рефераты конспекты курсовые дипломные лекции шпоры

- Раздел Образование
- /
- Выбор числа опытов
Реферат Курсовая Конспект
Выбор числа опытов
Выбор числа опытов - раздел Образование, АНАЛИТИЧЕСКИЕ И ИМИТАЦИОННЫЕ МОДЕЛИ При Разработке Имитационных Моделей Для Исследования Случайных Объектов Сущес...
При разработке имитационных моделей для исследования случайных объектов существует задача выбора числа опытов (объема выборки). Это непростая задача, т.к. во-первых, необходимо обосновать достоверность результатов моделирования и связать достоверность с точностью, а во-вторых, существуют события, вероятность появления которых очень мала (Р®0) или, наоборот очень велика (Р®1). Для обоснования объема выборки при имитационном моделировании применяют аналитические подходы [8,12,13].
В инженерной практике известны критерии для оценки погрешности. Непрерывную (аналоговую) величину х(t) в ряде инженерных задач рассматривают как дискретную, как показано на рис. 5.1.
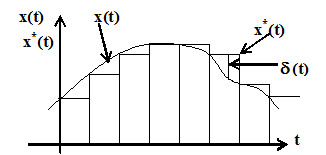
Рис. 5.1
Если х*(t) - результат измерения непрерывной величины х(t), то для любого момента t текущая погрешность дискретизации этой непрерывной величины определится: d(t)=х(t)-х*(t). Выбор критерия оценки d(t) зависит от назначения величины х(t). Известны следующие критерии.
Критерий наибольшего отклонения имеет вид
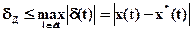 .Критерий применим, если известны априорные сведения о сигнале в форме условия Липшица
.Критерий применим, если известны априорные сведения о сигнале в форме условия Липшица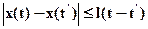 ,где l -некоторая константа.
,где l -некоторая константа.
Среднеквадратичный критерий приближения определяется по формуле
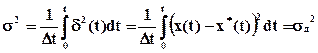 .
.
Среднеквадратичный критерий применим для функций, интегрируемых в квадрате. Использование среднеквадратичного критерия связано с усложнениями, например аппаратуры измерения, по сравнению с критерием наибольшего отклонения.
Интегральный критерий как мера отклонения х(t) от х*(t) имеет вид
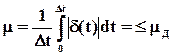 .
.
Если моделируются случайные процессы, то выше-названные критерии не применимы.
Выбор количества реализаций зависит от того, какие требования предъявляются к результатам моделирования.
Пусть для оценки случайной величины A, оцениваемой по результатам моделирования х, выбирается величина х*, являющаяся функцией от х. Значениях* будут отличаться от A в силу случайных факторов, т.е. можно связать точность оценки, теоретическое значение случайной величины A и её статистическую оценку х* в виде формулы
|A-х*|<e,(5.1)
где e - точность оценки.
В силу того, что каждый результат х* моделирования случайной величины A также является случайной величиной, то вероятность того, что неравенство (5.1) выполняется, будет достоверностью точности оценки х* случайной величины A, т.е. справедлива формула
Р(|A-х*|<e)=a. (5.2)
Воспользуемся сформулированным критерием (5.2) для определения точности результатов методом статистического моделирования. Пусть цель моделирования - вычисление вероятности р появления события A. Количество e наступления события A в реализации процесса является случайной величиной, принимающей значение х1=1 с вероятностью р и значение х2=0 с вероятностью 1-р. Пример случайного появления события A показан на рис. 5.2.

Рис. 5.2
Математическое ожидание случайной величины e определится по формуле
M[e]=х1р+х2(1-р)=р. (5.3)
Если х1=1, как появление события A, а х2=0, как не появление события, то значение M[e] совпадает с вероятностью р наступления события A.
Дисперсия определится по формуле
D[e]=[х1-M[e]]2р+[х2-M[e]]2(1-р)=р(1-р).(5.4)
При выполнении имитационного моделирования оценкой вероятности р является частость m/N наступления события A при N реализациях, m - число испытаний, в которых событие A наступило. Частость m/N определяется формулой
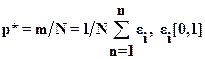 ,(5.5)
,(5.5)
где ei - количество наступлений событий A в реализации с номером i.
