рефераты конспекты курсовые дипломные лекции шпоры

- Раздел Образование
- /
- Операционные системы, среды и оболочки
Реферат Курсовая Конспект
Операционные системы, среды и оболочки
Операционные системы, среды и оболочки - раздел Образование, Удк 681.3.06 Ббк 32.973.26-018.2 Ф-32 Рекомен...
| УДК 681.3.06 ББК 32.973.26-018.2 Ф-32 | Рекомендовано научно-методическим советом УрГЭУ в качестве учебного пособия для студентов всех форм обучения |
Рецензенты:
Кафедра Автоматизированных Информационных Технологий Экономического факультета Кабардино-Балкарского государственного университета
Кафедра прикладной математики Уральского государственного технического университета – УПИ
Ответственные за выпуск:
В. М. Иванов - директор ЦДО;
А. Ф. Шориков – зав. кафедрой информационных систем
в экономике
Федоров Е. В.
Учебно-методическое пособие разработано на основе государственных… В пособии изложен материал по курсу «Операционные системы, среды и оболочки», который студенты, обучающиеся по…НАЗНАЧЕНИЕ И ФУНКЦИИ ОПЕРАЦИОННОЙ СИСТЕМЫ
В соответствии с этим определением ОС выполняет две группы функций: предоставление пользователю или программисту вместо реальной аппаратуры… повышение эффективности использования компьютера путем рационального управления его ресурсами в соответствии с…Управление процессами
Важнейшей частью операционной системы, непосредственно влияющей на функционирование вычислительной машины, является подсистема управления… Для каждого вновь создаваемого процесса ОС генерирует системные… Чтобы процесс мог быть выполнен, операционная система должна назначить ему область оперативной памяти, в которой будут…Управление памятью
Память является для процесса таким же важным ресурсом, как и процессор, так как процесс может выполняться процессором только в том случае, если его… Существует большое разнообразие алгоритмов распределения памяти, которые… Одним из наиболее популярных способов управления памятью в современных операционных системах является механизм…Управление файлами и внешними устройствами
Способность ОС к «экранированию» сложностей реальной аппаратуры очень ярко проявляется в одной из основных подсистем ОС – файловой системе.… Чтобы представить большое количество наборов данных, разбросанных случайным…Защита данных и администрирование
Безопасность данных вычислительной системы обеспечивается средствами отказоустойчивости ОС, направленными на защиту от сбоев и отказов аппаратуры… Важным средством защиты данных являются функции аудита ОС, заключающиеся в… Поддержка отказоустойчивости реализуется операционной системой, как правило, на основе резервирования. Чаще всего в…Интерфейс прикладного программирования
Прикладные программисты используют в своих приложениях обращения к ОС, когда для выполнения тех или иных действий им требуется особый статус,… Возможности операционной системы доступны прикладному программисту в виде… Для разработчиков приложений все особенности конкретной операционной системы представлены особенностями ее API.…Пользовательский интерфейс
Операционная система должна обеспечивать удобный интерфейс не только для прикладных программ, но и для человека, работающего за терминалом. Этот… Современные ОС поддерживают развитые функции пользовательского интерфейса для… При работе за алфавитно-цифровым терминалом пользователь имеет в своем распоряжении систему команд, мощность которой…Контрольные вопросы
6. Что представляет собой операционная система?
7. Какие основные функции выполняет ОС?
8. Назовите основные ресурсы вычислительной системы.
9. В чем сходство и различие терминов «программа» и «процесс»?
10. Какие задачи по управлению ресурсами возложены на ОС?
11. Какой смысл в терминах ОС вкладывается в слово «подсистема»?
12. Какие основные подсистемы относятся к подсистемам управления ресурсами?
13. Какие подсистемы являются общими для всех ресурсов?
14. Какие типы процессов Вам известны?
15. Что подразумевают под термином «адресное пространство»?
16. Что такое «контекст процесса»?
17. Какие функции выполняет подсистема управления памятью?
18. Какие задачи решает подсистема управления виртуальной па-мятью?
19. В чем суть механизма защиты памяти?
20. Для каких целей служит файловая система (ФС)?
21. Как организована поддержка отказоустойчивости системы?
22. Какое средство предусмотрено в ОС для того, чтобы пользовательское приложение могло управлять аппаратными средствами ПК?
23. Назовите стандарт API для ОС UNIX.
Сетевые операционные системы
Сетевые операционные системы устанавливаются на компьютеры, объединенные в вычислительную сеть. Компьютерная сеть - это набор компьютеров, связанных коммуникационной системой… При организации сетевой работы операционная система играет роль интерфейса, скрывающего от пользователя все детали…Сетевые и распределенные ОС
В зависимости от того, какой виртуальный образ создает операционная система, чтобы подменить им реальную аппаратуру компьютерной сети, различают… Сетевая ОС предоставляет пользователю некую виртуальную вычислительную… При использовании ресурсов компьютеров сети пользователь сетевой ОС всегда помнит, что он имеет дело с сетевыми…Функциональные компоненты сетевой ОС
К основным функциональным компонентам сетевой ОС можно от-нести средства управления локальными ресурсами компьютера, которые реализуют все функции… Сетевые средства, в свою очередь, можно разделить на три компонента: серверная часть ОС – средства предоставления локальных ресурсов и услуг в общее пользование;Сетевые службы и сетевые сервисы
Совокупность серверной и клиентской частей ОС, предоставляющих доступ к конкретному типу ресурса компьютера через сеть, называется сетевой службой.… Говорят, что сетевая служба предоставляет пользователям сети некоторый набор… Каждая служба связана с определенным типом сетевых ресурсов и/или определенным способом доступа к этим ресурсам.…Встроенные сетевые службы и сетевые оболочки
На практике сложилось несколько подходов к построению сетевых операционных систем, различающихся глубиной внедрения сетевых служб в операционную… сетевые службы глубоко встроены в ОС; сетевые службы объединены в виде некоторого набора - оболочки;Требования к современным операционным системам
Главным требованием, предъявляемым к операционной системе, является выполнение основных функций эффективного управления ресурсами и обеспечение… Расширяемость. В то время как аппаратная часть компьютера устаревает за… Переносимость. В идеале код ОС должен легко переноситься с процессора одного типа на процессор другого типа и с…Контрольные вопросы
28. В чем сходство и различие сетевой и распределенной ОС?
29. Какие два признака характеризуют термин «сетевая ОС»?
30. Какие основные функциональные компоненты можно выделить в сетевой ОС?
31. Дайте определение сетевой службы.
32. Является ли сетевая служба только клиентской или только серверной?
33. Назовите принципиальное различие между клиентом и сервером.
34. Перечислите основные требования, предъявляемые к современным операционным системам.
АРХИТЕКТУРА ОПЕРАЦИОННОЙ СИСТЕМЫ
Любая хорошо организованная сложная система имеет понятную и рациональную структуру, т.е. разделяется на части - модули, имеющие вполне законченное… Функциональная сложность операционной системы неизбежно приводит к сложности… Большинство современных операционных систем представляют собой хорошо структурированные модульные системы, способные к…Ядро и вспомогательные модули ОС
Наиболее общим подходом к структурированию операционной системы является разделение всех ее модулей на две группы: ядро - модули ОС, выполняющие основные функции; модули, выполняющие вспомогательные функции ОС.Ядро и привилегированный режим
Для надежного управления ходом выполнения приложений операционная система должна иметь по отношению к приложениям определенные привилегии. Иначе… Обеспечить привилегии операционной системе невозможно без специальных средств… Так как ядро выполняет все основные функции ОС, то чаще всего именно ядро становится той частью ОС, которая работает в…Многослойная структура ОС
Вычислительную систему, работающую под управлением ОС на основе ядра, можно рассматривать как систему, состоящую из трех иерархически расположенных…Рис. 2.3. Структура ядра
Средства аппаратной поддержки ОС. До сих пор об операционной системе говорилось как о комплексе программ, но часть функций ОС может выполняться и аппаратными средствами. Поэтому иногда можно встретить определение операционной системы как совокупности программных и аппаратных средств, что и отражено на рис. 2.3. К операционной системе относят, естественно, не все аппаратные устройства компьютера, а только средства аппаратной поддержки ОС, т.е. те, которые прямо участвуют в организации вычислительных процессов: средства поддержки привилегированного режима, систему прерываний, средства переключения контекстов процессов, средства защиты областей памяти и т.п.
Машинно зависимые компоненты ОС. Этот слой образуют програм-мные модули, в которых отражается специфика аппаратной платформы компьютера. В идеале этот слой полностью экранирует вышележащие слои ядра от особенностей аппаратуры. Это позволяет разрабатывать вышележащие слои на основе машинно независимых модулей, существующих в единственном экземпляре для всех типов аппаратных платформ, поддерживаемых данной ОС.
Базовые механизмы ядра. Этот слой выполняет наиболее примитивные операции ядра, такие как программное переключение контекстов процессов, диспетчеризация прерываний, перемещение страниц из памяти на диск и обратно и т.п. Модули данного слоя не принимают решений о распределении ресурсов - они только отрабатывают принятые «наверху» решения, что и дает повод называть их исполнительными механизмами для модулей верхних слоев. Например, решение о том, что в данный момент нужно прервать выполнение текущего процесса «А» и начать выполнение процесса «В», принимается менеджером процессов на вышележащем слое, а слою базовых механизмов передается только директива о том, что нужно выполнить переключение с контекста текущего процесса на контекст процесса «В».
Менеджеры ресурсов. Этот слой состоит из мощных функциональных модулей, реализующих стратегические задачи по управлению основными ресурсами вычислительной системы. Обычно на данном слое работают менеджеры (называемые также диспетчерами) процессов, ввода-вывода, файловой системы и оперативной памяти. Разбиение на менеджеры может быть и несколько иным, например, менеджер файловой системы иногда объединяют с менеджером ввода-вывода, а функции управления доступом пользователей к системе в целом и ее отдельным объектам поручают отдельному менеджеру безопасности. Каждый из менеджеров ведет учет свободных и используемых ресурсов определенного типа и планирует их распределение в соответствии с запросами приложений. Например, менеджер виртуальной памяти управляет перемещением страниц из оперативной памяти на диск и обратно. Для исполнения принятых решений менеджер обращается к нижележащему слою базовых механизмов с запросами о загрузке (выгрузке) конкретных страниц. Внутри слоя менеджеров существуют тесные взаимные связи, отражающие тот факт, что для выполнения процессу нужен доступ одновременно к нескольким ресурсам - процессору, области памяти, возможно, к определенному файлу или устройству ввода-вывода. Например, при создании процесса менеджер процессов обращается к менеджеру памяти, который должен выделить процессу определенную область памяти для его кодов и данных.
Интерфейс системных вызовов. Этот слой является самым верхним слоем ядра и взаимодействует непосредственно с приложениями и системными утилитами, образуя прикладной программный интерфейс операционной системы. Функции API, обслуживающие системные вызовы, предоставляют доступ к ресурсам системы в удобной и компактной форме, без указания деталей их физического расположения.
Приведенное разбиение ядра ОС на слои является достаточно условным. В реальной системе количество слоев и распределение функций между ними может быть и иным. В системах, предназначенных для аппаратных платформ одного типа, например ОС NetWare, слой машинно зависимых модулей обычно не выделяется, сливаясь со слоем базовых механизмов и, частично, со слоем менеджеров ресурсов. Не всегда оформляются в отдельный слой базовые механизмы - в этом случае менеджеры ресурсов не только планируют использование ресурсов, но и самостоятельно реализуют свои планы.
Возможна и противоположная картина, когда ядро состоит из большего количества слоев. Например, менеджеры ресурсов, составляя определенный слой ядра, в свою очередь, могут обладать многослойной структурой. Прежде всего это относится к менеджеру ввода-вывода, нижний слой которого составляют драйверы устройств, например драйвер жесткого диска или драйвер сетевого адаптера, а верхние слои - драйверы файловых систем или протоколов сетевых служб, имеющие дело с логической организацией информации.
Способ взаимодействия слоев в реальной ОС также может отклоняться от описанной выше схемы. Для ускорения работы ядра в некоторых случаях происходит непосредственное обращение с верхнего слоя к функциям нижних слоев, минуя промежуточные.
Выбор количества слоев ядра является ответственным и сложным делом: увеличение числа слоев ведет к некоторому замедлению работы ядра за счет дополнительных накладных расходов на межслойное взаимодействие, а уменьшение числа слоев ухудшает расширяемость и логичность системы. Обычно операционные системы, прошедшие долгий путь эволюционного развития, например многие версии UNIX, имеют неупорядоченное ядро с небольшим числом четко выделенных слоев, а у сравнительно «молодых» операционных систем, таких как Windows NT, ядро разделено на большее число слоев, и их взаимодействие формализовано в гораздо большей степени.
Аппаратная зависимость ОС
Многие операционные системы успешно работают на различных аппаратных платформах без существенных изменений в своем составе. Во многом это… Опыт разработки операционных систем показывает: ядро можно спроектировать… Объем машинно зависимых компонентов ОС зависит от того, насколько велики отличия в аппаратных платформах, для которых…Переносимость операционной системы
Если код операционной системы может быть сравнительно легко перенесен с процессора одного типа на процессор другого типа и с аппаратной платформы… Хотя ОС часто описываются либо как переносимые, либо как непереносимые,… 1. Большая часть кода должна быть написана на языке, трансляторы которого имеются на всех машинах, куда предполагается…Контрольные вопросы
39. Назовите составляющие ОС.
40. На какие группы принято разделять модули ОС?
41. Какие базовые функции закреплены за модулями ядра?
42. На какие группы программ подразделяются вспомогательные модули ОС?
43. Какие режимы процессора Intel x86, используемые ОС для работы ядра, Вам известны?
44. Какой из режимов работы процессора Intel x86 используется при выполнении модулей ядра?
45. На какие слои подразделяется ядро ОС?
46. Какие функции выполняет слой базовых механизмов ядра?
47. Какие функции выполняет слой менеджеров ресурсов?
48. Можно ли рассматривать базовую систему ввода-вывода компьютера (BIOS) как часть операционной системы?
49. В каком случае ОС, написанная на ассемблере, является переносимой?
2.6. Микроядерная архитектура
Концепция
Суть микроядерной архитектуры состоит в следующем. В привилегированном режиме остается работать только очень небольшая часть ОС, называемая… Все остальные более высокоуровневые функции ядра оформляются в виде…Рис. 2.5. Реализация системного вызова в микроядерной архитектуре
2.6.2. Преимущества и недостатки микроядерной архитектуры
Высокая степень переносимости обусловлена тем, что весь машинно-зависимый код изолирован в микроядре, поэтому для переноса системы на новый процессор требуется меньше изменений, и все они логически сгруппированы.
Расширяемость присуща микроядерной ОС в очень высокой степени. В традиционных системах даже при наличии многослойной структуры нелегко удалить один слой и поменять его на другой по причине множественности и размытости интерфейсов между слоями. Добавление новых функций и изменение существующих требуют хорошего знания операционной системы и больших затрат времени. В то же время ограниченный набор четко определенных интерфейсов микроядра открывает путь к упорядоченному росту и эволюции ОС. Добавление новой подсистемы требует разработки нового приложения, что никак не затрагивает целостность микроядра. Микроядерная структура позволяет не только добавлять, но и сокращать число компонентов операционной системы, что также бывает очень полезно. При микроядерном подходе конфигурируемость ОС не вызывает никаких проблем и не требует особых мер - достаточно изменить файл с настройками начальной конфигурации системы или же остановить ненужные больше серверы в ходе работы обычными для остановки приложений средствами.
Использование микроядерной модели повышает надежность ОС. Каждый сервер выполняется в виде отдельного процесса в своей собственной области памяти и таким образом защищен от других серверов операционной системы, что не наблюдается в традиционной ОС, где все модули ядра могут влиять друг на друга. И если отдельный сервер терпит крах, то он может быть перезапущен без останова или повреждения остальных серверов ОС. Более того, поскольку серверы выполняются в пользовательском режиме, они не имеют непосредственного доступа к аппаратуре и не могут модифицировать память, в которой хранится и работает микроядро. Другим потенциальным источником повышения надежности ОС является уменьшенный объем кода микроядра по сравнению с традиционным
ядром - это снижает вероятность появления ошибок программирования.
Модель с микроядром хорошо подходит для поддержки распределенных вычислений, так как использует механизмы, аналогичные сетевым: взаимодействие клиентов и серверов путем обмена сообщениями. Серверы микроядерной ОС могут работать как на одном, так и на разных компьютерах. В этом случае при получении сообщения от приложения микроядро может обработать его самостоятельно и передать локальному серверу или же переслать по сети микроядру, работающему на другом компьютере. Переход к распределенной обработке требует минимальных изменений в работе операционной системы - просто локальный транспорт заменяется на сетевой.
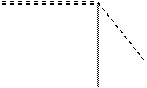
Производительность. При классической организации ОС (рис. 2.6, а) выполнение системного вызова сопровождается двумя переключениями режимов, а при микроядерной организации (рис. 2.6, б) - четырьмя. Таким образом, операционная система на основе микроядра при прочих равных условиях всегда будет менее производительной, чем ОС с классическим ядром. Именно по этой причине микроядерный подход не получил такого широкого распространения, которое ему предрекали.
Серьезность этого недостатка хорошо иллюстрирует история развития Windows NT. В версиях 3.1 и 3.5 диспетчер окон, графическая библиотека и высокоуровневые драйверы графических устройств входили в состав сервера пользовательского режима, и вызов функций этих модулей осуществлялся в соответствии с микроядерной схемой. Однако очень скоро разработчики Windows NT поняли, что такой механизм обращений к часто используемым функциям графического интерфейса значительно замедляет работу приложений и делает данную операционную систему уязвимой в условиях острой конкуренции. В результате в версию Windows NT 4.0 были внесены существенные изменения - все перечисленные выше модули были перенесены в ядро, что отдалило эту ОС от идеальной микроядерной архитектуры, но зато резко повысило ее производительность.
Приложение Приложение
 |  |
Ядро

