рефераты конспекты курсовые дипломные лекции шпоры

- Раздел Образование
- /
- Имитационное моделирование одноканальной СМО
Реферат Курсовая Конспект
Имитационное моделирование одноканальной СМО
Имитационное моделирование одноканальной СМО - раздел Образование, АНАЛИТИЧЕСКИЕ И ИМИТАЦИОННЫЕ МОДЕЛИ Алгоритмизация Может Осуществляться С Применением Способа Dt...
Алгоритмизация может осуществляться с применением способа Dt-моделирования, который позволяет определить состояния СМО через интервал времени Dt.
7.6.1. Алгоритм имитационной модели одноканальной СМО.Одноканальная СМО самая простая модель (см. рис. 7.1,а) при условии пуассоновского входного потока заявок и экспоненциального распределения времени обслуживания. Если поток заявок пуассоновский, то СМО определена шифром M/G/1/PM.
Одноканальную СМО следует рассматривать как элемент, т.е. предел членения СМО сложной структуры. Рассмотрим задачу построения имитационной модели одноканальной СМО с пуассоновским потоком заявок, характеризующимся интенсивностью a и функцией распределения времени обслуживания B(t).
Для понимания процесса функционирования одноканальной СМО следует построить временные диаграммы, на которых отображают время задержки w(t) заявок, а также определяют интервалы периода занятости p(t). На рис. 7.2 приведены временные диаграммы, отображающие процесс функционирования СМО.
Поток заявок П(t) описывается стохастическим распределением вероятностей длин интервалов между соседними заявками (показаны точками). Время задержки в момент поступления заявки скачком увеличивается на величину, равную времени обслуживания поступившей заявки, а затем убывает с угловым коэффициентом, равным единице. Интервалы периода занятости p(t) на нижней оси показаны выделенными отрезками (толстые линии).
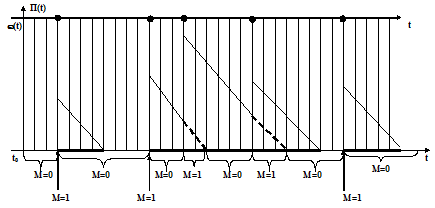
Рис. 7.2
При пуассоновском потоке заявок длины интервалов времени между соседними заявками описываются экспоненциальным распределением A(t)=1-e-at.
На рис. 7.2 имеются идентификаторы:
- I=1, если за такт моделирования Т=Δtпоступила заявка с вероятностью Рn, I=0, если заявка в систему не поступила;
- М=1, если в СМО есть очередь на обслуживание, М=0, если очередь отсутствует;
- L=1, если прибор занят обслуживанием (в СМО одна и более заявок ), L=0, если прибор от обслуживания свободен (в СМО нет заявок);
- К=1, если обслуживание окончено и заявка покидает СМО;
- JPM - максимально возможная длина очереди.
На рис. 7.3 приведена структурная схемя алгоритма имитационной модели СМО M/G/I/JPM, полученная исходя из модульного принципа построения программ.
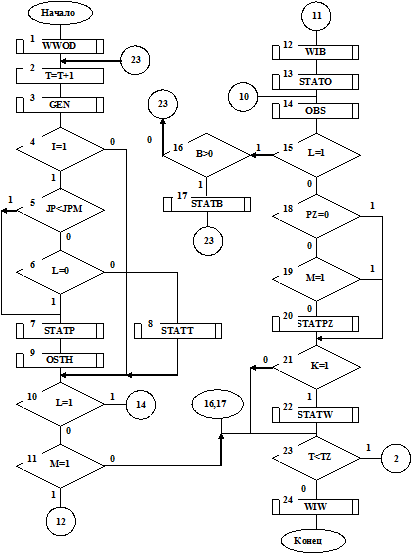
Рис.7.3
Алгоритм имитационной модели построен в соответствии с процедурами поступления заявок в систему, постановки их в очередь при занятом приборе, обслуживания заявок. Структура алгоритма имитационной модели состоит из подпрограмм, имитирующих конкретные операции в СМО. «Движение» по подпрограммам осуществляется с помощью ключей. Работает алгоритм имитационной модели следующим образом.
