рефераты конспекты курсовые дипломные лекции шпоры

- Раздел Образование
- /
- Министерство образования Российской Федерации
Реферат Курсовая Конспект
Министерство образования Российской Федерации
Министерство образования Российской Федерации - раздел Образование, Министерство Образования Российск...
Министерство образования Российской Федерации
Структуры и алгоритмы обработки данных (Анализ эффективности алгоритмов)Основные сведения
Понятия алгоритма и структуры данных
ЭВМ в настоящее время приходится не только быстро считать и выполнять определенные алгоритмы, но и хранить значительные объемы информации, к которым… С другой стороны, множеству значений, которые может принимать некоторая… 1. структуру хранения данных указанного типа, то есть выделение памяти, представление данных в ней и метод доступа к…Понятия сложности и эффективности алгоритмов и структур данных
1) быть простым для понимания, перевода в программный код и отладки; 2) эффективно использовать вычислительные ресурсы и выполняться по… Если разрабатываемая программа, реализующая некоторый алгоритм, должна выполняться только несколько раз, то первое…Асимптотические обозначения
Асимптотически точная оценка функции роста
Определение1. Вообще, если и положительно определенные функции, то запись означает, что найдутся константы c1 > 0 и c2 > 0 и такое n0 > 0,… (Запись «» читается как «эф от эн есть тэта от же от эн»). Если , то говорят, что является асимптотически точной оценкой (asymptotically tight bound) для . На самом деле это…Свойства асимптотических функций
Транзитивность: и влечёт ; и влечёт ;Сложение и умножение в O-символике
Доказательство. (Доказательство этой теоремы основывается простом соотношении… Поскольку , существует константа с1 и неотрицательное целое число n1 такие, что для всех справедливо .Ограниченность показателя функции роста
Таблица Функция трудоемкости решения задачи, f(n) T1 = 10000 мс T2 = 100*10000 затрат в 100 раз выше … То есть, если выделено T1 времени на ЭВМ для решения задачи этими алгоритмами, тогда мы успеем решить задачу…Основные классы эффективности
В теории анализа эффективности алгоритмов к одному классу относят все функции, чей порядок роста одинаков с точностью до постоянного множителя. Рассмотрим их более подробно.
| Класс трудоемкости | Вид функции трудоемкости | Название подкласса | Примечание | Пример алгоритма данного подкласса |
| Полиномиальный класс (Р-класс) | const | Алгоритм не зависит от длины входных параметров, то есть число операторов постоянно и не измениться не при каком случае. | ||
| log n | логарифмический | Обычно такая зависимость появляется в результате сокращения размера задачи на постоянное значение на каждом шаге итерации алгоритма. Обратите внимание, что в логарифмическом алгоритме исключается работа со всеми входными данными | Алгоритм бинарного поиска (метод деления отрезка пополам) среди n элементов. | |
| n | Линейная | К этому подклассу относятся алгоритмы, выполняющие сканирование списка, состоящего из n элементов. | Поиск элемента массива из n методом последовательного перебора | |

| «n- логарифм n» | К этому подклассу относятся большое количество алгоритмов декомпозиции, где для каждого из n элементов необходимо применить эффективный (например) поиск за логарифмическое время | Эффективные алгоритмы сортировки: пирамидальная, фиксированное двухпутевое слияния | |
| n2 | Квадратичная | подобная зависимость характеризует эффективность алгоритмов, содержащих два вложенных цикла, каждый из которых выполняется не более n раз | Простые схемы сортировки, например, пузырьковая, | |

