рефераты конспекты курсовые дипломные лекции шпоры

- Раздел Программирование
- /
- Основы алгоритмизации и Программирование
Реферат Курсовая Конспект
Основы алгоритмизации и Программирование
Основы алгоритмизации и Программирование - раздел Программирование, Министерство Образования Российской Федерации...
МИНИСТЕРСТВО ОБРАЗОВАНИЯ РОССИЙСКОЙ ФЕДЕРАЦИИ
Московский государственный университет экономики,
Статистики и информатики
Грибанов В.П.
Калмыкова О.В.
Сорока Р.И.
Основы алгоритмизации и
Программирование
Москва 2003
ББК -018*32.973 К 174СОДЕРЖАНИЕ
Введение6
1.Алгоритмизация вычислительных процессов.8
1.1 Основные определения и понятия. 8
1.2 Средства изображения алгоритмов. 9
1.3 Базовые канонические структуры алгоритмов. 14
Вопросы к главе 1.16
2.Введение в Турбо Паскаль.17
2.1 Общая характеристика языка Паскаль. 17
2.2 Основные понятия языка Турбо Паскаль. 18
2.2.1 Алфавит языка. 18
2.2.2 Элементарные конструкции. 19
2.2.3 Типы данных. 21
2.3 Операторы языка Паскаль. 24
2.3.1 Оператор присваивания. 24
2.3.2 Оператор перехода. Пустой оператор. Составной оператор. 25
2.3.3 Условный оператор. 26
2.3.4 Оператор выбора. 26
2.3.5 Операторы цикла. 28
Вопросы к главе 2.35
3.Структурированные типы данных.37
3.1 Свойства множеств. 37
3.2 Операции над множествами. 38
3.3 Описание записи (RECORD). 42
3.4 Оператор присоединения. 44
3.5 Запись с вариантами. 47
Вопросы к главе 3.48
4.Использование подпрограмм в Турбо Паскале.49
4.1 Структура программы на языке Паскаль. 49
4.2 Описание и вызов процедур. 50
4.3 Описание функции. 51
4.4 Формальные и фактические параметры. 52
4.5 Область действия имен. 57
4.6 Процедуры и функции без параметров. 59
4.7 Рекурсивные процедуры и функции. 59
4.8 Предварительно-определенные процедуры. 61
4.9 Модули. 62
Вопросы к главе 4.65
5.Стандартные процедуры и функции.66
5.1 Математические функции. 66
5.2 Функции округления и преобразования типов. 67
5.3 Функции порядкового типа. 68
5.4 Процедуры порядкового типа. 69
5.5 Строковые функции. 69
5.6 Строковые процедуры. 70
5.7 Прочие процедуры и функции. 71
5.8 Процедуры ввода данных. 72
5.9 Процедуры вывода данных. 74
5.9.1 Особенности вывода вещественных значений. 75
Вопросы к главе 5.77
6.Работа с файлами.78
6.1 Общие сведения о файлах. 78
6.2 Процедуры и функции для работы с файлами. 79
6.3 Особенности обработки типизированных файлов. 80
6.4 Особенности обработки текстовых файлов. 83
6.5 Файлы без типа. 85
6.6 Проектирование программ по структурам данных_ 86
6.7 Работа с файлами при обработке экономической
информации_ 93
6.7.1 Постановка задачи. 93
6.7.2 Проектирование программы. 98
6.7.3 Кодирование программы. 99
Вопросы к главе 6.104
7.Динамическая память.105
7.1 Указатель. 105
7.2 Стандартные процедуры размещения и освобождения динамической памяти. 108
7.3 Стандартные функции обработки динамической памяти. 110
7.4 Примеры и задачи. 112
7.5 Работа с динамическими массивами. 113
7.6 Организация списков. 117
7.7 Задачи включения элемента в линейный однонаправленный список без головного элемента. 125
7.8 Задачи на удаление элементов из линейного однонаправленного списка без головного элемента. 129
7.9 Стеки, деки, очереди. 134
7.10 Использование рекурсии при работе со списками. 136
7.11 Бинарные деревья. 137
7.12 Действия с бинарными деревьями. 139
7.13 Решение задач работы с бинарным деревом. 141
Вопросы к главе 7.145
8.Основные принципы структурного программирования.146
8.1 Понятие жизненного цикла программного продукта 146
8.2 Основные принципы структурной методологии. 147
8.3 Нисходящее проектирование. 148
8.4 Структурное кодирование. 148
8.5 Модульное программирование. 148
Вопросы к главе 8.150
9.Список литературы151
Введение
Учебное пособие разработано в соответствии с программой курса «Основы программирования» и предназначено для студентов специальностей «Прикладная информатика в экономике» и «Прикладная информатика в менеджменте».
Учебное пособие состоит из 8 глав.
В первой главе излагаются общие вопросы курса. Приводятся основные определения и понятия, описываются изобразительные средства представления алгоритмов, базовые канонические структуры алгоритмов.
Вторая глава посвящена введению в программирование на языке Турбо Паскаль. Описываются основные конструкции языка, начиная с алфавита языка, элементарных конструкций и типов данных и заканчивая операторами языка.
В третьей главе описываются структурированные типы данных: множества и записи, а также приемы работы с ними.
В четвертой главе излагаются вопросы использования подпрограмм в языке Турбо Паскаль. Приводится структура программы, описание и вызов процедур и функций, виды и способы передачи параметров в процедуры и функции, области действия идентификаторов в программах сложной структуры, использование рекурсивных процедур и функций. Завершается глава описанием структуры и отдельных частей модулей.
В пятой главе приводятся стандартные процедуры и функции. Описываются процедуры и функции модуля System, в котором располагается стандартная библиотека Турбо Паскаля, подключаемая по умолчанию. Рассматриваются особенности использования процедур ввода и вывода данных различных типов. Кроме того, описываются процедуры и функции модуля Crt, обеспечивающие удобную работу с экраном и клавиатурой.
Шестая глава посвящена работе с файлами. Сначала излагаются общие вопросы работы с файлами, затем особенности работы с различными типами файлов: типизированными файлами, текстовыми файлами и файлами без типа. Рассматривается проектирование программ по структурам данных и решение конкретной экономической задачи с использованием этого подхода.
В седьмой главе излагаются вопросы использования динамической памяти в программах. Приводятся стандартные процедуры и функции работы с динамической памятью и их использование для обработки динамических массивов. Далее рассматриваются динамические структуры данных: списки, стеки, очереди и деревья, а также приемы работы с ними. Описываются типовые операции, выполняемые над динамическими структурами данных, и обсуждаются возможности их реализации на языке Турбо Паскаль.
Восьмая глава посвящена основным принципам структурного программирования. Рассматриваются основные этапы жизненного цикла программного обеспечения, некоторые подходы к разработке программных продуктов: нисходящее проектирование, структурное кодирование и модульное программирование.
Алгоритмизация вычислительных процессов.
Основные определения и понятия.
Алгоритмизация – это процесс построения алгоритма решения задачи, результатом которого является выделение этапов процесса обработки данных,… Алгоритм – это точное предписание, определяющее вычислительный процесс,… Свойства алгоритма:Средства изображения алгоритмов.
Основными изобразительными средствами алгоритмов являются следующие способы их записи: - словесный; - формульно-словесный;Базовые канонические структуры алгоритмов.
Доказано, что любую программу можно написать, используя комбинации трех управляющих структур: - следования или последовательности операторов; - развилки или условного оператора;A; B;
Действия А и В могут быть:
- отдельным оператором;
- вызовом с возвратом некоторой процедуры;
- другой управляющей структурой.
2)развилка
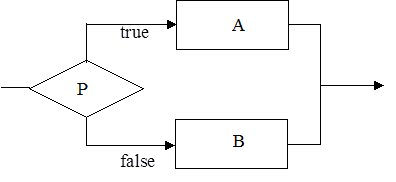
IF P then A else B;
Проверка Pпредставляется предикатом, т.е. функцией, задающей логическое выражение или условие, значением которого может быть истина или ложь. Эта структура может быть неполной, когда отсутствует действие, выполняемое при ложном значении логического выражения. Тогда структура будет следующая:
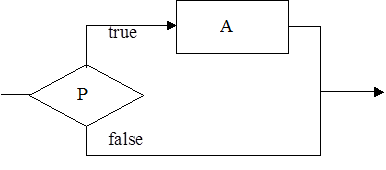
IF P then A ;
3)повторение
цикл – пока

While P do A ;
цикл – доRepeat A until P;
4) выбор – переключатель case (обобщение развилки), структура, облегчающая программирование без ущерба для ясности программы. Структура выбор… В зависимости от значения Р выполняется одно из действий А, В, …Z. После чего происходит переход к выполнению…Вопросы к главе 1.
2. Что такое программа? 3. Что такое алгоритм? 4. Что такое алгоритмический процесс?Введение в Турбо Паскаль.
Общая характеристика языка Паскаль.
Язык Паскаль был разработан Никласом Виртом первоначально для целей обучения программированию. В настоящее время он получил широкое распространение… Во-первых, по своей идеологии Паскаль наиболее близок к современной методике и… Во-вторых, Паскаль хорошо приспособлен для применения технологии разработки программ сверху-вниз (пошаговой…Основные понятия языка Турбо Паскаль.
Алфавит языка.
Язык Турбо Паскаль допускает использование прописных и строчных букв латинского алфавита, знака подчеркивания, арабских цифр и ограничителей.Элементарные конструкции.
Из основных символов непосредственно образуются элементарные конструкции языка, которые являются минимальными неделимыми синтаксическими единицами.… Различные объекты программы должны иметь имена. В качестве имен используются… Константы – это данные, значения которых не изменяются в процессе работы программы. Константы могут быть…Типы данных.
Каждая переменная и константа в программе на языке Паскаль имеет свой тип данных. Тип определяет набор операций, которые могут быть к ней применимы,… Все переменные, используемые в программе должны быть описаны в разделе…Операторы языка Паскаль.
Оператор присваивания.
Наиболее простым и часто используемым оператором языка является оператор присваивания:
<переменная> : = <выражение>;
Выражение – это формула для вычисления значения. Она образуется из операндов, соединенных знаками операций и круглыми скобками. В качестве операндов могут выступать переменные, константы, указатели функций.
Тип переменной в левой части оператора присваивания обычно должен совпадать с типом значения выражения в правой части. Возможны случаи несовпадения типов, например, когда слева переменная вещественного типа, а справа выражение целого типа. Выражения являются составной частью операторов.
В Паскале приоритеты выполнения операций следующие (в порядке убывания):
- одноместный минус;
- операция NOT;
- операции типа умножения ;
- операции типа сложения;
- операции сравнения (отношения).
Одноместный минус применим к операндам арифметического типа. Операция NOT– к операндам логических и целых типов. Если в одном выражении несколько операций одного приоритета, то они выполняются, начиная слева. Приоритеты можно изменить, поставив скобки. В логических выражениях необходимы скобки во избежание конфликта типа по приоритету.
Например, если в выражении … (X > 5) AND (Y > 10) … не поставить скобки, то будет синтаксическая ошибка, так как приоритет операции AND выше приоритета операций сравнения >.
<операции типа умножения> :: = * | / | div | mod | and
<операции типа сложения> :: = + | - | or | xor
<операции сравнения> :: = = | <> | < | > | <= | >= | in
Операции сравнения применимы для всех стандартных простых типов. Причем в одном выражении возможно использование операндов различных типов. Результат сравнения всегда имеет логический тип.
Например, (5 + 6) < (5 - 6) = TRUE в результате даст FALSE, а NOT(8.5 < 4) будет равно TRUE.
Сравнение строк символов выполняется слева направо посимвольно. Более короткие строки дополняются пробелами справа.
Оператор перехода. Пустой оператор. Составной оператор.
Оператор безусловного перехода GOTO служит для прерывания естественного хода выполнения программы. Следующим выполняется оператор, помеченный меткой, которая использована в данном операторе перехода. Один оператор может помечаться несколькими метками.
GOTO <метка> ;
<метка> - это целое без знака или идентификатор, обязательно описанный в разделе описания меток (LABEL).
Для того, чтобы пометить оператор, перед ним ставится метка, после которой записывается двоеточие.
<метка> :[<метка>: …] <оператор>;
Оператор GOTO не рекомендуется использовать при программировании, так как это существенно усложняет отладку и тестирование программы, тем более что остальных управляющих операторов языка вполне достаточно для реализации любого алгоритма.
Пустой оператор не обозначается и не вызывает никаких действий в программе, представляет собой дополнительную точку с запятой.
Если необходимо, чтобы группа операторов рассматривалась транслятором, как один оператор, эту группу операторов заключают в операторные скобки BEGINи END. Такой оператор называется составным оператором. Составной оператор может быть использован в любом месте программы, где разрешен простой оператор, но требуется выполнение группы операторов.
Условный оператор.
Условный оператор используется для программирования развилки, если условие сформулировано как логическое выражение.
IF <логическое выражение> THEN<оператор 1>
[ ELSE <оператор 2>] ;
<следующий оператор >;
Оператор выполняется таким образом: если результат вычисления логического выражения TRUE, то выполняется <оператор 1>, затем <следующий оператор >; если – FALSE, то выполняется <оператор 2>, затем <следующий оператор>. Операторы 1 и 2 могут быть простым или составным оператором. Если часть оператора, начинающаяся ELSE, отсутствует, то при логическом выражении равным FALSE, будет выполняться <следующий оператор>. При вложенности условных операторов ELSE всегда относится к ближайшему предшествующему IF. Следует избегать большой глубины вложенности условных операторов, так как при этом теряется наглядность и возможно появление ошибок.
