рефераты конспекты курсовые дипломные лекции шпоры

- Раздел Социология
- /
- СТАТИСТИЧЕСКОЕ РЕШЕНИЕ И ВЕРОЯТНОСТЬ ОШИБКИ
Реферат Курсовая Конспект
СТАТИСТИЧЕСКОЕ РЕШЕНИЕ И ВЕРОЯТНОСТЬ ОШИБКИ
СТАТИСТИЧЕСКОЕ РЕШЕНИЕ И ВЕРОЯТНОСТЬ ОШИБКИ - раздел Социология, ВВЕДЕНИЕ В ПРОБЛЕМУ СТАТИСТИЧЕСКОГО ВЫВОДА До Сих Пор Под Проверкой Статистической Гипотезы Мы Подразумевали Процедуру ...
До сих пор под проверкой статистической гипотезы мы подразумевали процедуру определения надежности связи (р-уровня, как показателя статистической значимости). Однако в конечном итоге проверка статистической гипотезы должна заканчиваться принятием статистического решения о том, какая же гипотеза верна: нулевая — об отсутствии связи или альтернативная — о ее наличии. Соответственно, от этого зависит и окончательный, содержательный вывод исследования: подтверждена или нет исходная научная гипотеза.
Вполне очевидно, что основанием для принятия исследователем решения о том, какая гипотеза верна, является /^-уровень — вероятность того, что верна все-таки нулевая гипотеза. Чем меньше р-уровень, тем с большей уверенностью можно отклонить Но в пользу Н], тем самым подтвердив исходную содержательную гипотезу. Не менее очевидно и то, что, принимая решение, исследователь всегда допускает вероятность его ошибочности: ведь исследование проведено на выборке, а вывод делается в отношении генеральной совокупности. При отклонении Но в пользу Н, исследователь рискует, что связи на самом деле в генеральной совокупности нет. И наоборот, решение в пользу Но вовсе не исключает наличие связи. Рассмотрим возможные исходе! принятия решения в зависимости от действительного положения дел:
В действительности:
Решение н а н истинна
| Неправильное решение, | Правильное решение, |
| ошибка I рода, | вероятность = 1 — р |
| вероятность = а | (мощность или |
| чувствительность критерия) | |
| Правильное решение, | Неправильное решение, |
| вероятность — 1 — а | ошибка 11 рода, |
| (доверительная вероятность) | вероятность = р |
исследователя: ° '
Отклонить Н(1 (принять Н)
Принять Н
Как следует из таблицы, решение исследователя зависит от того, какую вероятность ошибки I рода а,он считает допустимой: если ^-уровень, полученный в процессе проверки гипотезы, меньше или равен а, исследователь отклоняет Но, и это, как правило, желательный для него результат (содержательная гипотеза подтверждается!). Отметим, что в этом случае вероятность ошибки известна, она меньше или равна а, точнее, равна /ьуровню. Если же /^-уровень превышает а, то принимается Но и содержательная гипотеза не подтверждается1. Но при этом вероятность ошибки II рода f$— того, что верна все же Н] обычно остается неизвестной.
 1 В угоду критически настроенному научному сообществу, но к огорчению исследователя!
1 В угоду критически настроенному научному сообществу, но к огорчению исследователя!
