рефераты конспекты курсовые дипломные лекции шпоры

- Раздел Образование
- /
- Признаки и переменные. Типы данных и шкалы. Генеральная и выборочная совокупность. Меры центральной тенденции
Реферат Курсовая Конспект
Признаки и переменные. Типы данных и шкалы. Генеральная и выборочная совокупность. Меры центральной тенденции
Признаки и переменные. Типы данных и шкалы. Генеральная и выборочная совокупность. Меры центральной тенденции - раздел Образование, 1 Признаки И Переменные.Признак-Это Объективная Характеристи...
1 Признаки и переменные.ПРИЗНАК-это объективная характеристика единица стат. совокупности характерная черта или свойства которое может быть определено и измерено. Признаки бывают количественными и качественными. У количественного признака отдельные варианты имеют числовое выражение. Качественный признак:1)альтернативный2)атрибутивный имеет больше 2 вариантов и выражается в виде 3)понятий и напоминаний.ПЕРЕМЕННЫЕ – свойство, которое может менять своё значение. Рост является свойством всех людей, но у каждого он разный, а значит является переменной. Пол так же является переменной, но может принимать всего 2 значения. Все показатели тестов в психологии являются переменными. Порядковый имеет несколько различных вариантов. ИЗМЕРЕНИЕ реализуется за счет приписывания объектам значений так, чтобы отношения между значениями отражали отношения между объектами.
2 Типы данных и шкалы1 тип: номинальная или шкала наименований Этот базовый и самый примитивный тип шкалы. При его использовании каждому объекту присваивается только идентификационный номер, как, например, номера игроков в спортивной команде, номера телефонов и т.д. 2 тип: порядковая шкала Этот тип шкалы определяет порядок или ранг объектов наблюдения. Расстояния между объектами, которые следуют друг за другом (по убыванию или по возрастанию) не являются равными. На основании результата ранжирования нельзя сказать, что расстояние между свойствами объектов и равны расстоянию между свойствами объектов и . Часто данный тип шкалы еще называют шкалой восприятия. Например, оценка качества вина по десятибалльной шкале – наиболее понравившееся качество 10 баллов, наименее – 1 балл. 3 тип: интервальная шкала В отличие от порядковой шкалы, здесь имеет значение не только порядок следования величин, но и величина интервала между ними. Пример для данного типа шкалы: температура воды в море утром – 18 градусов, вечером – 24, т.е. вечерняя на 5 градусов выше, но нельзя сказать, что она в 1.33 раз выше. 4 тип: относительная или шкала отношений В отличие от интервальной шкалы может отражать то, во сколько один показатель больше другого. Относительная шкала имеет нулевую точку, которая характеризует отсутствие измеряемого качества. Например: цена на товар. Здесь за точку отсчета можно взять «ноль» рублей. Отметим, что на практике не часто удается привести измерения к данному типу шкалы.
3.Генеральная и выборочная совокупность1.Генеральная (включает все единицы наблюдения, которые могут быть к ней отнесены в соответствии с целью исследования.) Генеральная совокуп¬ность может рассматриваться не только в пределах конкретных производств или территориальных границ, но также и ограничи¬ваться другими признаками (пол, возраст) и их сочетанием. Таким образом, в зависимости от цели исследования и его за¬дач изменяются границы генеральной совокупности, для этого ис¬пользуют основные признаки, ее ограничивающие. 1. Выборочная (часть генеральной совокупности, которая должна быть репрезентативной по отношению к генеральной и наиболее полно отражать ее свойства). На основе анализа вы¬борочной совокупности можно получить достаточно полное пред¬ставление о закономерностях, присущих всей генеральной сово¬купности. Выборочная совокупность должна быть репрезентативной, т. е. в отобранной части должны быть представлены все элементы и в таком же соотношении, как в генеральной совокупности. Иными сло¬вами, выборочная совокупность должна отражать свойства генераль¬ной совокупности, т. е. правильно ее представлять
4. Репрезентативность выборки и типы — это показатель, заключающийся в том, что выборка должна полно и достоверно отображать признаки той совокупности, частью которой она является. Её также можно определять как свойство выборки наиболее полно представлять характеристики генеральной совокупности, существенные с точки зрения цели исследования. Типы выборок -Выборки делятся на два типа:- вероятностные- невероятностные
5. Меры центральной тенденции :мода.медиана.Назначение М. ц. т. — служить сводными количественными характеристиками, обеспечивающими наилучшее описание множества наблюдений или оценок одним единственным числом. Термины М. ц. т. и «средняя величина» часто употребляются как равнозначные, хотя некоторые авторы сужают объем понятия «средняя величина» до среднего арифметического. Несмотря на разнообразие М. ц. т., чаще всего встречаются мода, медиана и среднее. Мода — это просто наиболее часто встречающееся в определенной совокупности наблюдений значение переменной. При сгруппированных данных мода определяется как середина интервала группирования, содержащего наибольшее число значений наблюдаемой переменной. Медиана— это значение переменной, делящее упорядоченную совокупность наблюдений пополам, так что одна половина значений в этой совокупности лежит ниже медианы, а др. их половина — выше медианы. Если совокупность образована нечетным числом значений наблюдаемой переменной, то медиана равна значению переменной, являющемуся серединой упорядоченной совокупности наблюдений. Если же совокупность образована четным числом значений, то медиана определяется значением, лежащим посередине между двумя значениями, находящимися в центре упорядоченной совокупности наблюдений. Медиана — более полезная мера, чем мода, и часто используется в случае скошенного (асимметричного) распределения данных. Следует, однако, отметить, что медиана нечувствительна к величине крайних значений упорядоченной совокупности наблюдений.