Например,
… IF A > 0 THEN P := P + 1
ELSE
IF A < 0 THEN O := O + 1
ELSE N := N + 1 ; …
… IF A > 0 THEN
BEGIN
S := S+ A ; K := K + 1
END ;…
Оператор выбора.
Оператор выбора CASE может быть использован вместо условного оператора, если требуется сделать выбор более, чем из двух возможностей.
|
|
<метка> ,<метка> : <оператор 1> ;
|
|
<метка> ,<метка> : <оператор 2> ;
,<метка> . . <метка>
|
|
<метка> ,<метка> : <оператор n>;
,<метка> . . <метка>
[ ELSE <оператор>]
END;
Селекторное выражение (селектор, переключатель) и метки-константы (метки варианта, метки выбора) должны иметь один и тот же простой тип (кроме вещественного). Метки-константы в отличие от меток программы не требуется описывать в разделе описания меток. Но на них нельзя ссылаться в операторе GOTO. Метки варианта могут быть перечисляемого и интервального типа.
<оператор 1>,<оператор 2>,<оператор n> - простой или составной оператор.
Оператор выбора выполняется следующим образом. Сначала вычисляется селекторное выражение; затем выполняется оператор, метка варианта которого равна текущему значению селектора; после этого происходит выход из оператора CASE на следующий оператор. Если значение селектора не совпадает ни с одной из меток варианта, будет выполнен оператор после ELSE. Если ветвьELSEотсутствует, то управление передается следующему за CASE оператору.
Например,

… CASE K OF
0: Z := LN(X) ;
1: Z := EXP(X) ;
2: Z := SIN(X) ;
3: Z := COS(X)
ELSE
Z := 0
END ; …
В этом примере результат вычисляется по одной из стандартных функций в зависимости от параметра К, который получает свое значение перед выполнением этого оператора.
В следующем примере переменная OTVET получает значение YES или NO в зависимости от введенного значения символьной переменной V.Здесь метки варианта задаются перечислением.
… VAR V : CHAR;
OTVET : STRING;
…
CASE V OF
‘D’, ‘d’, ‘Д’, ‘д’ : OTVET := ‘YES’;
‘N’, ‘n’, ‘Н’, ‘н’ : OTVET := ‘NO’
ELSE
OTVET := ‘ ‘
END; …
В следующем примере метки выбора заданы интервалом.
… VAR V : CHAR;
OTVET : STRING;
…
CASE V OF
‘A’ . . ‘Z’,’a’ . . ‘z’ : OTVET := ‘буква’;
‘0’ . . ‘9’ : OTVET := ‘цифра’
ELSE
OTVET := ‘специальный символ‘
END; …
Операторы цикла.
Операторы цикла используются для многократного повторения входящих в их состав операторов. В языке Турбо Паскаль различают операторы цикла типа арифметической прогрессии (оператор цикла со счетчиком – FOR) и операторы цикла итерационного типа (WHILE и REPEAT).
Оператор цикла типа арифметической прогрессии используется, если заранее известно количество повторений цикла и шаг изменения параметра цикла +1 или –1.
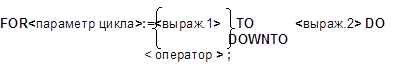
< параметр цикла > - это переменная цикла любого порядкового типа (целого, символьного, перечисляемого, интервального);
TO – шаг изменения параметра цикла +1;
DOWNTO - шаг изменения параметра цикла -1;
< выражение 1> - начальное значение параметра цикла, выражение того же типа, что и параметр цикла;
< выражение 2> -конечное значение параметра цикла, выражение того же типа, что и параметр цикла;
< оператор>- тело цикла - простой или составной оператор.
При выполнении оператора FOR выполняются следующие действия:
· вычисляется < выражение 1> , которое присваивается параметру цикла;
· проверяется условие окончания цикла: <параметр цикла> больше <выражения 2> при использовании конструкцииTO и <параметр цикла> меньше <выражения 2> при использовании конструкцииDOWNTO;
· выполняется тело цикла;
· наращивается (TO) или уменьшается (DOWNTO) на единицу параметр цикла;
· все этапы, кроме первого, циклически повторяются.
При использовании оператора необходимо помнить:
o Внутри цикла FOR нельзя изменять начальное, текущее или конечное значения параметра цикла.
o Если в цикле с шагом +1 начальное значение больше конечного, то цикл не выполнится ни разу. Аналогично для шага -1, если начальное значение меньше конечного.
o После завершения цикла значение параметр цикла считается неопределенным, за исключением тех случаев, когда выход из цикла осуществляется оператором GOTO или с помощью процедуры BREAK.
o Телом цикла может быть другой оператор цикла.
Например, для того, чтобы вычислить значение факториала F=N!можно воспользоваться следующими операторами:
a) … F:=1; b)… F:=1;
FOR I:=1 TO N DO FOR I:=N DOWNTO 1 DO
F:=F*I; … F:=F*I; …
В следующем примере цикл выполняется 26 раз и SIM принимает значения всех латинских букв от ’A’ до ‘Z’.
…
FOR SIM:=’A’ TO ‘Z’ DO
WRITELN( SIM);
Если телом цикла является другой цикл, то циклы называются вложенными или…BEGIN
FOR I:=1 TO N DO
FOR J:=1 TO M DO
READLN(A[I,J]);
Y:=0;
FOR I:=1 TO N DO
BEGIN
P:=1;
FOR J:=1 TO M DO
P:=P*A[I,J];
Y:=Y+P
END;
WRITELN(‘Y=’,Y)
END.
Операторы цикла итерационного типа используются обычно в том случае, если число повторений цикла заранее неизвестно или шаг изменения параметра цикла отличен от +1 или –1.
Оператор цикла с предусловием:
WHILE <логическое выражение> DO <оператор>;
Логическое выражение вычисляется перед каждым выполнением тела цикла. Если логическое выражение принимает значение TRUE, то тело цикла выполняется, если значение FALSE, происходит выход из цикла. Тело цикла может не выполниться ни разу, если логическое выражение сразу ложно. Телом цикла является простой или составной оператор.
Любой алгоритм, реализуемый с помощью оператора FOR, может быть записан с использованием конструкции WHILE.Например, вычисление значения факториала F=N!:
… F:=1;
I:=1;
WHILE I<=N DO
BEGIN
F:=F*I;
I:=I+1;
END; …
В следующем примере требуется подсчитать значение Sin (x) с использованием разложения функции в ряд:
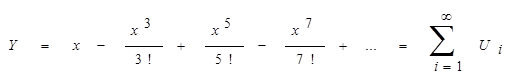
В сумму включить только те члены ряда, для которых выполняется условие:
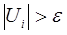
т.е. очередной член ряда должен быть больше заданной точности вычислений e.
Program SINX;
Var X,Y,E,U,Z : real;
K: integer;
Begin
Readln(X,E);
K:=0;
Y:=0;
U:=X;
Z:=sqr(X);
While abs(U)>E do
Begin
Y:=Y+U;
K:=K+2;
U:= -U* Z/ (K*(K+1));
End;
Writeln( ‘ SIN(X)=’, SIN(X), ‘ Y=’,Y);
End.
Для проверки правильности работы программы в оператор вывода включена печать значения синуса, вычисленного при помощи стандартной функции. Если полученное значение отличается от рассчитанного при помощи стандартной функции не более, чем на точность, можно считать, что программа работает правильно.
Рассмотрим пример вычисления значения квадратного корня из числа Х по итерационной формуле
 Yi+1 =(Yi + X/ Y i ) /2с точностью Yi+1 - Yi <=e
Yi+1 =(Yi + X/ Y i ) /2с точностью Yi+1 - Yi <=e
Начальное приближение Y0=A является параметром.
Program SQRTX;
Var X: real; {аргумент }
EPS: real; {точность вычисления }
Y0: real; {предыдущее приближение}
Y1: real; {очередное приближение }
A: real; {начальное приближение }
Begin
Readln( A,EPS,X);
If X>0 then
Begin
Y0:=A;
Y1:=(Y0+X/Y0)/2;
While abs(Y1-Y0)>EPS do
Begin
Y0:=Y1;
Y1:=(Y0+X/Y0)/2
End;
Writeln(‘Y1=’,Y1,’ при X=’,X)
End
Else
Writeln(‘Число ’, X, ' меньше нуля');
End.
Оператор цикла с постусловием:
REPEAT
<оператор 1> [;
<оператор 2>] [;
…
<оператор n>]
UNTIL <логическое выражение>;
Данная конструкция оператора цикла используется, если число повторений цикла заранее неизвестно, но известно условие выхода из цикла. Управляющее циклом логическое выражение является условием выхода из цикла. Если оно принимает значение TRUE, то выполнение цикла прекращается. При использовании оператора REPEAT цикл выполняется хотя бы один раз. В отличие от других операторов цикла оператор данного вида не требует операторных скобок BEGIN - END, так как их роль выполняют REPEAT - UNTIL.
Вычисление F=N! с использованием конструкции REPEAT – UNTILбудет выглядеть следующим образом:
. . .
F:=1;
I:=1;
Repeat
F:=F*I;
I:=I+1;
Until I>N;
. . .
Рассмотрим другой пример использования этого оператора. Вводится последовательность чисел. Определить количество элементов кратных 7.
Program rep;
Var A,K: integer;
C : char;
Begin
K:=0;
Repeat
Writeln(‘ Введите очередное число ‘);
Readln( A);
If A mod 7=0 then K:=K+1;
Writeln(‘Хотите выйти из цикла? д/y’ );
Readln( C ) ;
Until ( C=’д‘ ) or ( C=’y’) ;
Writeln(‘kol=’,K);
End.
Здесь условием выхода из цикла является ввод символов Дили Y при ответе на вопрос о выходе из цикла. Если вводится одна из этих букв, логическое выражение, записанное после UNTIL, становится TRUE и происходит выход из цикла.
В следующем примере требуется поменять местами максимальный и минимальный элементы, найденные среди элементов четных строк матрицы А(M,N).
Program Obmen;
Var A: array[1..30,1..30] of integer;
I,J : integer;
K1,L1,K2,L2 : integer;
T,M,N: integer;
Begin
Readln(M,N);
For I:=1 to M do
For J:=1 to N do
Readln( A[I,J]);
K1:=1;L1:=1; {координаты максимального элемента}
K2:=1;L2:=1; {координаты минимального элемента}
I:=2;
While I<=M do
Begin
For J:=1 to N do
If A[K1, L1]< A[I,J] then
Begin
K1:=I;L1:=J;
End
Еlse
If A[K2, L2]> A[I,J] then
Begin
K2:=I;L2:=J;
End;
I:=I+2;
End;
T:= A[K1, L1];
A[K1, L1]:= A[K2, L2];
A[K2, L2]:=T;
For I:=1 to M do
Begin
For J:=1 to N do
Write ( A[I,J] :6);
Writeln ;
End;
End.
Здесь используется цикл WHILE для индексации строк, т.к. нас интересуют только четные строки, следовательно, шаг для строк должен быть равен 2. В цикле FOR этого сделать нельзя.
В языке Турбо Паскаль 7.0 имеются процедуры BREAKи CONTINUE . Эти процедуры могут использоваться только внутри циклов FOR, WHILEили REPEAT. Процедура BREAK прерывает выполнение цикла и вызывает переход к оператору, следующему за циклом (может использоваться вместо оператора GOTO).Процедура CONTINUE осуществляет переход к следующему повторению цикла с пропуском последующих операторов тела цикла.
Например, необходимо определить номер первого элемента одномерного массива, оканчивающегося на 3.
Program Kon;
Var A:array [1.. 30] of integer;
FL: Boolean;
I,N: Integer;
Begin
Readln(N);
For I:=1 to N do
Readln( A[I] );
FL:=false;
For I:=1 to N do
Begin
If A[I] mod 10 <> 3 then Continue;
Writeln(‘Номер первого числа на 3 ’,I);
FL:=true;
Break;
End;
If not FL then Writeln(‘ нет чисел на 3‘);
End.
Если встречается число, оканчивающееся на 3, происходит вывод сообщения об этом, флаг – переменная FL – становится равным TRUE и программа заканчивает свою работу, т.к. цикл прерывается. Если же такое число не встречается, происходит нормальное завершение цикла, переменная FL остается равной FALSE и выводится сообщение о том, что таких чисел нет.
Вопросы к главе 2.
1. Дать определение языка программирования. 2. Дать классификационную характеристику языков программирования. 3. Определить особенности языков высокого уровня.Структурированные типы данных.
Данные одинакового простого типа (кроме вещественного) могут объединяться в множество. В общем виде тип множество описывается:Свойства множеств.
1) Если все элементы одного множества совпадают с элементами другого множества, то они (множества) считаются равными. Множества [1..5] и [1,2,3,4,5] равны. 2) Если все элементы одного множества являются членами другого множества, то 1 множество включено во 2 множество.Операции над множествами.
1) * - пересечение множеств (произведение).
Пусть X=[1,2,3,4,7,9], а Y=[1,2,3,10,5], тогда при выполнении оператора Z: = X * Y; множество Z содержит элементы, которые принадлежат как множеству X, так и множеству Y, т.е. Z=[1,2,3].
2) + - объединение множеств (сумма).
Пусть X=[1,2,3,4,7,9], а Y=[1,2,3,10,5], тогда при выполнении оператора Z:= X + Y; множество Z содержит элементы, которые принадлежат либо множеству X, либо множеству Y, т.е. Z=[1,2,3,4,5,7,9,10].