 t t
t t
 | |
а
Приложение Сервер ОС Приложение
 | |||||||
 | |||||||
 | |||||||
 |
Микроядро Микроядро
 t t t t
t t t t
 | | | |
б
Рис. 2.6. Смена режимов при выполнении системного вызова
Этот пример иллюстрирует главную проблему, с которой сталкиваются разработчики операционной системы, решившие применить микроядерный подход: что включать в микроядро, а что выносить в пользовательское пространство? В идеальном случае микроядро может состоять только из средств передачи сообщений, средств взаимодействия с аппаратурой, в том числе средств доступа к механизмам привилегированной защиты. Однако многие разработчики не всегда жестко придерживаются принципа минимизации функций ядра, часто жертвуя этим ради повышения производительности. В результате реализуемые ОС образуют некоторый спектр, на одном краю которого находятся системы с минимально возможным микроядром, а на другом – системы, подобные Windows NT, в которых микроядро выполняет достаточно большой объем функций.
Совместимость и множественные прикладные среды
В то время как многие архитектурные особенности операционных систем непосредственно касаются только системных программистов, концепция множественных прикладных сред непосредственно связана с нуждами конечных пользователей - с возможностью операционной системы выполнять приложения, написанные для других операционных систем.
Такое свойство операционной системы называется совместимостью.
Двоичная совместимость и совместимость исходных текстов
Необходимо различать совместимость на двоичном уровне и совместимость на уровне исходных текстов. Приложения обычно хранятся в ОС в виде исполняемых… Совместимость на уровне исходных текстов требует наличия соответствующего… Для этого достаточно соблюдения следующих условий:Трансляция библиотек
Одной из составляющих, формирующих прикладную программную среду, является набор функций интерфейса прикладного программирования API, которые… Например, для Windows-программы, работающей на Macintosh, при интерпретации… Чтобы программа, написанная для одной ОС, могла быть выполнена в рамках другой ОС, недостаточно лишь обеспечить…Способы реализации прикладных программных сред
Во многих версиях ОС UNIX транслятор прикладных сред реализуется в виде обычного приложения. В операционных системах, построенных с использованием… Один из наиболее очевидных вариантов реализации множественных прикладных сред… Приложение ОС2 API ОС2 Транслятор системных вызовов …Контрольные вопросы
54. Каким термином в микроядерной архитектуре принято называть менеджеры ресурсов, вынесенные в пользовательский режим?
55. Можно ли считать микроядерную архитектуру в высокой степени переносимой?
56. Почему микроядерная архитектура ОС в большей степени расширяема, чем классическая ОС?
57. Является ли микроядерная архитектура более надежной, чем традиционная?
58. Укажите причину, по которой производительность микроядерной архитектуры ниже, чем производительность традиционной ОС.
59. Можно ли считать ОС Windows NT 4.0 системой с микроядерной архитектурой?
60. Какие виды совместимости Вам известны?
61. За счет каких действий достигается двоичная совместимость для процессоров различных архитектур?
62. Укажите способ, который позволяет повысить производительность ПК при выполнении «чужого» исполняемого файла.
63. Достаточно ли одного метода трансляции библиотек для полной совместимости приложений?
ПРОЦЕССЫ И ПОТОКИ
Важнейшей функцией операционной системы является организация рационального использования всех ее аппаратных и информационных ресурсов. К основным…Мультипрограммирование
Мультипрограммирование или многозадачность (multitasking) - это способ организации вычислительного процесса, при котором на одном процессоре… Наиболее характерными критериями эффективности вычислительных систем… пропускная способность - количество задач, выполняемых вычисли-тельной системой в единицу времени;Мультипрограммирование в системах пакетной обработки
При использовании мультипрограммирования в системах пакетной обработки для повышения пропускной способности компьютера главной целью является… При возникновении такого рода блокировки выполняемой задачи естественным… Системы пакетной обработки предназначались для решения задач в основном вычислительного характера, не требующих…Мультипрограммирование в системах разделения времени
Повышение удобства и эффективности работы пользователя является целью другого способа мультипрограммирования - разделения времени.
В системах разделения времени пользователям (или одному пользователю) предоставляется возможность интерактивной работы сразу с несколькими приложениями. Для этого каждое приложение должно регулярно получать возможность «общения» с пользователем. Понятно, что в пакетных системах возможности диалога пользователя с приложением весьма огра-ничены.
В системах разделения времени эта проблема решается за счет того, что ОС принудительно периодически приостанавливает приложения, не дожидаясь, когда они добровольно освободят процессор. Всем приложениям попеременно выделяется квант процессорного времени, таким образом пользователи, запустившие программы на выполнение, получают возможность поддерживать с ними диалог.
Системы разделения времени призваны исправить основной недостаток систем пакетной обработки - изоляцию пользователя-программиста от процесса выполнения его задач. Каждому пользователю в этом случае предоставляется терминал, с которого он может вести диалог со своей программой. Так как в системах разделения времени каждой задаче выделяется только квант процессорного времени, ни одна задача не занимает процессор надолго и время ответа оказывается приемлемым. Если квант выбран достаточно небольшим, то у всех пользователей, одновременно работающих на одной и той же машине, складывается впечатление, что каждый из них единолично использует машину.
Ясно, что системы разделения времени обладают меньшей пропускной способностью, чем системы пакетной обработки, так как на выполнение принимается каждая запущенная пользователем задача, а не та, которая «выгодна» системе. Кроме того, производительность системы снижается из-за возросших накладных расходов вычислительной мощности на более частое переключение процессора с задачи на задачу. Это вполне соответствует тому, что критерием эффективности систем разделения времени является не максимальная пропускная способность, а удобство и эффективность работы пользователя. Вместе с тем мультипрограммное выполнение интерактивных приложений повышает и пропускную способность компьютера (пусть не в такой степени, как пакетные системы).
Аппаратура загружается лучше, поскольку в то время, пока одно приложение ждет сообщения пользователя, другие приложения могут обрабатываться процессором.
Мультипрограммирование в системах реального времени
Еще одна разновидность мультипрограммирования используется в системах реального времени, предназначенных для управления с компьютера различными… В системах реального времени мультипрограммная смесь представляет собой… В системах реального времени не стремятся максимально загружать все устройства, наоборот, при проектировании…Контрольные вопросы
68. Каким термином принято называть способ организации вычислительного процесса, при котором на одном процессоре попеременно выполняются несколько программ?
69. В чем суть концепции мультипрограммирования в системах пакетной обработки?
70. Какая главная цель ставится перед ОС в системах пакетной обработки?
71. Допускает ли система пакетной обработки ситуацию «зависа-
ния» ПК?
72. Какая из систем – пакетной обработки или разделения времени – обладает большей пропускной способностью?
73. Какой тип мультипрограммирования принято использовать в ОС, предназначенных для управления различными техническими объектами?
Мультипроцессорная обработка
Мультипроцессорная обработка - это способ организации вычислительного процесса в системах с несколькими процессорами, при котором несколько задач… Концепция мультипроцессирования не нова, она известна с 1970-х годов, но до… Не следует путать мультипроцессорную обработку с мультипрограммной обработкой. В мультипрограммных системах…Контрольные вопросы
77. Назовите известные Вам архитектуры мультипроцессорных
систем.
78. Назовите основные отличия симметричной и асимметричной архитектур.
79. Какой термин используется для обозначения асимметричной архитектуры?
80. Можно ли реализовать асимметричную организацию вычислительного процесса в симметричной архитектуре?
Планирование процессов и потоков
Одной из основных подсистем мультипрограммной ОС, непо-средственно влияющей на функционирование вычислительной машины, является подсистема… Каждый раз, когда процесс завершается, ОС предпринимает шаги, чтобы «зачистить…Создание процессов и потоков
Создать процесс - это прежде всего означает создать описатель процесса, в качестве которого выступает одна или несколько информационных структур,… Создание процесса включает также загрузку кодов и данных исполняемой программы… В многопоточной системе при создании процесса ОС создает для каждого процесса как минимум один поток выполнения. При…Планирование и диспетчеризация потоков
На протяжении существования процесса выполнение его потоков может быть многократно прервано и продолжено. (В системе, не поддерживающей потоки, все… Переход от выполнения одного потока к другому осуществляется в результате… Планирование потоков, по существу, включает в себя решение двух задач:Состояния потока
ОС выполняет планирование потоков, принимая во внимание их состояние. В мультипрограммной системе поток может находиться в одном из трех основных… выполнение - активное состояние потока, во время которого поток обладает всеми… ожидание - пассивное состояние потока, находясь в котором поток заблокирован по своим внутренним причинам (ждет…Вытесняющие и невытесняющие алгоритмы планирования
С самых общих позиций все множество алгоритмов планирования можно разделить на два класса: вытесняющие и невытесняющие. Невытесняющие (non-preemptive) алгоритмы планирования основаны на том, что… Вытесняющие (preemptive) алгоритмы - это такие способы планирования потоков, в которых решение о переключении…Алгоритмы планирования, основанные на квантовании
В основе многих вытесняющих алгоритмов планирования лежит концепция квантования. В соответствии с этой концепцией каждому потоку поочередно для… Смена активного потока происходит, если: поток завершился и покинул систему;Рис. 3.3. Граф состояний потока в системе с квантованием
Кванты, выделяемые потокам, могут быть одинаковыми для всех потоков или различными.
Если квант короткий, то суммарное время, которое проводит поток в ожидании процессора, прямо пропорционально времени, требуемому для его выполнения (то есть времени, которое потребовалось бы для выполнения этого потока при монопольном использовании вычислительной си-стемы).
Чем больше квант, тем выше вероятность того, что потоки завершатся в результате первого же цикла выполнения, и тем менее явной становится зависимость времени ожидания потоков от времени их выполнения. При достаточно большом кванте алгоритм квантования вырождается в алгоритм последовательной обработки, присущий однопрограммным системам, при котором время ожидания задачи в очереди никак не зависит от ее длительности. Кванты, выделяемые одному потоку, могут быть фиксированной величины, а могут и изменяться в разные периоды жизни потока. Пусть, например, первоначально каждому потоку назначается достаточно большой квант, а величина каждого следующего кванта уменьшается до некоторой заранее заданной величины. В таком случае преимущество получают короткие задачи, которые успевают выполняться в течение первого кванта, а длительные вычисления будут проводиться в фоновом режиме. Можно представить себе алгоритм планирования, в котором каждый следующий квант, выделяемый определенному потоку, больше предыдущего. Такой подход позволяет уменьшить накладные расходы на переключение задач в том случае, когда сразу несколько задач выполняют длительные вычисления.
Многозадачные ОС теряют некоторое количество процессорного времени для выполнения вспомогательных работ во время переключения контекстов задач. При этом запоминаются и восстанавливаются регистры, флаги и указатели стека, а также проверяется статус задач для передачи управления. Затраты на эти вспомогательные действия не зависят от величины кванта времени, поэтому чем больше квант, тем меньше суммарные накладные расходы, связанные с переключением потоков.
В алгоритмах, основанных на квантовании, какую бы цель они ни преследовали (предпочтение коротких или длинных задач, минимизация накладных расходов, связанных с переключениями), не используется никакой предварительной информации о задачах. При поступлении задачи на обработку ОС не имеет никаких сведений о том, является ли она короткой или длинной, насколько интенсивными будут ее запросы к устройствам ввода-вывода, насколько важно ее быстрое выполнение и т.д. Дифференциация обслуживания при квантовании базируется на «истории существования» потока в системе.
Алгоритмы планирования, основанные на приоритетах
Другой важной концепцией, лежащей в основе многих вытесняющих алгоритмов планирования, является приоритетное обслуживание. Приоритетное обслуживание… Приоритет может выражаться целым или дробным, положительным или отрицательным… Во многих ОС предусматривается возможность изменения приоритетов в течение жизни потока. Изменение приоритета может…Рис. 3.4. Схема назначения приоритетов в Windows NT
В Windows NT с течением времени приоритет потока, относящегося к классу потоков с переменными приоритетами, может отклоняться от базового приоритета потока, причем эти изменения могут быть не связаны с изменениями базового приоритета процесса. ОС может повышать приоритет потока (который в этом случае называется динамическим) в тех случаях, когда поток не полностью использовал отведенный ему квант, или понижать приоритет, если квант был использован полностью. ОС наращивает приоритет дифференцированно, в зависимости от того, какого типа событие не дало потоку полностью использовать квант. В частности, ОС повышает приоритет в большей степени потокам, которые ожидают ввода с клавиатуры (интерактивным приложениям), и в меньшей степени - потокам, выполняющим дисковые операции. Именно на основе динамических приоритетов осуществляется планирование потоков. Начальной точкой отсчета для динамического приоритета является значение базового приоритета потока. Значение динамического приоритета потока ограничено снизу его базовым приоритетом, верхней же границей является нижняя граница диапазона приоритетов реального времени.
В современных ОС существует две разновидности приоритетного планирования: обслуживание с относительными приоритетами и обслуживание с абсолютными приоритетами.
В обоих случаях выбор потока на выполнение из очереди готовых осуществляется одинаково: выбирается поток, имеющий наивысший приоритет. Однако проблема определения момента смены активного потока решается по-разному. В системах с относительными приоритетами активный поток выполняется до тех пор, пока он сам не покинет процессор, перейдя в состояние ожидания (или же произойдет ошибка, или поток завершится).
В системах с абсолютными приоритетами выполнение активного потока прерывается, кроме указанных выше причин, еще при одном условии: если в очереди готовых потоков появился поток, приоритет которого выше приоритета активного потока. В этом случае прерванный поток переходит в состояние готовности.
В системах, в которых планирование осуществляется на основе относительных приоритетов, минимизируются затраты на переключения процессора с одной работы на другую. С другой стороны, здесь могут возникать ситуации, когда одна задача занимает процессор долгое время. Ясно, что для систем разделения времени и реального времени такая дисциплина обслуживания не подходит: интерактивное приложение может ждать своей очереди часами, пока вычислительной задаче не потребуется ввод-вывод. А вот в системах пакетной обработки (в том числе известной ОС OS/360) относительные приоритеты используются широко.
В системах с абсолютными приоритетами время ожидания потока в очередях может быть сведено к минимуму, если ему назначить самый высокий приоритет. Такой поток будет вытеснять из процессора все остальные потоки (кроме потоков, имеющих такой же наивысший приоритет). Это делает планирование на основе абсолютных приоритетов подходящим для систем управления объектами, в которых важна быстрая реакция на событие.
Смешанные алгоритмы планирования
Во многих операционных системах алгоритмы планирования построены с использованием как концепции квантования, так и приоритетов. Например, в основе… Рассмотрим более подробно алгоритм планирования в операционной системе UNIX… Каждый процесс в зависимости от задачи, которую он решает, относится к одному из трех определенных в системе…Синхронизация процессов и потоков
Цели и средства синхронизации
Существует достаточно обширный класс средств операционной системы, с помощью которых обеспечивается взаимная синхронизация процессов и потоков.… Потоки в общем случае (когда программист не предпринял специальных мер по их…Сигналы
Сигнал дает возможность задаче реагировать на событие, источником которого может быть операционная система или другая задача. Сигналы вызывают…Контрольные вопросы
86. Какие термины ОС используются для обозначения единицы работы вычислительной системы?
87. Назовите отличия в организации вычислительного процесса на уровне потоков от организации вычислений на уровне процессов.
88. Дайте определение дескриптора процесса.
89. Что такое «контекст процесса»?
90. Назовите команду, с помощью которой в ОС UNIX происходит порождение процессов.
91. Назовите основные состояния потоков.
92. Какие алгоритмы планирования потоков Вам известны?
93. Чем различаются вытесняющий и невытесняющий алгоритмы планирования?
94. В чем суть концепции квантования?
95. Какой принцип заложен в алгоритм планирования потоков, основанный на приоритете обслуживания?
96. Кто может выступать в качестве инициатора изменения приоритета потока?
97. Какие разновидности приоритетного планирования Вам из-вестны?
98. В чем отличие абсолютных и относительных приоритетов?