Вначале происходит обращение к подпрограмме WWOD – ввод исходных данных, в которой описываются необходимые массивы, общие области, задаются начальные значения. В начальный такт моделирования необходимо определить:
- счетчик тактов моделирования Т=0;
- идентификаторы М=0, L=0, так как нет очереди и прибор свободен от обслуживания;
- длительность времени обслуживания ВТ=0, так как в СМО нет заявок;
- число заявок в очереди JP=0;
- момент времени начала интервала до следующей заявки ТН=0;
- длительность периода занятости PZ=0;
- память под все массивы: N[J] – массив времен поступления J-х заявок в очередь; массивы чисел для сравнения получаемых случайных величин (интервалов времени между соседними заявками, времени ожидания очереди, числа потерянных заявок, времени обслуживания, периода занятости и т.д.) с их оценками;
- и ввести значение вероятности РР=Рn;
- заданное число тактов моделирования TZ, значение JPМ и т.д.
Затем наращивается такт моделирования (см. блок 2 на рис. 7.3) и за данный отрезок времениΔt=1просматриваются изменения в СМО, для чего и предусмотрены подпрограммы.
Далее по алгоритму следует обращение к подпрограмме GEN – генерация заявок входного потока (см. блок 3 на рис. 7.3). Алгоритм подпрограммы GEN будет рассмотрен ниже. В подпрограмме GEN на основе анализа полной группы событий – поступления и непоступления заявок за рассматриваемый такт Т определяется факт появления заявки (идентификатор I=1) либо непоявления заявки (идентификатор I=0).
Зная такт моделирования Т, результат работы подпрограммы GEN, при I=1 (см. блок 4 на рис. 7.3) и числе заявок в очереди, меньшем максимально возможного (см. блок 5 на рис. 7.3), обращаемся к подпрограмме набора статистических данных потока заявок STATP. Это происходит потому, что заявка будет поставлена в очередь на обслуживание. Переход к подпрограмме STATP возможен также и в том случае, если в данном такте моделирования Т заявка поступила в СМО и в этом же такте СМО покидает заявка, обслуживание которой завершено, т.е. идентификатор L=0 (см. блок 6 на рис. 7.3).
В подпрограмме STATP набираются статистические данные для построения эмпирической кумулятивной функции распределения А*(t) длин интервалов между двумя любыми соседними заявками. Алгоритм подпрограммы STATP будет рассмотрен ниже.
Затем следует постановка поступившей заявки в очередь, что осуществляется в подпрограмме OSTH. Анализ очереди на обслуживание состоит из анализа следующих событий:
а1) есть очередь и за такт Т поступила заявка;
а2) есть очередь и за такт Т не поступила заявка;
а3) нет очереди и за такт Т поступила заявка;
а4) нет очереди и за такт Т не поступила заявка.
Если поступившую в такт Т заявку идентифицировать обозначением N[J]=T, где J – ее номер в очереди, а N[J]=T – такт поступления заявки в систему, то при событии а1 поступившая заявка получит значение идентификатора N[J]=T, где J=JP+1, JP – число заявок в очереди в предшествующем такте Т-1. При событииа3 поступившая заявка получит значение идентификатора N[1]=T.
Если заявка поступила, а число заявок в очереди равно JPM, а также при полностью заполненном буфере очереди в этом такте не окончено обслуживание заявки, то поступившая заявка теряется. В этом случае происходит переход к подпрограмме набора статистических данных потерянных заявок STAТT.
Если прибор свободен от обслуживания (L=0) и имеется очередь на обслуживание (М=1), то обращаемся к подпрограмме выбора заявки на обслуживание из очереди WIB (см. работу блоков 10, 11, 12 на рис. 7.3).
