рефераты конспекты курсовые дипломные лекции шпоры

- Раздел Образование
- /
- ОПЕРАЦИОННЫЕ СИСТЕМЫ
Реферат Курсовая Конспект
ОПЕРАЦИОННЫЕ СИСТЕМЫ
ОПЕРАЦИОННЫЕ СИСТЕМЫ - раздел Образование, Московский Государственный Университет Им. М.в.ломоносова...
МОСКОВСКИЙ ГОСУДАРСТВЕННЫЙ УНИВЕРСИТЕТ
им. М.В.ЛОМОНОСОВА
Факультет вычислительной математики и кибернетики
Курынин Р.В., Машечкин И.В., Терехин А.Н.
ОПЕРАЦИОННЫЕ СИСТЕМЫ
Конспект лекций
МОСКВА
Содержание
Содержание.. 2
1 Введение.. 5
1.1 Основы архитектуры вычислительной системы.. 10
1.1.1 Структура ВС.. 10
1.1.2 Аппаратный уровень ВС.. 11
1.1.3 Управление физическими ресурсами ВС.. 12
1.1.4 Управление логическими/виртуальными ресурсами. 14
1.1.5 Системы программирования. 16
1.1.6 Прикладные системы.. 22
1.1.7 Выводы, литература. 27
1.2 Основы компьютерной архитектуры.. 30
1.2.1 Структура, основные компоненты.. 30
1.2.2 Оперативное запоминающее устройство. 32
1.2.3 Центральный процессор. 36
1.2.3.1 Регистровая память. 37
1.2.3.2 Устройство управления. Арифметико-логическое устройство. 37
1.2.3.3 КЭШ-память. 38
1.2.3.4 Аппарат прерываний. 40
1.2.4 Внешние устройства. 44
1.2.4.1 Внешние запоминающие устройства. 45
1.2.4.2 Модели синхронизации при обмене с внешними устройствами. 49
1.2.4.3 Потоки данных. Организация управления внешними устройствами. 50
1.2.5 Иерархия памяти. 52
1.2.6 Аппаратная поддержка операционной системы и систем программирования. 53
1.2.6.1 Требования к аппаратуре для поддержки мультипрограммного режима. 53
1.2.6.2 Проблемы, возникающие при исполнении программ.. 56
1.2.6.3 Регистровые окна. 58
1.2.6.4 Системный стек. 60
1.2.6.5 Виртуальная память. 60
1.2.7 Многомашинные, многопроцессорные ассоциации. 64
1.2.8 Терминальные комплексы (ТК) 67
1.2.9 Компьютерные сети. 69
1.2.10 Организация сетевого взаимодействия. Эталонная модель ISO/OSI. 71
1.2.11 Семейство протоколов TCP/IP. Соответствие модели ISO/OSI. 73
1.3 Основы архитектуры операционных систем.. 78
1.3.1 Структура ОС.. 80
1.3.2 Логические функции ОС.. 83
1.3.3 Типы операционных систем.. 84
2 Управление процессами.. 87
2.1 Основные концепции. 87
2.1.1 Модели операционных систем.. 87
2.1.2 Типы процессов. 89
2.1.3 Контекст процесса. 90
2.2 Реализация процессов в ОС Unix. 91
2.2.1 Процесс ОС Unix. 91
2.2.2 Базовые средства управления процессами в ОС Unix. 93
2.2.3 Жизненный цикл процесса. Состояния процесса. 100
2.2.4 Формирование процессов 0 и 1. 101
2.3 Планирование. 104
2.4 Взаимодействие процессов. 104
2.4.1 Разделяемые ресурсы и синхронизация доступа к ним.. 104
2.4.2 Способы организации взаимного исключения. 106
2.4.3 Классические задачи синхронизации процессов. 108
3 Реализация межпроцессного взаимодействия в ОС Unix.. 115
3.1 Базовые средства реализации взаимодействия процессов в ОС Unix. 115
3.1.1 Сигналы.. 117
3.1.2 Неименованные каналы.. 122
3.1.3 Именованные каналы.. 129
3.1.4 Модель межпроцессного взаимодействия «главный–подчиненный». 130
3.2 Система межпроцессного взаимодействия IPC (Inter-Process Communication) 134
3.2.1 Очередь сообщений IPC.. 136
3.2.2 Разделяемая память IPC.. 142
3.2.3 Массив семафоров IPC.. 144
3.3 Сокеты — унифицированный интерфейс программирования распределенных систем.. 149
4 Файловые системы... 155
4.1 Основные концепции. 155
4.1.1 Структурная организация файлов. 156
4.1.2 Атрибуты файлов. 157
4.1.3 Основные правила работы с файлами. Типовые программные интерфейсы.. 158
4.1.4 Подходы в практической реализации файловой системы.. 161
4.1.5 Модели реализации файлов. 163
4.1.6 Модели реализации каталогов. 165
4.1.7 Соответствие имени файла и его содержимого. 166
4.1.8 Координация использования пространства внешней памяти. 167
4.1.9 Квотирование пространства файловой системы.. 168
4.1.10 Надежность файловой системы.. 169
4.1.11 Проверка целостности файловой системы.. 170
4.2 Примеры реализаций файловых систем.. 172
4.2.1 Организация файловой системы ОС Unix. Виды файлов. Права доступа. 173
4.2.2 Логическая структура каталогов. 174
4.2.3 Внутренняя организация файловой системы: модель версии System V.. 175
4.2.3.1 Работа с массивами номеров свободных блоков. 176
4.2.3.2 Работа с массивом свободных индексных дескрипторов. 176
4.2.3.3 Индексные дескрипторы. Адресация блоков файла. 177
4.2.3.4 Файл-каталог. 178
4.2.3.5 Достоинства и недостатки файловой системы модели System V.. 180
4.2.4 Внутренняя организация файловой системы: модель версии Fast File System (FFS) BSD 180
4.2.4.1 Стратегии размещения. 181
4.2.4.2 Внутренняя организация блоков. 182
4.2.4.3 Выделение пространства для файла. 183
4.2.4.4 Структура каталога FFS. 183
4.2.4.5 Блокировка доступа к содержимому файла. 184
5 Управление оперативной памятью.... 186
5.1 Одиночное непрерывное распределение. 186
5.2 Распределение неперемещаемыми разделами. 187
5.3 Распределение перемещаемыми разделами. 189
5.4 Страничное распределение. 190
5.5 Сегментное распределение. 197
5.6 Сегментно-страничное распределение. 199
6 Управление внешними устройствами.. 201
6.1 Общие концепции. 201
6.1.1 Архитектура организации управления внешними устройствами. 201
6.1.2 Программное управление внешними устройствами. 202
6.1.3 Планирование дисковых обменов. 203
6.1.4 RAID-системы. Уровни RAID.. 206
6.2 Работа с внешними устройствами в ОС Unix. 209
6.2.1 Файлы устройств, драйверы.. 209
6.2.2 Системные таблицы драйверов устройств. 210
6.2.3 Ситуации, вызывающие обращение к функциям драйвера. 211
6.2.4 Включение, удаление драйверов из системы.. 211
6.2.5 Организация обмена данными с файлами. 212
6.2.6 Буферизация при блок-ориентированном обмене. 213
6.2.7 Борьба со сбоями. 214
Введение
Настоящая[R1] книга основывается на многолетнем опыте чтения авторами курсов лекций и проведении семинарских занятий по операционным системам на факультете вычислительной математики и кибернетики Московского государственного университета им. М.В.Ломоносова (Россия) и на факультете компьютерных наук университета Ватерлоо (Онтарио, Канада).
Операционная система является одним из ключевых понятий, связанных с функционированием компьютеров и их программного обеспечения. В существующей литературе многие понятия, связанные с вычислительной техникой, определяется неоднозначно, что иногда вносит путаницу в представление полной картины того, что и как функционирует в современном компьютере. Неоднозначностью определений страдает и понятие операционная система. В каких-то источниках операционная система определяется, «как система интерфейсов, предназначенная для обеспечения удобства работы пользователя с компьютером», в каких-то — это «посредник между программами пользователя и аппаратными средствами», кто-то сопоставляет это понятие с «возможностями и интерфейсами, предоставляемыми инструментальными средствами программирования и/или прикладными системами». В целом, каждая из перечисленных интерпретаций понятия операционная система имеет право на существование, и природа появления того или иного представления ясна. Однако многие из используемых трактовок термина операционная система ориентированы на конкретную категорию пользователей (программист, пользователь прикладной системы, системный программист и т.п.) и не формируют целостной картины функций свойств и взаимосвязей с другими компонентами программного обеспечения и аппаратуры компьютера.
Авторы настоящей книги ставили перед собой цель выстроить систему определений и рассмотреть основные свойства и примеры реализации тех или иных аппаратных и программных компонентов, функционирующих в компьютере, в их взаимосвязи, акцентировав основное внимание на понятии операционная система, на основах ее построения, примерах организации тех или иных частей наиболее распространенных на сегодняшний день ОС.
История появления и развития операционных систем целиком и полностью связана с развитием и становлением аппаратных возможностей компьютеров. Рассмотрим ключевые этапы этого процесса.
Первое поколение компьютеров: середина 40-х — начало 50-х годов XX века. Компьютеры этого поколения строились на электронно-вакуумных лампах. В 1946 г. в Пенсильванском университете США была разработана вычислительная машина ENIAC (Electronic Numerical Integrator and Computer), которая считается одной из первых электронных вычислительных машин (ЭВМ). Данная машина была разработана по заказу министерства обороны США и применялась для решения задач энергетики и баллистики. Производительность таких компьютеров измерялась от сотен до тысяч команд (операций) в секунду. Компьютер состоял из процессора, оперативного запоминающего устройства и достаточно примитивных внешних устройств: устройства вывода (вывод цифровой информации на бумажную ленту), внешних запоминающих устройств (ВЗУ) — аппаратных средств хранения готовых к исполнению программы и данных (магнитные ленты), и устройства ввода, позволявшего вводить в оперативную память компьютера предварительно подготовленные на специальных носителях (перфокартах, перфоленте и пр.) программы и данные.
