рефераты конспекты курсовые дипломные лекции шпоры

- Раздел Философия
- /
- Общее понятие имитационного моделирования экономических процессов
Реферат Курсовая Конспект
Общее понятие имитационного моделирования экономических процессов
Общее понятие имитационного моделирования экономических процессов - раздел Философия, Общее Понятие Имитационного Модели...
Общее понятие имитационного моделирования экономических процессов.
Имитационное моделирование на цифровых вычислительных машинах является одним из наиболее мощных средств исследования, в частности, сложных… В настоящее время, когда компьютерная промышленность, предлагает…Пакеты визуального моделирования
Одним из главных достоинств систем визуального моделирования является то, что они позволяют пользователю не заботится о программной реализации… Программная реализация виртуального стенда скрыта от пользователя. Для… Еще одной важной особенностью современного пакета автоматизации моделирования является использование технологии…Объектно-ориентированное моделирование
Основные понятия
Объектно-ориентированное моделирование (ООМ) предполагает поддержку классов и экземпляров блоков, а также наследования и полиморфизма блоков.
Класс определяет некоторый шаблон или прототип блока (например, бассейн вообще). Оперируя с классом, например "Бассейн", нельзя говорить о конкретном значении уровня воды в нем, так как в определении класса присутствуют только информация о типах и именах используемых переменных, но не об их значениях.
Экземпляр блока - это конкретный представитель класса блоков, например, Бассейн_1 и Бассейн_2. Каждый экземпляр имеет свои собственные значения переменных (уровни воды в двух бассейнах могут быть разными). При создании нового экземпляра могут быть конкретизированы его параметры - специальные константы, которые не могут быть, как и любые константы, изменены в процессе функционирования, но могут оказаться разными для различных экземпляров. В функциональную схему могут входить несколько экземпляров одного и того же класса, например, выходная труба блока Бассейн_1 может являться входной для блока Бассейн_2.
Экземпляры могут быть статическими и динамическими. Статический экземпляр создается при создании модели и уничтожается при ее уничтожении. Например, каскад бассейнов явно является статической структурой. Динамические экземпляры создаются и уничтожаются в ходе моделирования. Например, при моделировании работы системы ПВО число самолетов в зоне видимости радиолокатора переменно.
Вообще говоря, понятия класса и экземпляра поддерживались явно или неявно практически всеми языками моделирования. В противном случае достаточно сложно моделировать системы с множеством однотипных блоков и невозможно моделировать системы с динамической структурой.
Более сложными понятиями ООМ являются наследование и полиморфизм.
Часто возникает необходимость создать новый класс "такой же, но ...". Например, нужно описать бассейн с подогревом воды, дополнив описание стандартного бассейна нужными деталями. В этом новом классе "Бассейн_с_подогревом" описание интерфейса и динамики уровня воды будет точно таким же, как и в классе "Бассейн". К нему добавится свое описание тепловых потоков и динамики температуры.
Можно просто перенести в описание нового класса элементы описания старого и добавить новые. Но можно объявить новый класс прямым потомком старого. В этом случае класс "Бассейн" будет являться суперклассом (родителем, базовым классом) для класса "Бассейн_с_подогревом", а тот в свою очередь будет являться подклассом (потомком, производным классом) по отношению к классу "Бассейн". В этом случае производный класс автоматически унаследует все элементы описания своего базового класса. Следует отметить, что наследование не означает простого копирования. Между классами возникает постоянная связь: если в классе "Бассейн" добавить новую переменную состояния (например, показатель хлорированности воды), то она автоматически появится в классе "Бассейн_с_подогревом".
Полиморфизм означает возможность использования вместо экземпляра блока некоторого базового класса экземпляра любого его производного класса. Например, для радиолокационной станции все сопровождаемые объекты являются экземплярами класса "Летательный_аппарат" и характеризуются только положением и вектором скорости. На самом же деле эти объекты могут являться самыми разнообразными потомками класса "Летательный_аппарат" от B-52 до птеродактиля.
Библиотеки классов
Наличие богатых библиотек классов является серьезным преимуществом той или иной системы моделирования. В этом случае модель может строиться механически из экземпляров стандартных классов с их параметрической настройкой. Возможности среды увеличиваются, если библиотеки классов создаются самим прикладным пользователем.
Следует отметить, что при построении библиотеки классов чрезвычайно удобным оказывается использование неориентированных блоков, поскольку это дает возможность создавать блоки, максимально независимые от внешнего окружения.
Численное решение
Максимально удобным для численного решения является явное представление моделируемой системы в виде такой гибридной, в которой все скачкообразные… Таким образом, задача численного нахождения решения распадается на… 1) выявление скрытой гибридности в описании непрерывных систем и построение гибридной системы, где узлам приписаны…Существующие подходы к визуальному моделированию сложных динамических систем
Их можно условно разделить на три группы: 1) пакеты "блочного моделирования": 2) пакеты "физического моделирования":Классификация моделей.
- Математические модели.
В основе их построения лежит допущение о том, что все релевантные(переставляемые) переменные, параметры и ограничения, а также целевая функция количественно измеримы. Поэтому, если xj, j=1,2,...,n представляют собой n управляемых переменных и условия функционирования исследуемой экономической системы характеризуются m ограничениями, то математическая модель может быть записана в следующем виде:
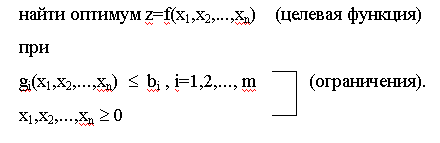