99. Какая зависимость (прямая или обратная) между квантом и приоритетом реализована в ОС UNIX System?
100. Какую роль выполняет сигнал в ОС?
УПРАВЛЕНИЕ ПАМЯТЬЮ
Функции операционной системы по управлению памятью
Под памятью (memory) здесь подразумевается оперативная память компьютера. В отличие от памяти жесткого диска, которую называют внешней памятью… Память является важнейшим ресурсом, требующим тщательного управления со… Помимо первоначального выделения памяти процессам при их создании ОС должна также заниматься динамическим…Типы адресов
Для идентификации переменных и команд на разных этапах жизненного цикла программы используются символьные имена (метки), виртуальные адреса и… Символьные имена присваивает пользователь при написании программы на… Виртуальные адреса, называемые иногда математическими или логическими адресами, вырабатывает транслятор, переводящий…Контрольные вопросы
104. Что принято понимать под термином «виртуальное адресное пространство»?
105. Могут ли совпадать виртуальные адреса команд разных процессов?
106. Какие способы структуризации виртуального адресного про-странства Вам известны?
107. Обязательно ли виртуальное адресное пространство требует наличия механизма виртуальной памяти?
108. На какие части в современных ОС разделяется виртуальная память?
109. Какой способ преобразования виртуальных адресов в физические адреса ОП жестко привязывает программу к первоначально выделенному участку памяти?
Алгоритмы распределения памяти
Следует ли назначать каждому процессу одну непрерывную область физической памяти или можно выделять память «кусками»? Должны ли сегменты программы,… На рис. 4.3 представлена схема алгоритмов распределения памяти. Методы распределения памяти С использованием внешней памяти Без…Рис. 4.3. Классификация методов распределения памяти
Все алгоритмы разделены на два класса: алгоритмы, в которых используется перемещение сегментов процессов между оперативной памятью и диском, и алгоритмы, в которых внешняя память не привлекается.
Алгоритмы распределения без использования внешней памяти
Распределение памяти динамическими разделами
В случае распределения памяти машины динамическими разделами каждому вновь поступающему на выполнение приложению на этапе создания процесса выделяется вся необходимая ему память (изначально вся память, отводимая приложениям, свободна). Если достаточный объем памяти отсутствует, то приложение не принимается на выполнение и процесс для него не создается. После завершения процесса память освобождается, и на это место может быть загружен другой процесс. Таким образом, в произвольный момент времени оперативная память представляет собой случайную последовательность занятых и свободных участков (разделов) произвольного размера.
При этом операционной системе, использующей этот метод управления памятью, приходится решать перечисленные ниже задачи.
Ведение таблиц свободных и занятых областей. В этих областях указываются начальные адреса и размеры участков памяти.
Анализ требований к памяти. При создании нового процесса просматриваются таблицы свободных областей и выбирается раздел, размер которого достаточен для размещения кодов и данных нового процесса. Выбор раздела может осуществляться по разным правилам: первый попавшийся раздел достаточного размера; раздел, имеющий наименьший достаточный размер, или раздел, имеющий наибольший достаточный
размер.
Загрузка программы в выделенный ей раздел и корректировка таблиц свободных и занятых областей. Данный способ предполагает, что программный код не перемещается во время выполнения, а значит, настройка адресов может быть проведена единовременно во время загрузки.
Корректировка таблиц свободных и занятых областей. Эта операция проводится после завершения процесса.
Методу распределения памяти динамическими разделами присущ серьезный недостаток, связанный с фрагментацией памяти, т.е. наличием большого числа несмежных участков свободной памяти малого размера (фрагментов), настолько малого, что ни одна из вновь поступающих программ не сможет уместиться ни в одном из участков, хотя суммарный объем фрагментов может составить значительную величину, намного превышающую требуемый объем памяти. Этот метод управления памятью лежит в основе подсистем управления памятью первых ОС 1960–1970-х годов.
Распределение памяти перемещаемыми разделами
Одним из методов борьбы с фрагментацией является перемещение всех занятых участков в сторону старших или младших адресов, с тем чтобы вся свободная память образовала единую свободную область. В дополнение к задачам, которые решает ОС при распределении памяти динамическими разделами, в данном случае она должна еще время от времени копировать содержимое разделов из одного места памяти в другое, при этом корректируя таблицы свободных и занятых областей. Эта процедура называется сжатием. Сжатие может выполняться либо при каждом завершении процесса, либо только тогда, когда для вновь создаваемого процесса нет свободного раздела достаточного размера. В первом случае требуется меньше вычислительной работы при корректировке таблиц свободных и занятых областей, а во втором - реже выполняется процедура сжатия.
Так как программы перемещаются по оперативной памяти в ходе своего выполнения, то в данном случае невозможно выполнить настройку адресов с помощью перемещающего загрузчика. Здесь более подходящим оказывается динамическое преобразование адресов.
Хотя процедура сжатия и приводит к более эффективному использованию памяти, она может потребовать значительного времени, что часто перевешивает преимущества данного метода.
Концепция сжатия применяется и при использовании других методов распределения памяти, когда отдельному процессу выделяется не одна сплошная область памяти, а несколько несмежных участков памяти произвольного размера (сегментов). Такой подход был использован в ранних версиях OS/2, в которых память распределялась сегментами, а возникавшая при этом фрагментация устранялась путем периодического перемещения сегментов.
Алгоритмы распределения с использованием внешней памяти
Необходимым условием для того, чтобы программа могла выполняться, является ее нахождение в оперативной памяти. Объем оперативной памяти, который… Большое количество задач, необходимое для высокой загрузки процессора, требует… В мультипрограммном режиме помимо активного процесса, т.е. процесса, коды которого в настоящий момент интерпретируются…Свопинг и виртуальная память
Виртуализация оперативной памяти осуществляется совокупностью программных модулей ОС и аппаратных схем процессора и включает решение следующих… размещение данных в запоминающих устройствах разного типа, например, часть… выбор образов процессов или их частей для перемещения из оперативной памяти на диск и обратно;Страничное распределение
При страничном распределении виртуальное адресное пространство каждого процесса делится на части одинакового, фиксированного для данной системы… Вся оперативная память машины также делится на части такого же размера,… При создании процесса ОС загружает в оперативную память несколько его виртуальных страниц (начальные страницы кодового…Сегментное распределение
При страничной организации виртуальное адресное пространство процесса делится на равные части механически, без учета смыслового значения данных. В… Кроме того, разбиение виртуального адресного пространства на «осмысленные»… Тогда коды этой подпрограммы могут быть оформлены в виде отдельного сегмента и включены в виртуальные адресные…Рис. 4.4. Распределение памяти сегментами
На этапе создания процесса во время загрузки его образа в оперативную память система создает таблицу сегментов процесса (аналогичную таблице страниц), в которой для каждого сегмента указываются:
физический адрес сегмента в оперативной памяти;
размер сегмента;
правила доступа к сегменту;
признаки модификации, присутствия и обращения к данному сегменту, а также некоторая другая информация.
Если виртуальные адресные пространства нескольких процессов включают один и тот же сегмент, то в таблицах сегментов этих процессов делаются ссылки на один и тот же участок оперативной памяти, в который данный сегмент загружается в единственном экземпляре.
Как видно, сегментное распределение памяти имеет очень много общего со страничным распределением.
Механизмы преобразования адресов этих двух способов управления памятью тоже весьма схожи, но есть и отличие, заключающееся в том, что сегменты имеют произвольный размер, а страницы – постоянный.
Виртуальный адрес при сегментной организации памяти может быть представлен парой (g, s), где g - номер сегмента, a s - смещение в сегменте. Физический адрес получается путем сложения адреса сегмента, который определяется по номеру сегмента g из таблицы сегментов,
и смещения s.
Недостатком сегментного распределения является избыточность. При сегментной организации единицей перемещения между памятью и диском является сегмент, имеющий в общем случае объем больший, чем страница. Однако во многих случаях для работы программы вовсе не требуется загружать весь сегмент целиком, достаточно было бы одной или двух страниц. Аналогично при отсутствии свободного места в памяти не стоит выгружать целый сегмент, когда можно обойтись выгрузкой нескольких страниц.
Но главный недостаток сегментного распределения - это фрагментация, которая возникает из-за непредсказуемости размеров сегментов.
В процессе работы системы образуются небольшие участки свободной памяти, в которые не может быть загружен ни один сегмент. Суммарный объем, занимаемый фрагментами, может составить существенную часть общей памяти системы, приводя к ее неэффективному использованию.
Система с сегментной организацией функционирует аналогично системе со страничной организацией: при каждом обращении к оперативной памяти выполняется преобразование виртуального адреса в физический, время от времени происходят прерывания, связанные с отсутствием нужных сегментов в памяти, при необходимости освобождения памяти некоторые сегменты выгружаются.
Одним из существенных отличий сегментной организации памяти от страничной является возможность задания дифференцированных прав доступа процесса к его сегментам. Например, один сегмент данных, содержащий исходную информацию для приложения, может иметь права доступа «только чтение», а сегмент данных, представляющий результаты, - «чтение и запись». Это свойство дает принципиальное преимущество сегментной модели памяти перед страничной.
Сегментно-страничное распределение
Данный метод представляет собой комбинацию страничного и сегментного механизмов управления памятью и направлен на реализацию достоинств обоих… Так же как и при сегментной организации памяти, виртуальное адресное… В большинстве современных реализаций сегментно-страничной организации памяти, в отличие от набора виртуальных…Рис. 4.5. Два способа сегментации
Деление общего линейного виртуального адресного пространства процесса и физической памяти на страницы осуществляется так же, как это делается при страничной организации памяти. Размер страниц выбирается равным степени двойки, что упрощает механизм преобразования виртуальных адресов в физические.
Виртуальные страницы нумеруются в пределах виртуального адресного пространства каждого процесса, а физические страницы - в пределах оперативной памяти. При создании процесса в память загружается только часть страниц, остальные загружаются по мере необходимости.
Время от времени система выгружает уже ненужные страницы, освобождая память для новых страниц. ОС ведет для каждого процесса таблицу страниц, в которой указывается соответствие виртуальных страниц физическим.
Базовые адреса таблицы сегментов и таблицы страниц процесса являются частью его контекста. При активизации процесса эти адреса загружаются в специальные регистры процессора и используются механизмом преобразования адресов.
Преобразование виртуального адреса в физический происходит в два этапа.
1. На первом этапе работает механизм сегментации. Исходный виртуальный адрес, заданный в виде пары (номер сегмента, смещение), преобразуется в линейный виртуальный адрес. Для этого на основании базового адреса таблицы сегментов и номера сегмента вычисляется адрес дескриптора сегмента. Анализируются поля дескриптора, и выполняется проверка возможности выполнения заданной операции. Если доступ к сегменту разрешен, то вычисляется линейный виртуальный адрес путем сложения базового адреса сегмента, извлеченного из дескриптора, и смещения, заданного в исходном виртуальном адресе.
2. На втором этапе работает страничный механизм. Полученный линейный виртуальный адрес преобразуется в искомый физический адрес.
В результате преобразования линейный виртуальный адрес представляется в том виде, в котором он используется при страничной организации памяти, а именно, в виде пары (номер страницы, смещение в странице).
Преобразование адреса происходит так же, как при страничной организации: старшие разряды линейного виртуального адреса, содержащие номер виртуальной страницы, заменяются номером физической страницы, взятым из таблицы страниц, а младшие разряды виртуального адреса, содержащие смещение, остаются без изменения.
Рассмотрим еще одну возможную схему управления памятью, основанную на комбинировании сегментного и страничного механизмов. Так же как и в предыдущих случаях, виртуальное пространство процесса делится на сегменты, а каждый сегмент, в свою очередь, делится на виртуальные страницы. Первое отличие состоит в том, что виртуальные страницы нумеруются не в пределах всего адресного пространства процесса, а в пределах сегмента. Виртуальный адрес в этом случае выражается тройкой (номер сегмента, номер страницы, смещение в странице).
Загрузка процесса выполняется операционной системой постранично, при этом часть страниц размещается в оперативной памяти, а часть - на диске. Для каждого процесса создается собственная таблица сегментов, а для каждого сегмента - своя таблица страниц. Адрес таблицы сегментов загружается в специальный регистр процессора, когда активизируется соответствующий процесс.
Таблица страниц состоит из дескрипторов, содержимое которых полностью аналогично содержимому ранее описанных дескрипторов страниц. А вот таблица сегментов состоит из дескрипторов сегментов, которые вместо информации о расположении сегментов в виртуальном адресном пространстве содержат описание расположения таблиц страниц в физической памяти. Это является вторым существенным отличием данного подхода от ранее рассмотренной схемы сегментно-страничной организации.
Разделяемые сегменты памяти
Подсистема виртуальной памяти представляет собой удобный механизм для решения задачи совместного доступа нескольких процессов к одному и тому же сегменту памяти, который в этом случае называется разделяемой памятью (shared memory).
Хотя основной задачей операционной системы при управлении памятью является защита областей оперативной памяти, принадлежащей одному из процессов, от доступа к ней остальных процессов, в некоторых случаях оказывается полезным организовать контролируемый совместный доступ нескольких процессов к определенной области памяти. Например, в том случае, когда несколько пользователей одновременно работают с некоторым текстовым редактором, нецелесообразно многократно загружать его код в оперативную память. Гораздо экономичней загрузить всего одну копию кода, которая обслуживала бы всех пользователей, работающих в данное время с этим редактором (для этого код редактора должен быть реентерабельным). Очевидно, что сегмент данных редактора не может присутствовать в памяти в единственном разделяемом экземпляре – для каждого пользователя должна быть создана своя копия этого сегмента, в которой помещаются редактируемый текст и значения других переменных редактора, например, его конфигурация, индивидуальная для каждого пользователя, и т.п.
Для организации разделяемого сегмента при наличии подсистемы виртуальной памяти достаточно поместить его в виртуальное адресное пространство каждого процесса, которому нужен доступ к данному сегменту, а затем настроить параметры отображения этих виртуальных сегментов так, чтобы они соответствовали одной и той же области оперативной памяти. Детали такой настройки зависят от типа используемой в ОС модели виртуальной памяти: сегментной или сегментно-страничной (чисто страничная организация не поддерживает понятие «сегмент», что делает невозможным решение рассматриваемой задачи). Например, при сегментной организации необходимо в дескрипторах виртуального сегмента каждого процесса указать один и тот же базовый физический адрес. При сегментно-страничной организации отображение на одну и ту же область памяти достигается за счет соответствующей настройки таблицы страниц каждого процесса.
В приведенном выше описании подразумевалось, что разделяемый сегмент помещается в индивидуальную часть виртуального адресного пространства каждого процесса (рис. 4.6, а) и описывается в каждом процессе индивидуальным дескриптором сегмента (и индивидуальными дескрипторами страниц, если используется сегментно-страничный механизм).
«Попадание» же этих виртуальных сегментов на общую часть оперативной памяти достигается за счет согласованной настройки операционной системой многочисленных дескрипторов для множества процессов.
Возможно и более экономичное для ОС решение этой задачи – помещение единственного разделяемого виртуального сегмента в общую часть виртуального адресного пространства процессов, т.е. в ту часть, которая обычно используется для модулей ОС (рис. 4.6, б). В этом случае настройка дескриптора сегмента (и дескрипторов страниц) выполняется только один раз, а все процессы пользуются такой настройкой и совместно используют часть оперативной памяти.
При работе с разделяемыми сегментами памяти ОС должна выполнять некоторые функции, общие для любых разделяемых между процессами ресурсов – файлов и т.п. Эти функции состоят в поддержке схемы именования ресурсов, проверке прав доступа определенного процесса к ресурсу, а также в отслеживании количества процессов, пользующихся данным ресурсом (чтобы удалить его в случае ненадобности). Для того чтобы отличать разделяемые сегменты памяти от индивидуальных, дескриптор сегмента должен содержать поле, имеющее два значения: shared (разделяемый) или private (индивидуальный).