Изначально компьютеры первого поколения использовались в однопользовательском, персональном режиме, т.е. вся система монопольно предоставлялась одному пользователю, при этом программа и необходимые данные, представленные в машинных кодах в двоичном представлении, вводились в оперативную память, а затем запускалась на исполнение. Пользователь (программист) использовал аппаратную консоль (или пульт управления) компьютера для ввода и запуска программы чтения данных через устройства ввода. Результат выполнения программы выводился на устройство печати. В случае возникновения ошибки работа компьютера по выполнению команд программы прерывалась, и возникшая ситуация отображалась на индикаторах пульта управления, содержание которых анализировалось программистом. Программирование в машинных кодах привносило ряд проблем, связанных с техническими сложностями написания, модификации и отладки программы. Кроме того, в задачу программиста входило кодирование всех необходимых операций ввода/вывода с помощью специальных машинных команд управления внешними устройствами. В этот период от пользователя компьютера требовались не только алгоритмические знания и навыки решения конкретной прикладной задачи, но и достаточно хорошие знания организации и использования аппаратуры компьютера, доскональное знание системы команд и кодировки, используемой в данном компьютере, знание особенностей программирования устройств ввода/вывода, т.е. программист должен был быть, отчасти, и инженером-электронщиком. На этапе существования компьютеров первого поколения появился класс программ, обеспечивающих определенные сервисные функции программирования — это ассемблеры, первые языки высокого уровня и трансляторы для этих языков, а также простейшие средства организации и использования библиотек программ. Кроме того, можно говорить о зарождении класса сервисных, управляющих программ: представителями этого класса являлись программы чтения и загрузки в оперативную память программ и данных с внешних устройств. Эти программы были предопределены фирмой-разработчиком компьютеров и вводились в оперативную память с использованием аппаратной консоли. Так при помощи консоли было возможно вручную ввести в оперативную память последовательность команд, составляющих управляющую программу, и осуществить ее запуск. В случае если управляющая программа размещалась на внешнем запоминающем устройстве, через аппаратную консоль вводилась последовательность команд, обеспечивающих чтение кода управляющей программы в оперативную память и передачу управления на ее точку входа.
Компьютеры второго поколения: конец 50-х годов — вторая половина 60-х годов ХХ века. Традиционно, с компьютерами второго поколения связывается использование полупроводниковых приборов — диодов и транзисторов, которые по функциональной емкости, размеру, энергопотреблению в десятки раз превосходили возможности электронно-вакуумных ламп. В результате компьютеры второго поколения стали обладать существенно более развитыми логическими возможностями и в тысячи раз превосходили компьютеры первого поколения по производительности. Широкое распространение получили новые высокопроизводительные внешние устройства ЭВМ. Все это определило и активное совершенствование программного обеспечения и способов использования компьютеров. Можно с уверенностью утверждать, что реальное зарождение понятия операционной системы связано именно с появлением и совершенствованием архитектуры компьютеров второго поколения.
Этапом в развитии форм использования компьютеров стала пакетная обработка заданий, суть которой состояла в следующем. В компьютере работала специальная управляющая программа, в функции которой входила последовательная загрузка в оперативную память и запуск на выполнение программ из заранее подготовленного пакета программ. Пакет программ физически может быть представлен в виде «большой» стопки перфокарт, в которой программы находятся последовательно. В этом случае управляющая программа по завершении выполнения текущей программы осуществляет чтение очередной программы через устройство считывания перфокарт, загрузку ее в оперативную память и передача управления на фиксированную точку входа в программу (адрес памяти с которого должно начинаться выполнение программы). По завершении программы или после возникновения в программе ошибки, которая вызывает аварийную остановку выполнения программы, управление передается в управляющую программу (Рис. 1).

Рис. 1. Пакетная обработка заданий.
Такой процесс продолжался до тех пор, пока все программы из пакета не будут выполнены. Развитие подобных управляющих программ послужило основой появлению первых прообразов операционных систем, которые в разных случаях назывались мониторными системами, супервизорами или диспетчерами.
Следующим этапом развития понятия операционная система стало появление компьютеров второго поколения, имевших аппаратную поддержку режима мультипрограммирования — режима, при котором одновременно находилась в обработке не одна, а несколько программ. При этом в каждый момент времени команды одной из обрабатываемых программ выполнялись процессором, другие выполняли обмен данными с внешними устройствами, третьи были готовы к выполнению процессором и ожидали своей очереди. В СССР представителем машин второго поколения, обеспечивавших поддержку мультипрограммной обработки, была вычислительная машина БЭСМ-6, созданная под руководством академика С.А.Лебедева. Для данного компьютера была разработана серия операционных систем, которые по своей структуре и основным функциям были достаточно близки к современным ОС (НД-69, НД-70, ОС ДУБНА, ДИСПАК, ОС ИПМ и др.). Прародительницей подавляющего большинства этих операционных систем была система под названием Д-68 (Диспетчер–68), разработанная под руководством Л.Н.Королева.
Развитие мультипрограммных систем, расширение спектра решаемых задач и существенное увеличение количества пользователей компьютеров потребовало развития «дружественности» интерфейсов между пользователем и системой. С точки зрения инструментальных средств программирования это развитие языков программирования и систем программирования, которое представимо в следующей эволюционной последовательности: система команд компьютера è автокоды и ассемблеры è языки программирования высокого уровня è проблемно-ориентированные языки программирования (Рис. 2).
Операционные системы также получили свое развитие в этот период времени: появились языки управления заданиями, которые позволяли пользователю до начала выполнения его программы сформировать набор требований по организации выполнения программы. Появились первые прообразы современных файловых систем — систем, позволяющих систематизировать и упростить способы хранения и доступа пользователей к данным, размещенным на внешних запоминающих устройствах, что позволило пользователю работать с данными во внешней памяти не в терминах физических устройств и координат местоположения данных на этих физических устройствах, а в терминах имен или адресов некоторых наборов данных. В связи с этим у пользователя появилась возможность абстрагироваться от знания особенностей и способов организации хранения и доступа к данным конкретных физических устройств, что во многом послужило основой для появления виртуальных устройств.

Рис. 2. Развитие языков и систем программирования.
Компьютеры[R2] третьего поколения: конец 60-х — начало 70-х годов ХХ века. Основным отличием компьютеров этого поколения было использование в качестве элементной базы интегральных схем, что определило увеличение производительности компьютеров, существенное снижение их размеров, веса, появление новых, высокопроизводительных внешних устройств. И, наверное, главной особенностью архитектуры компьютеров третьего поколения было начало аппаратной унификации их узлов и устройств, позволившей стимулировать создание семейств компьютеров, аппаратная комплектация которых могла достаточно просто варьироваться владельцем компьютера. Наиболее яркими представителями таких семейств были компьютеры серий IBM-360 фирмы IBM и семейство малых компьютеров PDP-11 фирмы DEC. Компьютеры первых двух поколений строились, как единые, аппаратно-целостные устройства, комплектация и возможности которых были существенно предопределены на этапе их производства. Их аппаратная модификация, обычно, была крайне затруднительна. Третье поколение компьютеров строилось на модульном принципе, что позволяло, при необходимости, осуществлять замену и расширение состава внешних устройств, увеличивать размеры оперативной памяти, заменять процессор на более производительный. Все это повлияло и на развитие и структуру операционных систем, которые вслед за аппаратурой приобрели модульную организацию с унификацией межмодульных интерфейсов. В операционных системах появились специальные программы управления устройствами — драйверы устройств, которые имели стандартные интерфейсы, позволявшие при аппаратной модификации компьютера достаточно просто обеспечивать программный доступ к новым или модифицированным устройствам. Кроме того, для обеспечения простоты и «дружественности» общения пользователя с различными устройствами компьютера появились виртуальные устройства, драйверы которых предоставляли пользователю набор единых правил работы с группой внешних устройств, что позволило создавать программы, не зависящие от типов используемых внешних устройств. Операционные системы компьютеров третьего поколения предоставляли новые режимы использования компьютеров, одним из таких режимов был диалоговый режим доступа к компьютеру. Вершиной идей, заложенных в операционные системы компьютеров третьего поколения, стала операционная система Unix, которая открыла направление развития комплексной стандартизации пользовательских интерфейсов, как на уровне интерфейсов командных языков, так и на различных уровнях программных интерфейсов от правил взаимодействия с драйверами устройств до интерфейсов с прикладными системами.
Завершение формирования сегодняшнего понятия операционной системы может быть связано с появлением четвертого и последующих поколений компьютеров, в построении которых использовалась элементная база, основанная на больших интегральных схемах. Компьютеры четвертого поколения, в первую очередь, ассоциируются с персональными компьютерами, совершившими в полном смысле слова революцию в массовом распространении информационных технологий. Компьютер из инструмента прикладного программиста стал повседневным, массово распространенным и доступным оборудованием. В связи с этим возник целый ряд проблем, решение которых потребовалось в операционных системах. В первую очередь это совершенствование «дружественности» пользовательских интерфейсов, упрощающих взаимодействие пользователя и операционной системы. Здесь лидирующую позицию занимают операционные системы компании Microsoft, которые в полном смысле слова совершили революцию в обеспечении массовости освоения компьютера. Активное развитие получили сетевые технологии, что привело к появлению сетевых и распределенных операционных систем. В этот период времени наибольшее развитие получила всемирная сеть Internet. В свою очередь возникли задачи обеспечения операционными системами безопасности хранения и передачи данных.

Рис. 3. Этапы эволюции.
На данном этапе в результате эволюции понятий образовалось достаточно полное и однозначное определение того, что называется операционной системой, определена типовая структура операционной системы и функции ее основных компонентов. Сформировались принципиально новые разновидности операционных систем и режимов использования компьютеров.
Следует отметить тот факт, что развитие компьютеров, системного программного обеспечения, методов применения вычислительной техники показали, что единственным периодом истории, когда аппаратная часть разрабатывалась исключительно в качестве вычислителя без учета потребностей поддержки решения задач организации вычислительного процесса был период создания и производства компьютеров первого поколения. На сегодняшний день аппаратура и программное обеспечение современных компьютеров представляют единую взаимозависимую вычислительную систему, в которой многие функции операционной системы нельзя рассматривать вне контекста аппаратной поддержки компьютера, а многие аппаратные возможности сложно рассматривать вне контекста операционных систем (Рис. 3).