В соответствии с заданной дисциплиной выбора на обслуживание осуществляется выбор заявки из очереди при условии, что прибор в такте Т свободен от обслуживания. Для заявки, выбранной на обслуживание, определяется время пребывания в очереди W и в подпрограмме набора статистических данных времени задержки в очереди STATO величина W фиксируется для набора статистических данных для дальнейшего построения кумулятивной эмпирической функции распределения времени ожидания W*(t).
Затем в алгоритме следует переход к подпрограмме определения времени обслуживания OBS (см. блок 14 на рис. 7.3). При имитации процессов (см. работу блоков 10, 11 на рис. 7.3), обслуживания прибором анализируются следующие события:
б1) обслуживание предыдущей заявки окончено, очереди нет и заявка не поступила;
б2) обслуживание окончено, заявка поступила, очередь из одной поступившей заявки;
б3) обслуживание окончено, очередь есть, заявка не поступила;
б4) обслуживание окончено, очередь есть, заявка поступила;
б5) обслуживание не окончено, очереди нет, заявка не поступила;
б6) обслуживание не окончено, очереди нет, заявка поступила;
б7) обслуживание не окончено, очередь есть, заявка не поступила;
б8) обслуживание не окончено, очередь есть, заявка поступила.
При выполнении событий б2, б3, б4 определяется время обслуживания В заявки, которая принята на обслуживание в соответствии с результатом работы подпрограммы WIB. При событиях б5 – б8 текущая величина времени обслуживания ВТ уменьшается на единицу. Текущая величина времени обслуживания ВТ введена в соответствии с динамикой изменения времени обслуживания, показанной на рис. 7.2.
Затем в подпрограмме набора статистических данных времени обслуживания STATB фиксируется величина В для последующего построения кумулятивной эмпирической функции распределения времени обслуживания В*(t). К подпрограмме STATB обращение происходит только в том такте Т, в котором определено значение времени обслуживания В при занятости прибора обслуживанием (см. блоки 15, 16, 17 на рис. 7.3).
В подпрограмме STATPZ (см. блок 20 на рис. 7.3) фиксируется случайная величина PZ – длительность периода занятости для набора статистических данных кумулятивной эмпирической функции распределения периода занятости Z*(t). Обращение в подпрограмме STATPZ происходит в том случае, если заявок в очереди нет (см. блок 19 на рис. 7.3), прибор свободен от обслуживания (см. блок 15 на рис. 7.3) и подсчитанная величина PZ больше нуля.
В подпрограмме STATW фиксируется случайная величина IN – интервал времени между двумя соседними обслуженными заявками, что позволяет набирать статистические данные для дальнейшего построения кумулятивной эмпирической функции распределения длин интервалов между обслуженными требованиями D*(t).
7.6.2. Алгоритмы подпрограмм.Рассмотрим особенности алгоритмов подпрограмм алгоритма имитационной модели одноканальной СМО. На рис. 7.4 приведена структурная схема алгоритма подпрограммы GEN.
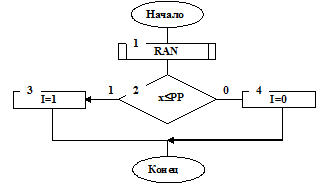
Рис. 7.4
В программе GEN событие появления заявки I=1 (см. блок 3 на рис. 7.4) либо событие непоявления заявки I=0 (см. блок 4 на рис. 7.4) выбираются по известной схеме моделирования случайных событий. Вероятность поступления заявки PP при условии пуассновского распределения входного потока заявок определится, как PP=aΔt.
На рис. 7.5 приведена структурная схема алгоритма подпрограммы STATP, который работает следующим образом.
Если в такте Т появилась на входе СМО заявка (I=1), то идентификатору ТK1 присваивается значение Т. Идентификатор TK1 принимает значение конца интервала между любыми двумя соседними заявками. Идентификатор TH1 принимает значение начала интервала. Длина интервала определится D1=TK1–TH1. Очевидно, что для определения интервала до следующей заявки, конец данного интервала станет началом следующего (см. блок 3 на рис. 7.5). Затем значение D1 сравнивается с заданными границами оценок D1[J]. При выполнении условия D1£D1[J] (см. блок 6 на рис. 7.4) в соответствующий счетчик K1[J] прибавляется единица.