3) - - разность множеств или относительное дополнение.
Пусть X=[1,2,3,4,7,9], а Y=[1,2,3,10,5], тогда при выполнении оператора Z: = X - Y; множество Z содержит элементы X, которые не принадлежат множеству Y, т.е. Z=[4,7,9].
4) = - проверка на равенство.
Если все элементы множества X являются элементами множества Y, то результатом выполнения операции будет TRUE, в противном случае – FALSE. Пусть X=[1,2,3,4,7,9], а Y=[1,2,3,10,5], тогда при выполнении оператора F: = X = Y; F= FALSE.
5) <> - проверка на неравенство.
Если какие-то элементы множества X не являются элементами множества Y или наоборот, то результатом выполнения операции будет TRUE, в противном случае – FALSE. Пусть X=[1,2,3,4,7,9], а Y=[1,2,3,10,5], тогда при выполнении оператора F:=X<>Y; F= TRUE.
6) >= - проверка на включение.
Если все элементы множества Y являются элементами множества X, то результатом выполнения операции будет TRUE, в противном случае – FALSE. Пусть X=[1,2,3,4,7,9], а Y=[1,2,3], тогда при выполнении оператора F: = X >= Y; F= TRUE.
7) <= - проверка на включение.
Если все элементы множества X являются элементами множества Y, то результатом выполнения операции будет TRUE, в противном случае – FALSE. Пусть X=[1,2,3], а Y=[1,2,3,10,5], тогда при выполнении оператора F: = X < = Y; F= TRUE.
8) IN - проверка принадлежности отдельного элемента множеству.
Слева от знака операции записывается выражение того же типа, что и базовый, а справа – множество. Если левый операнд является элементом множества Y, то результатом выполнения операции будет TRUE, в противном случае – FALSE. Пусть A=5, а Y=[1,2,3,10,5], тогда при выполнении оператора F: = A IN Y; F= TRUE.
Отношения > и < для множеств не определены.
Рассмотрим некоторые примеры, в которых используются операции над множествами.
Вводится строка символов. Требуется составить программу, распознающую является ли введенная строка идентификатором.
Var
sim:char;
fl:boolean;
s:string[127];
i,l:byte;
Begin
Readln(s);
l:=length(s);
sim:=s[1];
if not(sim in ['a'..'z']) then fl:=false
else fl:=true;
i:=2;
while(i<=l) and fl do
Begin
sim:=s[i];
if not (sim in ['a'..'z','0'..'9','_']) then fl:=false
else i:=i+1
End;
if fl then writeln('идентификатор')
else writeln(' нет ')
End.
Базовым типом множества в данной программе является тип CHAR.Поэтому для выполнения операции проверки принадлежности элемента множеству в правой части также требуется тип CHAR. Для выделения символа из строки используется индексирование, т.к. выделение символа с помощью функции COPYдает результат типа STRING, что недопустимо для множеств.
В следующем примере требуется вывести на экран все простые числа из интервала от 2 до 255.
USES CRT;
CONST N=255;
VAR ISX, REZ: SET OF 2..N;
I,J: INTEGER;
BEGIN
CLRSCR;
REZ:=[ ];
ISX:=[2..N];
I:=2;
REPEAT
WHILE NOT(I IN ISX) DO
I:=SUCC(I);
REZ:=REZ+[I];
J:=I;
WHILE J<=N DO
BEGIN
ISX:=ISX-[J];
J:=J+I
END;
UNTIL ISX=[ ];
WRITELN;
FOR I:=1 TO 255 DO
IF I IN REZ THEN
WRITE (‘ ‘,I,’ ‘);
READKEY
END.
В основу программы положен алгоритм, известный под названием «решето Эратосфена», т.е. метод отсеивания составных чисел, при котором последовательно вычеркиваются числа, делящиеся на 2, 3, 5 и т.д.; первое число, остающееся после каждого этапа, является простым и добавляется к результату. Исходное множество в начале программы содержит все натуральные числа от 2 до 255. Результат также является множеством, к которому последовательно добавляются элементы. Условием окончания работы является пустое множество, получившееся вместо исходного.
В следующем примере вводится строка символов. Разделителями будем считать символы «;?,. <>”’». Назовем словом любую последовательность символов, ограниченную с одной или с двух сторон разделителями. Требуется удалить слова, состоящие не более, чем из 2 различных символов. Если таких слов нет, то выдать сообщение.
Program delwd;
Uses crt;
const r:set of char= [' ',';',',','<','"','''','>','?','.'];
var s,c:string;
i,ns:byte;
f:boolean;
Begin
Clrscr;
write('s='); readln(s);
i:=1; F:=TRUE;
while i<=length(s) do
Begin
if not(s[i] in r) then
Begin
ns:=i; c:=’’;
while (i<=length(s)) and
not(s[i] in r) do
Begin
if pos(s[i],c)=0 then c:=c+s[i];
Inc(i);
End;
if length(c)<=2 then
Begin
Delete (s,ns,i-ns);
f:=false;
i:=ns-1
End;
End;
i:=i+1
End;
if f then writeln('no')
Else writeln(s);
Readkey
End.
Во вспомогательную строку С выбираются различные буквы во время прохода по слову. Если длина этой строки оказывается меньше или равна 2, слово нужно удалять. После удаления необходимо скорректировать значение переменной основного цикла для выделения очередного слова.
В следующем примере вводится строка символов. Требуется определить, содержит ли данная строка цифры и выдать сообщение об этом. Распечатать имеющиеся в строке цифры.
Program digit;
Uses crt;
Var
cf:set of 0..9;
s:string;
i,k:byte;
Begin
Clrscr;
write('s='); readln(s);
cf:=[ ];
i:=1;
while i<=length(s) do
Begin
k:=ord(s[i])-ord('0');
if k in [0..9] then cf:=cf+[k];
i:=i+1
End;
if cf=[ ] then writeln('no')
Else
Begin
for i:=0 to 9 do
if i in cf then write(i:3);
Writeln
End;
Readkey
End.
Так как цифры имеют последовательные коды, значение самой цифры можно определить, вычитая из кода цифры код цифры 0, что и выполняется в программе. Цифры, обнаруженные в строке, записываются во множество, которое затем выводится на экран.
Описание записи (RECORD).
Запись – это структура данных, состоящая из фиксированного числа компонент, называемых полями. Каждое поле имеет свой идентификатор и тип. К…. . .
END;
Например,
TYPE TA= RECORD
P1 : REAL;
P2 : CHAR;
P3 : BYTE
END;
VAR A: ARRAY[1..10] OF TA;
Здесь описан одномерный массив, каждый элемент которого представляет собой запись, имеющую структуру типа TA.
Запись может объявляться и непосредственно в разделе описания переменных.
VAR C : RECORD
P1 : REAL;
P2 : CHAR;
P3 : BYTE
END;
Рассмотрим пример. Дан массив записей со следующей структурой:
- шифр группы;
- номер зачетной книжки;
- код дисциплины;
- оценка.
Требуется определить средний балл студентов группы ДС101. При вводе массива последняя запись имеет шифр группы «99999».
Program srball;
type zap=record
shg:string[5];
nzk:integer;
kd:1..100;
oc:2..5
End;
var mas:array[1..100] of zap;
k,n,i:byte;
sum:real;
Begin
i:=0;
Repeat
Inc(i);
readln (mas[i].shg, mas[i].nzk, mas[i].kd,
mas[i].oc)
until mas[i].shg='99999';
n:=i; sum:=0; k:=0;
for i:=1 to n do
if mas[i].shg='ДС101' then
Begin
sum:=sum+mas[i].oc;
Inc(k)
End;
if k<>0 then sum:=sum/k;
writeln ('Средний балл в группе ДС-101=',sum)
End.
Оператор присоединения.
При обращении к компонентам записи используются составные имена. Для сокращения имен и повышения удобства работы с записями применяется оператор присоединения WITH.
WITH <идентификаторпеременной типа RECORD> DO
<оператор >;
Тогда в операторе при ссылке на компоненты записи имя переменной можно опускать.
При использовании оператора присоединения фрагмент рассмотренной ранее программы будет выглядеть:
. . .
i:=0;
Repeat
Inc(i);
WITH MAS[I] DO
Readln(shg,nzk,kd,oc)
until mas[i].shg='99999';
n:=i; sum:=0; k:=0;
for i:=1 to n do
WITH MAS[I] DO
if shg='ДС101' then
Begin
sum:=sum+oc;
Inc(k)
End;
. . .
Возможны вложенные описания записи и вложенные конструкции WITH.Рассмотрим пример вложенных описаний. Пусть запись о студентах содержит следующие поля:
- номер по порядку;
- ФИО (содержит в свою очередь поля – фамилия, имя, отчество),
- номер зачетной книжки;
- дата рождения (содержит поля –год, месяц, день).
Тогда в виде графа структуру записи можно изобразить следующим образом:
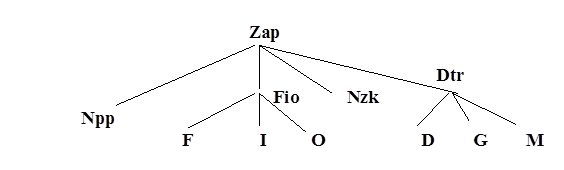
Программа ввода и подсчета количества введенных записей такой структуры может выглядеть:
Uses crt; или uses crt;
type zap=record type zap=record
npp:byte; npp:byte;
fio:record fio:record
f,i,o:string[15]; f,i,o:string[15];
End; end;
nzk:word; nzk:word;
dtr:record dtr:record
g:1970..2000; g:1970..2000;
m:string[3]; m:string[3];
d:1..31 d:1..31
End; end;
End; end;
var a:zap; var a:zap;
k,n:byte; k,n:byte;
Begin clrscr; begin clrscr;
k:=0; k:=0;
With a do with a,fio,dtr do
With fio do repeat
With dtr do inc(k);
repeat writeln('ввод ');
Inc(k); readln(npp);
writeln('ввод '); readln(f);
Readln(npp); readln(i);
Readln(f); readln(o);
Readln(i); readln(nzk);
Readln(o); readln(g);
Readln(nzk); readln(m);
Readln(g); readln(d);
readln(m); until d=99;
Readln(d); writeln(k);
until d=99; readkey
Writeln(k); end.
Readkey
End.
Запись с вариантами.
Состав и структура записи могут динамически меняться в зависимости от значения какого-либо из своих полей, называемого полем-признаком.
В общем виде описание записи с вариантами выглядит так:
TYPE <идентификатор типа>= RECORD
<идентификатор поля 1>:<тип 1>;
<идентификатор поля 2>:<тип 2>;
. . .
CASE <селектор>:<тип селектора> OF
<метка варианта 1>:(<поле варианта 11>:<тип 11>
[;<поле вар-та 12>:<тип 12>;<поле варианта 13>:<тип 13>;. . .]);
<метка варианта 2>:(<поле варианта 21>:<тип 21>
[;<поле вар-та 22>:<тип 22>;<поле варианта 23>:<тип 23>;. . .]);
<метка варианта k>:(<поле варианта k1>:<тип k1>
[;<поле вар-та k2>:<тип k2>;<поле варианта k3>:<тип k3>;. . .]);
. . .
<метка варианта m>:( )
END;
В этом описании вариантная часть записывается после постоянной части, к которой относятся поля 1, 2 . . . , и может быть только одна в записи. Метки варианта должны иметь такой же тип, как у селектора. Если какой-либо метке варианта не соответствуют поля, то записываются пустые круглые скобки, как у метки варианта m.
Пусть требуется описать запись следующей структуры. В каждой записи имеются поля, содержащие табельный номер и фамилию. В зависимости от того, кому принадлежит запись, состав остальных полей может быть разным:
- для студентов поля: номер группы и специальность;
- для преподавателей: институт, кафедра, стаж работы;
- для сотрудников дополнительных полей нет.
В виде графа структуру записей можно изобразить:
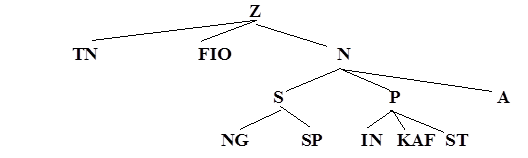
Описание соответствующей записи структуры данных:
type tz=record
tn:byte;
fio:string;
case n:char of
‘p’: ( in:byte; kaf:string; st:byte );
‘s’: ( ng:byte; sp:integer );
‘a’: ( )
End;
var Z:tz;
Вопросы к главе 3.
1. Как описываются множества?
2. Варианты использования множеств.
3. Основные операции над множествами.
4. Способы описания записи.
5. Обращение к компонентам записи.
6. Использование оператора присоединения With.
7. Назначение и общий вид записи с вариантами.
Использование подпрограмм в Турбо Паскале.
Структура программы на языке Паскаль.
Синтаксически программа на языке Паскаль делится на 2 части: заголовок и программный блок. Общий вид заголовка:BEGIN
<исполнительная часть программы> - раздел операторов
END.
Текст программы записывается в виде строк длиной не более 127 символов. В Турбо Паскале порядок следования разделов описаний произвольный и каждый из разделов может повторяться несколько раз или отсутствовать. Раздел операторов (начинается с BEGIN и заканчивается END)состоит из операторов, разделенных точкой с запятой. Исполнительная часть программы является обязательной, может быть единственной частью программы.