6 Меры центральной тенденции:среднее арифметическое.В статистике меры центральной тенденции служат для локализации множества значений вокруг одного единственного числа. При существующем многообразии мер центральной тенденции окончательный выбор меры всегда остается за исследователем.В самых простых случаях (и наиболее часто) в качестве меры центральной тенденции применяется среднее арифметическое, предложенное, наряду со средним геометрическим и средним гармоническим.. Сумма набора значений, поделенная на число значений. Это – наиболее часто используемое и наиболее полезное измерение центральной тенденции, так как в отличие от медианы и моды оно использует все данные распределения и служит основой для измерения вариативности или дисперсии. Когда используется сокращенное обозначение среднего без определения, это можно спокойно принимать как ссылку на среднее арифметическое. Символическое обозначение: М или X.
8 Меры изменчивости: Стандартное отклонение.Меры изменчивости тесно связаны с дисперсией – является стандартное отклонение, которое обычно обозначается Sx (сигма). Оно определяется как положительное значение квадратного корня из дисперсии. 2Sx = Sx Стандартное отклонение часто используется для оценки диапазона изменения наших исходных данных. Для этого применяется правило «трех стандартных отклонений».Стандартное отклонение может быть использовано также в процедуре преобразования исходных данных, которая получила название стандартизации.
7.Меры изменчивости: размах, дисперсия.Самой простой мерой изменчивости является размах выборки, для вычисления которого необходимо из максимального элемента выборки вычесть минимальный. R=xmax-xmin Т.к. размах определяется только двумя элементами выборки, то он не учитывает распределения остальных элементов выборки. ДИСПЕРСИЯ (от лат. dispersio - рассеяние) в математической статистике и теории вероятностей - мера рассеивания (отклонения от среднего). В статистике дисперсия есть среднее арифметическое из квадратов отклонений наблюденных значений (x1, x2,...,xn) случайной величины от их среднего арифметическогоВ теории вероятностей дисперсия случайной величины - математическое ожидание квадрата отклонения случайной величины от ее математического ожидания.
9 группировка данных – это разбиение совокупности на группы, однородные по какому-либо признаку. С точки зрения отдельных единиц совокупности группировка – это объединение отдельных единиц совокупности в группы, однородные по каким-либо признакам. Виды группировок: При проведении группировки приходится решать ряд задач:1) выделение группировочного признака;2) определение числа групп и величины интервалов;3) при наличии нескольких группировочных признаков описание того, как они комбинируются между собой;4) установление показателей, которыми должны характеризоваться группы, т.е. сказуемого группировки.Статистические группировки и классификации преследуют цели выделения качественно однородных совокупностей, изучения структуры совокупности, исследования существующих зависимостей. Каждой из этих целей соответствует особый вид группировки: типологическая, структурная, аналитическая (факторная). Типологическая группировка решает задачу выявления и характеристики социально-экономических типов (частных подсовокупностей).Структурная дает возможность описать составные части совокупности или строение типов, а также проанализировать структурные сдвиги. Аналитическая (факторная) группировка позволяет оценивать связи между взаимодействующими признаками. В зависимости от числа положенных в их основание признаков различают простые и многомерные группировки. Группировка, выполненная по одному признаку, называется простой. Многомерная группировка производится по двум и более признакам. Частным случаем многомерной группировки является комбинационная группировка, базирующаяся на двух и более признаках, взятых во взаимосвязи, в комбинации.является комбинационная группировка, базирующаяся на двух и более признаках, взятых во взаимосвязи, в комбинации.