Основы архитектуры вычислительной системы
Структура ВС
Представление о возможностях и свойствах конкретной вычислительной системы формируются с позиций каждого из уровней структурной организации. Так… Другой пример — компьютер, используемый для обучения школьников языку…Аппаратный уровень ВС
- правила программного использования, определяющие возможность корректного использования данного ресурса в программе (для процессора компьютера эти… - параметры физического ресурса, характеризующие его объемные характеристики… - степень использования данного физического ресурса в вычислительной системе — это параметры, которые характеризуют…Управление физическими ресурсами ВС
Частичным решением этих проблем стало появление специальных стандартных программ — драйверов физических ресурсов (или драйверов физических… Совокупность драйверов физических устройств составляет уровень управления…Системы программирования
Проектирование программной системы. На данном этапе принимаются решения, традиционно включающие в себя следующие шаги. - Исследование решаемой задачи, формирование концептуальных требований к… - Определение характеристик объектной вычислительной системы — характеристик аппаратных и программных компонентов…Прикладные системы
В истории развития прикладных систем можно выделить четыре этапа. Первый — прикладные системы компьютеров первого поколения. Основной… Рис. 13. Первый этап развития прикладных систем.Выводы, литература
Мы рассмотрели основные уровни структурной организации вычислительной системы. Следует отметить, что рассмотренная нами модель организации вычислительной системы не единственная: существуют и другие подходы в определении структуры ВС, но в большинстве случаев отличия не являются принципиальными. Выбранная нами модель служит основой для дальнейшего изложения материала.
Вернемся к вопросу, который в той или иной степени затрагивался при рассмотрении каждого из уровней ВС. Как представляется вычислительная система пользователя ВС на каждом из уровней? Что видит или что доступно пользователю ВС, который находится на одном из уровней структурной организации вычислительной системы? Рассмотрим еще раз уровни структурной организации ВС с позиций обозначенных вопросов (Рис. 19).

Рис. 19. Структура организации вычислительной системы.
Аппаратный уровень. Пользователь вычислительной системы — программист. Доступные средства программирования: система команд компьютера, аппаратные интерфейсы программного управления внешними устройствами. Таким образом, пользователь ВС, находясь на уровне аппаратуры, работает с конкретным компьютером.
Уровень управления физическими ресурсами. На данном уровне пользователем системы также является программист. Средства программирования, которые предоставляются пользователю на данном уровне, претерпели изменения, т.к. кроме возможности работы с системой команд компьютера, с аппаратными интерфейсами программного управления внешними устройствами пользователю предоставляются интерфейсы драйверов физических устройств (ресурсов) компьютера. С позиций программиста, он работает с компьютером, имеющим расширенные, по сравнению с предыдущим уровнем, возможности. Кроме стандартных аппаратных средств программирования компьютера (система команд, аппаратные интерфейсы взаимодействия с физическими внешними устройствами) появились интерфейсы драйверов физических устройств (ресурсов) компьютера.
Уровень управления логическими или виртуальными ресурсами. На данном уровне структурной организации вычислительной системы спектр средств программирования расширяется за счет интерфейсов драйверов виртуальных/логических устройств (или ресурсов). В общем случае, для программиста, работающего с системой на данном уровне, средства программирования компьютера представляются:
- системой команд компьютера;
- аппаратными интерфейсами программного управления физическими устройствами;
- интерфейсами драйверов физических устройств;
- интерфейсами драйверов виртуальных устройств.
Операционная система может ограничить доступ пользователей к аппаратным средствам управления внешними устройствами, к драйверам физических устройств, к некоторым драйверам виртуальных устройств. Однако, "условный" пользователь уровня управления виртуальными устройствами вычислительной системы работает с компьютером, имеющим расширенные возможности. При этом пользователь может не знать о том, какие устройства, используемые в его программе, являются физическими, реально существующими, а какие — виртуальными. А даже если он и знает, что какое-то устройство является, к примеру, физическим, то, скорее всего, он не имеет никакого представления о деталях организации управления этого устройства на уровне аппаратных интерфейсов.
Уровень систем программирования. Для иллюстрации проблемы упростим структуру системы программирования, рассмотрим практически вырожденный случай. Пусть система программирования, с которой работает пользователь ВС, состоит только из транслятора языка высокого уровня и стандартной библиотеки программ, — например, языка Си. В этом случае представление пользователя о компьютере, на котором он работает, может свестись к языковым конструкциям языка Си и возможностям, предоставляемым стандартной библиотекой языка Си. Происходит очередное "расширение" возможностей компьютера за счет конструкций языка Си и его стандартной библиотеки. Более того, пользователь может работать на данном "расширенном" компьютере, не подозревая о реальной архитектуре аппаратного уровня ВС, о физических и виртуальных устройствах, поддерживаемых операционной системой, о системе команд и внутренней организации данных реального компьютера.
Уровень прикладных систем. Тенденция "расширения" возможностей компьютера продолжается и на прикладном уровне. При этом для каждой категории пользователей прикладного уровня вычислительной системы существует свое расширение компьютера. Так, например, для оператора прикладной системы компьютер представляется набором функциональных средств прикладной системы, доступной через пользовательский интерфейс. Рассмотрим работу кассира в современном супермаркете, кассовый аппарат которого может являться специализированным персональным компьютером, работающим в составе системы автоматизации деятельности всего магазина. Для кассира работа с этим компьютером и, соответственно, возможности этого компьютера представляются в виде возможностей прикладной подсистемы, автоматизирующей его рабочее место. Заведомо кассир магазина может не иметь никаких представлений о внутренней организации специализированной вычислительной системы, на которой он работает (тип компьютера, тип операционной системы, состав драйверов ОС и т.п.).
Не будет преувеличением утверждение, что не менее 90% современных пользователей персональных компьютеров не имеют представления о системе команд компьютера, о структуре компьютерных данных, об аппаратных интерфейсах управления физическими устройствами — все это скрывают расширения компьютера, которые образуются за счет соответствующих уровней вычислительной системы. Мы будем говорить, что каждый пользователь, работая в соответствующем расширении компьютера, работает в виртуальной машине или виртуальном компьютере. Реальный компьютер используется непосредственно исключительно на аппаратном уровне. Во всех остальных случаях пользователь работает с программным расширением возможностей реального компьютера — с виртуальным компьютером. Причем "виртуальность" этого компьютера (или этих компьютеров) возрастает от уровня управления физическими ресурсами ВС до уровня прикладных систем.
Вернемся к замечаниям, с которых начали данный раздел, касающихся неоднозначности определений многих компонентов вычислительных систем и, в частности, неоднозначности определения термина «операционная система».
В некоторых изданиях ошибочно ассоциируют понятие виртуального компьютера исключительно с операционной системой. Это не так. Только что мы показали, что "виртуальность компьютера", с которым работает пользователь вычислительной системы, начинается с уровня управления физическими устройствами и завершается на уровне прикладных систем.
Также не совсем правильным является утверждение, что операционная система предоставляет пользователю удобства работы с вычислительной системой или простоту ее программирования. На самом деле эти свойства в большей степени принадлежат прикладным системам или системам программирования. Одной из возможных причин подобной неоднозначности является то, что на ранних периодах развития вычислительной техники системы программирования рассматривались в качестве компонента операционных систем. Вычислительная система является продуктом глубокой интеграции ее компонентов, и, безусловно, на удобства работы с ВС и на простоту программирования оказывают влияние и аппаратура компьютера, и операционная система, но эти свойства в существенно большей степени характеризуют системы программирования и прикладные системы.
В настоящем разделе были рассмотрены следующие базовые определения, понятия.
Вычислительная система — совокупность аппаратных и программных средств, функционирующих в единой системе и предназначенных для решения задач определенного класса. Рассмотрена пятиуровневая модель организации вычислительной системы: аппаратный уровень, уровень управления физическими ресурсами ВС, уровень управления логическими/виртуальными ресурсами, уровень систем программирования и уровень прикладных систем. Круг задач, на решение которых ориентирована вычислительная система, определяется наполнением уровня прикладных систем, однако возможность реализации тех или иных прикладных систем определяется всеми остальными уровнями, составляющими структурную организацию ВС.
Физические ресурсы (устройства) — компоненты аппаратуры компьютера, используемые на программных уровнях ВС или оказывающие влияние на функционирование всей ВС. Совокупность физических ресурсов составляет аппаратный уровень вычислительной системы.
Драйвер физического устройства — программа, основанная на использовании команд управления конкретного физического устройства и предназначенная для организации работы с данным устройством. Драйвер физического устройства скрывает от пользователя детальные элементы управления конкретным физическим устройством и предоставляет пользователю упрощенный программный интерфейс работы с устройством.
Логические, или виртуальные, ресурсы (устройства) ВС — устройство/ресурс, некоторые эксплутационные характеристики которого (возможно все) реализованы программным образом.
Драйвер логического/виртуального ресурса — это программа, обеспечивающая существование и использование соответствующего ресурса, для этих целей при его реализации возможно использование существующих драйверов физических и виртуальных устройств.
Ресурсы вычислительной системы — это совокупность всех физических и виртуальных ресурсов данной вычислительной системы.
Операционная система — это комплекс программ, обеспечивающий управление ресурсами вычислительной системы. В структурной организации вычислительной системы операционная система представляется уровнями управления физическими и виртуальными ресурсами.
Жизненный цикл программы в вычислительной системе — проектирование, кодирование (программная реализация или реализация), тестирование и отладка, ввод программной системы в эксплуатацию (внедрение) и сопровождение.
Система программирования — комплекс программ, обеспечивающий поддержание этапов жизненного цикла программы в вычислительной системе.
Прикладная система — программная система, ориентированная на решение или автоматизацию решения задач из конкретной предметной области.