Видом работы компилятора можно управлять директивами. Их включают в исходный текст в виде комментариев со специальным синтаксисом. Если процедура или функция хранятся в виде отдельного файла, то для включения их описания в исходный текст программы компилятору задается директива INCLUDE следующего вида:
{$I <имя файла>},
которая должна быть помещена в разделе описаний процедур и функций.
Например,
PROGRAM A1;
VAR ...
{$I B1.PAS}
BEGIN
...
END.
Файл B1.PAS может иметь вид:
PROCEDURE PP;
VAR ...
BEGIN
...
END;
Описание и вызов процедур.
Для реализации многократно повторяющихся участков вычислений и для обеспечения модульности программ в языке Турбо Паскаль предусмотрена возможность… Процедура - это поименованное сложное действие, которое представляет собой… Процедура или функция (общее название - подпрограмма) определяется в разделе описаний основной программы или другой…PR1 (A,B,C,S);
Описание функции.
Функция предназначена для вычисления какого-либо одного значения и используется в выражениях аналогично стандартным функциям. Синтаксис заголовка функции:Writeln ( PRF ( A,B,C));
If PRF ( A,B,C)>20 then K=K+1;
Формальные и фактические параметры.
При описании процедуры (функции) в ее заголовке могут быть указаны параметры следующих видов: - параметры-значения; - параметры-переменные;...
Procedure TOP ( A:TM; Var B: TV ; N: integer);
...
Здесь описаны два типа массивов. TV – для одномерного массива и TM для двумерного массива. Затем в списке формальных параметров для переменных А и В используются эти ранее определенные типы при описании соответственно матрицы и вектора.
Список параметров, задаваемых в заголовке процедуры или функции, обеспечивает связь подпрограммы с вызывающей программой. Через него в подпрограмму передаются исходные данные и возвращается результат (в процедуре). В языке Турбо Паскаль предусмотрены два принципиально отличающихся механизма передачи параметров : по значению и по ссылке.
Параметры-значения.
Параметры-переменные.
В качестве параметров-переменных могут быть использованы массивы и строки…Begin
S:=0;
For I:=0 to HIGH(A) do
S:=S+A[I];
Sum:=S;
End;
В основной программе такой массив может быть описан даже как
Var A: array [ -2 .. 3] of integer; Фактические границы массива здесь значения не имеют. Важно только то, что количество элементов массива в данном случае равно 6.
Открытая строка может задаваться с помощью стандартного типа OPENSTRING и стандартного типа STRING с использованием директивы компилятора {$P+} .
Например,
Procedure ZAP ( Var St : openstring; R: integer );
или
{$P+}
Procedure ZAP ( Var St : string; R: integer );
В языке Турбо Паскаль можно устанавливать режим компиляции, при котором отключается контроль за совпадением длины формального и фактического параметра строки {$V- }. При передаче строки меньшего размера формальный параметр будет иметь ту же длину, что и параметр обращения; при передаче строки большего размера происходит усечение до максимального размера формального параметра. Контроль включается только при передаче параметров-переменных , для параметров - значений длина не контролируется.
Рассмотрим пример, в котором используются процедура и функция. Требуется написать процедуру, в которой для матрицы, содержащей M столбцов и N строк, необходимо составить вектор номеров столбцов, все элементы которых упорядочены по возрастанию или убыванию и являются простыми числами. В главной программе вводятся все входные данные, производится обращение к процедуре и осуществляется вывод полученных результатов.
Uses crt;
tvect=array[1..100] of word; Var a:tmas; v:tvect;Begin
If b<>1 then pros:=true
else pros:=false;
For i:=2 to b div 2 do
If b mod i = 0 then pros:=false;
End;
Begin
k:=0;
For j:=1 to m do
Begin
z:=0; s:=0; f:=true;
For i:=1 to n-1 do
Begin
If x[i,j]>x[i+1,j] then z:=z+1;
If x[i,j]<x[i+1,j] then s:=s+1
End;
If (z = n-1) or (s = n-1) then
Begin
For i:=1 to n do
If not(pros(x[i,j])) then f:=false;
If f then
Begin
k:=k+1; r[k]:=j
End;
End;
End;
End;
Begin
Writeln('Введите N и M:');
Readln(n,m);
Writeln('Введите матрицу:');
For i:=1 to n do
For j:=1 to m do
Readln(a[i,j]);
FORM(a,n,m,v,k);
Writeln('Результат:');
For i:=1 to k do
Write(v[i],' ');
Readkey
End.
В этом примере в процедуру передаются входные данные: двумерный массив и его размерность. Массив передается как параметр-переменная, чтобы в процедуре не выделялась память для его копии. Результаты: вектор и его размерность обязательно передаются как параметры-переменные. Функция проверки простого числа является внутренней для процедуры и недоступна из главной программы.
Параметры-константы.
PROCEDURE<имя процедуры> (CONST <имя константы>: <тип>; ...);Параметры-процедуры и параметры-функции.
Для объявления процедурного типа используется заголовок подпрограммы, в котором опускается имя процедуры (функции).
Например:
Type
TPR1= Procedure( X,Y : real; Var Z : real);
TPR2= Procedure ;
TF1= Function: string;
TF2=Function ( Var S: string) : real;
Ниже приведен пример использования функции FF в качестве параметра другой функции RR.
Uses CRT;
Type FUN=Function (X,Y: real): real;
Var ...
Function FF (X,Y: real): real; FAR;
...
Begin ... End;
Function RR (X,Y: real; F : Fun): real; FAR;
...
Begin ... End;
Procedure TP (Var Z : real; X,Y: real;
Const R: integer);
...
Begin ... End ;
Begin
... Z:=RR(3 , 1 , FF);
TP (Z,X,Y,R);
...
End .
В этом примере используются:
X,Y - параметры-значения;
Z - параметр-переменная;
F- параметр-функция;
R- параметр-константа.
Область действия имен.
Любая подпрограмма представляет собой блок со своей областью описаний. Она может содержать внутри этого блока описания других процедур и функций, а…Процедуры и функции без параметров.
В случае использования процедур и функций без параметров связь данных осуществляется через глобальные переменные. Подпрограммы должны быть, по возможности, независимы от основной программы, поэтому все переменные , нужные только в…Рекурсивные процедуры и функции.
Рекурсия- это способ организации вычислительного процесса, при котором процедура или функция в процессе выполнения входящих в ее состав операторов… Рекурсия может быть прямой или косвенной. При прямой рекурсии оператор вызова подпрограммы содержится непосредственно…Program Main;
Var M: integer;
F:real;
Function FACT (N:integer): real;
Begin
If N=1 then
FACT:=1
Else
FACT:= N* FACT(N-1);
End;
Begin
Readln(M);
F:= FACT ( M );
Writeln (' M!=', F);
End.
b) Рекурсивная процедура
Program Main;
Var M: integer;
F:real;
Procedure FACT(N:integer; Var F: real);
Var Q : real;
Begin
If N=1 then Q:=1
Else FACT(N-1,Q);
F:=N*Q;
End;
Begin
Readln(M);
FACT ( M, F );
Writeln (' M!=', F);
End.
B варианте а) при м=4 выполняются следующие действия:
FACT:=4*FACT(3); FACT:=3*FACT(2); FACT:=2*FACT(1); FACT(1):=1.
При входе в функцию в первый раз отводится память под локальную переменную, соответствующую параметру-значению; ей присваивается значение фактического параметра (М). При каждом новом обращении строятся новые локальные переменные. Так как FACT(1)=1, то выполнение функции заканчивается. После этого выполняются действия:
FACT(1):=1; FACT:=2*FACT(1);
FACT(2):=2; FACT:=3*FACT(2);
FACT(3):=3*2=6; FACT:=4*FACT(3); т.е. FACT=24.
Предварительно-определенные процедуры.
При косвенной рекурсии одна подпрограмма вызывает другую, которая либо сама, либо посредством других подпрограмм вызывает исходную. В этом случае… Например:Program KOSV_R;
Var X,Y: integer;
Procedure LR ( A : integer); FORWARD;
Procedure TT (B: integer);
...
Begin
...
LR (...);
...
End;
Procedure LR ;
...
Begin
...
TT(...) ;
...
End;
Begin
...
TT(X) ;
LR(Y) ;
...
End.
В этом примере одна процедура вызывает другую, а вторая вызывает первую. При такой схеме взаимодействия процедур невозможно описать обе процедуры так, чтобы обращение к ним следовало после описания, как требует Паскаль. Для разрешения противоречия используется предварительное описание одной из процедур.
Модули.
Процедуры и функции могут быть сгруппированы в отдельный модуль. Модуль (unit)- это программная единица, текст которой компилируется автономно… Структура модуля отличается от структуры обычной программы на языке Турбо Паскаль. Модули имеют четыре основные части:…INTERFACE
TYPE<описание типов, определенных в данном модуле и доступных для других модулей>; CONST<описание констант, определенных в данномIMPLEMENTATION
TYPE<описание типов, определенных в данном модуле и недоступных для других модулей>; CONST<описание констант, определенных в данномEND.
Интерфейсная и реализационная части могут быть пустыми, но присутствовать должны обязательно. При подключении модуля вначале выполняются операторы секции инициализации (если они имеются), а затем операторы основного блока главной программы, в которую включен данный модуль.
Рассмотрим пример. Требуется написать главную программу, в которой вводится размер вектора и его элементы и вызывается процедура сортировки одномерного массива целых чисел в порядке возрастания. Длина массива не превышает 100. Процедуру оформить в виде модуля.
Uses Crt,Modsort;
Var A:mas;
I:byte;
N:byte;
Begin
Writeln('Ввод исходных данных:');
Readln(N);
For I:=1 to N do
Readln(A[I]);
SORT(A,N);
For I:=1 to N do
Writeln(A[I]);
Readkey
End.
Первым предложением программы является Uses,в котором подключается стандартный модуль Crt и модуль Modsort, где находится процедура сортировки.
Кроме того, тип, с которым описывается массив, отсутствует в главной программе, т.к. он присутствует в модуле.
Unit Modsort;
Interface
Type mas=array[1..100] of integer;
Procedure SORT(Var A:mas; N:byte);
Implementation
Procedure SORT;
Var I,J:byte;
X:integer;
Begin
For J:=1 to N-1 do
For I:=1 to N-J do
If A[I]>A[I+1] then
Begin
X:=A[I]; A[I]:=A[I+1]; A[I+1]:=X
End;
End;
End.
В интерфейсной части модуля описан тип masи заголовок процедуры сортировки. При подключении этого модуля с помощью предложения Usesвлюбой программе становятся доступными рассматриваемые тип и процедура. Это продемонстрировано в главной программе.
Вопросы к главе 4.
1. Назначение процедур и функций. 2. Возможность подключения процедур и функций с помощью опции компилятора. … 3. Описание заголовка процедуры.Стандартные процедуры и функции.
· SYSTEM – включает стандартные процедуры и функции языка; при использовании этого модуля его не требуется подключать с помощью USES, так как он… · DOS – содержит процедуры и функции для взаимодействия с MS DOS; · CRT - объединяет процедуры и функции для работы с экраном в текстовом режиме и клавиатурой;Математические функции.
При необходимости вычисления некоторых математических функций, для которых не существует стандартных функций в языке Турбо Паскаль, их выражают… tg(X)=Sin(X)/Cos(X)Функции округления и преобразования типов.
Функции порядкового типа.
Процедуры порядкового типа.
Строковые функции.
Для функции Concat общая длина полученной строки не должна превышать 256 байт.… Для функции Copy, если позиция в строке превышает длину этой строки, то результатом будет пустая строка. Если…Строковые процедуры.
Для процедуры Delete,если <позиция> больше длины строки, то строка не…Прочие процедуры и функции.
Процедуры ввода данных.
Ввод данных в языке Турбо Паскаль выполняется стандартными процедурами (операторами) READ или READLN, вывод - процедурами WRITE или WRITELN.… Вызов процедуры READ имеет следующий вид:Begin
For J:=1 to 3 do
Read (A[I,J]);
Readln
End;
Входной поток: 3 5 1
-4 7 9
2) For I:=1 to 2 do
For J:=1 to3 do
Read (A[I,J]);
Входной поток: 3 5 1
-4 7 9
3) For I:=1 to 2 do
For J:=1 to 3 do
Readln(A[I,J]);
Входной поток: 3
-4
В следующем примере наглядно показано, что при использовании READLNданные, находящиеся в конце строки, игнорируются.
Var A,B,C,D:integer;Входной поток:
1 строка: 10 20 30 40 50
…2 строка:60
Readln(A,B,C);
Readln(D);Результат:
A=10;B=20;C=30;D=60
Процедуры вывода данных.
Процедура (оператор) WRITEпредназначена для вывода выражений следующих типов: Integer, Byte, Real, Char, String, Boolean и др. WRITE ([<имя файла или устройства>,]Особенности вывода вещественных значений.
Если описать переменную вещественного типа, то возможны следующие варианты вывода этой переменной: 1) Write(R); Вывод осуществляется в нормализованном виде (экспоненциальная форма):. . .
A:=’книга’;
B:=1253E-5;
C:=12;
d:=1253E2;
Write(LST,’B=’,B:10:3,’ C=’,C:8,’ A=’,A:7,’ b1=’,b:8,’ d=’,d:6);
На печать будет выведено (здесь _ означает символ пробел, который на экране не виден):
В=_ _ _ _ _ 0.013_С=_ _ _ _ _ _12_А=_ _книга_B1=_1.3E-02_D=_1.3E+05
Процедура WRITELNимеет аналогичный вид:
WRITELN ([<имя файла или устройства>,]<список выражений>);
При вызове этой процедуры завершается формирование текущей строки файла. Следующий оператор WRITEилиWRITELN формирует новую строку. Можно использоватьWRITELN без параметров.