Ограничения x1,x2,...,xn >= 0 называются условиями неотрицательности. Эти условия требуют, чтобы переменные принимали только положительное или нулевое значение. В большинстве практических случаев такое требование вполне естественно. Нахождение оптимума осуществляется для определения наилучшего значения целевой функции, например, максимума прибыли или минимума затрат.
Общие классы математических моделей: модели линейного, целочисленного и динамического программирования, вероятностные модели, модели нелинейного программирования.
- Имитационные модели.
Воспроизводят поведение системы на протяжении некоторого промежутка времени. Это достигается путем идентификации ряда событий, распределение которых во времени дает важную информацию о поведении системы. После того как такие события определены, требуемые характеристики системы необходимо регистрировать только в моменты реализации этих событий. Информация характеристиках системы накапливается в виде статистических данных таких наблюдений. Эта информация обновляется всякий раз при наступлении каждого из интересующих нас событий.
Для построения имитационных моделей не требуется использования математических функций, явным образом связывающих те или иные переменные. Эти модели позволяют имитировать поведение сложных систем, для которых построение математических моделей и получение решений невозможно. Более того, гибкость, присущая имитационным моделям, позволяет добиться более точного представления системы.
Основной недостаток имитационного моделирования заключается в том, что его реализация эквивалентна проведению множества экспериментов, а это неизбежно обусловливает наличие экспериментальных ошибок. Кроме того, сам процесс оптимизации также вызывает затруднения.
- Эвристические методы.
Базируются на интуитивно или эмпирически выбираемых правилах, которые позволяют улучшить уже имеющееся решение. Используются в том случае, когда соответствующие математические построения оказываются настолько сложными, точное решение сформулированной задачи найти нельзя.
По, существу эвристические методы представляют собой процедуры поиска разумного перехода от одной точки пространства решений к некоторой другой точке с целью улучшения текущего значения целевой функции модели. Когда дальнейшего приближения к оптимуму добиться невозможно, лучшее из полученных решений принимается в качестве приближенного решения оптимизационной задачи.
Оптимизация заданной целевой функции.
Основной вывод, который следует из вышеизложенного, заключается в том, что полученное с помощью некоторой модели конкретное оптимальное решение…Проблема информационного обеспечения моделей.
Любая модель экономической системы независимо от ее сложности и адекватности системе-оригиналу принесет мало пользы при отсутствии необходимой информации.
Предположим, например, что некоторое предприятие выпускает продукцию двух видов, изготавливаемую из одного и того же сырья, имеющегося в ограниченном количестве. Пусть расход сырья на изготовление единицы продукции вида 1 равен а1, а продукции вида 2 - а2. Если через b обозначить имеющийся запас сырья, то при объемах производства каждого вида продукции, равных х1 и х2 соответственно, рассматриваемый производственный процесс характеризуется ограничением а1 х1 + а2 х2 <= b . Приступая к решению такой задачи мы должны найти значения а1, а2, и b. Определение этих параметров может оказаться затруднительным и потребовать тщательного анализа большого объема данных, характеризующих работу всего предприятия.
Этапы исследования экономических процессов.
1) идентификации проблемы; 2) построения модели; 3) решения поставленной задачи с помощью модели;Сетевая модель.
Для представления операции используется стрелка, направление которой соответствует процессу реализации программы во времени. Отношение упорядочения между операциями задается с помощью событий. Событие… Начальная и конечная точка любой операции описываются, таким образом, парой событий, которые обычно называют начальным…Правила построения сетевой модели.
Ни одна из операций не должна появляться в модели дважды. При этом следует различать случай, когда какая-либо операция разбивается на части; тогда… Правило 2. Ни одна пара операций не должна определяться одинаковыми начальными… Возможность неоднозначного определения операций через события появляется в случае, когда две или большее число…Моделирование экономических процессов в виде системы массового обслуживания
1) появление заявки на входе в систему; 2) прохождение очереди; 3) процесс обслуживания, после которого заявка покидает систему.Примеры
Пример 1. Обслуживание автомобилей.
Иванов, механик автосервиса, может заменить масло в среднем в трех автомобилях в течение часа (т.е. в среднем на одном автомобиле за 20 мин). Время обслуживания подчиняется экспоненциальному закону. Клиенты, нуждающиеся в этой услуге, приезжают в среднем по два в час, в соответствии с пуассоновским распределением. Клиенты обслуживаются в порядке прибытия, и их число не ограничено. Рассчитайте основные характеристики системы обслуживания.
Решение. На основе исходных данных получаем:
l = 2 машины в час — количество машин, поступающих в течение часа;
m = 3 машины в час — количество машин, обслуживаемых в течение часа;
 машины — среднее количество машин, находящихся в системе;
машины — среднее количество машин, находящихся в системе;
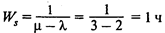 — среднее время ожидания в системе;
— среднее время ожидания в системе;
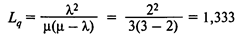 машины — среднее количество машин, ожидающих в очереди;
машины — среднее количество машин, ожидающих в очереди;
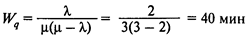 — среднее время ожидания в очереди;
— среднее время ожидания в очереди;
 — доля времени, в течение которого механик занят;
— доля времени, в течение которого механик занят;
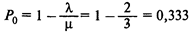 — вероятность того, что в системе нет ни одного клиента.
— вероятность того, что в системе нет ни одного клиента.
Вероятности того, что в системе находится более чем k машин:

Примечание. При k = 0 значение вероятности равно 1 – P0;
при k = 1 существует 44,4% шансов на то, что в системе находится более одной машины, и т.д.
Пример 2. Сопоставление затрат.
После того как мы получили основные характеристики системы обслуживания, часто бывает полезным провести ее экономический анализ. Как уже отмечалось, задачей менеджера является сопоставление возрастающих затрат на улучшение обслуживания и снижающихся затрат, связанных с ожиданием. Рассмотрим этот случай, дополнив условие примера 1.
Владелец автосервиса установил, что затраты, связанные с ожиданием, выражаются в снижении спроса вследствие неудовлетворенности клиентов и равны 100 руб. за час ожидания в очереди. Определите общие затраты функционирования автосервиса.
Решение. Так как в среднем каждая машина ожидает в очереди 2/3 часа (Wq) и в день обслуживается приблизительно 16 машин (l×8 = 2 машины в час в течение 8-часового рабочего дня), общее число часов, которое проводят в очереди все клиенты, равно
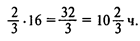
Следовательно, затраты, связанные с ожиданием, составляют
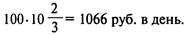
Другая важная составляющая затрат владельца автосервиса — зарплата механика Иванова. Предположим, что он получает 70 руб. в час, или 560 руб. в день. Следовательно, общие затраты составляют
1066 + 560 = 1626 руб. вдень.
Пример 3. Утилизация отходов.
Компания «Утиль» собирает и утилизирует в Мытищах алюминиевые отходы и стеклянные бутылки. Водители автомобилей, доставляющих сырье для вторичной переработки, ожидают в очереди на разгрузку в среднем 15 мин. Время простоя водителя и автомобиля оценивается в 6 тыс. руб. в час.
Новый автоматический компактор может обслуживать контейнеровозы с постоянным темпом 12 машин в час (5 мин на одну машину). Время прибытия контейнеровозов подчиняется пуассоновскому закону с параметром l = 8 автомобилей в час. Если новый компактор будет использоваться, то амортизационные затраты составят 0,3 тыс. руб. на один контейнеровоз. Следует ли использовать компактор?
Решение. Затраты на простой одного автомобиля в очереди за одну ездку в системе без компактора составляют