Основы компьютерной архитектуры
Структура, основные компоненты
1. Принцип двоичного кодирования информации: все поступающие и обрабатываемые компьютером данные кодируются при помощи двоичных сигналов. 2. Принцип программного управления. Программа состоит из команд, в которых… 3. Принцип хранимой программы. Для хранения команд и данных программы используется единое устройство памяти, которое…Оперативное запоминающее устройство
Рис. 22. Ячейка памяти. Машинное слово — поле программно изменяемой информации. В машинном слове могут располагаться машинные команды (или…Центральный процессор
Рассмотрим основные компоненты обобщенной структурной организации центрального процессора (Рис. 26). Рис. 26. Структура организации центрального процессора.Регистровая память
Регистры общего назначения (РОН) состоят из доступных для программ пользователей регистров, предназначенных для хранения операндов, адресов… Специальные регистры предназначены для координации информационного…Устройство управления. Арифметико-логическое устройство
Рис. 27. Схема выполнения программы. Пусть в начальный момент времени в счетчике команд СчК находится адрес первой команды программы. Для упрощения…КЭШ-память
Рис. 28. Общая схема работы КЭШа. Общая организация КЭШа следующая (Рис. 28).Аппарат прерываний
Прерыванием называется событие в компьютере, при возникновении которого в процессоре происходит предопределенная последовательность действий. Состав… Внутренние прерыванияинициируются схемами контроля работы процессора. К… Внешние прерывания — события, возникающие в компьютере в результате взаимодействия центрального процессора с внешними…Внешние устройства
Рис. 33. Внешние устройства. Мы более подробно остановимся на характеристиках и особенностях использования внешних запоминающих устройств, как…Внешние запоминающие устройства
ВЗУ могут разделяться на две группы по возможностям доступа к хранящимся данным. Первая группа — устройства, аппаратно допускающие как операции… Внешние запоминающие устройства могут, также подразделяться на устройства… Устройства последовательного доступа — это устройства, при доступе к содержимому произвольной записи которых…Модели синхронизации при обмене с внешними устройствами
Для иллюстрации рассмотрим пример. Пусть выполняемой в компьютере программе необходимо записать блок данных на магнитный диск. Что будет происходить… Синхронная работа с ВУ. При синхронной организации обмена в момент обращения к…Потоки данных. Организация управления внешними устройствами
Простейшей моделью является непосредственное управление процессоромвнешними устройствами (Рис. 39). Это означает, что центральный процессор… Рис. 39. Непосредственное управление центральным процессором внешнего устройства.Иерархия памяти
Рис. 42. Иерархия памяти. Самой дорогостоящей и наиболее высокопроизводительной памятью является память, которая размещается в центральном…Аппаратная поддержка операционной системы и систем программирования
Требования к аппаратуре для поддержки мультипрограммного режима
Рассмотрим схему организации мультипрограммного режима (Рис. 43). Пускай в начальный момент времени на процессоре обрабатывается Программа 1,… Рис. 43. Мультипрограммный режим.Проблемы, возникающие при исполнении программ
Вложенные обращения к подпрограммам (Рис. 44). Несколько лет назад проводились исследования, которые анализировали распределение времени исполнения… Рис. 44. Вложенные обращения к подпрограммам.Регистровые окна
Итак, имеющиеся K физических регистров разбиты на N окон, в каждом из которых регистры имеют номера от 0 до L–1. Соответственно, в системе… Рис. 47. Регистровые окна.Системный стек
Рис. 49. Системный стек. Но у данного подхода есть и недостаток. Поскольку стек располагается в оперативной памяти, то при каждой обработке…Виртуальная память
Итак, аппарат виртуальной памяти — это аппаратные средства компьютера, обеспечивающие преобразование (установление соответствия) программных… Механизм базирования адресов основан на двоякой интерпретации получаемых в… Аппарат базирования позволяет разрешить проблему перемещаемости программ по ОЗУ, поскольку процесс можно загрузить в…Многомашинные, многопроцессорные ассоциации
Начиная данную тему, мы, следуя традиционному научному подходу, сначала рассмотрим классификацию — это позволит выявить среди большого разнообразия… Для классификации существуют множество методов, проводящих деление по… В контексте машины можно выделить два потока информации: поток управления (для передачи управляющих воздействий на…Терминальные комплексы (ТК)
Суть ТК заключается в следующем. Пусть имеется некая вычислительная система. Ставится задача организовать массовый доступ к ее ресурсам. Под… Рис. 56. Терминальные комплексы.Компьютерные сети
Компьютерная сеть — это объединение компьютеров (или вычислительных систем), взаимодействующих через коммуникационную среду (Рис. 57). Коммуникационная среда — каналы и средства передачи данных. Можно выделить следующие свойства компьютерных сетей. Во-первых, сеть может состоять из значительного числа связанных…Основы архитектуры операционных систем
Операционная система — это комплекс программ, в функции которого входит обеспечение контроля за существованием, использованием и распределением… Начнем с того, что операционная система обеспечивает контроль за… Следующий пункт — использование ресурсов. Здесь имеется в виду, что операционная система предоставляет все средства,…Структура ОС
Простейшая структурная организация основана на представлении операционной системы в виде композиции следующих компонентов (Рис. 64). Рис. 64. Структурная организация ОС.Логические функции ОС
На уровне управления процессами решаются проблемы формирования процессов, поддержание жизненного цикла процесса, организация взаимодействия… Блок управления оперативной памятью реализует программную поддержку той или… Функции планирования можно понимать с разных точек зрения. Можно понимать планирование в узком смысле слова, т.е.…Типы операционных систем
Пакетная операционная система — это система, критерием эффективности функционирования которой минимизация потерь работы центрального процессора.… Пакет программ — это некоторая совокупность программ, которые необходимо… Первая причина — завершение выполнения процесса (в силу успешного перехода на точку завершения программы или же в силу…Управление процессами
Основные концепции
Также ранее отмечалось, что одной из функций логического блока управления процессами ОС является функция поддержания жизненного цикла процесса.… Выделим следующие типовые этапы жизненного цикла процесса: - образование (порождение или формирование) процесса,Модели операционных систем
Теперь рассмотрим модели операционных систем того или иного класса систем, и начнем мы рассмотрение моделипакетной однопроцессной системы (Рис. 69).… Рис. 69. Модель пакетной однопроцессной системы. 0 — поступление процесса в очередь на начало обработки ЦП (процесс…Типы процессов
Полновесные процессы (иногда их называют просто процессы) — это те процессы, машинный код которых обладает эксклюзивными правами на владение… Альтернативой являются т.н. легковесные процессы, известные также как нити, —…Контекст процесса
- пользовательская составляющая — это совокупность машинных команд и данных, которые характеризуют выполнение данного процесса; - системная составляющая, которая содержит в себе информацию об именовании,…Реализация процессов в ОС Unix
Процесс ОС Unix
С точки зрения понимания термина процесса в ОС Unix данное понятие можно определить двояко. В первом случае процесс можно определить как объект,… Остановимся сначала на первой трактовке процесса. В операционной системе… Пользовательская составляющая — это тело процесса. В нее входит сегмент кода, который содержит машинные команды и…Базовые средства управления процессами в ОС Unix
Новый процесс наследует почти все атрибуты исходного родительского процесса, за исключением идентификационной информации (т.е. у дочернего процесса,… #include <sys/types.h> #include <unistd.h>Жизненный цикл процесса. Состояния процесса
Рис. 79. Жизненный цикл процессов. Начальное состояние — это состояние создания процесса: после обращения к системному вызову fork() создается новый…Формирование процессов 0 и 1
Рассмотрим детально, как формируются данные процессы, но для этого необходимо разобраться, что происходит в системе при включении компьютера.… Что касается Unix-систем, то указанный загрузчик ОС осуществляет поиск,… Первым делом происходит инициализация системы, которая включает в себя установку начальных параметров в аппаратных…Взаимодействие процессов
Разделяемые ресурсы и синхронизация доступа к ним
Одной[R14] из важных проблем, которые появились в современных операционных системах, является проблема взаимодействия процессов.
Будем говорить, что процессы называются параллельными, если время их выполнения хотя бы частично перекрываются. Т.е. можно сказать, что все процессы, находящиеся в буфере обрабатываемых процессов, являются параллельными, т.к. в той или иной степени их выполнения во времени пересекаются, они существуют одновременно. Не стоит забывать, что, говоря о параллельных процессах, речь идет лишь о псевдопараллелизме, поскольку реально на процессоре может исполняться только один процесс.
Параллельные процессы могут быть независимыми и взаимодействующими. Независимые процессы используют множество независимых ресурсов, т.е. те ресурсы, которые принадлежат независимым процессам, в пересечении дают пустое множество. Альтернативой независимым процессам являются взаимодействующие процессы — те процессы, пересечение множеств ресурсов которых непустое. При этом одни процессы могут оказывать влияние на другие процессы, участвующие в этом взаимодействии.
Совместное использование ресурсов двумя и более процессами, когда каждый из них некоторое время владеет этими ресурсами, называется разделением ресурсов (как аппаратных, так и программных, или виртуальных). Разделяемый ресурс, использование которого организовано таким образом, что он может быть доступен в каждый момент времени только одному из взаимодействующих процессов, называется критическим ресурсом. Соответственно, часть программы, в рамках которой осуществляется работа с критическим ресурсом, называется критической секцией.
При организации корректного взаимодействия процессов очень важно требование, декларирующее, что результат работы взаимодействующих процессов не должен зависеть от порядка переключения выполнения между этими процессами, т.е. от соотношения скорости выполнения данного процесса со скоростями выполнения других процессов.
Рассмотрим пример (Рис. 83). Пусть имеется некоторая общая переменная (разделяемый ресурс) in и два процесса, которые работают с этой переменной. Пусть в некоторый момент времени процесс A присвоил переменной in значение X. Затем в некоторый момент процесс B ввел значение Y этой же переменной in. Далее оба процесса читают эту переменную, и в обоих случаях процессы прочтут значение Y. Возможно, что процессы могли совершить эти действия в ином порядке (поскольку по-другому могли быть обработаны на процессоре), и результат был бы отличным от этого. Соответственно, подобная ситуация, когда процессы конкурируют за разделяемый ресурс, называются гонкой процессов (race conditions).

Рис. 83. Гонка процессов.
Для минимизации проблем, возникающих при гонках, используется взаимное исключение — такой способ работы с разделяемым ресурсом, при котором в тот момент, когда один из процессов работает с разделяемым ресурсом, все остальные процессы не могут иметь к нему доступ. Для организации модели взаимного исключения используются различные модели синхронизации. Прежде, чем рассматривать их, необходимо отметить те проблемы, которые могут возникать при организации взаимного исключения — это тупики и блокировки.
Блокировка — это ситуация, когда доступ к разделяемому ресурсу одного из взаимодействующих процессов не обеспечивается за счет активности более приоритетных процессов. Отметим следующее. Рассмотрим некоторую модель доступа к разделяемому ресурсу, построенную на приоритетах, когда более приоритетный запрос на обращение к ресурсу будет обработан быстрее, чем менее приоритетный. И пусть в этой модели работают два процесса, у которого приоритеты доступа к разделяемому ресурсу разные. Тогда, если более приоритетный процесс будет «часто» выдавать запросы на обращение к ресурсу, может возникнуть ситуация, когда второй процесс будет «вечно» (или достаточно долго) ожидать обработки каждого своего запроса, т.е. этот менее приоритетный процесс будет блокирован.
Тупик, или deadlock, — это ситуация «клинчевая», когда из-за некорректной организации доступа к разделяемым ресурсам происходит взаимоблокировка. Рассмотрим пример тупиковой ситуации(Рис. 84).

Рис. 84. Пример тупиковой ситуации (deadlock).