Например, при совместном использовании операторов WRITE иWRITELNможно регулировать вывод по строкам:
Var A,B,C,D,E:integer;
Begin
A:=1; B:=2; C:=3; D:=4; E:=5;
Writeln (‘ A=’,A,’ B=’,B);
Write(‘ C=’,C);
Writeln(‘ D=’,D,’ E=’,E);
End.
На экран дисплея результат будет выведен в двух строках:
_A=1_B=2
_C=3_D=4_E=5
Вывод матрицы A (M,N) целых чисел на экран в виде прямоугольной таблицы можно реализовать следующими операторами:
. . .
For I:=1 to M do
Begin
For J:=1 to N do
Write(A[I,J]:5);
Writeln
End;
Вывод матрицы A(M,N) вещественных чисел на принтер в виде таблицы с одним разрядом после запятой представлен следующей программой:
Uses Printer;
Var A:array[1..10,1..10]of real;
M,N:integer;
Begin
Readln(M,N);
For I:=1 to M do
For J:=1 to N do
Read(A[I,J]);
For I:=1 to M do
Begin
For J:=1 to N do
Write(Lst,A[I,J]:6:1);
Writeln(Lst)
End;
Readkey
End.
Вопросы к главе 5.
2. Назначение основных стандартных модулей. 3. Особенности математических функций. 4. Особенности использования процедур для работы со строковыми данными.Работа с файлами.
Общие сведения о файлах.
При обработке на компьютере информация может храниться на внешних носителях в виде файлов. Файл на носителе – это поименованная совокупность логически связанных между собой данных (записей), имеющая определенную организацию и общее назначение.
Физическая запись – это совокупность данных, передаваемых в том или обратном направлении при одном обращении к внешнему носителю (т.е. минимальная единица обмена данными между внешней и оперативной памятью). Физическая запись состоит из логических записей.
Логическая запись – единица данных, используемая в операторах чтения и записи файлов. Логические записи объединяются в физическую запись для уменьшения числа обращений к внешнему устройству.
Для обращения к записям файла на внешнем носителе используется понятие логического файла. Логический файл или файл в программе – это совокупность данных, состоящая из логических записей, объединенных общим назначением.
Для связи файла в программе и файла на внешнем носителе используется процедура ASSIGN, где указывается имя файла в программе и имя файла на внешнем носителе.
Число записей файла произвольно, но в каждый момент времени доступна только одна запись. Длиной файла называют количество записанных компонент. Файл, не содержащий записей, называется пустым.
Каждая переменная файлового типа должна быть описана в разделе описания переменных var .Не допускается использование таких переменных в выраженияхи операторах присваивания. Тип компонент файла может быть любым кроме файлового.
В Турбо Паскале предварительно определен следующий стандартный тип:
TYPE TEXT = FILE OF CHAR;
В системе программирования Паскаль различаются 3 вида файлов:
· файлы с типом записей (типизированные файлы);
· текстовые файлы со строками неопределенной длины;
· файлы без типа для передачи данных блоками записей.
При работе с файлами необходимо придерживаться следующих общих правил:
 все имена файлов могут быть указаны в заголовке программы;
все имена файлов могут быть указаны в заголовке программы;
текстовые файлы должны быть описаны с типом TEXT;
каждый файл в программе должен быть закреплен за конкретным файлом на носителе процедурой ASSIGN;
открытие существующего файла для чтения, корректировки или дозаписи производится процедурой RESET,открытие создаваемого файла для записи – процедурой REWRITE;
по окончании работы с файлом он должен быть закрыт процедурой CLOSE.
Процедуры и функции для работы с файлами.
ASSIGN (<имя файла>,<имяфайла на носителе>) –процедура устанавливает связь между именем файловой переменной и именем файла на носителе.… RESET(<имя файла>) –процедура открытия существующего файла для чтения… REWRITE(<имя файла>) –процедура открытия создаваемого файла для записи. Если файл с таким именем уже…Особенности обработки типизированных файлов.
Файл с типом (типизированный файл) состоит из последовательности записей одинаковой длины и одинакового внутреннего формата. Записи следуют… При последовательном доступе записи располагаются на внешнем носителе… При прямом доступе предполагается, что данные располагаются в определенных областях, имеющих последовательные номера,…END;
VAR DAN: FILE OF ST;
В первом варианте тип файла описан в разделе описания типов, а затем в разделе описания переменных файловая переменная получает этот тип, во втором варианте тип предварительно не описывается. В третьем варианте предварительно описывается тип записи файла, а в разделе описания переменных этот тип используется для указания типа отдельной записи.
Процедуры чтения и записи для файлов с типом READ и WRITE. Кроме того, используются процедуры и функции ASSIGN, RESET, REWRITE, SEEK, CLOSE, FILEPOS, FILESIZE, EOF. Процедура TRUNCATEобрезает файл на заданной файловой позиции.
Пусть требуется создать файл из записей, данные которых вводятся с клавиатуры. После создания файла содержимое файла вывести на экран.
Структура записи файла следующая:
- фамилия;
- табельный номер;
- заработная плата.
type tz=record
fio:string[10];
tn:integer;
zp:real
End;
var zap:tz;
fout:file of tz;
fl:boolean;
name:string;
Begin
Repeat
writeln('имя файла ');
Readln(name);
Assign (fout,name);
{$i-} reset(fout); {$i+}
if ioresult=0 then
Begin
writeln('файл ',name,' уже есть');
Close(fout);
fl:=false
End
Else
Begin
Rewrite(fout);
fl:=true
End
Until fl;
With zap do
Repeat
writeln('ввод fio,tn,zp');
Readln(input,fio,tn,zp);
Write(fout,zap);
Until eof(input);
Close(fout);
Reset(fout);
With zap do
Repeat
Read(fout,zap);
writeln(fio:15,tn:9,zp:8:2);
Until eof(fout);
Close(fout)
End.
В начале программы выполняется ввод имени файла до тех пор, пока не будет введено имя несуществующего файла, т.к. в противном случае старый файл будет уничтожен и данные будут утеряны. После ввода нового имени флаг FLстановится равным TRUEи цикл ввода имени файла прекращается. После этого начинается непосредственно цикл ввода данных с клавиатуры из файла INPUT . Признак конца ввода Ctrl+Z. Стандартное имя файла ввода с клавиатуры INPUTможно опустить и в операторе чтения из файла readln, и в функции проверки конца ввода eof. После создания файла и ввода всех данных файл закрывается процедурой close. Затем созданный файл открывается для чтения, данные из него читаются и выводятся на экран в виде таблицы.
Файл может расширяться путем включения последующих элементов за последним существующим элементом файла. Для этого используется процедура позиционирования:
SEEK(<имя файла>, FILESIZE(<имя файла>)).
В следующей программе, используя прямой доступ к записям файла, созданного в предыдущей программе, требуется подсчитать сумму зарплаты рабочих, чьи табельные номера вводятся с клавиатуры (предполагается, что при создании файла были использованы табельные номера в интервале 101-999 и запись с номером 101 занимает первое место в файле, за ней следует запись с табельным номером 102 и т.д.).
type tz=record
fio:string[10];
tn:integer;
zp:real
End;
var zap:tz;
fout:file of tz;
tn1,tn2,n:integer;
s:real;
name:string;
Begin
writeln('имя файла ');
Readln(name);
Assign (fout,name);
Reset(fout);
s:=0;
Repeat
Readln(tn2);
tn1:=tn2-101; {формирование указателя записи}
Seek(fout,tn1);
Read(fout,zap);
s:=s+zap.zp;
Until eof;
writeln(‘s= ‘,s);
Close(fout)
End.
В этой программе процесс обработки заканчивается, когда прекращается ввод табельных номеров, подлежащих обработке, т.е. Ctrl+Z для файла ввода с клавиатуры.
Особенности обработки текстовых файлов.
Текстовые файлы состоят из символов. Каждый текстовый файл разделяется на строки неопределенной длины, которые заканчиваются символом конец строки.… К текстовым файлам возможен только последовательный доступ. С текстовыми…Readln(name);
Assign(f1,name);
write(‘ввод имени выходного файла:’);
Readln(name);
Assign(f2,name);
Reset(f1); rewrite(f2);
While not eof(f1) do
Begin
Readln(f1,pole);
while pos(‘дс-101’, pole) <> 0 do
Begin
pz:= pos(‘дс-101’, pole);
delete(pole,pz+3,1);
insert(‘2’,pole,pz+3);
End;
Writeln(f2,pole)
End;
Close(f1);
Close(f2);
End.
Здесь читаются последовательно строки из входного файла и в каждой строке в номере группы заменяется символ 1 на 2. Скорректированные строки выводятся в новый файл.
Файлы без типа.
Файлы без типа используются обычно при копировании файлов, когда не важна внутренняя структура записи файла. Если длина сегмента на диске 1024… Обмен информацией происходит непосредственно между программой и файлом без… Для работы с такими файлами предусмотрены специальные процедуры, позволяющие производить обмен группами блоков по 128…Var
FromF, ToF: file;
NR, NWr: Word;
NAME:STRING[12];
Buf: array[1..2048] of Char;
Begin
WRITE(‘ИМЯ ВХ.ФАЙЛА’);
READLN(NAME);
Assign(FromF, NAME);
WRITE(‘ИМЯ ВЫХ.ФАЙЛА ’);
READLN(NAME);
Assign(ToF,NAME);
Reset(FromF, 1);
Rewrite(ToF, 1);
Repeat
BlockRead(FromF, Buf, SizeOf(Buf), NR);
BlockWrite(ToF, Buf, NR, NWr);
until (NR = 0) or (NWr <> NR);
Close(FromF);
Close(ToF);
End.
В примере программы при открытии файла без типа в вызове процедуры RESETуказана длина записи равная 1. В этом случае при копировании файла не будут записаны лишние символы в новый файл.
Проектирование программ по структурам данных
Проектирование программ по структурам данных можно считать одним из самых зрелых и продвинутых направлений в индустриальном отношении. Использование диаграмм Варнье, Джексона и МЭСИД для проектирования программ… Все эти подходы основываются на создании диаграмм структур выходных и входных данных, определении несоответствий в них…Работа с файлами при обработке экономической информации
Постановка задачи.
Пусть для системы обработки данных требуется написать программу одновременного формирования трех ведомостей о начислении заработной платы для… На рис.7 показан фрагмент диаграммы потоков данных, из которого видно, что требуется получить три ведомости, названные…Проектирование программы.
Для проектирования программы будем использовать подход МЭСИД. Процесс проектирования начинается с составления диаграмм структур выходных данных. Они…Кодирование программы.
Текст программы приводится на рис.15. Таким образом из рассмотренного примера видно, что использование языка Паскаль в сочетании с методологиями…End;
tr=record
c:string[4];
m:string[30];
g:byte
End;
top=record
e:string[10];
p:word;
ei:string[2]
End;
tp=record
a:string[2];
x:string[25];
ph:string[7];
End;
var fn:file of tn; zn:tn;
fo:file of top; zo:top;
fr:file of tr; zr:tr;
fp:file of tp; zp:tp;
v1,v2,v3:text;
s0,sa,sb,sc,kod,chi:integer;
f:boolean;
a1,b1,bp:string[2];
c1:string[4];
nd:string;
ch:char;
Begin
write('имя осн.файла='); readln(nd);
Assign(fn,nd);
write('имя файла раб.='); readln(nd);
Assign(fr,nd);
write('имя файла опер.='); readln(nd);
Assign(fo,nd);
write('имя файла подр.='); readln(nd);
Assign(fp,nd);
assign(v1,'v1'); rewrite(v1);
assign(v2,'v2'); rewrite(v2);
assign(v3,'v3'); rewrite(v3);
writeln(v1,' Ведомость 1');
writeln(v1,' Цех Участок Таб.номер ',
Начислено');
writeln(v2,' Ведомость 2');
writeln(v3,' Ведомость 3');
writeln(v3,' Цех Название ',
Начислено');
s0:=0; f:=true;
Reset(fn); read(fn,zn);
Reset(fp); reset(fr);
While f do
Begin
a1:=zn.a; sa:=0;
zp.x:=' '; val(a1,chi,kod);
Seek(fp,chi-1); read(fp,zp);
writeln(v2,'Цех ',a1:3,' ',zp.x:25);
writeln(v2,'Участок Т.ном. ФИО',
' Начислено');
while f and(a1=zn.a) do
Begin
b1:=zn.b; bp:=b1; sb:=0;
while f and(a1=zn.a)and(b1=zn.b) do
Begin
c1:=zn.c; sc:=0;
zr.m:=' '; val(c1,chi,kod);
Seek(fr,chi-1); read(fr,zr);
while f and(a1=zn.a)and(b1=zn.b)and
(c1=zn.c) do
Begin
reset(fo); zo.p:=0;
Repeat
Read(fo,zo);
until eof(fo) or (zn.e=zo.e);
Close(fo);
sc:=sc+zo.p*zn.k;
If not eof(fn) then read(fn,zn)
else f:=false;
End;
writeln(v1,a1:5,b1:8,c1:10,sc:10);
writeln(v2,bp:5,c1:7,' ',zr.m:30,
sc:3);
bp:='';
sb:=sb+sc;
End;
writeln(v1,' по участку',
sb:5);
writeln(v2,' ',
'по участку', sb:5);
sa:=sa+sb;
End;
writeln(v1,' по цеху',
sa:5);
writeln(v2,' ',
' по цеху', sa:5);
writeln(v3, a1:6,zp.x:30,sa:5);
s0:=s0+sa;
End;
writeln(v1,' ',
'всего',s0:5);
writeln(v2,' ',
' всего',s0:5);
Close(v1); close(v2); close(v3); close(fn);
End.