Таким образом, в счетчиках K1[J] к окончанию процесса моделирования накапливаются частоты Nj событий, состоящих в том, что длины интервалов меньше соответствующих величин D1j. Эмпирические оценки вероятностей (частости) этих событий определятся по формулам
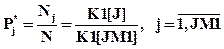 ,
,
где N – число заявок, поступивших в СМО за время моделирования, зафиксированное в счетчике К1[JM1]; JM1 – число счетчиков К1. Заметим, что в счетчик К1[1] заносится величина D11, в счетчик К1[2] заносится величина D12, …, в счетчик К1[JM1]заносится величина D1JM1, D11<D11<…<D1JM1.
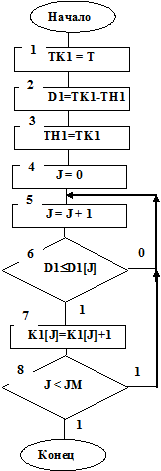
Рис. 7.5
Структурная схема алгоритма подпрограммы набора статистики о потерянных заявках STATT (см. рис. 7.6) аналогична схеме алгоритма подпрограммы STATP.
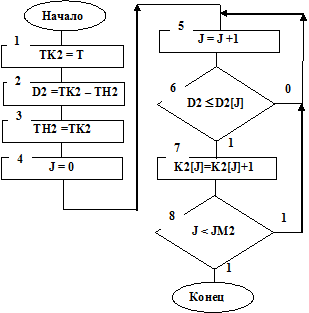
Рис. 7.6
Информация о частотах длин интервалов между потерянными заявками накапливается в счетчиках K2[J], а в счетчиках K2[JM2] будет к последнему такту моделирования TZ получено количество потерянных заявок. Частости событий, состоящих в том, что длины интервалов D2 меньше границ оценок D2[J], определятся по формуле
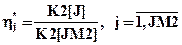 ,
,
а оценка вероятности (частость) потери заявок из-за занятости прибора и буфера очереди определится формулой
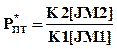 .
.
На рис. 7.7 приведена структурная схема алгоритма подпрограммы OSTH.
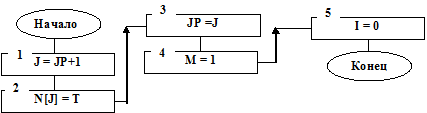
Рис. 7.7
Определяется номер в очереди J для поступившей заявки. Он будет на единицу больше номера JP последней заявки в очереди на обслуживание (см. блок 1 на рис. 7.7).
Для поступившей заявки определяется идентификатор N[J]=T (блок 2 на рис. 7.7), который имеет значение, равное времени поступления этой заявки в СМО. Число заявок в очереди стало на одну больше, то есть JP=J(блок 3 на рис. 7.7). Так как в очереди появилась заявка на обслуживание, то ключ М=1, а значение I=0, так как поступившая заявка «обработана» при постановке на очередь (блок 4 и блок 5 на рис. 7.7).
В имитационной модели предусмотрено применение трех дисциплин выбора заявок из очереди: первый пришел – первый обслужен (FIFO); последний пришел – первый обслужен (LIFO); случайный выбор заявки из очереди на обслуживание (SIRO).
На рис. 7.8 приведена структурная схема алгоритма подпрограммы WIBP – выбор заявки из очереди при прямом порядке обслуживания FIFO. Работает алгоритм следующим образом.
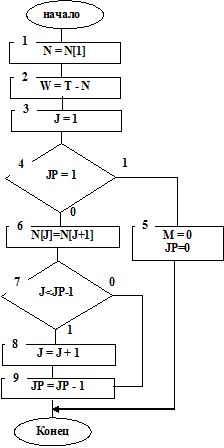
Рис. 7.8
Вызывается первый элемент массива N[1] (см. блок 1 на рис. 7.8), имеющий значение времени поступления в систему заявки, первой стоящей в очереди. В предшествующем такте Т-1 прибор освободился от обслуживания (L=0) и первая из очереди заявка в такте Т принимается к обслуживанию. Следовательно, время задержки этой заявки в очереди определится W=T–N(см. блок 2 на рис. 7.8). Затем, если очередь существует (см. блок 3 на рис. 7.8), необходимо «сдвинуть» массив очереди на один элемент вперед, то есть второй элемент массива становится первым, третий – вторым и т.д. (см. блоки 6, 7, 8 на рис. 7.8). Затем номер последней заявки в очереди уменьшается на единицу (см. блок 9 на рис. 7.8).