Предположим, что есть два процесса A и B, а также пара критических ресурсов. Пускай в некоторый момент времени процесс A вошел в критическую секцию работы с ресурсом 1. Это означает, что доступ любого другого процесса к данному ресурсу будет блокирован. Пусть также в это время процесс B войдет в критическую секцию ресурса 2. И этот ресурс также будет блокирован для доступа другим процессам. Пускай процесс A, не выходя из критической секции ресурса 1, пытается захватить ресурс 2. Но последний уже захвачен процессом B, и процесс A блокируется. Аналогично, пускай процесс B, не освобождая ресурс 2, пытается захватить ресурс 1 и также блокируется. Это пример простейшего тупика. Из него процессы никогда не смогут выйти. Соответственно, решением в данном случае может быть перезапуск системы или уничтожение обоих или одного из процессов.
Способы организации взаимного исключения
Семафоры Дейкстры — это формальная модель организации доступа, предложенная голландским ученым Дейкстрой, которая основывается на следующей… Операция down(S) проверяет значение семафора S, и если оно больше нуля, то… Операция up(S) увеличивает значение семафора на 1. При этом, если в системе присутствуют процессы, блокированные ранее…Классические задачи синхронизации процессов
Классические задачи синхронизации процессов отражают разные модели взаимодействия и демонстрируют использование механизма семафоров для организации такого взаимодействия.
Обедающие философы(Рис. 86). Пускай существует круглый стол, за которым сидит группа философов: они пришли пообщаться и покушать. Кушают они спагетти, которое находится в общей миске, стоящей в центре стола. Для приема пищи они пользуются двумя вилками: одна в левой руке, другая — в правой. Вилки располагаются по одной между каждыми двумя философами. Любой философ может взять обе вилки, покушать, затем положить вилки на стол, после этого вилки может взять его сосед и повторить эти действия. Если мы организуем работу таким образом, что любой философ, желающий поесть, берет сначала левую вилку, затем правую, после чего начинает кушать, то в какой-то момент может возникнуть ситуация тупика (когда каждый возьмет по одной левой вилке, а правая будет захвачена соседом).

Рис. 86. Обещающие философы.
Итак, данная задача иллюстрирует модель доступа равноправных процессов к общему ресурсу, и ставится вопрос, как организовать корректную работу такой системы.
Рассмотрим элементарное решение данной задачи.
#define N 5
void Philosopher(int i)
{
while(TRUE)
{
Think();
/* взятие левой вилки */
TakeFork(i);
/* взятие правой вилки */
TakeFork((i + 1) % N);
Eat();
/* освобождение левой вилки */
PutFork(i);
/* освобождение правой вилки */
PutFork((i + 1) % N);
}
}
Как было показано выше, в данном случае возможно появление ситуации, когда произойдет взаимоблокировка философов. Рассмотрим иное решение.
/* количество философов */
#define N 5
/* Номера левого и правого */
#define LEFT (i-1)%N
#define RIGHT (i+1)%N
/* состояния философов:
«думает»,
«желает поесть»,
«кушает»
*/
#define THINKING 0
#define HUNGRY 1
#define EATING 2
/* переопределяем тип СЕМАФОР */
typedef int semaphore;
/*
массив состояний каждого из философов, инициализированный нулями
*/
int state[N];
/* семафор для доступа в критическую секцию */
semaphore mutex = 1;
/*
массив семафоров по одному на каждого из философов,
инициализированный нулями
*/
semaphore s[N];
/* Процесс-философ (i = 0..N) */
void Philosopher(int i)
{
while(TRUE)
{
Think();
TakeForks(i);
Eat();
PutForks(i);
}
}
/* получение вилок */
void TakeForks(int i)
{
/* вход в критическую секцию */
down(&mutex);
state[i] = HUNGRY;
Test(i);
/* выход из критической секции */
up(&mutex);
down(&s[i]);
}
/* освобождение вилок */
void PutForks(int i)
{
/* вход в критическую секцию */
down(&mutex);
state[i] = THINKING;
Test(LEFT);
Test(RIGHT);
/* выход из критической секции */
up(&mutex);
}
void Test(int i)
{
if(state[i] == HUNGRY &&
state[LEFT] != EATING &&
state[RIGHT] != EATING)
{
state[i] = EATING;
up(&s[i]);
}
}
В этом решении каждый философ живет по аналогичному циклическому распорядку: размышляет некоторое время, затем берет вилки, кушает, кладет вилки. Рассмотрим процедуру получения вилок (TakeForks). Опускается семафор mutex, который используется для синхронизации входа в критическую секцию. Внутри критической секции меняем состояние философа (помечаем его состоянием «голоден»). Затем предпринимается попытка начать есть (вызывается функция Test). Функция Test проверяет, что если i-ый философ голоден, а его соседи в данный момент не едят (т.е. правая и левая вилки свободны), то этот философ начинает прием пищи (состояние EATING), а его семафор поднимается (заметим, что изначально этот семафор инициализирован нулем). После этого мы возвращаемся обратно в функцию TakeForks, в которой далее происходит выход из критической секции (подымаем семафор mutex), а затем опускаем семафор этого философа. Если внутри функции Test философу удалось начать прием пищи, то семафор поднят, и операция down обнулит его, не блокируясь. Если же функция Test не изменит состояние философа, а также не поднимет его семафор, то операция down в этой точке заблокируется до тех пор, пока оба соседа не освободят вилки.
Внутри функции освобождения вилок PutForks первым делом происходит опускание семафора mutex, происходит вход в критическую секцию. Затем меняется статус философа (на статус THINKING), после чего проверяем его соседей: если любой из них был заблокирован лишь из-за того, что наш i-ый философ забрал его вилку, то мы его разблокируем, и он начинает прием пищи. После этого происходит выход из критической секции путем подъема семафора mutex.
Заметим, что использование механизма взаимоисключающего нахождения внутри критической секции (за счет семафора mutex) гарантирует, что не возникнет ситуация, когда два процесса, соответствующие соседним философам, будут так спланированы на обработку на процессоре, что функция Test в каждом из них проработает и разрешит каждому из них начать прием пищи (что, конечно же, является ошибкой). Если же этого механизма не будет, то возможно, что один их процессов-соседей входит в Test, делает проверку на возможность начала приема пищи. Проверка дает истинное значение, управление переходит к первой команде внутри if-блока. После этого происходит смена процесса на процессоре, управление получает сосед этого философа. Тот тоже делает проверку внутри функции Test, и также получает положительный ответ, и управление переходит к первой инструкции if-блока. Дальнейшая работа будет некорректной.
Задача «читателей и писателей». Представим произвольную систему резервирования ресурса. Например, это может быть система резервирования места в гостинице. В данной системе существует два типа процессов для работы с информацией. Одни процессы могут читать информацию, а другие — ее изменять, корректировать. Соответственно, возникает все тот же вопрос, как организовать корректную совместную работу этих процессов. Это означает, что в любой момент времени читать данные могут любое количество процессов-читателей, но если процесс-писатель начал свою работу, то все остальные процессы (и читатели, и писатели) будут блокированы на входе в систему.
Рассмотрим модельную реализацию данной задачи при выбранной следующей стратегии: будем считать, что наиболее приоритетными являются читающие процессы. Т.е. процесс-писатель будет ожидать момента, когда все желающие процессы-читатели окончат свои действия в системе и покинут ее.
/* переопределение типа семафор */
typedef int semaphore;
/* семафор для доступа в критическую секцию */
semaphore mutex = 1;
/* семафор для доступа к хранилищу данных */
semaphore db = 1;
/* количество читателей внутри хранилища */
int rc = 0;
/* процесс-читатель */
void Reader(void)
{
while(true)
{
down(&mutex);
rc = rc + 1;
if(rc == 1)
down(&db);
up(&mutex);
ReadDataBase();
down(&mutex);
rc = rc – 1;
if(rc == 0)
up(&db);
up(&mutex);
UseDataRead();
}
}
/* процесс-писатель */
void Writer(void)
{
while(TRUE)
{
ThinkUpData();
down(&db);
WriteDataBase();
up(&db);
}
}
В приведенном решении процесс-читатель в каждом цикле своей работы входит в критическую секцию (за счет опускания семафора mutex), увеличивает счетчик читателей, находящихся в хранилище, на 1. Затем проверяет, что если он является первым читателем (т.е. в данный момент он единственный клиент в хранилище), то опускает семафор db, тем самым, препятствуя писателем войти в систему, если они того пожелают. Если же семафор db уже был опущен, то это означает, что в данный момент в хранилище присутствует писатель, и этот первый читатель заблокируется на этой операции, ожидая выхода писателя из системы. (Заметим, что это блокировка происходит внутри критической секции, поэтому остальные читатели будут блокироваться на опускании семафора mutex.) После этого происходит выход из критической секции (подымаем семафор mutex), чтение информации из хранилища. Затем производятся обратные действия по выходу из хранилища, которые также происходят внутри критической секции. Итак, на выходе мы уменьшаем число читателей в хранилище, и если этот читатель является последним клиентом в библиотеке, то происходит поднятие семафора db, разрешая работу писателям (которые к этому моменту могли быть заблокированы на входе). В конце цикла работы читатель обрабатывает полученные данные из хранилища, после чего цикл повторяется.
Писатель в начале каждого цикла своей работы подготавливает данные для сохранения, затем пытается войти в хранилище, опуская семафор db. Если в хранилище кто-то есть, то он будет ожидать, пока последний клиент (независимо, читатель это или писатель) не покинет его. После этого он производит корректировку данных в хранилище и покидает его, поднимая семафор db.
Заметим, что в данном решении если хотя бы один читатель находится внутри системы, то любой следующий читатель беспрепятственно в нее попадет, писатель же будет ожидать, когда все посетители покинут хранилище, т.е. реализована стратегия приоритетности читателя перед писателем.
Данная задача иллюстрирует модель доступа к общему ресурсу процессов, имеющих разные приоритеты.
Задача о «спящем парикмахере». Представим себе парикмахерскую, в которой имеется единственно рабочее кресло и единственный цирюльник. В парикмахерской есть комната ожидания, в которой стоят N кресел, на которых могут сидеть клиенты, ожидающие своей очереди. Если свободных кресел нет, то вновь приходящие клиенты сразу же покидают заведение. Когда посетителей нет, парикмахер может сидеть в своем кресле и дремать.
Данная задача является иллюстрацией модели клиент-сервер с ограничением на длину очереди клиентов.
Рассмотрим реализацию данной модели.