 ОП
ОП


 ВП2
ВП2

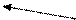






 ВП1
ВП1

а
ОП



 ВП2
ВП2

 ВП1 ВПn
ВП1 ВПn




 | |||
 |
б
Рис. 4.6. Два способа создания разделяемого сегмента памяти
Операционная система может создавать разделяемые сегменты как по явному запросу, так и по умолчанию. В первом случае прикладной процесс должен выполнить соответствующий системный вызов, по которому операционная система создаст новый сегмент в соответствии с указанными в вызове параметрами: размером сегмента, разрешенными над ним операциями (чтение/запись) и идентификатором. Все процессы, выполнившие подобные вызовы с одним и тем же идентификатором, получают доступ к этому сегменту и используют его по своему усмотрению, например в качестве буфера для обмена данными. Во втором случае операционная система сама в определенных ситуациях принимает решение о том, что нужно создать разделяемый сегмент.
Наиболее типичным примером такого рода является поступление нескольких запросов на выполнение одного и того же приложения. Если кодовый сегмент приложения помечен в исполняемом файле как реентерабельный и разделяемый, то ОС не создает при поступлении нового запроса новую индивидуальную для процесса копию кодового сегмента этого приложения, а отображает уже существующий разделяемый сегмент в виртуальное адресное пространство процесса. При закрытии приложения каким-либо процессом ОС проверяет, существуют ли другие процессы, пользующиеся данным приложением, и если их нет, то удаляет данный разделяемый сегмент.
Разделяемые сегменты выгружаются на диск системой управления виртуальной памятью по тем же алгоритмам и с помощью тех же механизмов, что и индивидуальные.
Вопросы для самопроверки
110. На какие классы принято разделять алгоритмы распределения памяти?
111. Какие подходы используются для виртуализации памяти в современных ОС?
112. Как называют область жесткого диска, которая отводится ОС для временного хранения страниц или сегментов виртуальной памяти?
113. Возможна ли организация разделяемой памяти при страничном распределении ОП?
Контрольные вопросы
114. Возможна ли ситуация, когда при динамическом способе распределения памяти ОС не принимает процесс на выполнение?
115. Что такое фрагментация ОП?
116. В чем суть процедуры сжатия ОП?
117. Назовите основной недостаток свопинга.
118. Назовите классы структуризации виртуальной памяти.
119. Чем отличается страничное распределение памяти от свопинга?
120. Какая информация содержится в дескрипторе страницы?
121. В какой информационной структуре хранятся адреса таблицы страниц?
122. Какой критерий используется ОС для определения выгружаемой из ОП страницы?
123. Почему в современных ОС предпочтительно сегментное распределение памяти, а не страничное?
124. Какая характеристика ПК определяет максимально возможный размер виртуального адресного пространства?
125. Если несколько процессов используют один и тот же сегмент памяти (общий), то как поступает ОС в этом случае?
126. Укажите основные недостатки сегментного распределения ОП.
127. В чем отличие сегментного распределения ОП от страничного?
128. Для каких целей ОС использует разделяемые сегменты памяти?
ВВОД-ВЫВОД И ФАЙЛОВАЯ СИСТЕМА
Одной из главных задач операционной системы является обеспечение обмена данными между приложениями и периферийными устройствами компьютера. В… Основными компонентами подсистемы ввода-вывода являются драйверы, управляющие…Специальные файлы
В унификацию драйверов большой вклад внесла операционная система UNIX. В этой системе все драйверы были разделены на два больших класса:… Устройства, с которыми работают байт-ориентированные драйверы, неадресуемы и… Блок- или байт-ориентированность является характеристикой как самого устройства, так и его драйвера. Очевидно, что…Логическая организация файловой системы
Одной из основных задач операционной системы является предоставление удобств пользователю при работе с данными, хранящимися на дисках. Для этого ОС…Цели и задачи файловой системы
Файл - это именованная область внешней памяти, в которую можно записывать и из которой можно считывать данные. Файлы хранятся в памяти, не зависящей… Файловая система (ФС) – это часть операционной системы, включающая: совокупность всех файлов на диске;Типы файлов
Файловые системы поддерживают несколько функционально различных типов файлов, в число которых, как правило, входят обычные файлы, файлы-каталоги,… Обычные файлы, или просто файлы, содержат информацию произвольного характера,… Каталог - это особый тип файлов, который содержит системную справочную информацию о наборе файлов, сгруппированных…Иерархическая структура файловой системы
Пользователи обращаются к файлам по символьным именам. Однако способности человеческой памяти ограничивают количество имен объектов, к которым… Корневой каталогРис. 5.1. Иерархия файловых систем
Граф, описывающий иерархию каталогов, может быть деревом или сетью. Каталоги образуют дерево, если файлу разрешено входить только в один каталог (рис. 5.1, б), и сеть - если файл может входить сразу в несколько каталогов (рис. 5.1, в). Например, в MS-DOS и Windows каталоги образуют древовидную структуру, а в UNIX - сетевую. В древовидной структуре каждый файл является листом. Каталог самого верхнего уровня называется корневым каталогом или корнем (root).
Частным случаем иерархической структуры является одноуровневая организация, когда все файлы входят в один каталог (рис. 5.1, а).
Имена файлов
Все типы файлов имеют символьные имена. В иерархически организованных файловых системах обычно используются три типа имен файлов: простые, составные… Простое, или короткое, символьное имя идентифицирует файл в пределах одного… В иерархических файловых системах разным файлам разрешено иметь одинаковые простые символьные имена при условии, что…Монтирование
Первое решение состоит в том, что на каждом из устройств размещается автономная файловая система, т.е. файлы, находящиеся на этом устройстве,… Другим вариантом является такая организация хранения файлов, при которой… Среди всех имеющихся в системе логических дисковых устройств операционная система выделяет одно устройство, называемое…Рис. 5.3. Общая файловая система после монтирования
После монтирования общей файловой системы для пользователя нет логической разницы между корневой и смонтированной файловыми системами. В частности, именование файлов производится так же, как если бы она с самого начала была единой.
Атрибуты файлов
Понятие «файл» включает не только хранимые им данные и имя, но и атрибуты. Атрибуты - это информация, описывающая свойства файла. Примеры возможных атрибутов файла: тип файла (обычный файл, каталог, специальный файл и т.п.);Логическая организация файла
В общем случае данные, содержащиеся в файле, имеют некую логическую структуру. Она является базой при разработке программы, предназначенной для… В первом случае, когда все действия, связанные со структуризацией и… Модель файла, в соответствии с которой содержимое файла представляется неструктурированной последовательностью…Контрольные вопросы
136. Назовите устройство, драйвер которого нельзя отнести ни к байт-ориентированным, ни к блок-ориентированным.
137. Для каких целей ОС UNIX использует специальные файлы?
138. В каком виде в современных ОС представлена логическая структура данных?
139. Что такое файл?
140. Дайте определение файловой системы.
141. В чем суть иерархической структуры файловой системы?
142. Может ли структура каталогов представлять из себя сеть?
143. Укажите три основных типа имен файлов.
144. Для каких целей служит простое имя файла?
145. Какие ограничения на длину файла Вам известны?
146. Для каких целей в ОС UNIX служит операция монтирования?
147. Что такое атрибут файла?
148. Что представляет собой файл в современных ОС?
Физическая организация файловой системы
Представление пользователя о файловой системе как об иерархически организованном множестве информационных объектов имеет мало общего с порядком…Диски, разделы, секторы, кластеры
Основным устройством, которое используется в современных вычислительных системах для хранения файлов, являются дисковые накопители. Они предназначены для считывания и записи данных на жесткие и гибкие магнитные диски.
Жесткий диск состоит из одной или нескольких стеклянных или металлических пластин, каждая из которых покрыта с одной или двух сторон магнитным материалом. Таким образом, диск в общем случае состоит из пакета пластин.
На каждой стороне каждой пластины размечены тонкие концентрические кольца - дорожки (traks), на которых хранятся данные. Количество дорожек зависит от типа диска. Нумерация дорожек начинается с 0 от внешнего края к центру диска. Когда диск вращается, элемент, называемый головкой, считывает двоичные данные с магнитной дорожки или записывает их на магнитную дорожку.
Головка может позиционироваться над заданной дорожкой. Головки перемещаются над поверхностью диска дискретными шагами, каждый шаг соответствует сдвигу на одну дорожку. Запись на диск осуществляется благодаря способности головки изменять магнитные свойства дорожки. Обычно все головки закреплены на едином перемещающем механизме и двигаются синхронно. Когда головка фиксируется на заданной дорожке одной поверхности, все остальные головки останавливаются над дорожками с такими же номерами. Совокупность дорожек одного радиуса на всех поверхностях всех пластин пакета называется цилиндром (cylinder). Каждая дорожка разбивается на фрагменты, называемые секторами (sectors) или блоками (blocks), так что все дорожки имеют равное число секторов, в которые можно максимально записать одно и то же число байтов. Сектор имеет фиксированный для конкретной системы размер, выражающийся степенью двойки. Чаще всего размер сектора составляет 512 байтов.
Поскольку дорожки разного радиуса имеют одинаковое число секторов, плотность записи становится тем выше, чем ближе дорожка к центру.
Сектор - наименьшая адресуемая единица обмена данными дискового устройства с оперативной памятью. Для того чтобы контроллер мог найти на диске нужный сектор, необходимо задать ему все составляющие адреса сектора: номер цилиндра, номер поверхности и номер сектора. Так как прикладной программе в общем случае нужен не сектор, а некоторое количество байтов, не обязательно кратное размеру сектора, то типичный запрос включает чтение нескольких секторов, содержащих требуемую информацию, и одного или двух секторов, содержащих наряду с требуемыми избыточные данные.
Операционная система при работе с диском использует, как правило, собственную единицу дискового пространства, называемую кластером (cluster). При создании файла место на диске ему выделяется кластерами. Например, если файл имеет размер 2560 байт, а размер кластера в файловой системе определен в 1024 байта, то файлу будет выделено на диске 3 кластера. Иногда кластер называют блоком (например, в ОС UNIX), что может привести к терминологической путанице. Вообще, терминология, используемая при описании форматов дисков и файловых систем, зависит от аппаратной платформы операционной системы.
Дорожки и секторы создаются в результате выполнения процедуры физического (низкоуровневого) форматирования диска, предшествующей использованию диска. Для определения границ блоков на диск записывается идентификационная информация. Низкоуровневый формат диска не зависит от типа операционной системы, которая этот диск будет исполь-зовать.
Разметку диска под конкретный тип файловой системы выполняют процедуры высокоуровневого (логического) форматирования. При высокоуровневом форматировании определяется размер кластера и на диск записывается информация, необходимая для работы файловой системы, в том числе информация о доступном и неиспользуемом пространстве, о границах областей, отведенных под файлы и каталоги, информация о поврежденных областях. Кроме того, на диск записывается загрузчик операционной системы - небольшая программа, которая начинает процесс инициализации операционной системы после включения питания или рестарта компьютера.