Очередь существует, если после выбора заявки на обслуживание номер последней заявки в очереди будет больше или равен двум (см. блок 3 на рис. 7.8). Если же в очереди была одна заявка (JP=1), то ключ М=0 и число заявок в очереди JP=0.
На рис. 7.9 приведена структурная схема алгоритма подпрограммы WIBI – выбор заявки из очереди при инверсном порядке обслуживания LIFO.
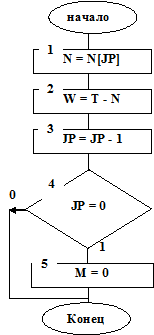
Рис. 7.9
При данном порядке обслуживания выбирается последняя из очереди заявка (ее номер JP) и время ее задержки в системе определится W=T–N[JP]. Число заявок в очереди после выбора уменьшается на единицу (см. блоки 1,2,3 на рис. 7.9). Затем проверяется условие наличия заявок в очереди (см. блок 4 на рис. 7.9). Если заявок в очереди нет, то ключ М=0.
На рис. 7.10 приведена структурная схема алгоритма подпрограммы WIBS – случайного (равновероятного) выбора заявки из очереди на обслуживание. Работает алгоритм следующим образом.
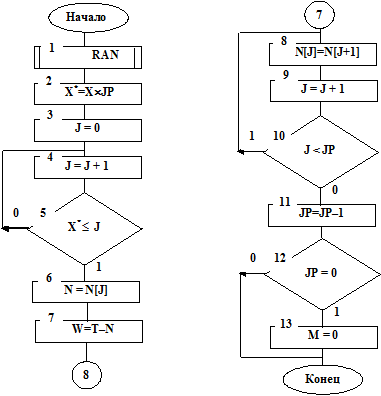
Рис. 7.10
Подпрограммой RAN (см. блок 1 на рис. 7.10) генерируется случайное число X, равновероятно распределенное в интервале (0,1). Затем величина этого числа приводится к длине очереди или величине интервала (0,JP). Для этого число X умножается на величину JP (см. блок 2 на рис. 7.10). Полученное число X*=X´JP равновероятно распределено в интервале (0,JP). Затем происходит поиск в схеме случайных событий (см. блоки 3, 4, 5 на рис. 7.10). При первом же выполнении условия считается, что на обслуживание случайно выбрана J-я заявка. Определяется ее время задержки W=T–N[J](см. блоки 6, 7 на рис. 7.10), а затем все заявки, стоящие в очереди после J-й, сдвигаются на один номер вперед (см. работу блоков 8, 9, 10 на рис. 7.10). Затем уменьшается на одну число заявок в очереди (см. блок 11 на рис. 7.10), и если число заявок в очереди равно нулю, то ключ М=0(см. блоки 12, 13 на рис. 7.10).
На рис. 7.11 приведена структурная схема алгоритма подпрограммы STATO – набора статистических данных о времени задержки заявок.
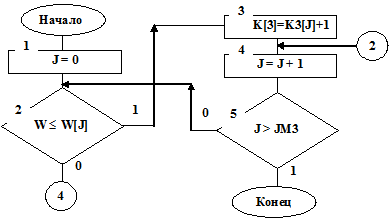
Рис. 7.11
Полученная в подпрограмме WIB случайная величина W сравнивается с границами W[J] по правилу 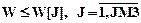 (см. блок 2 на рис. 7.11). В счетчиках K3[J] накапливается величина частоты события, состоящего в том, что случайная величина W≤W[J]. Оценки вероятностей (частости) этих событий определятся по формуле
(см. блок 2 на рис. 7.11). В счетчиках K3[J] накапливается величина частоты события, состоящего в том, что случайная величина W≤W[J]. Оценки вероятностей (частости) этих событий определятся по формуле
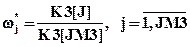 .