Из формул (5.3), (5.4) и (5.5) можно определить математическое ожидание и дисперсию частости m/N
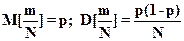 .(5.6)
.(5.6)
В силу центральной предельной теоремы вероятностей частость m/N при Nॠимеет распределение, близкое к нормальному. Поэтому для каждого значения достоверности a (вероятности) можно выбрать из таблиц нормального распределения такую величину (значение случайной величины) ta, что точность e будет равна
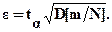 (5.7)
(5.7)
Подставив в формулу (5.7) значение D из формулы (5.6), получим
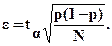 (5.8)
(5.8)
Из формулы (5.8) можно определить количество реализаций N, необходимых для получения оценки m/N с точностью e и достоверностью a:
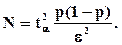 (5.9)
(5.9)
В формуле (5.9) неизвестны величины N и р, т.к. вероятность р определяется, исходя из ее оценки m/N, а N - число необходимых для этого опытов. Поэтому в практике моделирования для определения N поступают следующим образом. Выбирают N0=50-100. По результатам N0 реализаций определяют m/N0, т.е. осуществляют примерную оценку вероятности р=m/N0. Затем по формуле (5.9) окончательно выбирают N, принимая р=m/N.
Другим случаем является оценка по результатам моделирования среднего значения некоторой случайной величины. Пусть непрерывная случайная величина A имеет среднее значение 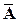 и дисперсию s2. В реализации с номером i случайная величина A принимает значение хi. В качестве оценки для среднего значения (математического ожидания) A используется среднее арифметическое
и дисперсию s2. В реализации с номером i случайная величина A принимает значение хi. В качестве оценки для среднего значения (математического ожидания) A используется среднее арифметическое
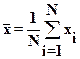 .
.
В силу центральной предельной теоремы при Nॠ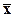 будет иметь приблизительно нормальное распределение с математическим ожиданием и дисперсией s2/N, поэтому точность определится по формуле
будет иметь приблизительно нормальное распределение с математическим ожиданием и дисперсией s2/N, поэтому точность определится по формуле
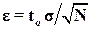 .
.
Число реализаций определится по формуле
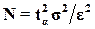 . (5.10)
. (5.10)
Так как в формуле (5.10) неизвестными являются число реализаций N и среднеквадратичное отклонение s2, то также выбирают N0=50-100. По результатам N0 реализаций определяют оценку дисперсии, а затем по формуле (5.10) окончательно выбирают N. Количество реализаций N в формуле (5.9) зависит от р, а в формуле (5.10) от s2.
Целесообразно так строить моделирующий алгоритм, чтобы методом моделирования оценивались параметры величин, имеющих возможно меньшую дисперсию, или вероятности случайных событий, не близкие к 0,5. Вероятности не должны быть также близки к 0 или 1, т.к. в этом случае снижается эффективность имитационного моделирования.
5.2. Значимость оценки
5.2.1. Статистическая проверка гипотезы относительно вероятности. При имитационном моделировании получают практические (эмпирические) результаты, которые затем аппроксимируют известными теоретическими распределениями, т.е. выдвигают гипотезу, то данное теоретическое распределение аппроксимирует эмпирическое распределение. Например, необходимо проверить гипотезу относительно того, что при выполнении имитационного моделирования частость р*=m/N является оценкой вероятности р события.
Пусть проверяется настройка станка на среднюю точку поля допуска. Проведено 280 независимых испытаний и интересующее нас событие появилось 151 раз. Модель появления независимых событий – биноминальное распределение. Если гипотетическая вероятность события р=1/2, то математическое ожидание равно Nр=280(1/2)=140, а среднеквадратичное отклонение биноминального распределения определится из формулы 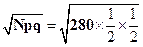 =8,37, где q=1-р – вероятность не появления события. Надо получить ответ на вопрос: можно ли считать наблюденную частоту 151 достаточно близкой к теоретической норме 140, отвечающей гипотезе р=1/2.
=8,37, где q=1-р – вероятность не появления события. Надо получить ответ на вопрос: можно ли считать наблюденную частоту 151 достаточно близкой к теоретической норме 140, отвечающей гипотезе р=1/2.
Чтобы получить ответ на заданный вопрос, следует выбрать границу допустимых при гипотезе отклонений частот (или частостей) от математического ожидания.