Прежде чем форматировать диск под определенную файловую систему, его необходимо разбить на разделы. Раздел (partition) - это непрерывная часть физического диска, которую операционная система представляет пользователю как логическое устройство (используются также названия логический диск и логический раздел). Логическое устройство функционирует так, как если бы это был отдельный физический диск. Именно с логическими устройствами работает пользователь, обращаясь к ним по символьным именам, используя, например, обозначения А, В, С, SYS и т.п. Операционные системы разного типа используют единое для всех них представление о разделах, но создают на его основе логические устройства, специфические для каждого типа ОС. Так же, как файловая система, с которой работает одна ОС, в общем случае не может интерпретироваться ОС другого типа, логические устройства не могут быть использованы операционными системами разного типа. На каждом логическом устройстве может создаваться только одна файловая система.
В частном случае, когда все дисковое пространство охватывается одним разделом, логическое устройство представляет собой физическое устройство в целом. Если диск разбит на несколько разделов, то для каждого из этих разделов может быть создано отдельное логическое устройство. Логическое устройство может быть создано и на базе нескольких разделов, причем эти разделы не обязательно должны принадлежать одному физическому устройству. Объединение нескольких разделов в единое логическое устройство может выполняться разными способами и преследовать разные цели, основные из которых: увеличение общего объема логического раздела, повышение производительности и отказоустойчивости. Примерами организации совместной работы нескольких дисковых разделов являются тома в ОС Novell NetWare или так называемые RAID-массивы.
На разных логических устройствах одного и того же физического диска могут располагаться файловые системы разного типа. Все разделы одного диска имеют одинаковый размер блока, определенный для данного диска в результате низкоуровневого форматирования. Однако в результате высокоуровневого форматирования в разных разделах одного и того же диска, представленных разными логическими устройствами, могут быть установлены файловые системы, в которых определены кластеры отличающихся размеров.
Операционная система может поддерживать разные статусы разделов, особым образом отмечая разделы, которые могут быть использованы для загрузки модулей операционной системы, и разделы, в которых можно устанавливать только приложения и хранить файлы данных. Один из разделов диска помечается как загружаемый (или активный). Именно из этого раздела считывается загрузчик операционной системы.
Физическая организация и адресация файла
Важным компонентом физической организации файловой системы является физическая организация файла, т.е. способ размещения файла на диске. Основными критериями эффективности физической организации файлов являются: скорость доступа к данным;Рис. 5.5. Схема адресации файловой системы ufs
Файловая система ufs поддерживает дисковые кластеры и меньших размеров, при этом максимальный размер файла будет другим. Используемая в более ранних версиях UNIX файловая система s5 имеет аналогичную схему адресации, но она рассчитана на файлы меньших размеров, поэтому в ней используется 13 адресных элементов вместо 15.
Метод перечисления адресов кластеров файла задействован и в файловой системе NTFS, используемой в ОС Windows NT/2000. Здесь он дополнен достаточно естественным приемом, сокращающим объем адресной информации: адресуются не кластеры файла, а непрерывные области, состоящие из смежных кластеров диска. Каждая такая область, называемая отрезком (run) или экстентом (extent), описывается с помощью двух чисел: начального номера кластера и количества кластеров в отрезке. Так как для сокращения времени операции обмена ОС старается разместить файл в последовательных кластерах диска, то в большинстве случаев количество последовательных областей файла будет меньше количества кластеров файла. Таким образом, объем служебной адресной информации в NTFS сокращается по сравнению со схемой адресации файловых систем ufs/s5.
Для того чтобы корректно принимать решение о выделении файлу набора кластеров, файловая система должна отслеживать информацию о состоянии всех кластеров диска: свободен/занят. Эта информация может храниться как отдельно от адресной информации файлов, так и вмес-
те с ней.
Физическая организация FAT
Логический раздел, отформатированный под файловую систему FAT, состоит из следующих областей. Загрузочный сектор содержит программу начальной загрузки операционной системы.… Основная копия FAT содержит информацию о размещении файлов и каталогов на диске.Физическая организация файловых систем s5 и ufs
В этом разделе вместо термина «кластер» будет использоваться термин «блок», как это принято в файловых системах UNIX. Файловые системы s5 (получившие название от System V, родового имени… Расположение файловой системы s5 на диске иллюстрирует рис. 5.7.Рис. 5.7. Расположение файловой системы s5 на диске
Основной особенностью физической организации файловой системы s5 является отделение имени файла от его характеристик, хранящихся в отдельной структуре, называемой индексным дескриптором (inode).
Индексный дескриптор в s5 имеет размер 64 байта и содержит данные о типе файла, адресную информацию, привилегии доступа к файлу и некоторую другую информацию:
идентификатор владельца файла;
тип файла – файл обычного типа, каталог, специальный файл, а также конвейер или символьная связь;
права доступа к файлу;
временные характеристики: время – последней модификации файла, время последнего обращения к файлу, время последней модификации индексного дескриптора;
число ссылок на данный индексный дескриптор, равное количеству псевдонимов файла;
адресная информация (структура адреса рассмотрена выше в разделе «Физическая организация и адресация файла»);
размер файла в байтах.
Каждый индексный дескриптор имеет номер, который одновременно является уникальным именем файла. Индексные дескрипторы расположены в особой области диска в строгом соответствии со своими номерами. Соответствие между полными символьными именами файлов и их уникальными именами устанавливается с помощью иерархии каталогов. Система ведет список номеров свободных индексных дескрипторов. При создании файла ему выделяется номер из этого списка, а при уничтожении файла номер его индексного дескриптора возвращается в список.
Запись о файле в каталоге состоит всего из двух полей: символьного имени файла и номера индексного дескриптора. Например, на рис. 5.8 показана информация, содержащаяся в каталоге /user.
Файловая система не накладывает особых ограничений на размер корневого каталога, так как он расположен в области данных и может увеличиваться как обычный файл.
| Имя | № индексного дескриптора |
| Progl | |
| firelights | |
| doc_23.txt | |
| glazing.txt | |
| lambda_good |
Рис. 5.8. Структура каталога в файловой системе s5
Доступ к файлу осуществляется путем последовательного просмотра всей цепочки каталогов, входящих в полное имя файла, и соответствующих им индексных дескрипторов. Поиск завершается после получения всех характеристик из индексного дескриптора заданного файла.
Рассмотрим эту процедуру на примере файла /home/stud2/labrab.doc, входящего в состав файловой системы, изображенной на рис. 5.9.
Корневой каталог /
 |

 /home /bin /sys
/home /bin /sys

 /stud1
/stud1
 |
/stud2

 /doc
/doc

 /studn
/studn
 labrab.doc
labrab.doc
otchet.doc
Корневой каталог Каталог /home Каталог /home/stud2
| . |  2 2
|
| .. | |
| home | |
| bin | |
| sys |
| . | |
| .. | |
| stud1 | |
| stud2 | |
| : : | : : |
| studn |
| . | |
| .. | |
| doc | |
| labrab.doc | |
| otchet.doc |

Рис. 5.9. Поиск адреса файла по его символьному имени
. – текущий каталог; .. – родительский каталог
Определение физического адреса этого файла включает следующие этапы.
1. Прежде всего просматривается корневой каталог с целью поиска первой составляющей символьного имени - home. Определяется номер
(в данном примере - 11) индексного дескриптора каталога, входящего в корневой каталог. Адрес корневого каталога известен системе.
2. Из области индексных дескрипторов считывается дескриптор с номером 11. Начальный адрес дескриптора определяется на основании известных системе номера начального сектора области индексных дескрипторов и размера индексного дескриптора. Из индексного дескриптора 11 определяется физический адрес каталога /home.
3. Просматривается каталог /home с целью поиска второй составляющей символьного имени stud2. Определяется номер индексного дескриптора каталога /home/stud2 (в данном случае - 36).
4. Считывается индексный дескриптор 36, определяется физический адрес /home/stud2.
5. Просматривается каталог /home/stud2, определяется номер индексного дескриптора файла labrab.doc (в данном случае - 131).
6. Из индексного дескриптора 131 определяются номера блоков данных, а также другие характеристики файла /home/stud2/labrab.doc.
Эта процедура требует в общем случае нескольких обращений к дис-ку – пропорционально числу составляющих в полном имени файла. Для уменьшения среднего времени доступа к файлу его дескриптор копируется в специальную системную область оперативной памяти. Копирование индексного дескриптора входит в процедуру открытия файла.
Физическая организация файловой системы ufs отличается от описанной физической организации файловой системы s5 тем, что раздел состоит из повторяющейся несколько раз последовательности областей «загруз-
чик - суперблок - блок группы цилиндров - область индексных дескрипторов» (рис. 5.10).
| Загрузочный блок |
| Суперблок |
| Блок группы цилиндров |
| Список inode |
| Блоки данных |
| Суперблок |
| Блок группы цилиндров |
| Список inode |
| Блоки данных |
Рис. 5.10. Физическая организация файловой системы ufs
В этих повторяющихся последовательностях областей суперблок является резервной копией основной первой копии суперблока. При повреждении основной копии суперблока может быть использована резервная копия суперблока. Области же блока группы цилиндров и индексных дескрипторов содержат индивидуальные для каждой последовательности значения. Блок группы цилиндров описывает количество индексных дескрипторов и блоков данных, расположенных на данной группе цилиндров диска. Такая группировка делается для ускорения доступа, чтобы просмотр индексных дескрипторов и данных файлов, описываемых этими дескрипторами, не приводил к слишком большим перемещениям головок диска.
Кроме того, в ufs имена файлов могут иметь длину до 255 символов (кодировка ASCII, по одному байту на символ), в то время как в s5 длина имени не может превышать 14 символов.
Физическая организация файловой системы NTFS
Файловая система NTFS была разработана в качестве основной файловой системы для ОС Windows NT в начале 1990-х годов с учетом опыта разработки… Основными отличительными свойствами NTFS являются: поддержка больших файлов и больших дисков объемом до 264 байт;Структура тома NTFS
В отличие от разделов FAT и s5/ufs все пространство тома NTFS представляет собой либо файл, либо часть файла. Основой структуры тома NTFS является… Все файлы на томе NTFS идентифицируются номером файла, который определяется… Загрузочный блок : : …Структура файлов NTFS
Адресная информация об отрезках, содержащих нерезидентные части файла, размещается в атрибутах резидентной части. Некоторые системные файлы являются полностью резидентными, а некоторые имеют и… Каждый файл и каталог на томе NTFS состоит из набора атрибутов. Важно отметить, что имя файла и его данные также…Рис. 5.12. Небольшой файл NTFS
Большие файлы (large). Если данные файла не помещаются в одну запись MFT, то этот факт отражается в заголовке атрибута Data, который содержит признак того, что этот атрибут является нерезидентным, т.е. находится в отрезках вне таблицы MFT. В этом случае атрибут Data содержит адресную информацию (VCN, LCN, k) каждого отрезка данных (рис. 5.13).
| SI | FN | Data
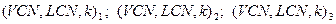
| SD |
  