/* количество стульев в комнате ожидания */
#define CHAIRS 5
/* переопределение типа СЕМАФОР */
typedef int semaphore;
/* наличие посетителей, ожидающих парикмахера */
semaphore customers = 0;
/*
количество парикмахеров, ожидающих посетителей (0 или 1)
*/
semaphore barbers = 0;
/* семафор для доступа в критическую секцию */
semaphore mutex = 1;
/* количество ожидающих посетителей */
int waiting = 0;
/* Брадобрей */
void Barber(void)
{
while(TRUE)
{
down(&customers);
down(&mutex);
waiting = waiting – 1;
up(&barbers);
up(&mutex);
CutHair();
}
}
/* Посетитель */
void Customer(void)
{
down(&mutex);
if(waiting < CHAIRS)
{
waiting = waiting + 1;
up(&customers);
up(&mutex);
down(&barbers);
GetHaircut();
}
else
{
up(&mutex);
}
}
Процесс-парикмахер первым делом опускает семафор customers, уменьшив тем самым количество ожидающих посетителей на 1. Если в комнате ожидания никого нет, то он «засыпает» в своем кресле, пока не появится клиент, который его разбудит. Затем парикмахер входит в критическую секцию, уменьшает счетчик ожидающих клиентов, поднимает семафор barbers, сигнализируя клиенту о своей готовности его обслужить, а потом выходит из критической секции. После описанных действий он начинает стричь волосы посетителю.
Посетитель парикмахерской входит в критическую секцию. Находясь в ней, он первым делом проверяет, есть ли свободные места в зале ожидания. Если нет, то он просто уходит (покидает критическую секцию, поднимая семафор mutex). Иначе он увеличивает счетчик ожидающих процессов и поднимает семафор customers. Если же этот посетитель является единственным в данный момент клиентом брадобрея, то он этим действием разбудит брадобрея. После этого он выходит из критической секции и «захватывает» брадобрея (опуская семафор barbers). Если же этот семафор опущен, то клиент будет дожидаться, когда брадобрей его поднимет, известив тем самым, что готов к работе. В конце клиент обслуживается (GetHaircut).
Реализация межпроцессного взаимодействия в ОС Unix
Базовые средства реализации взаимодействия процессов в ОС Unix
Если посмотреть на проблемы взаимодействия процессов, то можно выделить две группы взаимодействия. Первая группа — это взаимодействие процессов,… Рассмотрим взаимодействие в рамках локальной ЭВМ (одной ОС). Первым делом…Сигналы
Инициатором отправки сигнала процессу может быть как процесс или ОС. Для иллюстрации приведем следующий пример. Пускай в ходе выполнения некоторого… Инициатором посылки сигнала может выступать другой процесс. В качестве примера… Аппарат сигналов является механизмом асинхронного взаимодействия, момент прихода сигнала процессу заранее неизвестен.…Неименованные каналы
Для доступа к неименованному каналу система ассоциирует с ним два файловых дескриптора. Один из них предназначен для чтения информации из канала,… Организация данных в канале использует стратегию FIFO, т.е. информация, первой… Для создания неименованного канала используется системный вызов pipe().Именованные каналы
Таким образом, файлы FIFO могут использоваться для организации взаимодействия процессов, при этом в отличие от неименованных каналов эти файлы могут… Для создания файлов FIFO в различных реализациях используются разные системные… int mkfifo(char *pathname, mode_t mode);Очередь сообщений IPC
Рис. 90. Очередь сообщений IPC. Для организации работы с очередью предусмотрен набор функций. Во-первых, это уже упомянутая функция создания/доступа к…Разделяемая память IPC
Механизм разделяемой памяти позволяет нескольким процессам получить отображение некоторых страниц из своей виртуальной памяти на общую область физической памяти. Благодаря этому, данные, находящиеся в этой области памяти, будут доступны для чтения и модификации всем процессам, подключившимся к данной области памяти.
Процесс, подключившийся к разделяемой памяти, может затем получить указатель на некоторый адрес в своем виртуальном адресном пространстве, соответствующий данной области разделяемой памяти. После этого он может работать с этой областью памяти аналогично тому, как если бы она была выделена динамически (например, путем обращения к malloc()), однако, как уже говорилось, разделяемая область памяти не уничтожается автоматически даже после того, как процесс, создавший или использовавший ее, перестанет с ней работать.[R22]
Рассмотрим набор системных вызовов для работы с разделяемой памятью. Для создания/подключения к ресурсу разделяемой памяти IPC используется функция shmget().
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/shm.h>
int shmget (key_t key, int size, int shmflg);
Аргументы данной функции: key — ключ для доступа к разделяемой памяти; size задает размер области памяти, к которой процесс желает получить доступ. Если в результате вызова shmget() будет создана новая область разделяемой памяти, то ее размер будет соответствовать значению size. Если же процесс подключается к существующей области разделяемой памяти, то значение size должно быть не более ее размера, иначе вызов вернет -1. Заметим, что если процесс при подключении к существующей области разделяемой памяти указал в аргументе size значение, меньшее ее фактического размера, то впоследствии он сможет получить доступ только к первым size байтам этой области.[R23]
Третий параметр определяет флаги, управляющие поведением вызова. Подробнее алгоритм создания/подключения разделяемого ресурса был описан выше.
В случае успешного завершения вызов возвращает положительное число — дескриптор области памяти, в случае неудачи возвращается -1. Но наличие у процесса дескриптора разделяемой памяти не дает ему возможности работать с ресурсом, поскольку при работе с памятью процесс работает в терминах адресов. Поэтому необходима еще одна функция, которая присоединяет полученную разделяемую память к адресному пространству процесса, — это функция shmat().
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/shm.h>
char *shmat(int shmid, char *shmaddr, int shmflg);
При помощи этого вызова процесс подсоединяет область разделяемой памяти, дескриптор которой указан в shmid, к своему виртуальному адресному пространству. После выполнения этой операции процесс сможет читать и модифицировать данные, находящиеся в области разделяемой памяти, адресуя ее как любую другую область в своем собственном виртуальном адресном пространстве.
В качестве второго аргумента процесс может указать виртуальный адрес в своем адресном пространстве, начиная с которого необходимо подсоединить разделяемую память. Чаще всего, однако, в качестве значения этого аргумента передается 0, что означает, что система сама может выбрать адрес начала разделяемой памяти. Передача конкретного адреса (положительного целого) в этом параметре имеет смысл лишь в определенных случаях, и это означает, что процесс желает связать начало области разделяемой памяти с конкретным адресом. В подобных случаях необходимо учитывать, что возможны коллизии с имеющимся адресным пространством.
Третий аргумент представляет собой комбинацию флагов. В качестве значения этого аргумента может быть указан флаг SHM_RDONLY, который указывает на то, что подсоединяемая область будет использоваться только для чтения. Реализация тех или иных флагов будет зависеть от аппаратной поддержки соответствующего свойства. Если аппаратура не поддерживает защиту памяти от записи, то при установке флага SHM_RDONLY ошибка, связанная с модификацией содержимого памяти, не сможет быть обнаружена (поскольку программным способом невозможно выявить, в какой момент происходит обращение на запись в данную область памяти).
Эта функция возвращает адрес (указатель), начиная с которого будет отображаться присоединяемая разделяемая память. И с этим указателем можно работать стандартными средствами языка C. В случае неудачи вызов возвращает -1.
Соответственно, для открепления разделяемой памяти от адресного пространства процесса используется функция shmdt().
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/shm.h>
int shmdt(char *shmaddr);
Данный вызов позволяет отсоединить разделяемую память, ранее присоединенную посредством вызова shmat(). Параметр shmaddr — адрес прикрепленной к процессу памяти, который был получен при вызове shmat(). В случае успешного выполнения функция вернет значение 0, в случае неудачи возвращается -1.
И, напоследок, рассмотрим функцию shmctl() управления ресурсом разделяемая память.
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/shm.h>
int shmctl(int shmid, int cmd, struct shmid_ds *buf);
Данный вызов используется для получения или изменения процессом управляющих параметров, связанных с областью разделяемой памяти, наложения и снятия блокировки на нее и ее уничтожения. Аргументы вызова — дескриптор области памяти, команда, которую необходимо выполнить, и структура, описывающая управляющие параметры области памяти.
Возможные значения аргумента cmd:
- IPC_STAT — скопировать структуру, описывающую управляющие параметры области памяти;
- IPC_SET — заменить структуру, описывающую управляющие параметры области памяти, на структуру, находящуюся по адресу, указанному в параметре buf;
- IPC_RMID — удалить ресурс;
- SHM_LOCK, SHM_UNLOCK — блокировать или разблокировать область памяти. Это единственные средства синхронизации в данном ресурсе, их реализация должна поддерживаться аппаратурой.
Пример. Работа с общей памятью в рамках одного процесса. В данном примере процесс создает ресурс разделяемая память, размером в 100 байт (и соответствующими флагами), присоединяет ее к своему адресному пространству, при этом указатель на начало данной области сохраняется в переменной shmaddr. Дальше процесс производит различные манипуляции, а перед своим завершением он удаляет данную область разделяемой памяти.