.
На рис. 7.12 приведена структурная схема алгоритма подпрограммы OBS - имитации обслуживания заявок прибором.
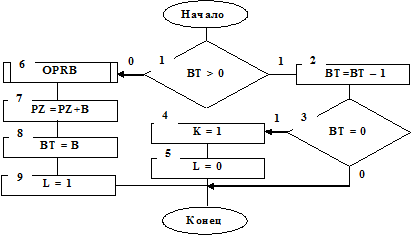
Рис. 7.12
Работает алгоритм следующим образом. Имитация длительности обслуживания должна осуществиться либо при поступлении заявки в СМО, свободную от обслуживания, либо после окончания обслуживания очередной заявки и при наличии заявок в очереди. Изменение времени обслуживания в каждом такте моделирования осуществляется идентификатором ВТ.
Если в (Т-1)-м такте не окончено обслуживание заявки, то ВТ>0 (см. блок 1 на рис. 7.12). Затем проверяется условие, не будет ли окончено обслуживание в Т-м такте (см. блоки 2, 3 на рис. 7.12). Если обслуживание окончено, то формируются признаки выходного потока заявок К=1 (заявка покидает СМО обслуженной) и свободного прибора (L=0). Если в предшествующий такт обслуживание было окончено (ВТ=0), то имитируется время обслуживания В в подпрограмме OPRB (см. блок 6 на рис. 7.12) для принятой на обслуживание заявки.
Время обслуживания В определяется исходя из задаваемого вида функции распределения вероятностей B(t). При имитации могут быть применены известные методы: метод обратных функций, метод ступенчатой аппроксимации и другие.
Наращивается значение идентификатора PZ – периода занятости (см. блок 7 на рис. 7.12). Определяется идентификатор текущего времени ВТ=В и устанавливается признак занятости прибора L=1.
На рис. 7.13 приведена структурная схема алгоритма подпрограммы STATB – набора статистических данных о времени обслуживания заявок.
Статистические данные накапливаются в такты, при которых прибор занят и начато обслуживание очередной заявки (см. блоки 15, 16 на рис. 7.13) L=1 и B>0, то есть в такты принятия заявок на обслуживание. В алгоритме подпрограммы STATB организован цикл по переменной J(см. блоки 1, 2, 5 на рис. 7.13). Случайная величина В сравнивается с границами В[J], заданными с экрана дисплея (см. блок 3 на рис. 7.13).
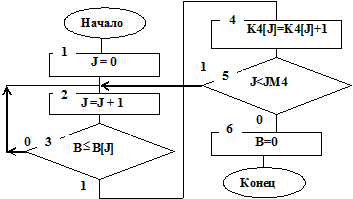
Рис. 7.13
В счетчиках K4[J] накапливаются величины, определяющие частоты, состоящие в том, что время обслуживания В меньше границы его оценки B[J], 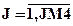 . Частости этих событий определяются формулой
. Частости этих событий определяются формулой
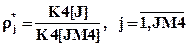 .
.
На рис. 7.14 приведена структурная схема алгоритма подпрограммы STATW– набора статистических данных выходного потока обслуженных заявок.
Набор статистических данных для исследования интервалов времени между обслуженными заявками осуществляется в такты, в которых истекает время обслуживания (L=0), обслуженная заявка покидает СМО, то есть признак наличия заявки выходного потока К=1 (см. блоки 15, 21 на рис. 7.3). В блоках 1, 2 (см. рис. 7.14) определяется интервал времени D3 между соседними обслуженными заявками. В блоке 3 начало нового интервала ТН3 между обслуженными заявками определяется как значение конца предшествующего интервала ТК3.