| |||
| Отрезок данных 1 | |||
| Отрезок данных 2 | |||
| Отрезок данных 3 | |||
 Запись
Запись
MFT
Рис. 5.13. Большой файл NTFS
Каталоги NTFS
Каждый каталог NTFS представляет собой один вход в таблицу MFT, который содержит атрибут Index Root – список файлов, входящих в каталог. Индексы… Небольшие каталоги (small indexes). Если количество файлов в каталоге… SI FN IR <a.bat, 27>…Рис. 5.14. Небольшой каталог
Для резидентного хранения списка используется единственный атрибут - Index Root. Список файлов содержит значения атрибутов файла. По умолчанию – это имя файла, а также номер записи MTF, содержащей начальную запись файла.
Большие каталоги (large indexes). По мере того как каталог растет, список файлов может потребовать нерезидентной формы хранения. Однако начальная часть списка всегда остается резидентной в корневой записи каталога в таблице MFT (рис. 5.15). Имена файлов резидентной части списка файлов являются узлами так называемого В-дерева (двоичного дерева). Остальные части списка файлов размещаются вне MFT. Для их поиска используется специальный атрибут Index Allocation, представляющий собой адреса отрезков, хранящих остальные части списка файлов каталога. Одни части списков являются листьями дерева, а другие являются промежуточными узлами, т.е. содержат наряду с именами файлов атрибут Index Allocation, указывающий на списки файлов более низких уровней.
Узлы двоичного дерева делят весь список файлов на несколько групп. Имя каждого файла-узла является именем последнего файла в соответствующей группе. Считается, что имена файлов сравниваются лексикографически, т.е. сначала принимаются во внимание коды первых символов двух сравниваемых имен. При этом имя считается меньшим, если код его первого символа имеет меньшее арифметическое значение. При равенстве кодов первых символов сравниваются коды вторых символов имен и т.д. Например, файл f1.exe, являющийся первым узлом двоичного дерева (поле IR), показанного на рис. 5.15, имеет имя, лексикографически большее имен avia.exe, az.exe, ... , emax.exe, образующих первую группу списка имен каталога. Соответственно файл ltr.exe имеет наибольшее имя среди всех имен второй группы, а все файлы с именами, большими ltr.exe, образуют третью и последнюю группу.
 | |
| SI | FN | IR <f1.exe, Nf1.exe> <ltr.exe, Nltr.exe> <####> | IA
   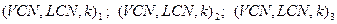
| SD |
| IR <avia.doc, Navia.doc> <az.exe, Naz.exe> … <emax.exe, Nemax.exe> <####> | ||||
| IR <gl.htm, Ngl.htm> <green.com, Ngreen.com> … <caw.doc, Ncaw.doc> <####> | ||||
| IR<main1.c, Nmain1.c> … <zero.txt, Nzero.txt> <####> |
Рис. 5.15. Большой каталог
Поиск в каталоге уникального имени файла, которым в NTFS является номер основной записи о файле в MFT, по его символьному имени происходит следующим образом. Сначала искомое символьное имя сравнивается с именем первого узла в резидентной части индекса. Если искомое имя меньше, то это означает, что его нужно искать в первой нерезидентной группе, для чего из атрибута Index Allocation извлекается адрес отрезка 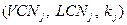 , хранящего имена файлов первой группы. Среди имен этой группы поиск осуществляется прямым перебором и сравнением до полного совпадения всех символов искомого имени с именем, хранящимся в каталоге. При совпадении из каталога извлекается номер основной записи о файле в MFT и остальные характеристики файла берутся уже
, хранящего имена файлов первой группы. Среди имен этой группы поиск осуществляется прямым перебором и сравнением до полного совпадения всех символов искомого имени с именем, хранящимся в каталоге. При совпадении из каталога извлекается номер основной записи о файле в MFT и остальные характеристики файла берутся уже
оттуда.
Если искомое имя больше имени первого узла резидентной части индекса, то его сравнивают с именем второго узла; если искомое имя меньше, то описанная процедура применяется ко второй нерезидентной группе имен, и т.д. В результате вместо перебора большого количества имен (в худшем случае - всех имен каталога) выполняется сравнение с гораздо меньшим количеством имен узлов и имен в одной из групп каталога.
Если одна из групп каталога становится слишком большой, то ее также делят на группы, последние имена каждой новой группы оставляют в исходном нерезидентном атрибуте Index Root, а все остальные имена новых групп переносят в новые нерезидентные атрибуты типа Index Root
(на рис. 5.15 этот случай не показан). К исходному нерезидентному атрибуту Index Root добавляется атрибут размещения индекса, указывающий на отрезки индекса новых групп. Если теперь при поиске искомого имени в нерезидентной части индекса первого уровня какое-либо сравнение показывает, что искомое имя оказывается меньше, чем одно из хранящихся там имен, то это говорит о том, что в данном атрибуте точного сравнения имени уже быть не может и нужно перейти к подгруппе имен следующего уровня дерева.
Вопросы для самопроверки
149. На какие области разбивает файловая система FAT логический раздел диска?
150. Укажите основную информационную составляющую файловой системы NTFS.
151. Что является основной компонентой файла в NTFS?
152. Для каких целей в NTFS используется информация об узлах
B-дерева?
Контрольные вопросы
153. В каких единицах дискового пространства ОС выделяет место под файлы?
154. Что понимают под разделом (partition) жесткого диска?
155. Обязательно ли одно логическое устройство размещается на одном жестком диске?
156. Какому параметру соответствует количество индексных указателей в таблице FAT?
157. Какое максимальное количество кластеров может поддерживать файловая система FAT16?
158. В каком случае в файловой системе FAT16 гарантируется надежное восстановление файла?
159. Как в терминах ОС UNIX принято называть информационную структуру, в которой хранятся характеристики файла?
160. Чем является индексный дескриптор с точки зрения идентификации файла?
161. Может ли файл в ОС UNIX иметь более одного символьного
имени?
162. Какая базовая единица дискового пространства используется для хранения информации в NTFS?
163. Какое количество стандартных записей содержит первый отрезок MFT?
164. Какие поля содержатся в атрибуте файла?
165. На какие типы делят файлы в NTFS в зависимости от способа их размещения?
166. Какая информация содержится в поле Data больших файлов?
167. Какую информацию содержит атрибут Index Root?
168. Какие атрибуты связаны с конкретным файлом в каталожной
записи?
5.8. Контроль доступа к файлам
5.8.1. Доступ к файлам как частный случай доступа
к разделяемым ресурсам
Файлы – это частный, хотя и самый популярный, вид разделяемых ресурсов, доступ к которым операционная система должна контролировать. Существуют и другие виды ресурсов, с которыми пользователи работают в режиме совместного использования. Прежде всего, это различные внешние устройства: принтеры, модемы, графопостроители и т.п. Область памяти, используемая для обмена данными между процессами, также является примером разделяемого ресурса. Да и сами процессы в некоторых случаях выступают в этой роли, например, когда пользователи ОС посылают процессам сигналы, на которые процесс должен реагировать.
Во всех этих случаях действует общая схема: пользователи пытаются выполнить с разделяемым ресурсом определенные операции, а ОС должна решать, имеют ли пользователи на это право. Пользователи являются
субъектами доступа, а разделяемые ресурсы – объектами. Пользователь осуществляет доступ к объектам операционной системы не непосредственно, а с помощью прикладных процессов, которые запускаются от его имени. Для каждого типа объектов существует набор операций, которые с ними можно выполнять. Например, для файлов это операции чтения, записи, удаления, выполнения; для принтера – перезапуск, очистка очереди документов, приостановка печати документа и т.д. Система контроля доступа ОС должна предоставлять средства для задания прав пользователей по отношению к объектам дифференцированно по операциям, например, пользователю может быть разрешена операция чтения и выполнения файла, а операция удаления – запрещена.
Во многих операционных системах реализованы механизмы, которые позволяют управлять доступом к объектам различного типа с единых позиций. Так, представление устройств ввода-вывода в виде специальных файлов в операционных системах UNIX является примером такого подхода:
в этом случае при доступе к устройствам используются те же атрибуты безопасности и алгоритмы, что и при доступе к обычным файлам и каталогам. Еще дальше продвинулась в этом направлении операционная система Windows NT. В ней используется унифицированная структура – объект безопасности. Она создается не только для файлов и внешних устройств, но и для любых разделяемых ресурсов, например секций памяти. Это позволяет использовать в Windows NT для контроля доступа к ресурсам любого вида общий модуль ядра – менеджер безопасности.
В качестве субъектов доступа могут выступать как отдельные пользователи, так и группы пользователей. Определение индивидуальных прав доступа для каждого пользователя позволяет максимально гибко задать политику расходования разделяемых ресурсов в вычислительной системе. Однако этот способ приводит в больших системах к чрезмерной загрузке администратора рутинной работой по повторению одних и тех же операций для пользователей с одинаковыми правами. Объединение таких пользователей в группу и задание прав доступа в целом для группы является одним из основных приемов администрирования в больших системах.
У каждого объекта доступа существует владелец. Владельцем может быть как отдельный пользователь, так и группа пользователей. Владелец объекта имеет право выполнять с ним любые допустимые для данного объекта операции. Во многих операционных системах существует особый пользователь (superuser, root, administrator), который имеет все права по отношению к любым объектам системы, не обязательно являясь их владельцем. Под таким именем работает администратор системы, которому необходим полный доступ ко всем файлам и устройствам для управления политикой доступа.
Различают два основных подхода к определению прав доступа.
Избирательный доступ имеет место, когда для каждого объекта сам владелец может определить допустимые операции с объектами. Этот подход называется также произвольным (от discretionary – предоставленный на собственное усмотрение) доступом, так как позволяет администратору и владельцам объектов определить права доступа произвольным образом, по их желанию. Между пользователями и группами пользователей в системах с избирательным доступом нет жестких иерархических взаимоотношений, т.е. взаимоотношений, которые определены по умолчанию и которые нельзя изменить. Исключение делается только для администратора, по умолчанию наделяемого всеми правами.
Мандатный доступ (от mandatory – обязательный, принудительный) – это такой подход к определению прав доступа, при котором система наделяет пользователя определенными правами по отношению к каждому разделяемому ресурсу (в данном случае файлу) в зависимости от того, к какой группе пользователь отнесен. От имени системы выступает администратор, а владельцы объектов лишены возможности управлять доступом к ним по своему усмотрению. Все группы пользователей в такой системе образуют строгую иерархию, причем каждая группа пользуется всеми правами группы более низкого уровня иерархии, к которым добавляются права данного уровня. Членам какой-либо группы не разрешается предоставлять свои права членам групп более низких уровней иерархии.
Мандатный способ доступа близок к схемам, применяемым для доступа к секретным документам: пользователь может входить в одну из групп, отличающихся правом доступа к документам с соответствующим грифом секретности, например, «для служебного пользования», «секретно», «совершенно секретно» и «государственная тайна». При этом пользователи группы «совершенно секретно» имеют право работать с документами «секретно» и «для служебного пользования», так как эти виды доступа разрешены для более низких в иерархии групп. Однако сами пользователи не распоряжаются правами доступа – этой возможностью наделен только особый чиновник учреждения.
Мандатные системы доступа считаются более надежными, но менее гибкими, обычно они применяются в специализированных вычислительных системах с повышенными требованиями к защите информации.
В универсальных системах используются, как правило, избирательные методы доступа, о которых и будет идти речь ниже.
Для определенности далее будем рассматривать механизмы контроля доступа к таким объектам, как файлы и каталоги, но необходимо понимать, что эти же механизмы могут использоваться в современных операционных системах для контроля доступа к объектам любого типа и отличия заключаются лишь в наборе операций, характерных для того или иного класса объектов.
Механизм контроля доступа
Каждый пользователь и каждая группа пользователей обычно имеют символьное имя, а также уникальный числовой идентификатор. При выполнении процедуры… Вход пользователя в систему порождает процесс-оболочку, который поддерживает… Для файловых объектов этот список может включать следующие операции:Имена файлов
Имена пользователейРис. 5.16. Матрица прав доступа
Обобщенно формат списка управления доступом можно представить в виде набора идентификаторов пользователей и групп пользователей, в котором для каждого идентификатора указывается набор разрешенных операций над объектом (рис. 5.17). Говорят, что список ACL состоит из элементов управления доступом (Access Control Element, АСЕ), при этом каждый элемент соответствует одному идентификатору. Список контроля доступа ACL с добавленным к нему идентификатором владельца объекта называют характеристикой безопасности.
В приведенном на рис. 5.17 примере процесс, который выступает от имени пользователя с идентификатором 3 и групп с идентификаторами 14, 52 и 72, пытается выполнить операцию записи (W) в файл. Файлом владеет пользователь с идентификатором 17. Операционная система, получив запрос на запись, находит характеристики безопасности файла (на диске или в буферной системной области) и последовательно сравнивает все идентификаторы процесса с идентификатором владельца файла и идентификаторами пользователей и групп в элементах АСЕ. В данном примере один из идентификаторов группы, от имени которой выступает процесс, а именно 52, совпадает с идентификатором одного из элементов АСЕ. Так как пользователю с идентификатором 52 разрешена операция чтения (признак W имеется в наборе операций этого элемента), то ОС разрешает процессу выполнение операции.