int main(int argc, char **argv)
{
key_t key;
char *shmaddr;
key = ftok(“/tmp/ter”, ’S’);
shmid = shmget(key, 100, 0666 | IPC_CREAT | IPC_EXCL);
shmaddr = shmat(shmid, NULL, 0);
/* работаем с разделяемой памятью, как с обычной */
putm(shmaddr);
waitprocess();
shmctl(shmid, IPC_RMID, NULL);
return 0;
}
Массив семафоров IPC
#include <sys/types.h> #include <sys/ipc.h> #include <sys/sem.h>Файловые системы
Основные концепции
Файловая система является с точки зрения пользователя первым виртуальным ресурсом (который появился в операционных системах), достаточно понятным и… С точки зрения аппаратной поддержки можно выделить следующие этапы развития.… На следующем этапе развития появились устройства прямого доступа (барабаны и магнитные диски), что естественно…Структурная организация файлов
Первой моделью файла явилась модель файла как последовательности байтов. В этом случае содержимое файла представляется как неинтерпретируемая… Следующие модели представляют файл как последовательность записей переменной и… Модель файла как последовательности записей постоянной длины является также аппаратно-ориентированной: она является…Атрибуты файлов
Под именем файла понимается последовательность символов, используя который организуется именованный доступ к данным файла. В одних файловых системах… Следующим немаловажным атрибутом являются права доступа. Данный атрибут… Следующий атрибут — персонификация — связан с предыдущим. Соответственно, данный атрибут содержит информацию о…Основные правила работы с файлами. Типовые программные интерфейсы
Во-первых, это начало работы с файлом (или открытие файла). Большинство систем для процессов, желающих работать с файлом, предполагают наличие… Второй блок действий образуют операции по работе с содержимымфайла (чтение и… Последний этап — это закрытие файла: уведомление системы о закрытии процессом файлового дескриптора (а не файла).…Подходы в практической реализации файловой системы
В приведенной модели работа аппаратного загрузчика основана на предположении о том, что любое системное устройство имеет некоторую предопределенную… Рис. 96. Структура «системного» диска.Модели реализации файлов
Рис. 97. Модель непрерывных файлов. Следующей моделью является модель файлов, имеющих организацию связанного списка (Рис. 98). В этой модели файл состоит…Модели реализации каталогов
Рис. 100. Модели организации каталогов. Одной из проблем, встречающейся в организации каталогов, является проблема длины имени. Изначально эта проблема…Соответствие имени файла и его содержимого
Как отмечалось выше, у любого файла есть его имя как отдельная характеристика файла или же как один из атрибутов файла. В различных файловых… На сегодняшний день почти все современные файловые системы позволяют нарушать… Первая модель — это симметричное, или равноправное, именование. В этом случае с одним и тем же содержимым…Координация использования пространства внешней памяти
Еще одна проблема, на которую стоит обратить внимание, — это проблема учета свободных блоков файловой системы. Здесь тоже существует несколько… Первый подход заключается в том, что вся совокупность свободных блоков… Вторая модель основана на использовании битовых массивов. В этом случае каждому блоку файловой системе ставится в…Квотирование пространства файловой системы
В общем случае модель квотирования может иметь два типа лимитов: жесткий и гибкий. Для каждого пользователя при регистрации его в системе для него… Рис. 103. Квотирование пространства файловой системы.Надежность файловой системы
Минимизация потери информации при аварийных ситуациях может достигаться за счет использования различных систем архивирования, или резервного… Следующая модель заключается в т.н. инкрементном архивировании. Эта модель… Также при архивировании могут использоваться дополнительные приемы, в частности, компрессия. Но тут встает дилемма: с…Проверка целостности файловой системы
Для выявления непротиворечивости и исправления возможных ошибочных ситуаций файловая система использует избыточную информацию, т.е. данные тем или… Рассмотрим модельный пример. В системе формируются две таблицы, каждая из… На втором шаге система запускает процесс анализа блоков на предмет их незанятости. Для каждого свободного блока…Примеры реализаций файловых систем
В[R30] качестве примеров реализаций файловых систем рассмотрим файловые системы, реализованные в ОС Unix. Выбор наш объясняется тем, что создатели ОС Unix изначально выбрали удачную архитектуру файловой системы, причем эту файловую систему нельзя рассматривать в отрыве от самой ОС: ОС Unix строится на понятии файла как одном из фундаментальных понятий (напомним, что вторым важным понятием является понятие процесса). Необходимо заметить, что, как утверждают авторы системы, архитектура файловой системы была заимствована и развита из ОС Multix (файловую систему которой скорее можно назвать экспериментальной, и, как следствие, она не была массово распространена).
В качестве одного из главных достоинств ОС Unix является то, что именно эта система стала одной из первых систем, в которой была реализована иерархическая файловая система. Сама же операционная система строится на понятиях процесса и файла, т.е. все то, с чем мы работаем, является файлом, а это, в свою очередь, означает, что в системе реализованы унифицированные интерфейсы доступа и организации информации.
Еще одно важное достоинство, которое необходимо отметить у ОС Unix, — это то, что она стала одной из первых операционных систем, открытых для расширения набора команд системы. До ее создания практически все команды, которые были доступны пользователю, представлялись в виде набора жестких правил общения человека с системой (сравнимые с современными интерпретаторами команд), модифицировать который не представлялось возможным. Если же требовалось внести коррективы в существующие команды, то необходимо было обратиться к разработчику операционной системы, и тот, по сути, создавал новую систему. В ОС Unix все исполняемые команды принадлежат одной из двух групп: команды, встроенные в интерпретатор команд (например, pwd, cd и т.д.), и команды, реализация которых представляется в виде исполняемых файлов, расположенных в одном из каталогов файловой системы (это либо исполняемый бинарный файл, либо текстовый файл с командами для исполнения интерпретатором команд). Данный подход означает, что, варьируя правами доступа к файлам, уничтожая при необходимости или добавляя новые исполняемые файлы, пользователь способен самостоятельно выстраивать функциональное окружение, необходимое для решения его задач.
Еще одним достоинством этой операционной системы является элегантная организация идентификации доступа и прав доступа к файлам (об этом речь пойдет ниже). Так или иначе, но обозначенные фундаментальные концепции лежат в основе современных операционных систем семейства Unix до сих пор.
Организация файловой системы ОС Unix. Виды файлов. Права доступа
- обычный файл (regular file) — это те файлы, с которыми регулярно имеет дело пользователь в своей повседневной работе (например, текстовый файл,… - каталог (directory) — файл данного типа содержит имена и ссылки на… - специальный файл устройств (special device file) — как отмечалось выше, каждому устройству, с которым работает ОС…Логическая структура каталогов
Прежде всего, необходимо отметить, что файловая система ОС Unix является иерархической древовидной файловой системой (Рис. 109), т.е. у нее есть… Рис. 109. Логическая структура каталогов.Работа с массивами номеров свободных блоков
Рис. 111. Работа с массивами номеров свободных блоков. Работа с массивом номеров свободных блоков достаточно проста. При запросе на получение свободного блока происходит…Работа с массивом свободных индексных дескрипторов
Если происходит освобождение индексного дескриптора (т.е. происходит удаление файла), то происходит обращение к данному массиву. Если в массиве есть… При создании файла происходят обратные действия. Идет обращение к массиву,… Рассмотренные массивы свободных блоков и свободных индексных дескрипторов исполняют роль специализированных КЭШей:…Индексные дескрипторы. Адресация блоков файла
Рис. 112. Индексные дескрипторы. Для каждого индексного дескриптора существует, по меньшей мере, одно имя, зарегистрированное в каталогах файловой…Файл-каталог
Файлы-каталоги (Рис. 114) имеют следующую структурную организацию. Каждая…Достоинства и недостатки файловой системы модели System V
С другой стороны, данная система не лишена недостатков, большая часть которых следует из ее достоинств. Первым недостатком является тот факт, что в… Следующая проблема опять-таки связана с концентрацией информации в суперблоке.… Следующий недостаток связан с фрагментацией блоков файла по диску. Здесь имеется в виду, что при интенсивной работе…Стратегии размещения
Следующей стратегией является равномерность использования блоков данных. Во время создания файла он делится на несколько частей. Часть файла,… И, наконец, третья стратегия размещения — технологическое размещение…Внутренняя организация блоков
Создатели рассматриваемой файловой системы пошли по пути увеличения размера блока. За счет этого 1) уменьшается фрагментация файла по диску и 2)… Размещение файла по блокам файловой системы строится на основе следующей…Выделение пространства для файла
Рис. 119. Выделение пространства для файла. Если, например, размер файла petya.txt увеличивается на столько, что конец файла не помещается в 08 и 09 фрагментах,…Структура каталога FFS
Рис. 120. Структура каталога FFS BSD. Таким образом, система позволяет использовать имена файлов произвольной длины вплоть до 255 символов, что достаточно…Блокировка доступа к содержимому файла
Исключающая блокировка (exclusive lock) — это «жесткая» блокировка: если произошла такая блокировка области, то любой другой процесс не сможет… Альтернативой исключающей блокировке является распределенная блокировка…Управление оперативной памятью
Второй задачей является выбор стратегии распределения памяти. Иными словами, решается задача, какому процессу, в течение которого времени и в каком… Конкретное выделение ресурса тому или иному потребителю является третьей… И, наконец, четвертой задачей является выбор стратегии освобождения памяти. Освобождение памяти можно рассматривать с…Одиночное непрерывное распределение
При таком подходе не возникает особых организационных трудностей. С точки зрения обеспечения корректности функционирования этой модели необходимо… Рис. 121. Одиночное непрерывное распределение.Распределение неперемещаемыми разделами
Данная модель строится по следующим принципам (Рис. 122). Опять же, все адресное пространство оперативной памяти делится на две части. Одна часть отводится под операционную систему, все оставшееся пространство отводится под работу прикладных процессов, причем это пространство заблаговременно делится на N частей (назовем их разделами), каждая из которых в общем случае имеет произвольный фиксированный размер. Эта настройка происходит на уровне операционной системы. Соответственно, очередь прикладных процессов разделяется по этим разделам.
Существуют концептуально два варианта организации этой очереди. Первый вариант (вариант Б) предполагает наличие единственной сквозной очереди, которая по каким-то соображениям распределяется между этими разделами. Второй вариант (вариант А) организован так, что с каждым разделом ассоциируется своя очередь, и поступающий процесс сразу попадает в одну из этих очередей.
Существуют несколько способов аппаратной реализации данной модели. С одной стороны, это использование двух регистров границ, один из которых отвечает за начало, а второй — за конец области прикладного процесса. Выход за ту или иную границу ведет к возникновению прерывания по защите памяти.

Рис. 122. Распределение неперемещаемыми разделами.
Альтернативной аппаратной реализацией может служить механизм ключей защиты (PSW — process[or] status word), которые могут находиться в слове состояния процесса и в слове состояния процессора. Данное решение подразумевает, что каждому разделу ОЗУ ставится в соответствие некоторый ключ защиты. Если аппаратура поддерживает, то в процессоре имеется слово состояния, в котором может находиться ключ защиты доступного в данный момент раздела. Соответственно, у процесса также есть некоторый ключ защиты, который тоже хранится в некотором регистре. Если при обращении к памяти эти ключи защиты совпадают, то доступ считается разрешенным, иначе возникает прерывание по защите памяти.
Рассмотрим теперь алгоритмы, применяемые в данной модели распределения памяти. Сначала рассмотрим алгоритм для модели с N очередями. Сортировка входной очереди процессов по отдельным очередям к разделам сводится к тому, что приходящий процесс размещается в разделе минимального размера, достаточного для размещения данного процесса. Заметим, что в общем случае не гарантируется равномерная загрузка всех очередей, что ведет к неэффективности использования памяти. Возможны ситуации, когда к каким-то разделам имеются большие очереди, а к разделам большего размера очередей вообще нет, т.е. возникает проблема недозагрузки некоторых разделов.
Другая модель с единой очередью процессов является более гибкой. Но она имеет свои проблемы. В частности, возникает проблема выбора процесса из очереди для размещения его в только что освободившийся раздел.
Одно из решений указанной проблемы может состоять в том, что из очереди выбирается первый процесс, помещающийся в освободившемся разделе. Такой алгоритм достаточно простой и не требует просмотра всей очереди процессов. Но в этом случае зачастую возможны ситуации несоответствия размеров процесса и раздела, когда процесс намного меньше этого раздела. Это может привести к тому, что маленькие процессы будут «подавлять» более крупные процессы, которые могли бы поместиться в освободившемся разделе.