10.Ститистические таблицы и вариационые ряды.Статистическая таблица — система строк и столбцов, в которой в определенной последовательности излагается статистическая информация о социально-экономических явлениях.Вариационный ряд — упорядоченная по величине последовательность выборочных значений наблюдаемой случайной величины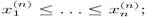 авные между собой элементы выборки нумеруются в произвольном порядке; элементы вариационного ряда называются порядковыми (ранговыми) статистиками; число λm = m / n называется рангом порядковой статистики
авные между собой элементы выборки нумеруются в произвольном порядке; элементы вариационного ряда называются порядковыми (ранговыми) статистиками; число λm = m / n называется рангом порядковой статистики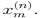 11ГРАФИЧЕСКОЕ ПРЕДСТАВЛЕНИЕ ДАННЫХ - способ наглядного представления данных в виде к--л. геом. образа, количественно соответствующего числовым данным, и изображения его на чертеже, рисунке. Наглядность и быстрота восприятия графич. изображений дают возможность оценки качеств. характеристик, поэтому Г. п. д. позволяет существенно повысить эффективность анализа данных. Г. п. д. ценно тем, что привлекает к процессу анализа интуицию, производя преобразования понятий в образы и образов в понятия.
11ГРАФИЧЕСКОЕ ПРЕДСТАВЛЕНИЕ ДАННЫХ - способ наглядного представления данных в виде к--л. геом. образа, количественно соответствующего числовым данным, и изображения его на чертеже, рисунке. Наглядность и быстрота восприятия графич. изображений дают возможность оценки качеств. характеристик, поэтому Г. п. д. позволяет существенно повысить эффективность анализа данных. Г. п. д. ценно тем, что привлекает к процессу анализа интуицию, производя преобразования понятий в образы и образов в понятия.
12. Полиго́н часто́т и гистограмма— один из способов графического представления плотности вероятности случайной величины. Представляет собой ломаную, соединяющую точки, соответствующие срединным значениям интервалов группировки и частотам этих интервалов.
Гистогра́ммаспособ графического представления табличных данных.
Количественные соотношения некоторого показателя представлены в виде прямоугольников, площади которых пропорциональны. Чаще всего для удобства восприятия ширину прямоугольников берут одинаковую, при этом их высота определяет соотношения отображаемого параметра.
Таким образом, гистограмма представляет собой графическое изображение зависимости частоты попадания элементов выборки от соответствующего интервала группировки.
13.Асимметрия В теории вероятностей и в математической статистике в качестве меры асимметрии распределения является коэффициент асимметрии, который определяется формулой 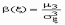 ,
,
где 3 - центральный момент третьего порядка, 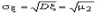 - среднеквадратичное отклонение
- среднеквадратичное отклонение
14 Эксцесс. – это мера крутости кривой распределения.
Эксцесс равен: 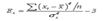
Кривая распределения может быть островершинной, плосковершинной, средне вершинной. Эти четыре момента составляют набор особенностей распределения при анализе данных. Для нормального распределения А=0, Е=0.
Функция ЭКСЦЕСС.Возвращает эксцесс множества данных. Эксцесс характеризует относительную остроконечность или сглаженность распределения по сравнению с нормальным распределением. Положительный эксцесс обозначает относительно остроконечное распределение. Отрицательный эксцесс обозначает относительно сглаженное распределение. : Синтаксис: ЭКСЦЕСС(число1;число2; ...) Число1, число2,... — от 1 до 255 аргументов, для которых вычисляется эксцесс. Можно использовать один массив или одну ссылку на массив вместо аргументов, разделяемых точкой с запятой.,Замечания:Аргументы могут быть либо числами, либо содержащими числа именами, массивами или ссылками. Учитываются вводимые непосредственно в список аргументов логические значения и текстовые представления чисел. Если аргумент, который является массивом или ссылкой, содержит текст, логические значения или пустые ячейки, эти значения игнорируются; ячейки, содержащие нулевые значения, учитываются.Аргументы, представляющие собой значения ошибок или текст, который не может быть преобразован в числа, приводят к возникновению ошибки.Если задано менее четырех точек данных или если стандартное отклонение выборки равно 0, то функция ЭКСЦЕСС возвращает значение ошибки #ДЕЛ/0!.