Будет определено критическое отклонение, превышение которого при выдвинутой гипотезе настолько маловероятно, что его можно считать практически невозможным. Если превышение критического отклонения будет наблюдаться, то это указывает на несовместимость выдвинутой гипотезы с наблюдениями и говорят, что наблюденная частость значимо отклоняется от вероятности. Если фактическое отклонение меньше критической границы, то опыт не противоречит выдвинутой гипотезе и наблюденное отклонение можно объяснить случайностью испытаний.
На практике, в соответствии с критерием (5.2), задают уровень значимости a, т.е. вероятность практически невозможных отклонений. Эта вероятность обычно не превышает значение 0,05. Область больших отклонений, соответствующую уровню значимости a, называют критической областью, а само правило проверки – критерием значимости. Критическую границу для отклонений от теоретической нормы можно определить, пользуясь нормальным приближением к биноминальному закону. На рис. 5.3 приведены двухсторонние критические границы для проверки гипотезы р=1/2.
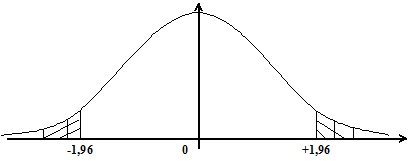
Рис. 5.3
Вероятность 0,95 соответствует при нормированном нормальном распределении интервалу (-1,96, +1,96) около центра распределения, т.к. вероятность того, что абсолютная величина нормированного отклонения превысит значение 1,96, равна 0,05, т.е.
Р(|A|>1,96)=Р(|m-Nр|>1,96s)»0,05,
где m – практическая частота.
Уровень значимости 0,01 соответствует границе 2,58, т.е.
Р(|A|>2,58)=Р(|m-Nр|>2,58s)»0,01.
Для рассмотренного выше примера настройки станка на среднюю точку поля допуска s=8,37 и 5% критическая граница соответствует 1,96´8,37=16,41, а 1% критическая граница соответствует 2,58´8,37=21,59.
Таким образом, область допустимых значений при 5% критической границы определяется пределами
Nр±1,96s=140±16,41,
а при области допустимых значений при 1% критической границы определяется пределами
Nр±2,58s=140±21,6.
Если выдвинутая гипотеза, что наблюденная частота 151 достаточно близка к теоретической норме 140, отвечающей вероятности р=1/2, верна, то отклонение частоты от теоретической нормы в пяти случаях из 100 может превышать 16,4, и в одном случае из 100 может превышать 21,6. Так как в рассмотренном примере отклонение составило 151-140=11, т.е. оно находится в области допустимых значений, то нет оснований считать гипотезу р=1/2 противоречащей наблюдениям.
5.2.2. Общая задача проверки гипотез. При наличии явлений рассеивания признаков случайной величины требуется провести сравнительную оценку, причем обоснованный вывод может быть получен путем научно поставленного анализа статистических данных.
Данные рассматривают как некоторые выборки, информирующие о поведении случайных величин, и позволяющие делать определенные заключения о законах распределения этих величин.
Существуют некоторые выборки значений случайной величины А. Необходимо сделать заключение о законах распределения случайной величины А. Можно сделать предположение, что тип закона распределения известен (нормальный, пуассоновский и т.д.), но неизвестны его параметры, т.е. проверка гипотезы сводится к сравнению статистических характеристик, оценивающих параметры выбранных законов распределения.
Для проверки гипотезы согласно критерию выбираются надлежащие уровни значимости (см. разд. 5.2.1) a=5%, 2%, 1% и т.д., отвечающие событиям, которые при данном исследовании считаются практически невозможными. Затем определяется критическая область (см. рис. 5.3) данного критерия, вероятность попадания в которую в точности равна уровню значимости a, если гипотеза верна. Значения критерия, лежащие вне критической области, образуют дополнительную к ней область допустимых значений (незаштрихованная область на рис. 5.3).
Если a/100 – уровень значимости, то вероятность попадания критерия в область допустимых значений при справедливости выдвинутой гипотезы равна 1-a/100. Если значение критерия, вычисленное по произведенным наблюдениям (опытам), окажется в критической области, то гипотеза отвергается. Если значение критерия окажется в области допустимых значений, что наблюденное значение критерия не противоречит гипотезе.
Чем меньше уровень значимости, тем меньше вероятность забраковать проверяемую гипотезу, когда она верна, т.е. совершить ошибку первого рода. С уменьшением уровня значимости понижается чувствительность критерия, т.к. расширяется область допустимых значений и увеличивается вероятность совершения ошибки второго рода, т.е. принятия проверяемой гипотезы, когда она не верна. Уровень значимости критерия проверки контролирует лишь ошибки первого рода и не измеряет степень риска, связанного с принятием неверной ошибки.