Рис.15 Текст программы.
Вопросы к главе 6.
2. Какие типы файлов существуют в Турбо Паскале ? 3. Как организовать прямой доступ к типизированным файлам ? 4. Особенности работы с типизированными файлами.Динамическая память.
В предшествующих разделах использовались переменные, память под которые выделялась статически, то есть на стадии компиляции. Эти области памяти (для… Исправить положение можно, применив специальный механизм распределения памяти.… Можно отметить следующие достоинства динамической памяти:Указатель.
Обращение к участку динамической памяти в программе осуществляется с помощью специальной ссылочной переменной, которая называется указателем… Переменная типа «указатель» содержит адрес размещения участка динамической… Формат описания типа «указатель» следующий:Type
{правильные объявления типов}
p1=^word;{ p1 - идентификатор типа «указатель» на данные типа word.}
p2=^char; { p2 - идентификатор типа «указатель» на данные типа char}
p4=array[1..10] of ^real; {p4 - идентификатор типа «указатель» на массив указателей, ссылающихся на данные типа real}
{неправильные объявления типов}
p5=^array[1..10] of real;
p6=^string[25];
p7=^record
field1 : string [15];
field2 : real;
End;
В формате объявления типа «указатель» должен быть указан идентификатор типа, поэтому стандартные идентификаторы (integer, real и т.д.) можно указывать непосредственно в описаниях типа «указатель». Ошибки в описаниях типов p5, p6 и p7 будут отмечены компилятором из-за того, что, в таких случаях надо прежде описать идентификатор типа, а затем использовать его в других описаниях.
Следующие описания будут правильными:
Type
...
mas = array[1..10] of real;
st = string[25];
rec = record
field1 : string [15];
field2 : real;
End;
Var
p5 : ^mas;
p6 : ^st;
p7 : ^rec;
...
Указатель может находиться в одном из трех состояний, а именно:
1) еще не инициализирован;
2) содержит адрес размещения;
3) содержит значение предопределенной константы nil; такой указатель называется пустым, то есть не указывает ни на какую переменную. Указатель со значением nilсодержит 0 в каждом из четырех байтов.
Указатели можно сравнивать с другими указателями ( =, <> ), присваивать им адрес или значение другого указателя, передавать как параметр. Указатель нельзя отпечатать или вывести на экран.
Обращение к выделенной динамический памяти кодируется следующим образом:
<идентификатор указателя>^
Рассмотрим пример обращения к переменным, размещенным в динамической памяти:
Type
sym=^char;
zap=record
field1, field2: real;
End;
m=array[0..9] of word;
Var
ch : sym;
rec : ^zap;
mas : ^m;
...
ch^:='*'; {обращение к динамической переменной типа char, запись в эту область символа звездочка}
...
Readln (rec^.field1); {обращение к полю field1 динамической записи, ввод в него данных с клавиатуры }
...
Writeln ( mas[5]^); {обращение к элементу mas[5] динамического массива, вывод на экран значения указанного элемента}
...
Фактически можно говорить, что ch^, rec^.field1иmas[5]^ исполняют роль имён динамических объектов в программе, адреса которых хранятся в указателях сh, rec и mas соответственно.
Следует отметить, что обращение к переменным типа pointer (указателям, которые не указывают ни на какой определенный тип и совместимы со всеми другими типами указателей) приводит к ошибке.
Например.
Var
p:pointer;
...
p^:=1; {ошибка!}
Стандартные процедуры размещения и освобождения динамической памяти.
При выполнении программы наступает момент, когда необходимо использовать динамическую память, т.е. выделить её в нужных видах, разместить там какие-то данные, поработать с ними, а после того, как в данных отпадет необходимость - освободить выделенную память.
Динамическая память может быть выделена двумя способами:
1. С помощью стандартной процедуры New:
New (P);
Эта процедура создает новую динамическую переменную (выделяет под нее участок памяти) и устанавливает на нее указатель P (в P записывается адрес… 2. С помощью стандартной процедуры GetMem.GetMem (P,size);
где P - переменная типа «указатель» требуемого типа.
size - целочисленное выражение размера запрашиваемой памяти в байтах.
Эта процедура создает новую динамическую переменную требуемого размера и свойства, а также помещает адрес этой созданной переменной в переменную Ртипа «указатель». Доступ к значению созданной переменной можно получить с помощью P^.
Например:
Type
Rec =record
Field1:string[30];
Field2:integer;
End;
ptr_rec = ^ rec;
Var
p : ptr_rec;
Begin
GetMem(Р, SizeOf (Rec)); { Выделение памяти, адрес выделенного участка фиксируется в Р; размер этой памяти в байтах определяет и возвращает стандартная функция SizeOf, примененная к описанному типу данных; однако, зная размеры внутреннего представления используемых полей, можно было бы подсчитать размер памяти «вручную» и записать в виде константы вместо SizeOf (Rec) }
...
{использование памяти}
...
FreeMem(p, SizeOf(Rec)); {освобождение уже ненужной памяти}
...
Динамическая память может быть освобождена четырьмя способами.
1. Автоматически по завершении всей программы.
2. С помощью стандартной процедуры Dispose.
Dispose (P);
В результате работы процедуры Dispose(P) участок памяти, связанный с указателем P, помечается как свободный для возможных дальнейших размещений. При… Ввиду различия в способах реализации процедуру Dispose не следует использовать совместно с процедурами Markи…FreeMem (P, size);
где P - переменная типа «указатель»,
size - целочисленное выражение размера памяти в байтах для освобождения.
Эта процедура помечает память размером, равным значению выражения size, связанную с указателем P, как свободную (см. пример для GetMem).
4. С помощью стандартных процедур Маrk и Release.
Mark (P);
Release (P);
Mark - запоминает состояние динамической области в переменной-указателе р; Release - освобождает всю динамическую память, которая выделена процедурами… Обращения к Markи Release нельзя чередовать с обращениями к Dispose и FRееМеm ввиду различий в их реализации.Var
p:pointer;
p1, p2, p3:^integer;
Begin
New(p1);
p1^ := 10;
Mark(p); {пометка динамической области}
New(p2);
p2^ := 25;
New(p3);
p3^ := p2^ + p1^;
Writeln ( p3^);
Release(p); {память, связанная с p2^ и p3^, освобождена, а p1^ может использоваться}
End.
Стандартные функции обработки динамической памяти.
В процессе выполнения программы может возникнуть необходимость наблюдения за состоянием динамической области. Цель такого наблюдения - оценка возможности очередного выделения динамической области требуемого размера. Для этих целей Турбо Паскаль предоставляет две функции (без параметров).
MaxAvail;
Эта функция возвращает размер в байтах наибольшего свободного в данный момент участка в динамической области. По этому размеру можно судить о том, какую наибольшую динамическую память можно выделить.
Тип возвращаемого значения - longint.
type zap=record
field1: string [20];
field2: real;
End;
var p: pointer;
Begin
...
if MaxAvail <SizeOf(zap)
Then
Writeln ('He хватает памяти!')
Else
GetMem(р, SizeOf(zap));
...
Вторая функция:
MemAvail;
Эта функция возвращает общее число свободных байтов динамической памяти, то есть суммируются размеры всех свободных участков и объем свободной динамической области. Тип возвращаемого значения - longint.
...
Writeln( 'Доступно', MemAvail, 'байтов' );
Writeln('Наибольший свободный участок=', MaxAvail, 'байтов' );
...
Это решение основано на следующем обстоятельстве. Динамическая область размещается в специально выделяемой области, которая носит название «куча» (heap). Куча занимает всю или часть свободной памяти, оставшейся после загрузки программы. Размер кучи можно установить с помощью директивы компилятора М:
{$М<стек>, <минимум кучи>, <максимум кучи>}
где <стек>- специфицирует размер сегмента стека в байтах. По умолчанию размер стека 16 384 байт, а максимальный размер стека 65 538 байт;
<минимум кучи> - специфицирует минимально требуемый размер кучи в байтах; по умолчанию минимальный размер 0 байт;
<максимум кучи> - специфицирует максимальное значение памяти в байтах для размещения кучи; по умолчанию оно равно 655 360 байт, что в большинстве случаев выделяет в куче всю доступную память; это значение должно быть не меньше наименьшего размера кучи.
Все значения задаются в десятичной или шестнадцатеричной формах. Например, следующие две директивы эквивалентны:
{$М 16384,0,655360}
{$M $4000, $0, $A000}
Если указанный минимальный объем памяти недоступен, то программа выполняться не будет.
Управление размещением в динамической памяти осуществляет администратор кучи, являющийся одной из управляющих программ модуля System.
Примеры и задачи.
Рассмотрим пример размещения и освобождения разнотипных динамических переменных в куче.
Type
st1=string[7];
st2=string[3];
var i,i1,i2,i3,i4:^integer;
r^:real;
s1:^st1;
s2:^st2;
Begin
New(i);
i1^:=1;
New(i2);
i2^:=2;
New(i3);
i3^=3;
New(i4);
Disроsе (i2);{освобождается второе размещение} New (i); {память нужного размера (в данном случае два байта) выделяется на… i^:=5; (*2*)END.
В следующем примере используется массив указателей.
Uses Crt;
Var
r: array [1..10] of ^real;
i:1..10;
Begin
Randomize; {инициализация генератора случайных чисел}
for i:=1 to 10 do
Begin
New(r[i]);
r[i]^:=Random; {генерация случайных вещественных чисел в диапазоне 0 <= r[i]^ < 1}
writeln(r[i]^);{Вывод случайных чисел в экспоненциальной форме}
End;
End.
Работа с динамическими массивами.
При работе с массивами практически всегда возникает задача настройки программы на фактическое количество элементов массива. В зависимости от применяемых средств решение этой задачи бывает различным.
Первый вариант -использование констант для задания размерностимассива.
Program First;
Const
N : integer = 10;
{ либо N = 10; }
Var
A : array [ 1..N ] of real;
I : integer;
Begin
For i := 1 to N do
Begin
Writeln ('Введите', i , '-ый элемент массива');
Readln ( A [ i ] )
End;
{ И далее все циклы работы с массивом используют N}
Такой способ требует перекомпиляции программы при каждом изменении числа обрабатываемых элементов.
Второй вариант - программист планирует некоторое условно максимальное (теоретическое) количество элементов, которое и используется при объявлении массива. При выполнении программа запрашивает у пользователя фактическое количество элементов массива, которое должно быть не более теоретического. На это значение и настраиваются все циклы работы с массивом.
Program Second;
Var
A : array [ 1..25 ] of real;
I, NF : integer;
Begin
Writeln ('Введите фактическое число элементов’,
‘ массива <= 25');
Readln ( NF );
For i := 1 to NF do
Begin
Writeln ('Введите ',i, ' -ый элемент массива');
Readln ( A [ i ] )
End;
{ И далее все циклы работы с массивом используют NF}
Этот вариант более гибок и технологичен по сравнению с предыдущим, так как не требуется постоянная перекомпиляция программы, но очень нерационально расходуется память, ведь ее объем для массива всегда выделяется по указанному максимуму. Используется же только часть ее
Вариант третий - в нужный момент времени надо выделить динамическую память в требуемом объеме, а после того, как она станет не нужна, освободить ее.
Program Dynam_Memory;
Type
Mas = array [ 1..2 ] of <требуемый_тип_элемента>;
Ms = ^ mas;
Var
A : Ms;
I, NF : integer;
Begin
Writeln ('Введите фактическое число элементов массива');
Readln ( NF );
GetMem ( A, SizeOf ( <требуемый_тип_элемента>)*NF);
For i := 1 to NF do
Begin
Writeln ('Введите ', i , ' -ый элемент массива ');
Readln ( A^ [ i ] )
End;
{ И далее все циклы работы с массивом используют NF}
. . . . .
FreeMem (a, nf*SizeOf (<требуемый_тип_элемента>));
End.
Рассмотрим пример использования динамического одномерного массива, который используется как двумерный массив. После ввода реальной размерности массива и выделения памяти для обращения к элементу двумерного массива адрес его рассчитывается, исходя из фактической длины строки и положения элемента в строке (при заполнении матрицы по строкам). Требуется найти максимальный элемент в матрице и его координаты.
Uses crt;
type t1=array[1..1] of integer;
Var
a:^t1;
n,m,i,j,k,p:integer;
max:integer;
Begin
Clrscr;
write('n='); readln (n);
write('m='); readln (m);
getmem (a,sizeof(integer)*n*m);
for i:=1 to n*m do
read(a^[ i ]);
max:=a^[1]; k:=1; p:=1;
for i:=1 to n do
for j:=1 to m do
if a^[(i-1)*m+j] > max then
Begin
max:=a^[(i-1)*m+j];
k:=i; p:=j
End;
write('строка=',k:2,' столбец=',p:2);
freemem(a,2*n*m);
Readkey;
End.
В следующем примере для хранения двумерного массива используется одномерный массив указателей на столбцы. В задаче требуется найти столбцы матрицы, в которых находятся минимальный и максимальный элементы матрицы и если это разные столбцы, то поменять их местами.