Эксцесс определяется следующим образом:
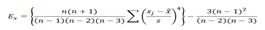
15 Место математической статистики в экспериментальных псих.исл-ях.При статистической обработки результатов психолог исследований заключается в том, что анализируемая база данных характеризуется большим количеством показателей различных типов, их высокой вариативностью под влиянием неконтролируемых случайных явлений, необходимостью учета объективных и субъективных факторов, сложностью корреляционных связей между переменными выборками. Психолог. исл можно разбить на три группы. Первая - это номинальные переменные (пол, возраст и другие анкетные данные и т.д.). Арифметические операции над такими величинами лишены смысла, так что результаты описательной статистики (выборочные средние, дисперсия) к таким величинам не применимы. Классический способ их анализа - разбиение на классы относительно тех или иных номинальных признаков и проверка значимых различий по классам. Вторая группа данных имеет количественную шкалу измерения, но эта шкала является порядковой (ординальной). При анализе ординальных переменных используются как разбиение на подвыборки, так и ранговые технологии (например, нахождение ранговой корреляции). Третья группа - количественные переменные, отражающие степень выраженности замеряемого показателя, - это успеваемость, тесты Амтхауэра, Кеттелла и другие оценочные тесты
1 6 нулевая и альтернативная гипотеза Нулевая гипотеза – это основное проверяемое предположение, которое обычно формулируется как отсутствие различий, отсутствие влияние фактора, отсутствие эффекта, равенство нулю значений выборочных характеристик и т.п. Примером нулевой гипотезы в педагогике является утверждение о том, что различие в результатах выполнения двумя группами учащихся одной и той же контрольной работы вызвано лишь случайными причинами. Другое проверяемое предположение (не всегда строго противоположное или обратное первому) называется конкурирующей или альтернативной гипотезой. Так, для упомянутого выше примера гипотезы Н0 в педагогике одна из возможных альтернатив Н1 будет определена как: уровни выполнения работы в двух группах учащихся различны и это различие определяется влиянием неслучайных факторов, например, тех или других методов обучения. Выдвинутая гипотеза может быть правильной или неправильной, поэ тому возникает необходимость проверить ее. Так как проверку произво дят статистическими методами, то данная проверка называется статистической. При проверке статистических гипотез возможны ошибки (ошибочные суждения) двух видов: — можно отвергнуть нулевую гипотезу, когда она на самом деле верна (так называемая ошибка первого рода); — можно принять нулевую гипотезу, когда она на самом деле не верна (так называемая ошибка второго рода).Ошибка, состоящая в принятии нулевой гипотезы, когда она ложна, качественно отличается от ошибки, состоящей в отвержении гипотезы, когда она истинна. Эта разница очень существенна вследствие того, что различна значимость этих ошибок. Проиллюстрируем вышесказанное на следующем примере.
17.Ошибки первого рода и ошибки второго рода — это ключевые понятия задач проверки статистических гипотез. Ошибка первого рода состоит в том, что будет отвергнута правиль ная гипотеза.Ошибка второго рода состоит в том» что будет принята неправильная гипотеза.Правильное решение может быть принято также в двух случаях: гипотеза принимается; причем и в действительности она правильная; гипотеза отвергается, причем и в действительности она неверна.
18Статистический критерий — строгое математическое правило, по которому принимается или отвергается та или иная статистическая гипотеза с известным уровнем значимости. Построение критерия представляет собой выбор подходящей функции от результатов наблюдений (ряда эмпирически полученных значений признака), которая служит для выявления меры расхождения между эмпирическими значениями и гипотетическими.Параметрическими называются те статистические критерии, которые используют в процессе расчетов параметры распределения, то есть средние значения и дисперсии. Помимо этого, должно выполняться требование соответствия эмпирического распределения нормальному распределению. Примером параметрического критерия может служить t – критерий Стьюдента, позволяющий непосредственно оценивать различия в средних между двумя выборками.Непараметрическими называются критерии, не включающие в формулу расчета параметры распределения, и оперирующие частотами или рангами.