При заданном уровне значимости можно по разному устанавливать критическую область, гарантирующую этот уровень. Например, в качестве критерия рассматривается некоторый показатель, распределенный при проверяемой гипотезе нормально с плотностью распределения f(x;a;s).В качестве критической области соответствующей уровню значимости a=5% можно принять:
- область больших положительных отклонений так, что
Р(tq)=Р(x>a+tqs)=0,05,
но
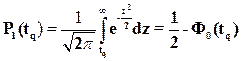 , (5.11)
, (5.11)
тогда из таблицы значений нормированной функции Лапласа
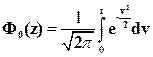
определим, что tq=1,65;
- область больших отрицательных отклонений
Р2(tq)=Р(x<a-tqs)=Р(x<a-1,65s);
- область больших по абсолютной величине отклонений
Р3(tq)=Р(|x-a|>tqs)=0,05,
определив t из соотношения
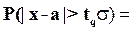
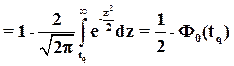 , (5.12)
, (5.12)
так что tq=1,96;
- область малых по абсолютной величине отклонений
Р4(tq)=Р(|x-a|>tqs)=2Ф0(z), (5.13)
так что tq»0,063.
Эти области показаны на рис. 5.4.
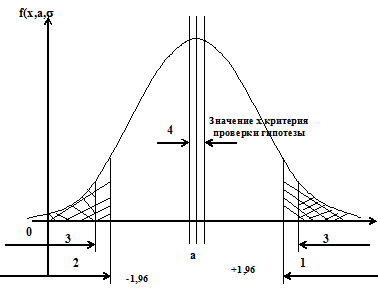
1 – область больших положительных отклонений;
2 - область больших отрицательных отклонений;
3 - область больших по абсолютной величине отклонений (состоит из двух половин); 4 - область малых по абсолютной величине отклонений
Рис. 5.4
5.2.3. Проверка гипотез о законе распределения. Рассмотренные в предшествующем разделе (см. разд. 5.2.2) методы проверки предполагали известным закон распределения случайной величины и направлены на определение параметров распределения. При обработке результатов имитационного моделирования (статистических данных) вид закона распределения является гипотетическим и нуждается в статистической проверке, т.е. задача о критерии проверки гипотезы по данным выборки состоит в том, что случайная величина Х подчинена закону распределения Р(х).
Эти критерии, называемые критериями соответствия, основаны на выборе определенной меры расхождения между теоретическим и эмпирическим распределениями. Если такая мера расхождения для рассматриваемого случая превосходит установленный предел, то гипотеза не подтверждается.
Рассмотрим наиболее употребительный критерий c2 (критерий Пирсона). Пусть гипотеза предполагает вид функции распределения Р(х). Вся область изменения случайной величины Х разбита на конечное число k множеств D1, D1, …, Dk. Если случайная величина Х непрерывна, то множества D1, D1, …, Dk представляют собой интервалы, а если случайная величина Х дискретна, то множества D1, D1, …, Dk представляют собой группы отдельных значений случайной величины Х. Пусть pi - вероятность того, что значения случайной величины Х при данном распределении Р(х) принадлежат интервалу Di.
Объем выборки N, а mi - число значений случайной величины Х в выборке O(x1, x2, x3, …, xN), попавших в интервал Di. Очевидно, что
p1+p2+ …+pk=1, (5.14)
m1+m2+ …+mk=N. (5.15)
Если проверяемая гипотеза верна, то mi представляет частоту появления события, имеющего в каждом из N произведенных испытаний вероятность pi. В таком случае mi можно рассматривать как случайную величину, подчиненную биномиальному закону распределения с центром в центре в точке Npi и средним квадратическим 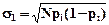 . Если N достаточно велико, то можно считать, что частота распределена асимптотически нормально с центром в центре в точке Npi и средним квадратическим
. Если N достаточно велико, то можно считать, что частота распределена асимптотически нормально с центром в центре в точке Npi и средним квадратическим 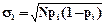 .
.
Если проверяемая гипотеза верна, то можно ожидать, что в совокупности будут асимптотически нормально распределены случайные величины
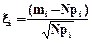 , (i=1,2,…,k), (5.16)
, (i=1,2,…,k), (5.16)
связанные между собой соотношением
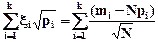 , (5.17)
, (5.17)
вытекающем из условий (5.14) и (5.15).