Uses crt;
Type
vk=^t1;
t1=array[1..1] of integer;
mt=^t2;
t2=array[1..1] of vk;
Var
a:mt;
m,n,i,j,k,l:integer;
max,min:integer;
r:pointer;
Begin
Clrscr;
Readln (n,m);
{выделение памяти под указатели столбцов матрицы}
getmem(a,sizeof (pointer)*m);
{выделение памяти под элементы столбцов}
for j:=1 to m do
getmem (a^[j],sizeof(integer)*n);
for i:=1 to n do
for j:=1 to m do
read(a^[ j ]^[ i ]);
for i:=1 to n do
Begin
for j:=1 to m do
write (a^[ j ]^[ i ]:4);
Writeln
End;
max:=a^[1]^[1]; k:=1; min:=max; l:=1;
for j:=1 to m do
for i:=1 to n do
if a^[ j ]^[ i ]<min then
Begin
min:=a^[j]^[i]; l:=j;
End
Else
if a^[ j ]^[ i ]>max then
Begin
max:=a^[j]^[i]; k:=j;
End;
{для обмена столбцов достаточно поменять указатели на столбцы}
if k<>l then
Begin
r:=a^[k]; a^[k]:=a^[l]; a^[l]:=r
End;
for i:=1 to n do
Begin
for j:=1 to m do
write(a^[j]^[i]:3,' ');
Writeln
End;
for i:=1 to m do
freemem (a^[ i ],n*sizeof(integer));
freemem (a,m*sizeof(pointer))
End.
Организация списков.
Преимущества динамической памяти становятся особенно очевидными при организации динамических структур, элементы которых связаны через адреса (стеки,… Список - это конечное множество динамических элементов, размещающихся в разных областях памяти и объединенных в…Type
point=^zap;
zap=record
inf1 : integer; { первое информационное поле }
inf2 : string; { второе информационное поле }
next : point; {ссылочное поле }
End;
Из этого описания видно, что имеет место рекурсивная ссылка: для описания типа point используется тип zap, а при описании типа zapиспользуется тип point. По соглашениям Паскаля в этом случае сначала описывается тип «указатель», а затем уже тип связанной с ним переменной. Правила Паскаля только при описании ссылок допускают использование идентификатора (zap) до его описания. Во всех остальных случаях, прежде чем упомянуть идентификатор, необходимо его определить.

 В случае двунаправленного списка в описании должно появиться еще одно ссылочное поле того же типа, например,
В случае двунаправленного списка в описании должно появиться еще одно ссылочное поле того же типа, например,
Type
point=^zap;
zap=record
inf1 : integer; { первое информационное поле }
inf2 : string; { второе информационное поле }
next:point; {ссылочное поле на следующий элемент}
prev:point; {ссылочное поле на предыдущий элемент}
End;
Как уже отмечалось, последовательность обработки элементов списка задается системой ссылок. Отсюда следует важный факт: все действия над элементами списка, приводящие к изменению порядка обработки элементов списка - вставка, удаление, перестановка - сводятся к действиям со ссылками. Сами же элементы не меняют своего физического положения в памяти.
При работе со списками любых видов нельзя обойтись без указателя на первый элемент. Не менее полезными, хотя и не всегда обязательными, могут стать адрес последнего элемента списка и количество элементов. Эти данные могут существовать по отдельности, однако их можно объединить в единую структуру типа «запись» (из-за разнотипности полей: два поля указателей на элементы и числовое поле для количества элементов). Эта структура и будет представлять так называемый головной элемент списка. Следуя идеологии динамических структур данных, головной элемент списка также необходимо сделать динамическим, выделяя под него память при создании списка и освобождая после окончания работы. Использование данных головного элемента делает работу со списком более удобной, но требует определенных действий по его обслуживанию.
Рассмотрим основные процедуры работы с линейным однонаправленным списком без головного элемента. Действия оформлены в виде процедур или функций в соответствии с основными требованиями модульного программирования (см. соответствующий раздел пособия).
Приведем фрагменты разделов Type и Var, необходимые для дальнейшей работы с линейным однонаправленным списком без головного элемента.
Type
el = ^zap;
zap=record
inf1 : integer;{ первое информационное поле }
inf2 : string; { второе информационное поле }
next : el; {ссылочное поле }
End;
Var
first, { указатель на первый элемент списка }
p, q , t : el; { рабочие указатели, с помощью которых
будет выполняться работа с элементами списка }
Задачи включения элемента в линейный однонаправленный список без головного элемента.
Графическое представление выполняемых действий дано на рис. 21
Формирование пустого списка.
Procedure Create_Empty_List ( var first : el);
Begin
first = nil;
End;
Формирование очередного элемента списка.
Procedure Create_New_Elem(var p: el);
Begin
New (p);
Writeln ('введите значение первого информационного поля: ');
Readln ( p^.inf1 );
Writeln ('введите значение второго информационного поля:'); Readln ( p^.inf2 );
p^.next := nil;
{все поля элемента должны быть инициализированы}
End;
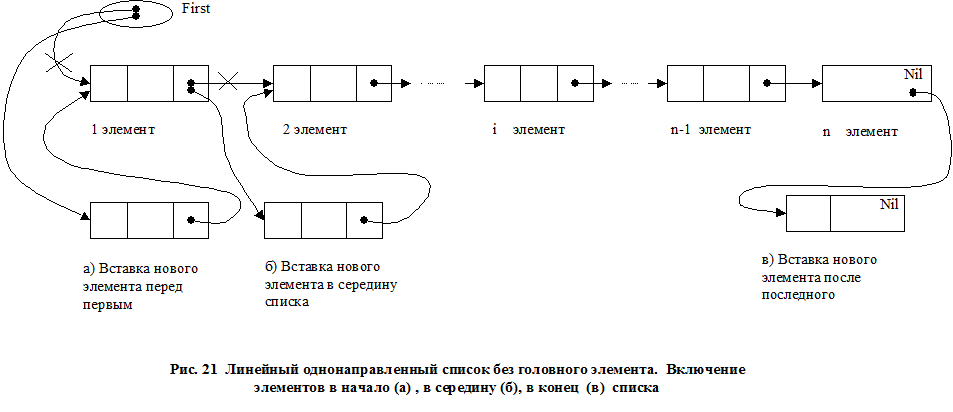
Подсчет числа элементов списка.
Function Count_el(First:el):integer;
Var
K : integer;
q : el;
Begin
If First = Nil then
k:=0 {список пуст}
Else
begin {список существует}
k:=1; {в списке есть хотя бы один элемент}
q:=First;
{перебор элементов списка начинается с первого}
While q^.Next <> Nil do
Begin
k:=k+1;
q:=q^.Next;
{переход к следующему элементу списка}
End;
End;
Count_el:=k;
End;
ПРИМЕЧАНИЕ: аналогично может быть написана процедура, например, печати списка, поиска адреса последнего элемента и др.
Вставка элемента в начало списка.
Procedure Ins_beg_list(P : el; {адрес включаемого элемента}
Var First : el);
Begin
If First = Nil Then
Begin
First := p;
P^.next := nil{ можно не делать, так как уже сделано при
формировании этого элемента}
End
Else
Begin
P^.Next:=First;{ссылка на бывший первым элемент}
First:=p;{ включаемый элемент становится первым }
End;
End;
Включение элемента в конец списка.
Procedure Ins_end_list(P : el; Var First : el);
Begin
If First = Nil Then
First:=p
Else
Begin
q:=First;{цикл поиска адреса последнего элемента}
While q^.Next <> Nil do
q:=q^.Next;
q^.Next:=p;{ссылка с бывшего последнего
на включаемый элемент}
P^.Next:=Nil;{не обязательно}
End;
End;
Включение в середину (после i-ого элемента).
Procedure Ins_after_I ( first : el; p : el; i : integer);
Var
t, q : el;
K ,n : integer;
Begin
n := count_el(first);{определение числа элементов списка}
if (i < 1 ) or ( i > n )then
Begin
writeln ('i задано некорректно');
Exit;
End
Else
Begin
if i = 1 then
Begin
t := first;{адрес 1 элемента}
q := t^.next;{адрес 2 элемента}
t^.next := p;
p^.next := q;
End
Else
if i = n then
begin{ см. случай вставки после последнего
элемента}
. . .
End
else{вставка в «середину» списка}
Begin
t := first;
k := 1;
while ( k < i ) do
begin{поиск адреса i-го элемента}
k := k + 1;
t := t^.next;
End;
q := t^.next;
{найдены адреса i-го (t) и i+1 -го (q) элементов }
t^.next := p;
p^.next := q;
{элемент с адресом р вставлен}
End;
End;
End;
ПРИМЕЧАНИЕ: аналогично рассуждая и применяя графическое представление действия, можно решить задачу включения элемента перед i-ым. Строго говоря, такая задача не эквивалентна задаче включения элемента после (i-1)-го.
Задачи на удаление элементов из линейного однонаправленного списка без головного элемента.
Графическое представление выполняемых действий дано на рисунке 22.
Удаление элемента из начала списка.
ПРИМЕЧАНИЕ: перед выполнением операции удаления элемента или списка желательно запрашивать у пользователя подтверждение удаления.
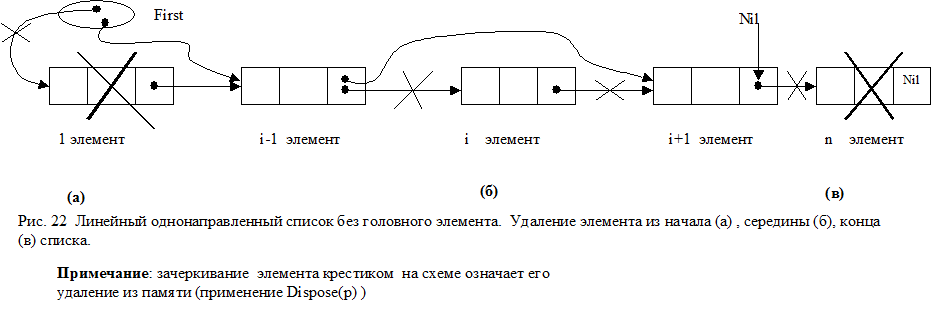
Procedure Del_beg_list ( Var First : el);
Var
p : el;
answer : string;
Begin
If First <> Nil then
Begin { список не пуст }
writeln ('Вы хотите удалить первый элемент?(да/нет) ');
Readln ( answer );
if answer = 'да' then
Begin
p:=First;
If p^.Next = Nil Then{в списке один элемент }
Begin
Dispose (p);{уничтожение элемента}
First:=Nil;{список стал пустым }
End
Else
Begin
P := first;{адрес удаляемого элемента }
First:=first^.Next;
{адрес нового первого элемента}
Dispose(p);
{удаление бывшего первого элемента }
End;
End
End
Else
writeln ('список пуст, удаление первого элемента невозможно');
End;
Удаление элемента из конца списка.
Нужен запрос на удаление
Procedure Del_end_list( Var First :el);
Begin
If First < > Nil then
Begin {список не пуст}
if fiRst^.next = nil then
begin{в списке - единственный элемент }
p := first;
Dispose (p);
First := nil;
End
Else
begin{в списке больше одного элемента }
Q := First;
T := First;
{цикл поиска адреса последнего элемента}
While q^.Next < > Nil do
Begin
T := q;{запоминание адреса текущего элемента}
q:=q^.Next;{переход к следующему элементу}
End;
{после окончания цикла Т - адрес предпоследнего,
а Q - адрес последнего элемента списка}
dispose (q);{удаление последнего элемента}
t^.next := nil;{предпоследний элемент стал
последним}
End
End
Else
writeln ('список пуст, удаление элемента невозможно');
End;
ПРИМЕЧАНИЕ. После исключения элемента из списка этот элемент может не удаляться из памяти, а через список параметров передан на какую-либо обработку, если этого требует алгоритм обработки данных.
Удаление элемента из середины списка (i-ого элемента).
Procedure Del_I_elem ( first : el; i : integer);
Var
t, q, r : el;
K ,n : integer;
Begin
n := count_el(first);{определение числа элементов списка}
if (i < 1 ) or ( i > n ) then
Begin
writeln ('iзадано некорректно');
Exit;
End
Else
Begin
{нужно добавить подтверждение удаления }
if i = 1 then
begin{удаляется 1 элемент}
t := first;
first:= first^.next;
Dispose ( t);
End
Else
if i = n then
begin{ см. случай удаления последнего элемента}
. . .
End
else{удаление из «середины» списка}
Begin
t := first;
q := nil;
k := 1;
while ( k < i ) do
begin{поиск адресов (i-1)-го и i-го элементов}
k := k + 1;
q := t;
t := t^.next;
End;
r := t^.next;
{найдены адреса i-го (t), (i-1)-го (q) и (i+1)-го (r) элементов }
q^.next := r;
dispose ( t );{удален i-ый элемент }
End;
End;
End;
Удаление всего списка с освобождением памяти.
Procedure Delete_List(Var First : el);
Var
P, q : el;
Answer : string;
Begin
If First <> Nil Then
Begin{ список не пуст }
writeln ( 'Вы хотите удалить весь список ? (да/нет)' );
Readln ( answer );
if answer = 'да' then
Begin
q:=First;
p:=nil;
While ( q <> nil ) do
Begin
p:=q;
q:=q^.Next;
Dispose(p);
End;
First:=Nil;
End;
End
Else
writeln ('список пуст');
End;
Задачи на замену элементов в линейном однонаправленном списке без головного элемента.
Операция замены элемента в списке практически представляет собой комбинацию удаления и вставки элемента. Читателю дается возможность, используя… Действуя аналогично, можно построить графические схемы и программы задач…Стеки, деки, очереди.