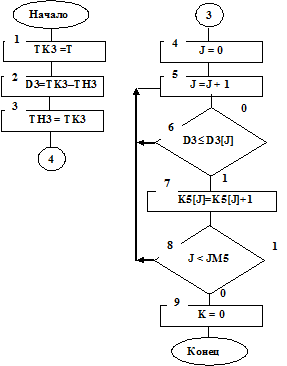
Рис. 7.14
Логика работы алгоритма подпрограммы STATW подобного изменения значений идентификаторов ТН3, ТК3 и определения значений идентификатора D3 показана на рис. 7.15.
В блоках 4,5,8 (см. рис. 7.14) организован цикл по переменной J, 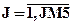 .
.
В счетчиках K5[J] накапливаются величины, определяющие события, состоящие в том, что длина интервала D3 между соседними обслуженными заявками меньше либо равна границе оценки D3[J], а частости этих событий определятся как
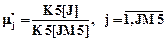 .
.
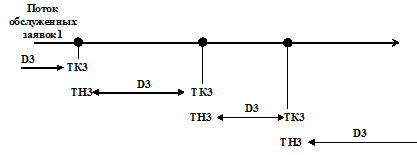
Рис. 7.15
На рис. 7.16 приведена структурная схема алгоритма подпрограммы STATPZ – набора статистических данных о длительности периода занятости.
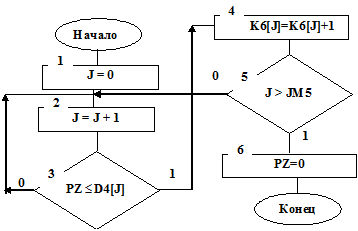
Рис. 7.16
Программа работает по аналогии с описанными выше программами набора статистических данных.
Набор статистических данных длин отрезков периода занятости PZ фиксируется в такты, когда окончилось обслуживание, L=0, значение идентификатора PZ отлично от нуля и нет в системе очереди, М=0 (см. блоки 15, 18, 19 на рис. 7.3).
В счетчиках К6[J] накапливаются частоты событий, состоящих в том, что длина периода занятости PZ меньше либо равна границам оценки D4[J]. Частоты этих событий определятся по формуле
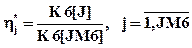 .
.
Полученные статистические данные во всех программах STATP, STATT, STATO, STATB, STATPZ и STATW позволяют построить кумулятивные эмпирические функции распределения:
- A*(t) – длин интервалов времени между заявками входного потока;
- Z*(t) – длин интервалов времени между потерянными заявками;
- W*(t) – времени задержки заявок в очереди;
- D*(t) – длин интервалов времени между обслуженными заявками;
- B*(t) – времени обслуживания заявок;
- П*(t) - периода занятости.
Пример построения эмпирических распределений на примере построения кумулятивной эмпирической функции распределения времени ожиданияW*(t) показан на рис. 7.17.

Рис. 7.17
– Конец работы –
Эта тема принадлежит разделу:
АНАЛИТИЧЕСКИЕ И ИМИТАЦИОННЫЕ МОДЕЛИ
ФЕДЕРАЛЬНОЕ АГЕНТСТВО ПО ОБРАЗОВАНИЮ... Технологический институт... Федерального государственного образовательного учреждения высшего профессионального образования...
Если Вам нужно дополнительный материал на эту тему, или Вы не нашли то, что искали, рекомендуем воспользоваться поиском по нашей базе работ: Имитационное моделирование одноканальной СМО
Что будем делать с полученным материалом:
Если этот материал оказался полезным ля Вас, Вы можете сохранить его на свою страничку в социальных сетях:
| Твитнуть |
Хотите получать на электронную почту самые свежие новости?

Подпишитесь на Нашу рассылку
Реклама





Информация в виде рефератов, конспектов, лекций, курсовых и дипломных работ имеют своего автора, которому принадлежат права. Поэтому, прежде чем использовать какую либо информацию с этого сайта, убедитесь, что этим Вы не нарушаете чье либо право.
© copyright 1999 - 2024 allRefs.net. Все права защищены. Страница сгенерирована за: 0.062 сек.
Новости и инфо для студентов