В качестве меры расхождения данных выборки (эмпирических частот) m1, m2, …, mk с теоретическими частотами Np1, Np2, …, Npk рассмотрим величину
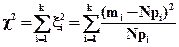 . (5.18)
. (5.18)
Для практических приложений можно применять подобное равенство:
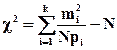 . (5.19)
. (5.19)
Согласно формуле (5.18) случайная величина c2 представляет собой сумму квадратов асимптотически нормально распределенных случайных величин, связанных линейной зависимостью (5.17).
Из теории вероятностей известна теорема. Если проверяемая гипотеза верна, то критерий c2, определяемый по формуле (5.18), имеет распределение, стремящееся при N®¥ к распределению c2 с k-1 степенями свободы.
При проведении проверки задают уровень значимости a% для критерия.
Пусть 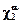 обозначает a% предел для закона распределения c2 с k-1 степенями свободы. Этот закон имеет табличное задание и его значения приводятся в приложениях книг с изложением теории вероятностей.
обозначает a% предел для закона распределения c2 с k-1 степенями свободы. Этот закон имеет табличное задание и его значения приводятся в приложениях книг с изложением теории вероятностей.
Если гипотеза верна, то при достаточно большом числе опытов N справедливо определение вероятности
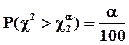 . (5.20)
. (5.20)
После определения случайной величины c2 по данным выборки O(x1, x2, x3, …, xN), будет выполняться одно из двух условий:
- при 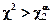 критерий попадает в критическую область и, следовательно, расхождение выборочных данных с гипотетическим допущением о законе распределения случайной величины существенно, гипотеза отвергается;
критерий попадает в критическую область и, следовательно, расхождение выборочных данных с гипотетическим допущением о законе распределения случайной величины существенно, гипотеза отвергается;
- при 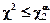 несущественно расхождение выборочных данных с гипотетическим допущением о законе распределения, гипотеза принимается.
несущественно расхождение выборочных данных с гипотетическим допущением о законе распределения, гипотеза принимается.
Во втором случае в a% всех случаев, но неизвестно каких, гипотеза неверна. Принято считать достаточным нормальное приближение для практических расчетов, если Npi³10 "i. Если есть группы со значениями Npi меньшими 10, то рекомендуют соседние группы объединять так, чтобы новые группы удовлетворяли условию Npi³10 "i.
Если число степеней свободы k>30, то соответствующего значения случайной величины c2 нельзя найти в табличном задании закона распределения c2. В этом случае применяют следующую приближенную формулу:
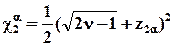 , (5.21)
, (5.21)
основанную на том, что 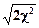 оказывается асимптотически нормальным законом
оказывается асимптотически нормальным законом 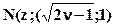 , z2a - есть 2a% предел абсолютного уклонения нормальной переменной, заданный в табличных приложениях книг по теории вероятностей.
, z2a - есть 2a% предел абсолютного уклонения нормальной переменной, заданный в табличных приложениях книг по теории вероятностей.
– Конец работы –
Эта тема принадлежит разделу:
АНАЛИТИЧЕСКИЕ И ИМИТАЦИОННЫЕ МОДЕЛИ
ФЕДЕРАЛЬНОЕ АГЕНТСТВО ПО ОБРАЗОВАНИЮ... Технологический институт... Федерального государственного образовательного учреждения высшего профессионального образования...
Если Вам нужно дополнительный материал на эту тему, или Вы не нашли то, что искали, рекомендуем воспользоваться поиском по нашей базе работ: Выбор числа опытов
Что будем делать с полученным материалом:
Если этот материал оказался полезным ля Вас, Вы можете сохранить его на свою страничку в социальных сетях:
| Твитнуть |
Хотите получать на электронную почту самые свежие новости?

Подпишитесь на Нашу рассылку
Реклама





Информация в виде рефератов, конспектов, лекций, курсовых и дипломных работ имеют своего автора, которому принадлежат права. Поэтому, прежде чем использовать какую либо информацию с этого сайта, убедитесь, что этим Вы не нарушаете чье либо право.
© copyright 1999 - 2024 allRefs.net. Все права защищены. Страница сгенерирована за: 0.027 сек.
Новости и инфо для студентов