ЧАСТЬ П. МЕТОДЫ СТАТИСТИЧЕСКОГО ВЫВОДА: ПРОВЕРКА ГИПОТЕЗ

|
Принятие Но: в угоду критически настроенному научному сообществу, но к огорчению исследователя
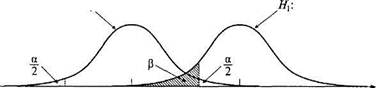
Рассмотрим соотношение ошибок I и II рода. Предположим, как и в прошлых примерах, проверяется гипотеза об отличии среднего значения от некоторой величины А. Нулевой гипотезе Но: М = А соответствует известное теоретическое распределение со средним А. Предположим также, что в генеральной совокупности на самом деле среднее значение больше А и равно В, а исследователь, как обычно, об этом даже и не догадывается. Этому положению дел будет соответствовать свое, «альтернативное» теоретическое распределение, сходное с распределением для Но, но со средним В (рис. 7.3). На рис. 7.3 видно, что с уменьшением а растет «доверительная вероятность» 1 — а, которая определяет величину отклонения выборочного среднего от А для принятия Н(); уменьшая а, исследователь увеличивает возможное отклонение выборочного среднего от Л, при котором принимается Но. Принятие Но при больших отклонениях выборочного среднего от А увеличивает вероятность ошибки II рода, р вероятность того, что на самом деле верна альтернативная гипотеза. Таким образом, снижение величины а увеличивает риск допустить ошибку IIрода — не обнаружить различия или связи, которые на самом деле существуют.
Вероятность (1 —13) называется мощностью (чувствительностью) критерия. Эта величина характеризует статистический критерий с точки зрения его способности отклонять Но, когда она не верна. Точное значение величины мощности критерия в большинстве случаев остается неизвестным. Величина
| Нп: |
 А В М
А В М
Рис. 7.3. Соотношение вероятностей ошибок [ и II рода
ГЛАВА 7- ВВЕДЕНИЕ В ПРОБЛЕМУ СТАТИСТИЧЕСКОГО ВЫВОДА
(1 —а) характеризует степень доверия к результатам статистической проверки и называется доверительной вероятностью.
Итак, основная проблема статистического вывода заключается в том, что заранее должно быть установлено оптимальное значение величины а, удовлетворяющее двум противоречивым требованиям. Величина а должна быть достаточно мала, чтобы обеспечивать доверие к результатам исследования при отклонении Но. Величина а должна быть достаточно велика, чтобы отклонить Но при наличии связи (различий), не допуская ошибки II рода. Вопрос о том, какая же величина а является приемлемой, не имеет однозначного ответа. Есть лишь общие соображения, которыми можно руководствоваться при назначении а для статистического вывода:
□ Для установленного значения а вероятность ошибки (3 уменьшается с
ростом объема выборки.
□ Вероятность ошибки (3 уменьшается при увеличении значения а (на
пример, с 0,01 до 0,05).
Вопрос о величине а — вопрос о том, при каком же /7-уровне исследователь может отклонить Но, решается преимущественно исходя из неформальных соглашений, принятых на основе практического опыта в различных областях исследования. Традиционная интерпретация различных уровней значимости исходит из а = 0,05 и приведена в табл. 7.1. В соответствии с ней приемлемым для отклонения Но признается уровень р < 0,05. Такая относительно высокая вероятность ошибки I рода может быть рекомендована для небольших выборок (когда высока вероятность ошибки II рода). Если объемы выборок около 100 и более объектов, то порог отклонения Но целесообразно снизить до а = 0,01 и принимать решение о наличии связи (различий) при р < 0,01.
Таблица 7.1 Традиционная интерпретация уровней значимости при а = 0,05
| Уровень значимости | Решение | Возможный статистический вывод |
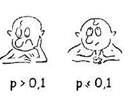
| р > 0,1 | Принимается Но | «Статистически достоверные различия не обнаружены» |
| р<0,1 | сомнения в истинности Н(), неопределенность | «Различия обнаружены на уровне статистической тенденции» |
| /?< 0,05 | значимость, отклонение Н() | «Обнаружены статистически достоверные (значимые) различия» |
| р < 0,01 | высокая значимость, отклонение Но | «Различия обнаружены на высоком уровне статистической значимости» |
|
|
ЧАСТЬ П. МЕТОДЫ СТАТИСТИЧЕСКОГО ВЫВОДА: ПРОВЕРКА ГИПОТЕЗ
НАПРАВЛЕННЫЕ И НЕНАПРАВЛЕННЫЕ АЛЬТЕРНАТИВЫ
Основная (нулевая) статистическая гипотеза, как отмечалось, содержит утверждение о равенстве нулю (коэффициента корреляции) или о равенстве средних значений, дисперсий и т. д. Если по результатам статистической проверки основная гипотеза отклоняется, то принимается альтернативная гипотеза. Принимаемая альтернатива может быть как направленной(например, Н}: г > О или Н,: М1 > М2), так и не направленной(например, Н],1 г ^ 0 или Н,: Л/, ^ М2). То, какая альтернатива должна быть принята по результатам проверки, зависит от применяемого для проверки метода и теоретического распределения. Обычно характер альтернативы явно указывается при описании метода.