19.Параметрические и непараметрические статические критерии.–это метод стат. вывода, который прим. в отношении параметровгенеральной совокупности. Самым главным усл. для параметрических методов явл. нормальность распределения переменных и, как следствие, правомерность применения таких статистик, как среднее значение и стандартное отклонение. Непараметрические методы не связывают анализ с каким-либо законом распределения.. Они позволяют исследовать данные без каких-либо допущений о характере распределения переменных, в том числе — при нар.требования нормальности распределения.методы предназначены для номинативных и ранговых переменных, в отношении кот.недопустимо применение арифметических операций, они основаны на различных дополнительных вычислениях,Наиболее часто применяемые непараметрические методы: сравнение двух независимых выборок (критерий Манна-Уитни), проводится по двум критериям.
20.Уровень статистической значимости - это вероятность того, что мы сочли различия существенными, а они на самом деле случайны. Когда мы указываем, что различия достоверны на 5% уровне значимости, или при р<0,05. то мы имеем ввиду, что вероятность того, что они недостоверны, составляет 0,05.Если же мы указываем, что различия достоверны на 1% уровне значимости, или при р<0,01, то имеем ввиду, что вероятность того, что они все-таки недостоверны равна 0,01.Иначе, уровень значимости - это вероятность отклонения нулевой гипотезы, в то время как она верна.Ошибка, состоящая в том, что мы отклонили нулевую гипотезу, в то время как она верна, называется ошибкой 1 рода.Вероятность такой ошибки обычно обозначается как а. Поэтому правильнее указывать уровень значимости: а<0,05 или а<0,01.
21. Мощность критерия. Мощность статистического критерия представляет собой вероятность отвержения нулевой гипотезы, когда она фактически неверна. Иными словами, мощность говорит нам о том, насколько вероятно в данном исследовании получить статистически значимый результат, если искомая закономерность действительно имеет место в генеральной совокупности. Из этого определения следует, что любой исследователь кровно заинтересован в высоком значении мощности используемого статистического критерия.
22.Тео́рия приня́тия реше́ний — область исследования, вовлекающая понятия и методы математики, статистики, экономики, менеджмента и психологии с целью изучения закономерностей выбора людьми путей решения разного рода задач, а также способов поиска наиболее выгодных из возможных решений. Принятие решения — это процесс рационального или иррационального выбора альтернатив, имеющий целью достижение осознаваемого результата. Различают нормативную теорию, которая описывает рациональный процесс принятия решения и дескриптивную теорию, описывающую практику принятия решений.
23 не параметрические методы..Тест Мана-Уитни (Mann-Whitney U test) или критерий ранговых сумм Вилкоксона (Wilcoxon Rank-Sum test).
Данный тест (критерий) является непараметрическим аналогом t-теста, когда предположение о нормальности не выполняется. Критерий Мана - Уитни применяется для сравнения двух независимых совокупностей одинаковой или разной численности по их центральной тенденции. Иначе говоря, по данному критерию сравнивают центры двух эмпирических распределений, или эмпирические функции распределений. Выборки могут принадлежать порядковой или количественной шкале. Этот критерий называется ранговым, так как он оперирует не численными значениями вариант, а их рангами. Данный критерий - один из самых популярных тестов среди исследователей-биологов и медиков и, исторически, один из первых критериев, основанных на рангах. U (Mann Whitney U) - статистика критерия. U- сколько раз Y предшествует X в объединённой ранжированной выборке. U связано с суммой рангов W как
U = W - nx (nx - 1) / 2 Среднее Wx = nx (nx + ny + 1) / 2 При уровене значимости < 0.05 принимается конкурирующая гипотеза о различии выборок.Критерий рекомендуется для выборок умеренной численности (численность каждой выборки от 12 до 40).
24 Непараметрические методы сравнения выборки. Сравнение более 2ух выборок. Критерий Н-Краскала-Уоллиса Непараметрические методы математической статистики - методы непосредственной оценки и проверки гипотез о теоретическом распределении вероятностей и тех или иных его общих свойствах (симметрии, независимости и т. п.) по результатам наблюдений.Сравнение выборок производится с помощью различных статистических критериев: t-критерий Стьюдента ;T-критерий Вилкоксона; U-критерий Манна-Уитни;Критерий знаков; и др. Критерий Краскела-Уоллиса предназначен для оценки различий одновременно между тремя, четырьмя и т.д. выборками по уровню какого-либо признака.Критерий Н иногда рассматривается как непараметрический аналог метода дисперсионного однофакторного анализа для несвязных выборок.Критерий является продолжением критерия U на большее, чем 2, количество сопоставляемых выборок.