Одной из важных концепций в программировании является концепция стека. Стеком называется упорядоченный набор элементов, в котором добавление новых… 1) добавление в стек нового элемента;Использование рекурсии при работе со списками.
Рекурсия является одним из удобнейших средств при работе с линейными списками. Она позволяет сократить код программы и сделать алгоритмы обхода… По определению понятия, рекурсивная процедура - это процедура, в теле которой… Хотя рекурсии в списках не являются настолько очевидным решением, как в деревьях, все же они позволяют оптимизировать…Begin
if q< >nil { ограничитель рекурсии } then
Begin
Inc(count);
Count_El( q^.next , count);
End
End;
При входе в процедуру count = 0,а q=first (указатель на первый элемент списка).Далее рекурсивная процедура работает так. Анализируется значение указателя, переданного в процедуру. Если он не равен Nil (список не закончился), то счетчик числа элементов увеличивается на 1. Далее происходит очередной вызов рекурсивной процедуры уже с адресом следующего элемента списка, а «текущая» рекурсивная процедура приостанавливается до окончания вызванной процедуры. Вызванная процедура работает точно так же: считает, вызывает процедуру и переходит в состояние ожидания. Формируется как бы последовательность из процедур, каждая из которых ожидает завершения вызванной процедуры. Этот процесс продолжается до тех пор, пока очередное значение адреса не станет равным Nil (признак окончания списка). В последней вызванной рекурсивной процедуре уже не происходит очередного вызова, так как не соблюдается условие q<>nil, срабатывает «ограничитель рекурсии». В результате процедура завершается без выполнения каких-либо действий, а управление возвращается в «предпоследнюю», вызывающую процедуру. Точкой возврата будет оператор, стоящий за вызовом процедуры, в данном тексте - End, и «предпоследняя» процедура завершает свою работу, возвращая управление в вызвавшую её процедуру. Начинается процесс «сворачивания» цепочки ожидающих завершения процедур. Счетчик count, вызывавшийся по ссылке, сохраняет накопленное значение после завершения всей цепочки вызванных рекурсивных процедур.
Если из текста рассмотренной процедуры убрать использование счетчика, то получится некий базисный вариант рекурсивной процедуры, который можно применять при решении других задач обработки списка: распечатать содержимое списка; определить, есть ли в списке элемент с заданным порядковым номером или определенным значением информационного поля; уничтожить список с освобождением памяти и др.
Бинарные деревья.
Кроме линейных структур существуют и нелинейные, при помощи которых задаются иерархические связи данных. Для этого используются графы, а среди них… Бинарное (двоичное) дерево - это конечное множество элементов, которое либо…Действия с бинарными деревьями.
Рассматривая действия над деревьями, можно сказать, что для построения дерева необходимо формировать узлы, и, определив предварительно место… Далее необходимо осуществлять поиск заданного узла в дереве. Это можно… Может возникнуть задача и уничтожения дерева в тот момент, когда необходимость в нем (в информации, записанной в его…Построение бинарного дерева.
Важным понятием древовидной структуры является понятие двоичного дерева поиска. Правило построения двоичного дерева поиска: элементы, у которых… Рассмотрим пример формирования двоичного дерева. Предположим, что нужно…Решение задач работы с бинарным деревом.
Элемент дерева используется для хранения какой-либо информации, следовательно, он должен содержать информационные поля, возможно разнотипные.… Приведем пример описания полей и элементов, необходимых для построения дерева.Type
Nd = ^ node;
Node = record
Inf1 : integer;
Inf2 : string ;
Left : nd;
Right : nd;
End;
Var
Root, p,q : nd;
Приведенный пример описания показывает, что описание элемента списка и узла дерева по сути ничем не отличаются друг от друга. Различия в технологии действий тоже невелики - основные действия выполняются над ссылками, адресами узлов. Основные различия - в алгоритмах.
При работе с двоичным деревом возможны следующие основные задачи:
1) создание элемента, узла дерева,
2) включение его в дерево по алгоритму двоичного поиска,
3) нахождение в дереве узла с заданным значением ключевого признака,
4) определение максимальной глубины дерева,
5) определение количества узлов дерева,
6) определение количества листьев дерева,
7) ряд других задач.
Приведем примеры процедур, реализующих основные задачи работы с бинарным деревом.
{создание элемента дерева}
Procedure CREATE_EL_T(var q:ND; nf1:integer;
inf2:string);
Begin
New(q);
q^.inf1:=inf1;
q^.inf2:=inf2;
{значения полей передаются в качестве параметров}
q^.right:=nil;
q^.left:=nil;
End;
procedure Insert_el ( p : nd; {адрес включаемого элемента}
var root : nd);
Var
q, t : nd;
Begin
if root = nil then
root := p {элемент стал корнем}
Else
begin { поиск по дереву }
t := root;
q := root;
while ( t < > nil ) do
Begin
if p^.inf1 < t^.inf1 then
Begin
q := t;{ запоминание текущего адреса}
t := t^.left; {уход по левой ветви}
End
Else
if p^.inf1 > t^.inf1 then
Begin
q := t;{ запоминание текущего адреса}
t := t^.right; {уход по правой ветви}
End
Else
Begin
writeln ('найден дубль включаемого элемента');
exit; {завершение работы процедуры}
End
End;
{после выхода из цикла в q - адрес элемента, к которому
должен быть подключен новый элемент}
if p^.inf1 < q^.inf1 then
q^.left := p {подключение слева }
Else
q^.right := p; {подключение справа}
End;
ПРИМЕЧАНИЕ: элемент с дублирующим ключевым признаком в дерево не включается.
Данный алгоритм движения по дереву может быть положен в основу задачи определения максимального уровня (глубины) двоичного дерева, определения, есть ли в дереве элемент с заданным значением ключевого признака и т.д., то есть таких задач, решение которых основывается на алгоритме двоичного поиска по дереву.
Однако не все задачи могут быть решены с применением двоичного поиска, например, подсчет общего числа узлов дерева. Для этого требуется алгоритм, позволяющий однократно посещать каждый узел дерева.
При посещении любого узла возможно однократное выполнение следующих трех действий:
1) обработать узел (конкретный набор действий при этом не важен). Обозначим это действие через О (обработка);
2) перейти по левой ссылке (обозначение - Л);
3) перейти по правой ссылке (обозначение - П).
Можно организовать обход узлов двоичного дерева, однократно выполняя над каждым узлом эту последовательность действий. Действия могут быть скомбинированы в произвольном порядке, но он должен быть постоянным в конкретной задаче обхода дерева.
На примере дерева на рис. 10 проиллюстрируем варианты обхода дерева.
1) Обход вида ОЛП. Такой обход называется «в прямом порядке», «в глубину». Он даст следующий порядок посещения узлов:
20, 10, 8, 15, 17, 35, 27, 24, 30
2) Обход вида ЛОП. Он называется «симметричным» и даст следующий порядок посещения узлов:
8, 10, 15, 17, 20, 24, 27, 30, 35
3) Обход вида ЛПО. Он называется «в обратном порядке» и даст следующий порядок посещения узлов:
8, 17, 15, 10, 24, 30, 27, 35, 20
Если рассматривать задачи, требующие сплошного обхода дерева, то для части из них порядок обхода, в целом, не важен, например, подсчет числа узлов дерева, числа листьев/не листьев, элементов, обладающих заданной информацией и т.д. Однако такая задача, как уничтожение бинарного дерева с освобождением памяти, требует использования только обхода «в обратном порядке».
Рассмотрим средства, с помощью которых можно обеспечить варианты обхода дерева.
При работе с бинарным деревом с точки зрения программирования оптимальным вариантом построения программы является использование рекурсии. Базисный вариант рекурсивной процедуры обхода бинарного дерева очень прост.
{ обход дерева по варианту ЛОП }
Procedure Recurs_Tree ( q : nd );
Begin
If q <> nil Then
Begin
Recurs_Tree( q^.left );{уход по левой ветви-Л}
Work ( q ); { процедура обработки дерева-О}
Recurs_Tree( q^.right );{уход по правой ветви-П}
End;
End;
Рекурсия в этой программе действует точно так же, как и в рекурсивных процедурах работы со списками: создается цепочка процедур, каждая из которых рекурсивно обращается к себе и затем ожидает завершения вызванной процедуры. Потенциально бесконечный процесс рекурсивного вызова останавливается с помощью «ограничителя рекурсии», в данном случае им становится нарушение условия ( q <> nil ), когда при обходе обнаруживается «нулевая» ссылка вместо реального адреса. При этом начинается последовательное завершение вызванных процедур с возвратом управления в вызывающую. Способ обхода меняется с изменением порядка обращений к процедурам.
Для практической проработки действия механизма рекурсии при реализации вариантов обхода дерева можно воспользоваться уже построенным деревом с рис.10.
Пример использования рекурсивной процедуры при решении задачи подсчета листьев двоичного дерева.
Procedure Leafs_Count( q : nd; var k : integer );
Begin
If q <> nil Then
Begin
Leafs_Count( q^.left, k );
If (q^.left = nil) and (q^.right = nil) Then
K := K +1;
Leafs_Count( q^.right, k );
End;
End;
{удаление дерева с освобождением памяти}
Procedure del_tree(q : nd );
Begin
if q<>nil then
Begin
del_tree (q^.left);
del_tree (q^.right);
Dispose(q)
End
End;
В заключение следует сказать о том, что рекурсивный обход дерева применим в большинстве задач, однако необходимо все же различать варианты эффективного применения двоичного поиска и сплошного обхода.
Вопросы к главе 7.
1. Особенности использования статической и динамической памяти. 2. Описание динамических переменных. 3. Использование указателей и ссылочных переменных.Основные принципы структурного программирования.
Понятие жизненного цикла программного продукта
Основные принципы структурной методологии.
Принцип абстракции.
Этот принцип позволяет разработчику рассматривать программу в нужный момент без лишней детализации. Детализация увеличивается при переходе от верхнего уровня абстракции к нижнему.
Принцип формальности.
Он предполагает строгий методический подход к программированию, придает творческому процессу определенную строгость и дисциплину.
Принцип модульности.
В соответствии с этим принципом программа разделяется на отдельные законченные фрагменты, модули, которые просты по управлению и допускают независимую отладку и тестирование. В результате отдельные ветви программы могут создаваться разными группами программистов.
Принцип иерархического упорядочения.
Взаимосвязь между частями программы должна носить иерархический, подчиненный характер. Это, кстати, следует и из принципа нисходящего проектирования.
Нисходящее проектирование.
Нисходящее проектирование строится на вышеперечисленных принципах. При нисходящем проектировании происходит анализ задачи с целью определения… На основе структурной схемы программы выполняется реализация подзадач в виде… После разбиения программного комплекса на программные модули и подготовки спецификаций на каждый программный модуль…Структурное кодирование.
Структурное кодирование - это метод кодирования (программирования), предусматривающий создание понятных, простых и удобочитаемых программных модулей… Для кодирования программных модулей используются унифицированные (базовые)… Программные комплексы и программные модули, закодированные в соответствии с правилами структурного программирования,…Модульное программирование.
Модульное программирование - это организация программы как совокупности небольших независимых блоков, модулей, структура и поведение которых… Программа, разработанная в соответствии с принципами структурного… · программа должна разделяться на независимые части, называемые модулями;Вопросы к главе 8.
2. Основные этапы разработки программного обеспечения. 3. Дать определение технологии программирования. 4. Цели структурного программирования.Список литературы
1. Вирт Н. Алгоритмы и структуры данных. М., Мир, 1989.
2. Вирт Н. Алгоритмы + структуры данных = программы. М., Мир,1985.
3. Дайитбегов Д.М., Черноусов Е.А. Основы алгоритмизации и алгоритмические языки. Учебник. М., Финансы и статистика, 1992.
4. Джонс Ж.,Харроу К. Решение задач в системе Турбо Паскаль. М., Финансы и статистика, 1989.
5. Епанешников А.М., Епанешников В.А. Программирование в среде Turbo Pascal 7.0. М., Диалог-МИФИ, 1995.
6. Кормен Т., Лейзерсон Ч., Ривест Р. Алгоритмы: построение и анализ. М.. МЦНМО, 1999.
7. Лэнгсам Й., Огенстайн М., Тэненбаум А Структуры данных для персональных ЭВМ, М., Мир, 1989.
8. Семашко Г.Л., Салтыков А.И. Программирование на языке Паскаль. М., Наука, 1988
9. Турбо Паскаль 7.0. К., Торгово-издательское бюро BHV, 1996
10. Фаронов В.В. Turbo Pascal 7.0. Начальный курс. Учебное пособие. М., Нолидж,1998.
– Конец работы –
Используемые теги: основы, алгоритмизации, Программирование0.069
Если Вам нужно дополнительный материал на эту тему, или Вы не нашли то, что искали, рекомендуем воспользоваться поиском по нашей базе работ: Основы алгоритмизации и Программирование
Что будем делать с полученным материалом:
Если этот материал оказался полезным для Вас, Вы можете сохранить его на свою страничку в социальных сетях:
| Твитнуть |
Хотите получать на электронную почту самые свежие новости?

Подпишитесь на Нашу рассылку
Реклама





Информация в виде рефератов, конспектов, лекций, курсовых и дипломных работ имеют своего автора, которому принадлежат права. Поэтому, прежде чем использовать какую либо информацию с этого сайта, убедитесь, что этим Вы не нарушаете чье либо право.
© copyright 1999 - 2024 allRefs.net. Все права защищены. Страница сгенерирована за: 0.248 сек.
Новости и инфо для студентов