В большинстве случаев направленность или ненаправленность альтернативы зависит от формы теоретического распределения. Если оно симметрично и включает отрицательные значения, то обычно применяются ненаправленные альтернативы. Это относится к таким теоретическим распределениям, KaKZ-распределение (нормальное распределение), распределение f-Стьюден-та и т. д. Если распределение асимметрично и может принимать только положительные значения, то применяются направленные альтернативы, например, при использовании критериев %2-Пирсона или /"-Фишера, хотя встречаются и исключения. Важно отметить, что выбор альтернативы — направленной или ненаправленной — исключает произвол исследователя и обычно задается выбранным методом проверки гипотезы.
Если процедура проверки гипотезы Но подразумевает ненаправленную альтернативу, то критические области, соответствующие ее отклонению (принятию альтернативы), поровну распределяются по обоим «хвостам» распределения (рис. 7.4). Чаще всего интервал принятия нулевой гипотезы (1 —а) при этом охватывает диапазон теоретических значений, симметричный относительно нуля (вспомним Z-распределение). Поэтому такие критерии часто называют двусторонними (2-tailed), имеющими «двахвоста» —для проверки ненаправленных гипотез. Заметим, что в этом случае, если принят уровень а для решения об отклонении Но, существует два теоретических (критических) значения: одно отсекает а/2 справа, а другое, отрицательное — а/2 слева. Если проверяется направленная гипотеза, то процедура проверки допускает при-
 |
 о t3 -t3 о и
о t3 -t3 о и
а) б)
Рис.7.4. Различие направленной (а) и ненаправленной (б) альтернатив (для одного итого же эмпирического значения р-уровень в случае (б) в два раза больше, чем в случае (а))
ГЛАВА 7. ВВЕДЕНИЕ В ПРОБЛЕМУ СТАТИСТИЧЕСКОГО ВЫВОДА
нятие односторонней альтернативы (1-tailed) (например, Н^ г>0). В этом случае, если принят уровень а для решения об отклонении Но, существует одно теоретическое (критическое) значение (для Н,: г>0 — положительное), и оно отсекает ровно а справа (или слева — в зависимости от направления альтернативы). Очевидно, что односторонняя альтернатива более «лояльна» к отклонению Но для одних и тех же выборочных результатов. При двусторонней альтернативе, по сравнению с односторонней, нулевая гипотеза отвергается при больших значениях силы связи (корреляции, различий средних и пр.).
Важно отметить, что принятие по результатам проверки гипотезы ненаправленной альтернативы вовсе не означает ограничение выводов лишь «ненаправленными» суждениями типа: «средние различаются», «корреляция отличается от нуля». Как следует из предыдущих рассуждений, проверка ненаправленной гипотезы является более «строгой» (при прочих равных условиях). Принятие ненаправленной (двусторонней) альтернативы позволяет сделать вывод о направлении связи в генеральной совокупности в соответствии с выборочными данными.
ПРИМЕР______________________________________________________________
При проверке статистической значимости коэффициентов корреляции обычно используются ненаправленные альтернативы (Но: г = 0 против Н^ г^ 0). Однако если Но отклоняется, например, при г-—0,34, то вывод не ограничивается констатацией отличия от нуля, а распространяется и на знак связи: «обнаружена статистически достоверная отрицательная корреляция».
