конспектов, лекций, курсовых и дипломных работ имеют своего автора, которому принадлежат права. Поэтому, прежде чем использовать какую либо информацию с этого сайта, убедитесь, что этим Вы не нарушаете чье либо право.
© copyright 1999 - 2024 allRefs.net. Все права защищены. Страница сгенерирована за: 0.027 сек.
Новости и инфо для студентов