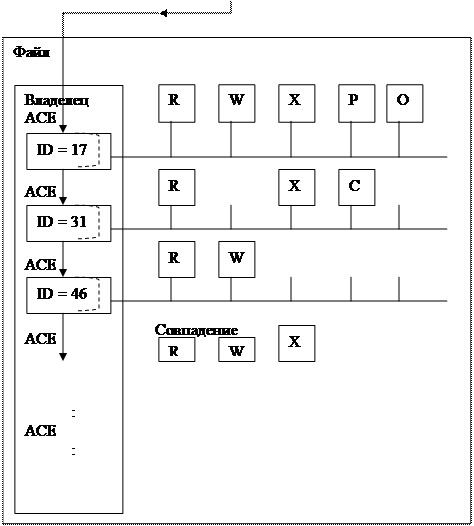
ID = 52
 Рис. 5.18. Проверка прав доступа
Рис. 5.18. Проверка прав доступа
 | ||
 |
Рис. 5.17. Проверка прав доступа
Описанная обобщенная схема хранения информации о правах доступа и процедуры проверки имеют в каждой операционной системе свои особенности, которые рассматриваются далее на примере операционных систем UNIX и Windows NT.
Организация контроля доступа в ОС UNIX
В ОС UNIX права доступа к файлу или каталогу определяются для трех субъектов: владельца файла (идентификатор User ID, UID); членов группы, к которой принадлежит владелец (Group ID, GID);Запрос операции
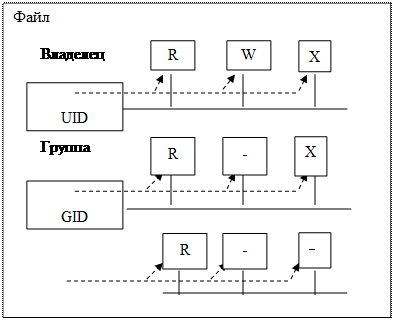 |
Рис. 5.18. Проверка прав доступа в UNIX
Механизм эффективных идентификаторов позволяет пользователю получать некоторые виды доступа, которые ему явно не разрешены, но могут быть получены с помощью вполне ограниченного набора приложений, хранящихся в файлах с установленными признаками смены идентификаторов.
Использование модели файла как универсальной модели разделяемого ресурса позволяет в UNIX применять одни и те же механизмы для контроля доступа к файлам, каталогам, принтерам, терминалам и разделяемым сегментам памяти.
Система управления доступом ОС UNIX была разработана в 1970-е годы и с тех пор мало изменилась. Эта достаточно простая система позволяет во многих случаях решить поставленные перед администратором задачи по предотвращению несанкционированного доступа, однако вследствие своей простоты она иногда требует слишком больших ухищрений или же вовсе не может быть реализована.
Вопросы для самопроверки
169. Файлы и принтеры – это единственный разделяемый ресурс, доступ к которому контролируется операционной системой?
170. Каким образом пользователи осуществляют доступ к разде-ляемым ресурсам?
171. Одинаковы ли допустимые наборы операций для различных разделяемых ресурсов?
172. Какие основные подходы к определению прав доступа Вам известны?
173. В чем отличие реальных и эффективных идентификаторов пользователей и групп пользователей, используемых в ОС UNIX?
Контрольные вопросы
174. Является ли владелец разделяемого ресурса единственным
субъектом, который может выполнять с объектом любые допустимые операции?
175. Существует ли система жестких иерархических отношений при избирательном методе доступа?
176. Существует ли система жестких иерархических отношений при мандатном методе доступа?
177. Какие операции с файлами и каталогами определены в ОС Unix?
178. Какое количество уровней работы с операциями над файлами реализовано в Windows NT?
179. Как именуют список прав доступа, связанный с файлами и каталогами, разрешающий или запрещающий пользователям и группам пользователей выполнять операции с данными объектами?
180. Укажите файловую систему, поддерживаемую ОС Windows NT, в которой список управления доступом не используется.
181. Для каких трех субъектов в ОС UNIX определяются права доступа к файлу?
182. Какое число признаков включает характеристика безопасности файлов в ОС UNIX?
183. Может ли модель файла, как универсальная модель разделяемого ресурса в ОС UNIX, применяться для контроля доступа к другим ресурсам, например терминалам, принтерам, разделяемым сегментам памяти?
Организация контроля доступа в ОС Windows NT
Система управления доступом в ОС Windows NT отличается высокой степенью гибкости, которая достигается за счет большого разнообразия субъектов и… Для разделяемых ресурсов в Windows NT применяется общая модель некоторого… Все объекты хранятся в древовидных иерархических структурах, элементами которых являются объекты-ветви (каталоги) и…Разрешения на доступ к каталогам и файлам
В Windows NT администратор может управлять доступом пользователей к каталогам и файлам только в разделах диска, в которых установлена файловая… Разрешения в Windows NT бывают индивидуальные и стандартные. Индивидуальные… В табл. 5.2 показано шесть индивидуальных разрешений (элементарных операций), смысл которых различается для каталогов…Соотношение индивидуальных и стандартных разрешений для файлов
Таблица 5.3
| Стандартное разрешение | Индивидуальные разрешения |
| No Access | Ни одного |
| Read | RX |
| Change | RWXD |
| Full Control | Все |
Для каталогов в Windows NT определено семь стандартных разрешений: No Access, List, Read, Add, Add & Read, Change и Full Control. В табл. 5.4 показано соответствие стандартных разрешений индивидуальным разрешениям для каталогов, а также то, каким образом эти стандартные разрешения преобразуются в индивидуальные разрешения для файлов, входящих в каталог, в том случае, если файлы наследуют разрешения каталога.
Соотношение стандартных и индивидуальных
разрешений для каталогов
Таблица 5.4
| Стандартные разрешения | Индивидуальные разрешения для каталога | Индивидуальные разрешения для файлов каталога при наследовании |
| No Access | Ни одного | Ни одного |
| List | RX | Не определены |
| Read | RX | RX |
| Add | WX | Не определены |
| Add & Read | RWX | RX |
| Change | RWXD | RWXD |
| Full Control | Все | Все |
При создании файла он наследует разрешения каталога указанным способом только в том случае, если у каталога установлен признак наследования его разрешений. Стандартная оболочка Windows NT – Windows Explorer – не позволяет установить такой признак для каждого разрешения отдельно (то есть задать маску наследования), управляя наследованием по принципу «все или ничего». Существует ряд правил, которые определяют действие разрешений.
Пользователи не могут работать с каталогом или файлом, если они не имеют явного разрешения на это или не относятся к группе, которая имеет соответствующее разрешение.
Разрешения имеют накопительный эффект, за исключением разрешения No Access, которое отменяет все остальные имеющиеся разрешения. Например, если группа Engineering имеет разрешение Change для какого-то файла, а группа Finance имеет для этого файла только разрешение Read и Петров является членом обеих групп, то у Петрова будет разрешение Change. Однако если разрешение для группы Finance изменится на No Access, то Петров не сможет использовать этот файл, несмотря на то, что он член группы, которая имеет доступ к файлу.
По умолчанию в окнах Windows Explorer находят свое отражение стандартные права, а переход к отражению индивидуальных прав происходит только при выполнении некоторых действий. Это стимулирует администратора и пользователей к использованию тех наборов прав, которые разработчики ОС посчитали наиболее удобными.
Вопросы для самопроверки
184. Какие характеристики безопасности используются в общей модели объекта, применяемого для разделяемых ресурсов в ОС Windows NT?
185. Какие схемы хранения объектов используются в ОС Windows NT?
186. Какой метод доступа (централизованный или распределенный) применяется в Windows NT?
187. Какие классы операций доступа поддерживаются в Windows NT?
188. Какие правила в Windows NT используются для назначения списка ACL вновь создаваемому объекту?
189. По каким правилам в ОС Windows NT определяются действия разрешений?
Контрольные вопросы
190. Как именуется программа, используемая в ОС Windows NT для проверки прав доступа к объектам?
191. В чем смысл встроенных пользователей и групп в ОС
Windows NT?
192. Может ли администратор Windows NT создавать пользователей и группы и самостоятельно назначать им права?
193. Наследуются ли права группы ее членами?
194. Что понимается под словосочетанием «токен доступа» (access token)?
195. Какие объекты в Windows NT снабжаются дескрипторами
безопасности?
196. Может ли менять ACL объекта пользователь, который его создал?
197. Если администратор Windows NT стал владельцем некоторого объекта, принадлежащего другому пользователю, а затем захотел вернуть владение объектом прежнему хозяину, то может ли он это сделать?
198. В чем отличие элементов ACL Windows NT от ОС UNIX?
199. Допустимо ли в Windows NT управлять доступом к файлам и каталогам для ФС типа FAT?
200. Какие типы разрешений определены в Windows NT?
201. Перечислите стандартные разрешения ОС Windows NT, применяемые для файлов.
202. Перечислите стандартные разрешения ОС Windows NT, применяемые для каталогов.
ОТВЕТЫ НА ВОПРОСЫ ДЛЯ САМОПРОВЕРКИ
1. Заменяет реальные машинные команды командами высокого уровня.
2. Создание и уничтожение процессов, распределение процессорного времени, обеспечение процессов ресурсами, синхронизация и межпроцессное взаимодействие.
3. Использование объемов памяти больших размеров, превышающих размер наличной физической памяти.
4. Преобразует символьные имена файлов в физические адреса данных на диске, организует совместный доступ к данным, защищает данные от несанкционированного доступа.
5. Логический вход в систему, назначение прав доступа к файлам и принтерам, ограничение на выполнение системных действий, аудит со-бытий.
24. Экранирует от пользователя все низкоуровневые аппаратные интерфейсы.
25. Сетевая надстройка к операционной системе.
26. Интерфейс между потребителем и поставщиком услуг (службой).
27. Да.
35. Структурная организация ОС на основе различных программных модулей.
36. Аппаратура, ядро, утилиты и приложения.
37. Согласовать прикладной программный интерфейс с функциями операционной системы.
38. Большая часть кода пишется на языке, трансляторы которого имеются на всех машинах, аппаратно зависимый код изолируется в нескольких модулях.
50. В привилегированном режиме остается небольшая часть ОС, соответствующая базовым механизмам, работа которых в пользовательском режиме невозможна.
51. Микроядро использует механизмы, аналогичные взаимодействию клиента и сервера путем обмена сообщениями.
52. Возможность ОС выполнять приложения, написанные для дру-гих ОС.
53. Библиотечные функции одной ОС подготавливаются в среде другой ОС. За счет выполнения этих функций на родном процессоре скорость работы приложения существенно повышается.
64. Количество задач, выполняемых системой в единицу времени; интерактивная работа пользователя; способность системы выдерживать заранее заданные интервалы времени между запуском задачи и получением результатов.
65. Нет.
66. Квант времени, выдаваемый системой каждому процессу.
67. Выдерживание заданного интервала времени между запуском задачи и получением результата.
74. В мультипрограммной среде в каждый момент времени выполняется только одна задача, а в мультипроцессорной – несколько, но каждая на своем процессоре.
75. Нет.
76. Нет.
81. Обеспечение процессов необходимыми ресурсами, синхронизация потоков, «зачистка» завершившихся процессов.
82. Нет.
83. Определяет момент времени смены активного потока, выбирает на выполнение готовый поток.
84. При значительном увеличении кванта времени, когда любая задача может быть решена за один квант.
85. Потоки реального времени, потоки с переменным приоритетом.
101. Символьные адреса – присваивает пользователь при написании программы.
Виртуальные адреса (математические или логические адреса) –вырабатывает транслятор, переводящий программу на машинный язык.
Физические адреса – соответствуют номерам ячеек оперативной памяти, где будут расположены переменные и команды.
102. Замена всех виртуальных адресов один раз во время загрузки процесса.
Программа загружается в виртуальных адресах, но во время обращения к ОП они преобразуются в физические адреса ОП.
103. Вытесняемая (paged) и невытесняемая (non-paged).
110. Алгоритмы, основанные на перемещении сегментов процессов между ОП и дисками, и алгоритмы, в которых внешняя память не используется.
111. Свопинг (swapping) – образы процессов перемещаются целиком.
Виртуальная память (virtual memory) – только части образов процессов (сегменты и страницы) перемещаются между ОП и диском.
112. Файл свопинга или страничный файл.
113. Нет, так как в этом случае отсутствует механизм прав доступа к областям ОП.
129. Блок-ориентированные и байт-ориентированные.
130. Да.
131. Логическая модель заменяет физическую структуру хранимых данных на более удобную, представляя ее в виде файла.
132. Обычные файлы, каталоги и специальные файлы.
133. Один файл – одно полное имя.
134. Принципы размещения файлов, каталогов и системной информации на реальном устройстве.
135. Одно.
152. На системную (загрузочная запись, FAT, корневой каталог) и область данных.
153. Главная таблица файлов (MFT).
154. Атрибут. Данные также являются атрибутом файла, как и его имя.
155. Для разбиения упорядоченных имен файлов на группы с целью сокращения поиска нужного файла.
169. Нет. В роли общего ресурса могут выступать различные внешние устройства: принтеры, модемы, графопостроители и т.п. Область памяти, используемая для обмена данными между процессами, также является разделяемым ресурсом. Сами процессы в некоторых случаях выступают в роли разделяемого ресурса, когда пользователи посылают процессам сигналы, на которые процесс должен реагировать.
170. Пользователь осуществляет доступ к разделяемым ресурсам не непосредственно, а с помощью прикладных процессов, запускаемых от его имени или группы, которой принадлежит пользователь.
171. Нет. Для файла – чтение, запись, удаление. Для принтера – перезапуск, очистка очереди, приостановка печати.
172. Избирательный доступ, когда для каждого объекта сам владелец может определить допустимые операции с объектами.
Мандатный доступ (обязательный, принудительный) – это такой подход к определению прав доступа, при котором система наделяет пользователя определенными правами по отношению к каждому разделяемому ресурсу в зависимости от того, к какой группе пользователей он принад-лежит.
173. Реальные идентификаторы субъектов задаются процессу при его порождении, а по эффективным идентификаторам проверяются права доступа процесса к файлу. Эффективные идентификаторы могут заменить реальные, но в исходном состоянии они совпадают с реальными.
184. Набор допустимых операций.
Идентификатор владельца.
Управление доступом.
185. Древовидная иерархическая структура для файлов и каталогов.
Иерархическая структура «родитель-потомок» для процессов.
Для устройств – принадлежность к определенному типу устройств и связь с устройствами других типов.
186. Централизованный.
187. Разрешения (permissions) – это множество операций, которые могут быть определены для субъектов всех типов по отношению к объектам любого типа: файлам, каталогам, принтерам, секциям памяти и т.д.
Права (user rights) – определяются для субъектов типа «группа» на выполнение некоторых системных операций: установку системного времени, архивирование файлов, выключение компьютера и т.п. Именно права, а не разрешения отличают одну встроенную группу пользователей от другой. Некоторые права у встроенной группы являются также встроенными – их у группы нельзя отнять. Остальные права можно удалить или добавить из общего списка прав.
Возможности пользователей (user abilities) определяются для отдельных пользователей на выполнение действий, связанных с формированием их операционной среды, например, на изменение состава главного меню и т.д.
188. Если процесс во время создания объекта явно задает все права доступа, то система безопасности приписывает этот ACL объекту.
Если процесс не снабжает объект списком ACL и объект имеет имя, то применяется принцип наследования разрешений.
Если процесс не задал явно ACL для создаваемого объекта и не имеет наследуемых элементов ACL, то используется список ACL по умолчанию из токена доступа процесса.