В системе с компактором время ожидания в очереди при l = 8 автомобилей в час и m = 12 автомобилей в час будет равно

Затраты на простой автомобиля в очереди в этом случае составят
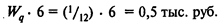
Сокращение времени простоя привело к сокращению затрат на простой одного автомобиля за одну ездку на сумму в 1,5 – 0,5 = 1 тыс. руб.
При условии, что затраты по эксплуатации компактора на один контейнеровоз составляют 0,3 тыс. руб., общие затраты составят 0,5 + 0,3 = 0,8 тыс. руб.
Система с компактором дает экономию в 1,5 – 0,8 = 0,7 тыс. руб. Таким образом, компактор использовать следует.
Имитационное моделирование управления запасами
1) его доля в общем количестве запасов фирмы; 2) его доля в общей стоимости запасов. Методика 20/80.В соответствии с этой методикой компоненты запаса, составляющие 20% его общего количества и 80% его…I. Детерминированные модели
Простейшая модель оптимального размера заказа.
1) темп спроса на товар известен и постоянен; 2) получение заказа мгновенно; 3) закупочная цена не зависит от размера заказа;Модель оптимального размера заказа с фиксированным временем его выполнения.
1) темп спроса на товар известен и постоянен; 2) время выполнения заказа известно и постоянно; 3) закупочная цена не зависит от размера заказа;Модель оптимального размера заказа с производством.
1) темп спроса на товар известен и постоянен; 2) темп производства товара известен и постоянен; 3) время выполнения заказа известно и постоянно;Модель оптимального размера заказа с дефицитом.
1) темп спроса на товар известен и постоянен; 2) время выполнения заказа известно и постоянно; 3) закупочная цена не зависит от размера заказа.Модель оптимального размера заказа с количественными скидками.
1) темп спроса на товар известен и постоянен; 2) время выполнения заказа известно и постоянно. Исходные данные: темп спроса, издержки заказа, издержки хранения, цена товара, количественные скидки в случае закупки…II. Стохастическая модель
Дискретная стохастическая модель оптимизации начального запаса.
Пусть S — размер запаса на начало периода планирования; D — величина спроса за период планирования (целое число); Н — удельные издержки хранения за период;Примеры
Пример 1. Продажа автомобилей.
Андрей Удачливый, торговый агент компании Volvo, занимается продажей последней модели этой марки автомобиля. Годовой спрос на эту модель оценивается в 4000 единиц. Цена каждого автомобиля равна 90 тыс. руб., а годовые издержки хранения составляют 10% от цены самого автомобиля. Анализ показал, что средние издержки заказа составляют 25 тыс. руб. на заказ. Время выполнения заказа — 8 дней. Ежедневный спрос на автомобили равен 20.
Вопросы:
1. Чему равен оптимальный размер заказа?
2. Чему равна точка восстановления?
3. Каковы совокупные издержки?
4. Каково оптимальное количество заказов в год?
5. Каково оптимальное время между двумя заказами, если предположить, что количество рабочих дней в году равно 200?
Решение. Исходные данные:
величина спроса D = 4000 единиц;
издержки заказа K = 25 тыс. руб.;
издержки хранения H = 9/200 тыс. руб.;
цена за единицу с = 90 тыс. руб.;
время выполнения заказа L = 8 дней;
ежедневный спрос d = 20 единиц;
число рабочих дней Т= 200.
Используя простейшую модель оптимального размера заказа, получаем:
размер заказа Q = 149 единиц;
точка восстановления R = 160 единиц;
число заказов за год N= 26,83;
совокупные издержки С = 1341 тыс. руб;
стоимость продаж cD = 360 млн руб.;
число дней между заказами t = 7,45.
Пример 2. Поставка товара с фиксированным интервалом времени.
Магазин «Лада» закупает духи «Ландыш» на одной из парфюмерных фабрик. Годовой спрос на этот продукт составляет 600 шт. Издержки заказа равны 850 руб., издержки хранения — 510 руб за одну упаковку (20 шт.) в год. Магазин заключил договор на поставку с фиксированным интервалом времени.
Количество рабочих дней в году — 300. Время поставки товара — б дней. Стоимость одного флакона — 135 руб.
Вопросы:
1. Чему равно оптимальное число заказов в течение года?
2. Чему равна точка восстановления запаса?
3. Каковы минимальные совокупные издержки?
Решение. Оптимальный размер заказа