Ранее отмечалось, что определение р-уровня значимости — чисто техническая процедура, выполняемая компьютерной программой автоматически, а при расчетах «вручную» — по таблицам теоретических распределений (критических значений). Тем не менее, полезно знать, что существует простое соотношение между /ьуровнями для направленных и ненаправленных альтернатив. Для одного и того же эмпирического значения критерия р-уровень значимости для направленной альтернативы в 2 раза меньше р-уровня для ненаправленной альтернативы.
ПРИМЕР______________________________________________________________
Предположим, сравниваются две дисперсии. При использовании таблицы критических значений для критерия /^Фишера (для направленных альтернатив) (приложение 3) эмпирическое значение оказалось между критическими для р = 0,05 и /7 = 0,01. Следовательно, для направленной альтернативы р< 0,05. Однако при сравнении двух дисперсий проверяется двусторонняя (ненаправленная) альтернатива, поэтому действительный уровень значимости в данном случае — р < 0,1.
Различие между направленной и ненаправленной альтернативами, кажется, еще более усложняет и без того непростую логику статистической проверки гипотез. Однако в большинстве случаев выбор альтернативы не является проблемой для исследователя — он определен самим методом (критерием) статисти-
ЧАСТЬ II. МЕТОДЫ СТАТИСТИЧЕСКОГО ВЫВОДА: ПРОВЕРКА ГИПОТЕЗ
ческой проверки и исключает возможность произвола. То, какая альтернатива предполагается, указывается явным образом при описании метода проверки. При проверке гипотезы с помощью таблиц критических значений указывается, для какой альтернативы приведены критические значения. А при использовании статистической компьютерной программы в результатах указывается, для какой альтернативы приведен /^-уровень значимости. Например, при обработке в среде программы SPSS: Sig. (2-taiIed) —/^-уровень значимости (двусторонний), Sig. (I-tailed) — р-уровень значимости (односторонний).
СОДЕРЖАТЕЛЬНАЯ ИНТЕРПРЕТАЦИЯ СТАТИСТИЧЕСКОГО РЕШЕНИЯ
Статистическое решение является основанием для содержательного вывода в отношении проверяемой гипотезы. Но гарантирует ли отклонение Но истинность содержательной гипотезы о наличии связи или различий? Может ли принятие Но служить основанием для вывода об отсутствии связи или различий?
Принятие Но.Из обсуждения оснований принятия статистического решения следует, что, когда принимается Но, всегда остается вероятность того, что связь или различия все же есть. И мы ничего не можем сказать о том, насколько велика или мала эта вероятность.
Принятие Но не означает, что различия отсутствуют или мера связи равна нулю; из этого следует только то, что статистически значимые результаты не обнаружены.
Когда в результате исследования принимается Но, никакого содержательного вывода сделать нельзя. Поэтому выражение «Отрицательный результат исследования — тоже результат» имеет для исследователя исключительно психотерапевтическое значение: отрицательный результат исследования — это отсутствие какого бы то ни было результата!
Отклонение Но.В этом случае остается вероятность того, что Но все-таки верна и эта вероятность равна/?-уровню значимости. Следовательно, нельзя утверждать, что результаты доказывают справедливость содержательной гипотезы. Корректным будет более осторожный вывод о том, что получено свидетельство в пользу содержательной гипотезы.
Не менее рискован содержательный вывод о причинно-следственной зависимости между изучаемыми явлениями только на основании статистической значимости связи между соответствующими признаками. Конечно, статистическая связь между признаками — это необходимое, но не достаточное условие причинно-следственной связи между ними. Утверждение о том, что явление А есть причина явления В, справедливо, если одновременно выполняются три условия (Д. Кэмпбелл, 1980): а) явления А и i?статистически связаны; б) А происходит раньше В; в) отсутствует альтернативная интерпрета-
ГЛАВА 7. ВВЕДЕНИЕ В ПРОБЛЕМУ СТАТИСТИЧЕСКОГО ВЫВОДА
 Альтернативная интерпретация статистически достоверной связи между явлениями
Альтернативная интерпретация статистически достоверной связи между явлениями
ция появления В помимо А (другими словами — отсутствует обшая причина С совместной изменчивости А и В). Таким образом, применение статистических методов позволяет обосновать наличие только статистической связи — одного из трех признаков причинно-следственной связи.