Другое решение предлагает, напротив, искать в очереди процесс максимального размера, помещающийся в освободившийся раздел. Очевидно, данный алгоритм требует просмотра всей очереди процессов, но зато он достаточно эффективно обходит проблему фрагментации раздела (возникающей, когда «маленький» процесс загружается в крупный раздел, и оставшаяся часть раздела просто не используется). Как следствие, данный алгоритм подразумевает дискриминацию «маленьких» процессов при выборе очередного процесса для постановки на исполнение.
Чтобы избавиться от последней проблемы, можно воспользоваться некоторой модификацией второго решения, основанного на следующем. Для каждого процесса имеется счетчик дискриминации. Под дискриминацией будем понимать ситуацию, когда в системе освободился раздел, достаточный для загрузки данного раздела, но система планирования ОС его пропустила. Соответственно, при каждой дискриминации из счетчика дискриминации процесса вычитается единица. Тогда при просмотре очереди планировщик первым делом проверяет значение этого счетчика: если его значение — ноль и процесс помещается в освободившемся разделе, то планировщик обязан загрузить данный процесс в этот раздел.
К достоинствам данной модели распределения оперативной памяти можно отнести простоту аппаратных средств организации мультипрограммирования (например, использование двух регистров границ) и простоту используемых алгоритмов. Сделаем небольшое замечание. Если речь идет о модели с N очередями, то никаких дополнительных требований к реализации не возникает. Можно так все организовать, что подготавливаемый процесс в зависимости от его размера будет настраиваться на адресацию соответствующего раздела. Если же речь идет о модели с единой очередью процессов, то появляется требование к перемещаемости кода, это же требование добавляется и к аппаратной части. В данном случае это регистр базы, который может совпадать с одним из регистров границ.
К недостаткам можно отнести внутреннюю фрагментацию в разделах, поскольку зачастую процесс, загруженный в раздел, оказывается меньшего размера, чем сам раздел. Во-вторых, это ограничение предельного размера прикладных процессов размером максимального физического раздела ОЗУ. И, в-третьих, опять-таки весь процесс размещается в памяти, что может привести к неэффективному использованию ресурса (поскольку, как упоминалось выше, зачастую процесс работает с локализованной областью памяти).
Распределение перемещаемыми разделами
Данная модель распределения (Рис. 123) разрешает загрузку произвольного (нефиксированного) числа процессов в оперативную память, и под каждый процесс отводится раздел необходимого размера. Соответственно, система допускает перемещение раздела, а, следовательно, и процесса. Такой подход позволяет избавиться от фрагментации.
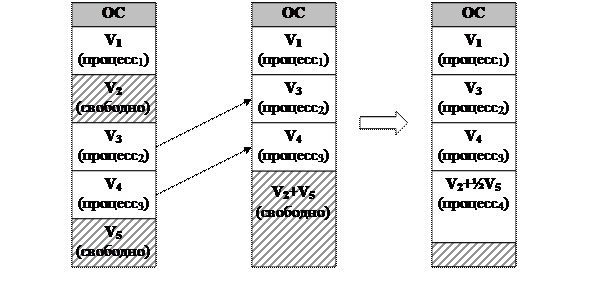
Рис. 123. Распределение перемещаемыми разделами.
По мере функционирования операционной системы после завершений тех или иных процессов пространство оперативной памяти становится все более и более фрагментированным: в памяти присутствует множество небольших участков свободного пространства, суммарный объем которых позволяет поместить достаточно крупный процесс, но каждый из этих участков меньше этого процесса. Для борьбы с фрагментацией используется специальный процесс компрессии. Данная модель позволяет использовать компрессию за счет того, что исполняемый код процессов может перемещаться по оперативной памяти.
Очевидно, что в общем случае операция компрессии достаточно трудоемкая, поэтому существует ряд подходов для ее организации. С одной стороны компрессия может быть локальной, когда система для высвобождения необходимого пространства передвигает небольшое количество процессов (например, два процесса). С другой стороны, возможен вариант, когда в некоторый момент система приостанавливает выполнение всех процессов и начинает их перемещать, например, к началу оперативной памяти, тогда в конце ОЗУ окажется вся свободная память. Таким образом, стратегии могут быть разными.
Что касается аппаратной поддержки, то здесь она аналогична предыдущей модели: требуются аппаратные средства защиты памяти (регистры границ или же ключи защиты) и аппаратные средства, позволяющая осуществлять перемещение процессов (в большинстве случаев для этих целей используется регистр базы, который в некоторых случаях может совпадать с одним из регистров границ). Используемые алгоритмы также достаточно очевидны и могут напоминать алгоритмы, рассмотренные при обсуждении предыдущей модели.
К основному достоинству данной модели распределения памяти необходимо отнести ликвидацию фрагментации памяти. Отметим, что для систем, ориентированных на работу в мультипрограммном пакетном режиме (когда почти каждый процесс является более или менее большой вычислительной задачей), задача дефрагментации, или компрессии, не имеет существенного значения, поскольку для многочасовых вычислительных задач редкая минутная приостановка для совершения компрессии на эффективность системы не влияет. Соответственно, данная модель хорошо подходит для такого класса систем.
Если же, напротив, система предназначена для обработки большого потока задач пользователей, работающих в интерактивном режиме, то частота компрессии будет достаточно частой, а продолжительность компрессии с точки зрения пользователя достаточно большой, что, в конечном счете, будет отрицательно сказываться на эффективности подобной системы.
К недостаткам данной модели необходимо отнести опять-таки ограничение предельного размера прикладного процесса размером физической памяти. И, так или иначе, это накладные расходы, связанные с компрессией. В одних системах они несущественны, в других — напротив, имеют большое значение.
Страничное распределение
Данная модель основывается на том, что все адресное пространство может быть представлено совокупностью блоков фиксированного размера (Рис. 124),… Рис. 124. Страничное распределение.Сегментное распределение
Избавиться от указанных недостатков на концептуальном уровне призвана модель сегментного распределения памяти (Рис. 131). Данная модель представляет… Рис. 131. Сегментное распределение.Сегментно-страничное распределение
Итак, данный механизм подразумевает, что в процессе имеется ряд виртуальных сегментов, которые дробятся на страницы. Поэтому данная модель сочетает… Примером реализации может служить реализация, предложенная компанией Intel.…Управление внешними устройствами
Общие концепции
Архитектура организации управления внешними устройствами
Первой исторической моделью стало непосредственное управление центральным процессором внешними устройствами (Рис. 134.А), когда процессор на уровне… Рис. 134. Модели управления внешними устройствами: непосредственное (А), синхронное/асинхронное (Б), с использованием…Программное управление внешними устройствами
Рис. 135. Иерархия архитектуры программного управления внешними… Можно выделить следующие цели программного управления устройствами. Во-первых, это унификация программных интерфейсов…Планирование дисковых обменов
Будем рассматривать некоторое дисковое устройство, обмен с которым осуществляется дорожками (т.е. происходит обращение и считывание соответствующей… Первая стратегия, которую мы рассмотрим, — стратегия FIFO (First In First…RAID-системы. Уровни RAID
RAID-система — это совокупность физических дисковых устройств, которая представляется в операционной системе как одно устройство, имеющее… RAID-системы предполагают размещение на разных устройствах, составляющих… На сегодняшний день выделяют семь моделей RAID-систем (от нулевой модели до шестой). Рассмотрим их по порядку.Работа с внешними устройствами в ОС Unix
Файлы устройств, драйверы
С точки зрения интерфейсов организации работы с внешними устройствами система делит абсолютно все устройства на две категории: байт-ориентированные… Но, говоря о блок- и байт-ориентированных устройствах, следует помнить, что за… Рассмотрим системную организацию информации, необходимой для управления внешними устройствами. Как упоминалось выше, в…Системные таблицы драйверов устройств
Каждая запись этих таблиц содержит структуру специального формата, называемую коммутатором устройства. Коммутатор устройства хранит указатели на… Стоит отметить следующие типовые имена точек входа в драйвер: - βopen(), βclose();Ситуации, вызывающие обращение к функциям драйвера
Во-вторых, это обработка запросов на обмен. Если процессу необходимо произвести считывание или запись данных, то в этом случае происходит обращение… В-третьих, это обработка прерывания, связанного с данным устройством.… И, в-четвертых, это выполнение специальных команд управления устройством. Функции управления могут быть самыми…Включение, удаление драйверов из системы
Альтернативной моделью, существующей и по сей день, является модель динамического связывания драйверов. В этом случае в системе присутствуют… Для реализации указанной модели в различных системах имеются разные средства:…Организация обмена данными с файлами
Для организации операций обмена в ОС Unix используются системные таблицы и структуры, часть которых ассоциирована с каждым процессом (т.е. они… Таблица открытых файлов (ТОФ) создается в адресном пространстве процесса.… Каждая запись ТОФ содержит целый набор атрибутов, который в данный момент нам не интересен, но в этом наборе имеется…Буферизация при блок-ориентированном обмене
Для буферизации используют пул буферов, размером в один блок каждый. Вкратце рассмотрим алгоритм, состоящий из пяти действий. 1. Поиск заданного блока в буферном пуле. Если удачно, то переход на п.4 2. Поиск буфера в буферном пуле для чтения и размещения заданного блока.Борьба со сбоями
Во-вторых, в системе доступна команда sync, позволяющая осуществлять в любой момент этот сброс информации по желанию пользователя. И, наконец, система использует избыточную информацию, позволяющую… [1] Для создания файла FIFO в UNIX System V.3 и ранее используется системный вызов mknod(), а в BSD UNIX и System V.4…– Конец работы –
Используемые теги: операционные, системы0.055
Если Вам нужно дополнительный материал на эту тему, или Вы не нашли то, что искали, рекомендуем воспользоваться поиском по нашей базе работ: ОПЕРАЦИОННЫЕ СИСТЕМЫ
Что будем делать с полученным материалом:
Если этот материал оказался полезным для Вас, Вы можете сохранить его на свою страничку в социальных сетях:
| Твитнуть |
Хотите получать на электронную почту самые свежие новости?

Подпишитесь на Нашу рассылку
Реклама





Информация в виде рефератов, конспектов, лекций, курсовых и дипломных работ имеют своего автора, которому принадлежат права. Поэтому, прежде чем использовать какую либо информацию с этого сайта, убедитесь, что этим Вы не нарушаете чье либо право.
© copyright 1999 - 2024 allRefs.net. Все права защищены. Страница сгенерирована за: 0.154 сек.
Новости и инфо для студентов