Число заказов в течение года
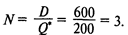
Поскольку среднесуточный спрос равен 600/300 = 2 шт., точка восстановления запаса составит 2 • 6 = 12 шт. Минимальные издержки заказа и хранения
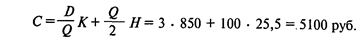
Ответы: 1.3. 2.12шт. 3.5100руб.
Пример 3. Производство деталей.
На первом станке производятся детали в количестве 12 000 единиц в год. Эти детали используются для производства продукции на втором станке производительностью 3600 единиц в год. Оставшиеся детали образуют запас. Издержки хранения составляют 0,5 руб. за одну деталь в год. Стоимость производственного цикла на первом станке равна 800 руб. Определите оптимальный размер партии на первом станке.
Решение. Оптимальный размер партии

Пример 4. Планирование дефицита.
Вернемся к примеру 2 и рассмотрим вариант планирования дефицита. Допустим, по оценке менеджера, упущенная прибыль, связанная с отсутствием товара и утратой доверия клиентов, составляет 20 руб. в год за один флакон духов «Ландыш» при условии, что издержки заказа и хранения остаются без изменения. Определите оптимальный размер заказа при плановом дефиците. Нужно ли менеджеру вводить систему с плановым дефицитом?
Решение. Оптимальный размер заказа
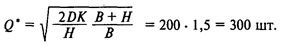
Максимальный размер запаса за один цикл

Совокупные издержки

Совокупные издержки при плановом дефиците меньше издержек без дефицита на 1718,7 руб. Следовательно, целесообразно ввести систему с плановым дефицитом.
Пример 5. Продажи со скидками.
Магазин «Медвежонок» продает игрушечные гоночные машинки. В зависимости от размера заказа фирма предлагает скидки:

Издержки заказа составляют 49 руб. Годовой спрос на машинки равен 5000. Годовые издержки хранения в процентном отношении к цене составляют 20%. Найдите размер заказа, минимизирующий общие издержки.
Решение. Рассчитаем Q* для каждого вида скидок: Q1* = 700, Q2* = 714, Q3* =718.
Так как Q1* находится в интервале между 0 и 1000, то его необходимо взять равным 700. Оптимальный объем со скидкой Q2* меньше количества, необходимого для получения скидки, следовательно, его необходимо принять равным 1000 единиц. Аналогично Q3* берем равным 2000 единиц.
Получим: Q1* = 700, Q2* = 1000, Q3* = 2000.
Далее необходимо рассчитать общие издержки для каждого размера заказа и вида скидок, а затем выбрать наименьшее значение. Расчеты приведены в следующей таблице:
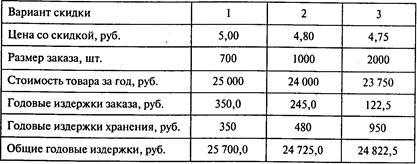
Выберем тот размер заказа, который минимизирует общие годовые издержки. Из таблицы видно, что заказ в размере 1000 игрушечных машинок будет минимизировать совокупные издержки.
Пример 6. Создание запаса продукции при дискретном спросе. Небольшой салон специализируется на продаже видеомагнитофонов стоимостью 2000 руб. Затраты на хранение единицы продукции составляют 500 руб. Изучение спроса, проведенное в течение месяца, дало следующее распределение числа покупаемых видеомагнитофонов:

Найдите оптимальный размер запаса.
Решение. Доказано, что при дискретном случайном спросе суммарные затраты C(S) = Н 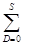 (S–D)p(D) + В
(S–D)p(D) + В (D–S)p(D) минимальны при размере запаса S*, удовлетворяющем неравенству
(D–S)p(D) минимальны при размере запаса S*, удовлетворяющем неравенству 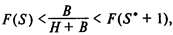 где
где  — плотность убытков, F(S)=р(D<S) — функция распределения величины спроса. Вычислим плотность убытков:
— плотность убытков, F(S)=р(D<S) — функция распределения величины спроса. Вычислим плотность убытков: 
Найдем значения функции распределения величины спроса:

Оптимальный размер запаса продукции удовлетворяет неравенству F(6) < 0,8 < F(7). Следовательно, размер запаса в 6 единиц будет оптимальным.
Основы теории матричных игр
а) заинтересованных сторон; б) возможных действий каждой из сторон; в) интересов сторон.Матричная игра двух лиц с нулевой суммой
Игра, в которой множества А и В стратегий игроков конечны, т.е. |А| < ¥, |В| < ¥, называется матричной. В этом случае функция… Элементы матрицы могут быть положительными, отрицательными или равными нулю.… Игрок 1 стремится к максимальному выигрышу, игрок 2 — к минимальному проигрышу. Решить игру — значит найти…Матричная игра двух лиц с ненулевой постоянной суммой
Такого рода игра сводится к игре двух лиц с нулевой суммой следующим образом: 1) каждому игроку выплачивается сумма с/2; 2) решается игра с нулевой суммой с матрицей выигрышей игрока 1, гдеПримеры
Пример 1. Выбор стратегии. Матрица некоторой игры имеет вид

Найдите оптимальные стратегии игроков.
Решение. В этой игре игрок 1 имеет три возможные стратегии: а1, а2, а3 из, а игрок 2 — четыре возможные стратегии: b1, b2, b3, b4.
Рассмотрим процесс принятия игроками решения (предполагается, что они действуют рационально). Взглянув на таблицу, можно заметить, что если игрок 1 не знает, как поступит его противник, то, действуя наиболее целесообразно и считая, что противник будет действовать подобным же образом, он выберет стратегию а2, которая гарантирует ему наибольший из трех возможных наименьших выигрышей: 9, 13, 8. Другими словами, игрок 1 руководствуется принципом максиминного выигрыша. Этот выигрыш a = 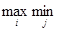 аij есть нижняя цена игры. Для нашего примера a = 13.
аij есть нижняя цена игры. Для нашего примера a = 13.
Игрок 2 рассуждает аналогично: если он выберет стратегию b1, ,то потеряет самое большее 23, если стратегию b2, то — 40, и т.д. В результате он выберет стратегию b3, которая гарантирует ему наименьший из четырех возможных проигрышей: 23, 40, 13, 25. Принято говорить, что игрок 2 руководствуется принципом минимаксного проигрыша. Этот проигрыш b = 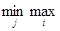 аij есть верхняя цена игры. Для нашей матрицы b = 13.
аij есть верхняя цена игры. Для нашей матрицы b = 13.
Ситуация (a2, b3) есть седловая точка, и a = b = 13 есть цена игры.
При наличии седловой точки ни одному из участников игры невыгодно отклоняться от своей минимаксной стратегии: он будет наказан противником тем, что получит меньший выигрыш.
Пример 2. Где строить?
Две конкурирующие крупные торговые фирмы Ф1 и Ф2 планируют построить в одном из четырех небольших городов Г1, Г2, Г3 и Г4, лежащих вдоль автомагистрали, по одному универсаму. Взаимное расположение городов, расстояние между ними и численность населения показаны на рис. 1.

Рис. 1
Прибыль каждой фирмы зависит от численности населения городов и степени удаленности универсамов от места жительства потенциальных покупателей. Специально проведенное исследование показало, что прибыль в универсамах будет распределяться между фирмами следующим образом:

Например, если универсам фирмы Ф1 расположен к городу Г1 ближе универсама фирмы Ф 2, то прибыль от покупок, сделанных жителями данного города, распределится следующим образом: 75% получит Ф1, остальное — Ф 2.
Представьте описанную ситуацию как игру двух лиц.
В каких городах фирмам целесообразно построить свои универсамы?
Решение. Составим платежную матрицу игры, в которой игроком 1 будет фирма Ф 1, а игроком 2 — фирма Ф2. Стратегии обоих игроков: строить свой универсам в городе Г1, в городе Г2 и т.д. Элементы матрицы — прибыль фирмы Ф1 (в тыс. руб.), которая, как предполагается, пропорциональна (причем с одним и тем же коэффициентом) числу покупателей. Величина указанного коэффициента пропорциональности для выбора оптимального места размещения универсамов значения не имеет, поэтому примем его равным единице.
Платежная матрица имеет вид