25.Непараметрический метод сравнения выборок. Сравнение 2 зависимых выборок Критерий Т-Вилкоксона Не включает формулу расчета параметры распределения основаны на апперированием частотамиили рангами.Зависимые выборки:до и после,пары близнецов,мужья и жены. Критерий Т-Вилкоксона-для сопостовления показателей изменений в 2 разных условиях на 1 и той же выборке.Можно определить явл. ли сдвиг показателя в каком то направлении более сужественным.
27 выявление различий в распределении признака ПирсонаПри сопоставлении эмпирического распределения признака с теоретическим; при сопоставлении двух или более эмпирических распределений одного и того же признака.Метод позволяет сопоставлять распределения признаков, представленных в любой шкале, начиная от шкалы наименований. В самом простом случае «есть результат – нет результата» уже можно пользоваться данным критерием. Метод требует тщательной группировки данных и сложных вычислений.
28.Многофункциональные критерии. – кот.могут исп. по отношен. к самым разнообразным данным, выборкам и задачам. К числу таких критериев относится критерий φ* Фишера (угловое преобразование Фишера) и, с некоторыми оговорками - биномиальный критерий m. Эти критерии построены на сопоставлении долей, выраженных в долях единицы или в %. Суть критериев состоит в определении того, какая доля наблюдений (реакций, выборов, испытуемых) в данной выборке характеризуется интересующим исследователя эффектом и какая доля этим эффектом не характеризуется.Критерий φ* — угловое преобразование Фишера-предназначен для сопоставлен. двух выборок по частоте встречаемости интересующего исследователя эффекта, оценивает достоверность различий м/ж %-ми долями двух выборок, в которых зарегистрирован интересующий нас эффект.
29 Частотные таблицы.Каждая строка частотной таблицы описывает одно возможное значение. Строка с пометкой нет данных представляет наблюдения, в которых не было дано никакого ответа. Всего имеется 107 допустимых ответов, а также одно наблюдение, в котором психическое состояние неизвестно. Первый столбец содержит метки отдельных значений (крайне неустойчивое, неустойчивое, устойчивое, ..). Во втором столбце под заголовком «Частота» приведена частота каждого из вариантов ответа на вопрос из теста. В третьем столбце показана процентная частота каждого ответа. Процентная частота соответствует отношению каждого из вариантов ответа к общему количеству опрашиваемых, включая утерянные значения. В четвертом столбце дано допустимое процентное значение. При определении этого значения утерянные данные исключаются.Последний столбец содержит накопленные процентные значения. Накопленные проценты — это сумма процентных частот допустимых ответов.В последней строке содержится сумма всех столбцов (Всего)
30 Таблицы сопряженностиТаблица сопряженности - средство представления совместного распределения двух переменных, предназначенное для исследования связи между ними. Таблица сопряженности является наиболее универсальным средством изучения статистических связей, так как в ней могут быть представлены переменные с любым уровнем измерения.
Простейшая форма кросстабуляции - это таблица сопряженности 2 x 2. К примеру, пусть проводится исследование, в котором мужчины и женщины опрашиваются о том, какой напиток они предпочитают (газированную воду марки A или газированную воду марки B); файл данных может быть ПОЛ ГАЗ.ВОДА
наблюдение 1 мужчина А
наблюдение 2 женщина В
наблюдение 3 женщина В
наблюдение 4 женщина
… … …
Результаты:
ГАЗ. ВОДА: A ГАЗ. ВОДА: B
ПОЛ: мужчина 20 (40%) 30 (60%) 50 (50%)
ПОЛ: женщина 30 (60%) 20 (40%) 50 (50%)
50 (50%) 50 (50%) 100 (100%)
33. Коэффициент линейной корреляции Пирсона Наиболее распространенный коэффициент корреляции. Предназначен для расчета силы и направления линейной зависимости между переменными исследования.
Смысл коэффициента линейной корреляции.
Коэффициент линейной корреляции отражает меру линейной зависимости между двумя переменными. Предполагается, что переменные измерены в интервальной шкале либо в шкале отношений.
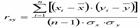 Где xi и yi - сравниваемые количественные признаки, n – число сравниваемых наблюдений, σx и σy – стандартные отклонения в сопоставляемых рядах
Где xi и yi - сравниваемые количественные признаки, n – число сравниваемых наблюдений, σx и σy – стандартные отклонения в сопоставляемых рядах
Понятие корелляции. Коэффициент корреляции как показатель линейной связи.