Следует отметить, что при оформлении исследовательского отчета (курсовой или дипломной работы, публикации) статистические гипотезы и статистические решения, как правило, не приводятся. Обычно при описании результатов указывают критерий, приводят необходимые описательные статистики (средние, сигмы, корреляции и т. д.), эмпирические значения критериев, степени свободы и обязательно — ^-уровень значимости. Затем формулируют содержательный вывод в отношении проверяемой гипотезы с указанием (обычно — в виде неравенства) достигнутого или не достигнутого уровня значимости.
ПРИМЕРЫ___________________________________________
На трех разных выборках проверялась содержательная гипотеза о связи креативности и тревожности. При расчете на компьютере корреляций Пирсона были получены следующие результаты для каждой из трех выборок:
1. /•= 0,270; W-36;/? = 0,11.
2. /-=0,411; УУ = 28;р = 0,02.
3. r=0,270; /V=41;p=0,08.
Приведем примеры содержательных выводов для каждого случая:
1. Связь между креативностью и тревожностью не обнаружена (р > 0,1). Или: ста
тистически значимой связи между креативностью и тревожностью не обнару
жено (р > 0,1).
2. Обнаружена статистически значимая связь между креативностью и тревожнос
тью (р < 0,05). Или: обнаружена статистически достоверная связь между креа
тивностью и тревожностью (р < 0,05).
3. Связь между креативностью и тревожностью обнаружена лишь на уровне стати
стической тенденции (р< 0,1).
В заключении главы отметим место статистического вывода в общей последовательности проверки содержательной гипотезы.
1. Формулировка содержательной гипотезы.
2. Планирование исследования (выборка, процедура, инструментарий...),
в том числе предварительная формулировка доступной проверке стати
стической гипотезы.
ЧАСТЬ II. МЕТОДЫ СТАТИСТИЧЕСКОГО ВЫВОДА: ПРОВЕРКА ГИПОТЕЗ
3. Проведение измерений и накопление исходных данных.
4. Окончатдлытя формулировка статистической гипотезы, выбор статис
тического критерия, установление величины ос — допустимой вероятно
сти ошибки I рода.
5. Определение />-уровня статистической значимости в результате приме
нения статистического критерия.
6. Статистический вывод: статистическое решение о принятии или откло
нении Но.
7. Формулировка содержательного вывода.
Глава 8
– Конец работы –
Эта тема принадлежит разделу:
ВВЕДЕНИЕ В ПРОБЛЕМУ СТАТИСТИЧЕСКОГО ВЫВОДА
ВВЕДЕНИЕ В ПРОБЛЕМУ СТАТИСТИЧЕСКОГО ВЫВОДА ГИПОТЕЗЫ НАУЧНЫЕ И СТАТИСТИЧЕСКИЕ ПРИМЕР Исходя из... ПРИМЕР... Первым примером применения такой логики для проверки статистической ги потезы по видимому является работа врача...
Если Вам нужно дополнительный материал на эту тему, или Вы не нашли то, что искали, рекомендуем воспользоваться поиском по нашей базе работ: СТАТИСТИЧЕСКОЕ РЕШЕНИЕ И ВЕРОЯТНОСТЬ ОШИБКИ
Что будем делать с полученным материалом:
Если этот материал оказался полезным ля Вас, Вы можете сохранить его на свою страничку в социальных сетях:
| Твитнуть |
Хотите получать на электронную почту самые свежие новости?

Подпишитесь на Нашу рассылку
Реклама





Информация в виде рефератов, конспектов, лекций, курсовых и дипломных работ имеют своего автора, которому принадлежат права. Поэтому, прежде чем использовать какую либо информацию с этого сайта, убедитесь, что этим Вы не нарушаете чье либо право.
© copyright 1999 - 2024 allRefs.net. Все права защищены. Страница сгенерирована за: 0.027 сек.
Новости и инфо для студентов