Рассмотрим примеры расчета значений элементов (Г1, Г2) и (Г3, Г4) матрицы.
Ситуация (Г1, Г2) означает, что фирма Ф1, строит универсам в городе Г1, а фирма Ф2 — в городе Г2. Число покупателей фирмы Ф1 складывается из покупателей четырех городов. Для ситуации (Г1, Г2) число покупателей из Г1: 0,75×30, из Г2: 0,45×50, из Г3 0,45×40, из Г4: 0,45×30, т.е. в сумме 76,5 тыс. руб. Для ситуации (Г3, Г4) число покупателей из Г1: 0,75×30, из Г2: 0,75×50, из Г3: 0,75×40, из Г4: 0,45×30, т.е. в сумме 103,5 тыс. руб. Элементы матрицы выигрышей фирмы Ф2 — дополнения до числа 150 (общее число жителей в четырех городах). Таким образом, имеет место игра двух лиц с ненулевой постоянной суммой, оптимальные стратегии которой те же, что и для соответствующей игры с нулевой суммой.
Полученная платежная матрица имеет седловую точку (Г2, Г2). Соответствующий элемент матрицы равен 90.
Таким образом, обеим фирмам следует строить свои универсамы в одном и том же городе Г2, при этом прибыль фирмы Ф1 составит 90 тыс., а фирмы Ф2 — 60 тыс. руб.
.
3. Метод Монте-Карло (метод статистических испытаний Имитационное моделирование случайных факторов)состоит из четырех этапов:
1. Построение математической модели системы, описывающей зависимость моделируемых характеристик от значений стохастических переменных.
2. Установление распределения вероятностей для стохастических переменных.
3. Установление интервала случайных чисел для каждой стохастической переменной и генерация случайных чисел.
4. Имитация поведения системы путем проведения многих испытаний и получение оценки моделируемой характеристики системы при фиксированных значениях параметров управления. Оценка точности результата.
Описание этапов:
Первый этап. Стохастическая имитационная модель (ИМ) некоторой реальной системы может быть представлена как динамическая система, которая под воздействием внешних случайных входных сигналов (входных переменных) изменяет свое состояние (случайные переменные состояния), что в свою очередь приводит к изменению выходных сигналов (выходных переменных):
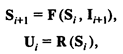
гдеF, R — вектор-функции;
Ii, Ui, Si — векторы соответственно входных, выходных переменных и переменных состояния системы в тактовый момент моделирования i.
Имитационная модель — это экспериментальная модель системы, в которой искусственно воспроизводятся случайности, имеющие место в реальной системе. Она представляет собой совокупность математических соотношений между входными, выходными переменными и переменными состояния в сочетании с алгоритмической реализацией некоторых зависимостей.
Существует два подхода в имитационном моделировании динамических процессов.
Первый заключается в том, что весь период моделирования разбивается на равные промежутки времени (такты моделирования) и анализ состояния системы, а также значений выходных переменных производится через одинаковые промежутки времени. При таком подходе возникает проблема выбора «правильной» продолжительности такта. Кроме того, не исключается появление тактов, в которых состояние системы по сравнению с предыдущим не изменилось.
При втором подходе величина такта моделирования не фиксируется, моделирование в этом случае происходит в момент наступления одного из «существенных» событий. Например, при моделировании производственного процесса на предприятии такими событиями могут быть освобождение или начало загрузки станка, поступление на обработку детали, невыход на работу станочника, исчерпание запаса необходимых комплектующих деталей на складе и др. Именно второй подход чаще всего используется на практике и поддерживается современными языками моделирования.
Второй этап. Случайные величины, используемые в ИМ, могут быть дискретными или непрерывными. В первом случае необходимо знать их распределения, во втором — плотности распределений. Эти зависимости могут быть известны из теории, определены в результате специальных исследований либо заданы в качестве гипотезы. Точность модели (при прочих равных условиях) зависит от того, насколько точно заданы указанные распределения (плотности распределений).
Третий этап. Моделирование случайных величин при компьютерных имитационных экспериментах производится с помощью датчика псевдослучайных чисел, предусмотренного в любом современном языке программирования. Обычно это датчик случайных чисел с равномерным распределением на интервале [0, 1]. Если известны вероятности наступления событий, то, используя такой датчик, можно отвечать на вопросы: «Какое из N возможных событий произошло?» или «Какое значение приняла случайная величина?»