Линейный коэффициент корреляции
где , — среднее значение выборок. Коэффициент корреляции изменяется в пределах от минус единицы до плюс единицы[11].Корреляция качественных признаков – метод анализа связи переменных, измеряемых в порядковых шкалах и шкалах наименований . Наиболее часто такой корреляционный анализ проводят с помощью коэффициентов ранговой корреляции, используемых в случаях, когда обе переменные измеряются в шкалах порядка или легко могут быть преобразованы в ранги. При измерении сравниваемых переменных в шкалах наименований широко применяются коэффициенты сопряженности, в которых в качестве промежуточной расчетной величины используется критерий согласия Пирсона. Наиболее часто в таких расчетах пользуются коэффициентом сопряженности Пирсона
37 Линейная регрессия.Регрессия - величина, выражающая зависимость среднего значения случайной величины у от значений случайной величины х.Уравнение регрессии выражает среднюю величину одного признака как функцию другого.линейная - регрессия, применяемая в статистике в виде четкой экономической интерпретации ее параметров: у = а+b*х+Е;Функция регрессии - это модель вида у = л», где у - зависимая переменная (результативный признак); х - независимая, или объясняющая, переменная (признак-фактор). Линия регрессии - график функции у = f (x)
38 Множественная линейная регрессия – уравнение связи с несколькими независимыми переменными: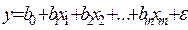 , где у – зависимая (объясняемая, эндогенная) – регрессанд; x1, x2, , xm – независимые (объясняющие, экзогенные) переменные – регрессоры, e – случайная составляющая модели.
, где у – зависимая (объясняемая, эндогенная) – регрессанд; x1, x2, , xm – независимые (объясняющие, экзогенные) переменные – регрессоры, e – случайная составляющая модели.
39 Зависимые и не зависимые переменные.Термины зависимая и независимая переменная обычно применяются в экспериментальных исследованиях, где приходится манипулировать некоторыми переменными. В этом смысле "независимость" переменной определяется как независимость от реакции, свойств и намерений объектов эксперимента и т.п. Некоторые переменные предполагаются "зависимыми" от действий объекта эксперимента или условий эксперимента. Эти переменные, возможно в неявной форме, содержат некоторую информацию о поведении или реакции объекта в ходе эксперимента. Независимые переменные - это переменные, значениями которых можно управлять, а зависимые переменные - это переменные, которые можно только измерять или регистрировать.
40. Дисперсионный анализ – анализ изменчивости признака под влиянием каких-либо контролируемых переменных факторов. задача дисперсионного анализа состоит в том, чтобы из общей вариативности признака выделить три частные вариативности:- Вариативность, обусловленную действием каждой из исследуемых независимых переменных.- Вариативность, обусловленную взаимодействием исследуемых независмых переменных.- Вариативность случайную, обусловленную всеми неучтенными обстоятельствами. Вариативность, обусловленная действием исследуемых переменных и их взаимодействием соотносится со случайной вариативностью. Показателем этого соотношения является F – критерий Фишера (метод, не имеющий ничего общего, кроме автора, с «угловым преобразованием Фишера»). FэмпА = Вариативность, обусловленная действием переменной А / Случайная вариативность FэмпБ = Вариативность, обусловленная действием переменной Б / Случайная вариативность FэмпАБ = Вариативность, обусловленная взаимодействием А и Б / Случайная вариативность
Виды дисперсеонного анализа.Однофакторный Д.А для незвязных выборокВиды дисперсионного анализа.Дисперсионный анализ схематически можно подразделить на несколько категорий. Это деление осуществляется, смотря по тому, сколько, во-первых, факторов принимает участие в рассмотрении, во-вторых, - сколько переменных подвержены действию факторов, и, в-третьих, - по тому, как соотносятся друг с другом выборки значений.При наличии одного фактора, влияние которого исследуется, дисперсионный анализ именуется однофакторным, и распадается на две разновидности:- Анализ несвязанных (то есть – различных) выборок. Например, одна группа респондентов решает задачу в условиях тишины, вторая – в шумной комнате. (В этом случае, к слову, нулевая гипотеза звучала бы так: «среднее время решения задач такого-то типа будет одинаково в тишине и в шумном помещении», то есть не зависит от фактора шума. Анализ связанных выборок. То есть: двух замеров, проведенных на одной и той же группе респондентов в разных условиях. Тот же пример: в первый раз задача решалась в тишине, второй – сходная задача – в условиях шумовых помех. (На практике к подобным опытам следует подходить с осторожностью, поскольку в действие может вступить неучтенный фактор «научаемость», влияние которого исследователь рискует приписать изменению условий, а именно, - шуму.В случае, если исследуется одновременное воздействие двух или более факторов, мы имеем дело с многофакторным дисперсионным анализом, который также можно подразделить по типу выборки.Если же Однофакторный дисперсионный анализ для несвязанных выборок.Метод однофакторного дисперсионного анализа применяется в тех случаях, когда исследуются изменения результативного признака (зависимой переменной) под влиянием изменяющихся условий или градаций какого-либо фактора. Влиянию каждой из градаций фактора подвержены разные выборки.Должно быть не менее трех градаций фактора и не менее двух наблюдений в каждой градации.Описание метода.Расчеты начинаются с расстановки всех данных по столбцам, относящимся к каждому из факторов соответственно.Следующим действием будет нахождение сумм значений по столбцам (то есть – градациям) и возведение их в квадратФактически метод состоит в сопоставлении каждой из полученных и возведенных в квадрат сумм с суммой квадратов всех значений, полученных во всем эксперименте.воздействию факторов подвержено несколько переменных, - речь идет о многомерном анализе.