| Кубическая | Как правило, подобная зависимость характеризует эффективность алгоритмов, содержащих три вложенных цикла | Простой алгоритм перемножения матриц | |
| Не детерминировано-полиномиальный (NP-класс) | 
| Экспоненциальная | Данная зависимость типична для алгоритмов, выполняющих обработку всех подмножеств некоторого множества, состоящего из n элементов. | Задача о ханойских башнях. |
| n! | Факториальная | Данная зависимость типична для алгоритмов, выполняющих обработку всех перестановок некоторого множества, состоящего из n элементов | Полный перебор всех сочетаний элементов исходного множества при поиске решения задачи. | |
| Часто термин "экспоненциальный" используется в широком смысле (в том числе и для всего класса) и означает очень высокие порядки роста, имеющий принципиально другой характер поведения по сравнению с полиномом некоторой степени. |
Для примера приведем числа, иллюстрирующие скорость роста для нескольких функций, которые часто используются при оценке временной сложности алгоритмов (см. Таблица 1).
Таблица 1
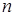
| 
|
| 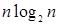
| 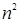
| 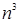
| 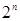
| 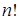
|

| 
|
| 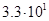
| 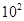
| 
|
| 
|
|
| 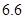
|
| 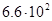
| 
| 
| 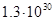
| 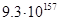
|
|
|
|
| 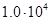
|
| 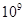
| ||
|
| 
|
| 
| 
| 
| ||

| 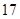
|
| 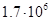
| 
| 
| ||
|
| 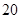
|
| 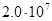
|
|
|
Порядок чисел, приведенных в таблице, имеет чрезвычайное значение для анализа алгоритмов. Как видно из таблицы, самый малый порядок роста имеет логарифмическая функция. Причем его значение настолько мало, что программы, реализующие алгоритмы с логарифмическим количеством основных операций, будут выполняться практически мгновенно для всех диапазонов входных данных реального размера, причем вне зависимости от основания логарифма, так как переход от одного основания к другому есть константа:
loga n = loga b logb n.
Поэтому далее будем опускать основание логарифма, то есть log n.
Если считать, что числа соответствуют микросекундам, то для задачи с 1048476 элементами алгоритму со временем работы T(log n) потребуется 20 микросекунд, а алгоритму со временем работы T(n2) – более 12 дней.
Существует и другая крайность: показательная функция 2n и функция n! – вычисление факториала. Обе эти функции имеют настолько высокий порядок роста, что его значение становится астрономически большим уже при умеренных значениях n. Например, чтобы выполнить 2100 операций компьютеру, имеющему производительность в один триллион операций в секунду, понадобиться без малого 4 • 1010 лет! Однако это ничто по сравнению со временем, которое затратит тот же компьютер на выполнение 100! операций.
Подводя итог, отметим: c помощью алгоритмов, в которых количество выполняемых операций растет по экспоненциальному закону, можно решить лишь задачи очень малых размеров.
Именно для этого и следует на практике оценивать трудоемкость разрабатываемого алгоритма.
Принципы анализа эффективности нерекурсивных алгоритмов
1. Выбрать параметр (или параметры), по которому будет оцениваться размер входных данных алгоритма (например, число элементов массива). 2. Определить основную операцию алгоритма. (Как правило, она находится в… – присваивания;Примеры анализа алогритмов
Пример 1. Рассмотрим задачу поиска наибольшего элемента в списке из n чисел. Для простоты предположим, что этот список реализован в виде массива. Ниже приведен псевдокод алгоритм решения этой задачи.
Алгоритм MaxElement (А [0.. n – 1])
// Входные данные: массив вещественных чисел А[0..n – 1]
// Выходные данные: возвращается значение наибольшего
// элемента массива А
begin
maxval <— А[0]
for i <— 1 to n - 1 do
if A[i] > maxval
then maxval <– А[i]
return maxval
end
Очевидно, что в этом алгоритме размер входных данных нужно оценивать по количеству элементов в массиве, т.е. числом n. Операции, выполняемые чаще всего, находятся во внутреннем цикле for алгоритма. Таких операций две: сравнение (А[i] > maxval) и присваивание (maxval <— А[i]). Какую из них считать базовой? Поскольку сравнение выполняется на каждом шаге цикла, а присваивание — нет, логично считать, что основной операцией алгоритма является операция присваивания. (Обратите внимание, что для любого массива размером n количество операций сравнения в рассматриваемом алгоритме постоянно. Поэтому не имеет смысла отдельно рассматривать эффективность алгоритма для худшего, типичного и лучшего случаев.)
Обозначим через f(n) количество выполняемых в алгоритме операций сравнения и попытаемся вывести формулу, выражающую их зависимость от размера входных данных n. Известно, что за один цикл в алгоритме выполняется одна операция сравнения. Этот процесс повторяется для каждого значения счетчика цикла i, которое изменяется от 1 до n – 1 включительно. Поэтому для f(n) получаем следующую сумму:

Значение этой суммы очень легко вычислить, поскольку в ней единица суммируется сама с собой n – 1 раз. Поэтому
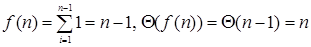 .
.
Пример 2. Рассмотрим задачу проверки единственности элементов, то есть необходимо попарно сравнить элементы и убедиться, что все элементы массива различны.
АЛГОРИТМ UniqueElements (A [0.. n – 1])
// Входные данные: массив вещественных чисел А[0.. n–1]
// Выходные данные: возвращается значение "true", если все
// элементы массива А различны, и "false"– в противном случае
begin
for i <– 0 to n – 2 do
for j <– i + 1 to n – 1 do if A[i] = A[j]
then return false // и досрочное завершение цикла
return true
end
В этом алгоритме, как и в примере 1, размер входных данных вполне естественно оценивать по количеству элементов в массиве, т.е. числом n. Поскольку в наиболее глубоко вложенном внутреннем цикле алгоритма выполнятся только одна операция сравнения двух элементов, ее и будем считать основной операцией этого алгоритма. Обратите внимание, что количество операций сравнения будет зависеть не только от общего числа n элементов в массиве, но и от того, есть ли в массиве одинаковые элементы, и если есть, то на каких позициях они расположены. Ограничимся рассмотрением наихудшего случая.
По определению наихудший случай входных данных соответствует таком) массиву элементов, при обработке которого количество операций сравнений f(n) будет максимальным среди всей совокупности входных массивов размером n. После анализа внутреннего цикла алгоритма приходим к выводу, что наихудший случай входных данных (т.е. когда цикл выполняется от начала до конца, а не завершается досрочно) может возникнуть при обработке массивов двух типов:
а) в которых нет одинаковых элементов;
б) в которых два одинаковых элемента находятся рядом и расположены в самом конце массива.
В подобных случаях при каждом повторе внутреннего цикла в нашем алгоритме выполняется одна операция сравнения. При этом переменная цикла j последовательно принимает значения от i + 1 до n – 1. Внутренний цикл каждый раз повторяется заново при каждом выполнении внешнего цикла. При этом переменная внешнего цикла i последовательно принимает значения от 0 до n – 2. Таким образом, получаем:
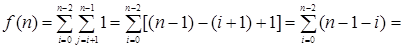
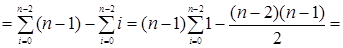
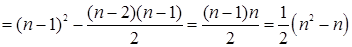
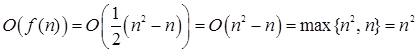
Обратите внимание, что этот результат можно было легко предсказать: в рассматриваемом алгоритме в самом худшем случае для массива, состоящего из n элементов, нужно сравнить между собой все (n–1)n /2 различных пар элементов.
Пример 3. Для двух заданных матриц А и В размером n х n определите временную эффективность алгоритма их умножения С = АВ, основанного на определении этой операции. По определению С – это матрица размером n х n, элементы которой являются скалярными произведениями соответствующих строки матрицы А ни столбца матрицы В, как показано ниже.
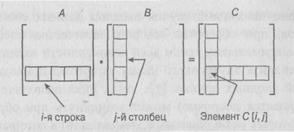
АЛГОРИТМ MatrixMultiplication (A [0..n – 1, 0.. n – 1],
В [0.. n – 1, 0.. n – 1])
// Выполняется умножение двух квадратных матриц
// размером n х n. Используется алгоритм,
// основанный на определении этой операции
// Входные данные: две квадратные n х n матрицы А к В
// Выходные данные: матрица С = АВ
BEGIN
FOR i 0 TO n-1 DO
0 TO n-1 DO
FOR j0 TO n-1 DO
C[i,j]0.0
FOR k0 TO n-1 DO
C[i,j]C[i,j]+A[i, k]*B[k,j]
RETURN C
END
В этом алгоритме размер входных данных соответствует размеру матрицы n. Во внутреннем цикле алгоритма выполняются две арифметические операции: умножение и сложение. В принципе, в качестве основной операции алгоритма можно выбрать как одну, так и другую операцию. Мы рассмотрим случай, когда в качестве основной выбрана операция умножения. Заметьте, что для рассматриваемого алгоритма не обязательно отдавать предпочтение одной из этих операций, поскольку на каждом шаге внутреннего цикла каждая из них выполняется только один раз. Поэтому, подсчитав, сколько раз выполняется одна из операций, мы автоматически подсчитываем и количество выполнения другой операции. А теперь давайте составим сумму для общего числа операций умножения f(n), выполняемых в алгоритме. Поскольку это число зависит только от размера исходных матриц, не требуется отдельно рассматривать наихудший, типичный и наилучший случаи.
Вполне очевидно, что на каждом шаге внутреннего цикла алгоритма выполняется только одна операция умножения. При этом значение переменной цикла k последовательно изменяется от нижней границы 0 до верхней границы n – 1. Поэтому количество операций умножения, выполняемых для каждой пары значений переменных i и j, можно записать следующей тройной суммой:

Для вычисления значения этой суммы воспользуемся формулами из следующего раздела:
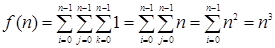 .
.
Рассматриваемый алгоритм достаточно прост.
Время выполнения алгоритма на конкретном компьютере можно оценить с помощью следующего произведения:

 — время выполнения одной команды умножения на рассматриваемом компьютере. Чтобы получить более точную оценку, необходимо также учесть время выполнения команд сложения:
— время выполнения одной команды умножения на рассматриваемом компьютере. Чтобы получить более точную оценку, необходимо также учесть время выполнения команд сложения:

где са ~ время выполнения одной команды сложения. Обратите внимание, что полученная оценка отличается от прежней только постоянным множителем, а не порядком роста.
Формулы, использующиеся при анализе алгоритмов
Свойства логарифмов
lg a означает логарифм по основанию 10; — логарифм по основанию ; х и у — произвольные положительные числа.Комбинаторика
1. Количество перестановок n-элементного множества: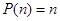
2. Количество k-комбинаций n-элементного множества (сочетаний элементов из n):

3. Количество подмножеств n-элементного множества:
Значение суммы некоторого ряда
2. 3. 4.Правила работы с суммами
2. 3. 4.– Конец работы –
Используемые теги: Министерство, образования, российской, Федерации0.071
Если Вам нужно дополнительный материал на эту тему, или Вы не нашли то, что искали, рекомендуем воспользоваться поиском по нашей базе работ: Министерство образования Российской Федерации
Что будем делать с полученным материалом:
Если этот материал оказался полезным для Вас, Вы можете сохранить его на свою страничку в социальных сетях:
| Твитнуть |
Хотите получать на электронную почту самые свежие новости?

Подпишитесь на Нашу рассылку
Реклама





Информация в виде рефератов, конспектов, лекций, курсовых и дипломных работ имеют своего автора, которому принадлежат права. Поэтому, прежде чем использовать какую либо информацию с этого сайта, убедитесь, что этим Вы не нарушаете чье либо право.
© copyright 1999 - 2024 allRefs.net. Все права защищены. Страница сгенерирована за: 0.138 сек.
Новости и инфо для студентов