189. Пользователи не могут работать с каталогом или файлом, если они не имеют явного разрешения на это или же они не относятся к группе, которая имеет соответствующее разрешение. Разрешения имеют накопительный характер за исключением разрешения No Access, которое отменяет все прочие разрешения.
ЛАБОРАТОРНЫЕ РАБОТЫ
Лабораторные работы относятся к практической части курса «Операционные системы, среды и оболочки». Лабораторные работы разделены по содержанию на две группы. Содержание лабораторных работ группы I построено на основе операционных систем компании Microsoft.
Группа I состоит из следующих лабораторных работ.
1. Системный реестр Windows 9X. Редактор базы данных регистрации.
2. Администрирование сетевой ОС Windows XP.
3. Командные центры Windows 9Х.
В качестве базовой операционной системы здесь выбрана самая распространенная на сегодняшний день, наиболее простая и доступная для изучения ОС Windows 9X. Изучаемые в ней компоненты присутствуют во всей серии современных ОС Windows XX.
В группу II входят лабораторные работы по изучению ОС Linux.
4. Установка ОС Red Hat Linux. Режимы работы системы. Инсталляция приложений.
5. Подсистемы управления ОС.
6. Файловые системы. Сетевые сервисы ОС Linux.
Для завершения курса студентам достаточно выполнить именно этот набор лабораторных работ. Лабораторные работы группы I выполняются студентами, если по каким-либо причинам нет возможности провести лабораторные работы группы II. Лабораторная работа № 3 группы I предназначена для домашнего выполнения. Методика выполнения лабораторных работ и их описание приведены ниже. Завершает практический курс контрольная работа.
Методические указания для проведения лабораторных занятий
и выполнения контрольной работы
1. На лабораторных занятиях студенты получают навыки по настройке и администрированию операционной системой (ОС) Windows 9X, изучают возможности манипулирования графическими элементами системы, предоставляя или запрещая рядовым пользователям возможность самостоятельно менять настройки системы.
2. Содержание лабораторных занятий группы I:
администрирование ОС Windows XX; редактирование системного реестра; изучение командных центров ОС Windows XX.
3. Содержание лабораторных занятий группы II:
подготовка разделов жесткого диска ПК для инсталляции системы; установка ОС на ПК; инсталляция приложений; администрирование ОС Red Hat Linux; графические и текстовые оболочки; графические системы аутентификации пользователей; файловые системы; сетевые сервисы; сетевые оболочки ОС Red Hat Linux.
4. Контрольная работа завершает практические занятия по курсу.
Вопросы для контрольной работы приведены на стр. 250. Преподаватель составляет варианты контрольной работы, в которые включает не менее десяти вопросов из списка и раздает студентам для выполнения. Ответы оформляются на листке бумаги в напечатанном или рукописном виде и предоставляются для проверки.
Во время проверки контрольной работы определяются неточности и недоработки, которые студент допустил при выполнении лабораторных работ и собственно контрольной работы.
5. Составление отчета. Отчет по лабораторным работам группы I составляется в редакторе Word for Windows. Отчет должен иметь стандартный титульный лист с заголовком «Отчет по лабораторным работам», где далее следует информация о составителе (студент группы, название группы, фамилия и инициалы студента) и проверяющем.
На первом листе отчета размещается заголовок «Лабораторная работа № 1», где далее следуют номер задания и результат его выполнения. Результат может быть графическим или текстовым. Например.
Задание № 1
Окно c результатом выполненного задания помещается в буфер промежуточного хранения (клавиши <Alt>+<Print Screen>), а затем вставляется в соответствующий параграф отчета либо с помощью кнопки «Вставить» панели «Стандартная» редактора, либо с помощью клавиш <Shift>+<Insert>.
Указанные действия повторяются для каждого пункта задания.
Методика составления отчета лабораторных работ группы II дана в лабораторной работе № 4. Отчеты по выполненным работам сохраняются на дискете или распечатываются на принтере, после чего предоставляются преподавателю для проверки. Работа, выполненная без замечаний, считается зачтенной.
Лабораторная работа № 1
Системный реестр Windows 9X.
Редактор базы данных регистрации
Введение. Операционная система Windows 9Х относится к типу однопользовательских многозадачных систем. Благодаря удобному графическому интерфейсу… Как любая современная ОС, Windows 9X имеет встроенные средства… Утилиты панели управления предназначены для конфигурации технических и программных средств ОС. С помощью этих утилит…Командный файл системного реестра
Во второй строке указывается полный путь расположения ключа начиная с корневой записи, например: … В третьей строке указываются название и значение ключа, например:Утилита редактора системных правил Poledit
Рассмотренная нами ранее программа regedit.exe входит в стандартную поставку ОС Windows 9X и позволяет менять любые настройки реестра. В настоящее… Задание 5. Откройте папку Poledit и запустите программу редактирования… В окне Редактор системных правил откройте меню Файл и выполните директиву Открыть реестр, что приведет к появлению…Список ключей системного реестра
[HKEY_CURRENT_USERSoftwareMicrosoftWindowsCurrentVersionPoliciesSystem] Параметр: NoDispCPL Этот параметр отключает доступ к значку «Дисплей» в Панели управления и не позволяет пользователям изменять параметры…Заблокировать возможность удаления принтеров.
[HKEY_CURRENT_USERSoftwareMicrosoftWindowsCurrentVersionPoliciesExplorer]
Параметр: NoDeletePrinter
Заблокировать возможность добавления принтеров.
Параметр: NoAddPrinter Скрыть вкладку «Устройства» утилиты «Система».Установка удаленного терминала (Remote DeskTop Connection)
Установочная программа клиента удаленного терминала располагается в папке WindowsSystem32clientstsclientwin32 ОС Windows 2003 Server. В… Задание 1. С помощью директивы Найти кнопки <Пуск> найдите сервер… Username: StudentРабота с Windows 2003 Server
Щелкните по директиве Подключение к удаленному рабочему столу (Remote Desktop Connection). На экране появится окно с одноименным названием. Если… Задание 2. В поле Компьютер (Computer) введите имя сервера, на котором Вы… На экране появится окно Log on to Windows с полями ввода логического имени клиента и пароля. Введите:Утилиты панели управления
Процедура инсталляции сетевых компонентов Рабочей станции Windows XP… Щелкните по кнопке <Пуск> (Start), выберите директиву Панель управления (Control Panel), затем Сетевые…Управление рабочей станцией
Щелкните правой клавишей мыши на значке Мой компьютер и выполните директиву Управление компьютером (Computer Management). Эта директива содержит… Общие папки (Shared Folders) – папка, в которой сгруппированы три… Общие ресурсы (Shares) – папка с отображением ресурсов, выделенных в сеть данной рабочей станцией;Администрирование
Административные программы сервера расположены в программной группе Администрирование (Administrative Tools), найти которую можно в меню кнопки… Задание 10. Откройте программную группу Администрирование. Окно поместите в… Active Directory – домены и доверие (Domain and Trust);Конфигурирование сервера
Утилита является однопользовательской. Если после запуска на экране появится сообщение о ее занятости, повторите попытку позже, когда Ваш коллега… Запуск утилиты Мастер настройка сервера (Configure Your Server)приводит к… Примечание. При деинсталляции службы Контроллер домена (Active Directory) удаляются все пользователи домена, включая…Управление контроллером домена
Если ПК с ОС Windows 2003 Server определен как контроллер домена, то в программной группе Администрирование (Administrative Tools) должны… Рассмотрим утилиту Active Directory – пользователи и компьютеры. Эта утилита… Builtin (встроенные группы, которым на сервере предоставлены определенные привилегии);Предоставление доступа к ресурсам сервера
В корневом каталоге логического диска с файловой системой NTFS, имя которого вам укажет преподаватель (в УрГЭУ – диск I:), с помощью проводника… Доступ (Sharing) – установка прав доступа к папке на уровне локальной сети… Безопасность (Security) – установка прав доступа к папке на уровне локального ресурса. Эта вкладка отображается на…Привилегия клиента удаленного терминала
Задание 19. В программной группе Администрирование (Administrative Tools) выполните директиву Настройка служб терминалов (Terminal Services… Используя клавишу Добавить (Add), внесите логическое имя пользователя в список…Командные центры Windows 9Х
Работа предназначена для самостоятельного выполнения. Введение. Командные центры Windows 9X по управлению системными ресурсами,… С директивами панели задач и проводником Вы познакомились на практических занятиях по другим дисциплинам. По утилитам…Рабочий стол. Свойства рабочего стола
Важным достоинством ОС Windows 9X является то, что, как всякая современная операционная система, она позволяет изменять и настраивать свой… Задание 14. Откройте системное меню рабочего стола и с помощью подменю… Вновь включите опцию упорядочения автоматически.Лабораторная работа № 4
Введение. Операционная система (ОС) Fedora Core X принадлежит к классу… ОС Fedora Core X соответствует стандарту API POSIX для UNIX систем, поэтому знания, полученные студентами во время…Инсталляция ОС Fedora Core X
Стандартная установка на ПК ОС Fedora Core X, как и Red Hat Linux, обычно проводится в графическом режиме с загрузочного компакт-диска, на котором… Примечание. Далее все действия по инсталляции будут проводиться с… Задание 4. Установите загрузочную flash-память в гнездо USB-разъема и перезагрузите компьютер. После загрузки…Графический интерфейс GNOME ОС Linux
X Window принадлежит к классу классических графических оболочек ОС UNIX. GNOME и KDE – современные оконные менеджеры, на развитие которых оказала… Графический интерфейс GNOME имеет много общего с графическим интерфейсом ОС… Меню кнопки <Пуск> содержит ряд директив, назначение которых Вам предлагается выяснить самостоятельно,…Лабораторная работа № 4
Установка ОС Fedora Core X
Исполнитель – студент группы ПИЭ…, Ф.И.О. Активируйте окно терминала. С помощью клавиш <Alt>+<Print Screen> вызовите программу получения снимка…Текстовый интерфейс ОС Linux
Алфавитно-цифровой терминал
Если интерфейс GNOME напоминает графический интерфейс ОС Windows 98, то алфавитно-цифровой терминалом ОС Linux больше похож на окно DOS. Однако в… Задание 9. С помощью клавиш <Ctrl>+<Alt>+<F1> переключитесь…Режимы работы ОС Linux
Задание 10. Запустите интерфейс mc и по клавише <F4> откройте для редактирования файл /etc/inittab, предварительно перейдя в каталог /etc. По… В файле inittab содержится директивная информация о загрузке и завершении… 1) идентификаторы запуска, останова и завершения работы ОС:Установка приложений в ОС Red Hat
Установка приложений – это не самый сложный процесс взаимодействия пользователя с компьютером даже для ОС типа UNIX, хотя в ОС Windows ХX процесс… В ОС Linux установка приложений не столь однозначна, как в ОС Windows XX,…Лабораторная работа № 5
Подсистемы управления ОС
Введение. Функции операционной системы обычно группируются либо в соответствии с типами локальных ресурсов, которыми управляет ОС, либо в… Цель лабораторной работы. Ознакомить студентов с утилитами подсистемы… 1) подсистемы управления;Управление ресурсами ОС Linux
Подсистема управления процессами. Операционная система для каждого вновь создаваемого процесса создает специальную информационную структуру, в… В этой структуре также находится дополнительная информация, которая отражает… В системное программное обеспечение ОС Linux входит набор утилит, позволяющий просмотреть состояние информационных…Системный монитор
Окно утилиты содержит строку меню: Файл, Правка, Вид, Справка и вышеуказанные вкладки. В меню Файл находится директива выхода из утилиты, а в меню Справка –… Меню Правка окна утилиты Системный монитор содержит директивы по управлению процессами: Завершить процесс, Снять…Подсистемы управления, общие для всех ресурсов
К подсистемам управления, общим для всех ресурсов, относятся:
подсистема пользовательского интерфейса;
подсистема администрирования и защиты данных;
интерфейс прикладного программирования.
Администрирование в ОС Red Hat.
Локальные системы
Задание 7. Перейдите на вкладку Группы и нажмите кнопку Добавить группу. В диалоговом окне Создать новую группу укажите имя StudentsN (N – номер… Задание 8. Перейдите на вкладку Пользователи и нажмите клавишу Добавить… Данные пользователя;Пользовательский интерфейс
Режим текстового терминала, загрузка которого осуществляется по системному вызову init 3, был рассмотрен нами в лабораторной работе № 4. Поэтому в… Удаленный текстовый терминалРегистрация событий
Информацию о загрузке ядра, в процессе которой определяются технические характеристики ПК, можно просмотреть с помощью утилиты dmesg. Ввиду большого… Задание 22. Используя команду last | less, выделите в журнале регистрации всех… CPU …Файловые системы. Сетевые сервисы ОС Linux
Введение. Обычно файлы, хранимые на жестком диске, представляют собой несвязанные блоки информации, расположенные в разных местах диска.… Наиболее популярные на сегодняшний день ОС Windows XX и UNIX используют… В мире Windows наиболее популярны файловые системы:Создание и локализация файловой системы
Для создания файловой системы на каком-либо внешнем носителе служит команда mkfs. Руководство по использованию этой команды можно получить по… man mkfs или mkfs --help. Это команда имеет множество ключей, среди которых отметим ключ t. Ключ t служит для явного указания типа создаваемой…Сервисы Linux
ОС Linux выполнена на основе классического ядра, в котором часть системных функций выполняется серверами ОС, такими как vsftpd, httpd, sendmail,… Список установленных серверов и режимы их запуска можно просмотреть как в…СПИСОК ВОПРОСОВ К КОНТРОЛЬНОЙ РАБОТЕ
1. Допустим, Вам надо написать деловое письмо на немецком языке. Можно ли установить немецкую раскладку клавиатуры под Windows 9X? Если можно, то… 2. Для переключения раскладки клавиатуры с русской на английскую Вы… 3. При работе с «мышью» Вы замечаете, что при нажатии левой клавиши на экране появляется системное меню. Что это…– Конец работы –
Используемые теги: операционные, системы, среды, оболочки0.062
Если Вам нужно дополнительный материал на эту тему, или Вы не нашли то, что искали, рекомендуем воспользоваться поиском по нашей базе работ: Операционные системы, среды и оболочки
Что будем делать с полученным материалом:
Если этот материал оказался полезным для Вас, Вы можете сохранить его на свою страничку в социальных сетях:
| Твитнуть |
Хотите получать на электронную почту самые свежие новости?

Подпишитесь на Нашу рассылку
Реклама





Информация в виде рефератов, конспектов, лекций, курсовых и дипломных работ имеют своего автора, которому принадлежат права. Поэтому, прежде чем использовать какую либо информацию с этого сайта, убедитесь, что этим Вы не нарушаете чье либо право.
© copyright 1999 - 2024 allRefs.net. Все права защищены. Страница сгенерирована за: 0.152 сек.
Новости и инфо для студентов