42.Факторный анализ, Назначение.ф.а — многомерный метод, применяемый для изучения взаимосвязей между значениями переменных. Предполагается, что известные переменные зависят от меньшего количества неизвестных переменных и случайной ошибки.Факторный анализ – определение влияния факторов на результат - является одним из сильнейших методических решений в анализе хозяйственной деятельности компаний для принятия решений. Для руководителей - дополнительный аргумент, дополнительный "угол зрения". Факторный анализ позволяет решить две важные проблемы исследователя: описать объект измерения всесторонне и в то же время компактно. С помощью факторного анализа возможно выявление скрытых переменных факторов, отвечающих за наличие линейных статистических связей корреляций между наблюдаемыми переменными. Таким образом можно выделить 2 цели Факторного анализа: определение взаимосвязей между переменными, (классификация переменных), т. е. «объективная R-классификация»[1][2]; сокращение числа переменных необходимых для описания данных.
44.Вращение и интерпретация факторов. Цель вращения – получить простую структуру, которой соответствует большое значение нагрузки каждой переменной только по одному фактору и малое по всем остальным факторам. Нагрузка отражает связь между переменной и фактором, являясь подобием коэффициента корреляции. Значение нагрузки лежит в пределах [-1;1].
45.Понятие о кластерном анализе.Назначение кластерного анализамногомерная статистическая процедура, выполняющая сбор данных, содержащих информацию о выборке объектов, и затем упорядочивающая объекты в сравнительно однородные группы[1][2][3][4]. Задача кластеризации относится к статистической обработке, а также к широкому классу задач обучения без учителя
Кластерный анализ выполняет следующие основные задачи:Разработка типологии или классификации.Исследование полезных концептуальных схем группирования объектов.Порождение гипотез на основе исследования данных.Проверка гипотез или исследования для определения, действительно ли типы (группы), выделенные тем или иным способом, присутствуют в имеющихся данных.
46.Метод кластерного анализа.Выполняет сбор данных,содерж-х инф. о выборке обьектов,и упорядочивающая их в сравнительно однородные группы.Задачи: разработка типологии или классификации. Порождение гипотез на осн. исследования данных.Проверка гипотез для определения действительно ли группы ,выделенные присутствуют в имеющихся данных. Кластеризуются только количественные данные
– Конец работы –
Используемые теги: знаки, Переменные, типы, данных, шкалы, Генеральная, выборочная, Совокупность, меры, Центральной, тенденции0.143
Если Вам нужно дополнительный материал на эту тему, или Вы не нашли то, что искали, рекомендуем воспользоваться поиском по нашей базе работ: Признаки и переменные. Типы данных и шкалы. Генеральная и выборочная совокупность. Меры центральной тенденции
Что будем делать с полученным материалом:
Если этот материал оказался полезным для Вас, Вы можете сохранить его на свою страничку в социальных сетях:
| Твитнуть |
Хотите получать на электронную почту самые свежие новости?

Подпишитесь на Нашу рассылку
Реклама





Информация в виде рефератов, конспектов, лекций, курсовых и дипломных работ имеют своего автора, которому принадлежат права. Поэтому, прежде чем использовать какую либо информацию с этого сайта, убедитесь, что этим Вы не нарушаете чье либо право.
© copyright 1999 - 2024 allRefs.net. Все права защищены. Страница сгенерирована за: 0.229 сек.
Новости и инфо для студентов