Предположим, что в ИМ используется случайная величина X, принимающая дискретные значения х1, х2,..., хN с вероятностями соответственно p1, p2,..., pN (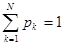 ). Получение некоторой реализации этой переменной в модели производится следующим образом.
). Получение некоторой реализации этой переменной в модели производится следующим образом.
Строится функция распределения случайной величины X. Указанная функция определяется посредством равенства F(X) = åpk, в котором суммирование распространяется на все индексы, для которых хk < X. С помощью датчика случайных чисел получают случайное число и из отрезка [0, 1].
Из равномерности распределения получаемых случайных чисел следует, что вероятность получения случайного числа из произвольного интервала, включенного в [0, 1], равна длине этого интервала. Поэтому вероятность реализации Х = хk равна вероятности попадания полученного от датчика случайного числа и в произвольный интервал длиной pk на отрезке [0, 1]. Можно, таким образом, утверждать, что если очередное число и датчика удовлетворяет неравенствам 0 < и £ р1, то имеет место реализация Х = х1, в случае p1 < и £ p1 + р2 — реализация Х = х2 и т.д. В общем случае для k = 2, ..., N: если  < и £
< и £ 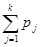 , то Х = хk.
, то Х = хk.
Заметим, что границы указанных неравенств совпадают со значениями построенной выше функции распределения F(X).
Удобнее, однако, иметь дело не с дробными значениями границ интервалов, в которые попадает случайное число и, а с их целочисленными значениями, тем более, что с помощью датчиков случайных чисел можно генерировать числа из любого диапазона. Чтобы получить целые значения границ интервалов, достаточно умножить все pk на 10d, где d — целое, минимальное значение которого равно максимальной точности (максимальному числу знаков после десятичной точки) чисел pk, k = 1,..., N. Например, если {рk} = {0,3; 0,153; 0,5; 0,047}, то минимальное значение d равно 3 (все рk нужно умножить на 1000). Таким образом, 10d определяет длину интервала значений рассматриваемой случайной величины в ИМ.
Четвертый этап. Точность статистических оценок параметров реальной системы зависит от числа наблюдений (объема выборки). Погрешности в оценках обусловлены как статистическим характером самой модели, так и влиянием начальных данных (начального состояния имитационной системы), а также возможной автокорреляцией последовательных значений некоторого параметра в процессе моделирования. Очевидно, что с увеличением числа испытаний точность моделирования должна возрастать. Ввиду того что увеличение объема выборки связано с ростом затрат на моделирование, важно уметь определять минимальное число испытаний, необходимое для достижения заданной точности оценки с заданной вероятностью.
Широкое распространение получили два метода статистических испытаний. Один из них предполагает проведение достаточно большого числа Т последовательных наблюдений в течение одного прогона модели (одного сеанса имитирования).
Другой метод заключается в реализации т независимых прогонов модели, т.е. в m-кратном повторении одного и того же цикла имитирования. При этом, если мы хотим получить в сумме Т наблюдений, в течение каждого прогона можно делать по Т/т (допустим, что это число целое) наблюдений. Оба метода дают примерно одинаковый результат.
Пусть значения уt (t = 1,..., Т) представляют собой результаты Т последовательных измерений значений случайной величины y во время одного и того же сеанса имитации. Среднее по времени значение у определяется выражением
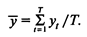
Обозначим через математическое ожидание случайной величины у. Тогда для достаточно большого T получаем
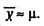
Оценка дисперсии  (если временной ряд не является автокоррелированным) имеет вид
(если временной ряд не является автокоррелированным) имеет вид

где D(у) — дисперсия случайной величины у.
Для оценки качества результатов, полученных методом Монте-Карло при неизвестной дисперсии наблюдаемой случайной величины, предположим, что Z — характеристика, которая должна быть определена (вероятность события, математическое ожидание, дисперсия и т.п.), a x — ее значение, уточняемое по мере накопления данных, остающееся случайным вследствие ограниченности числа T проведенных наблюдений. В этих условиях можно говорить о вероятности p(|Z – x| < ) по отношению к интересующей нас характеристике. Величина |Z – | представляет собой погрешность в оценке Z, a — некоторый допустимый ее предел.
Из неравенства Чебышёва следует
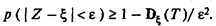
Из этого неравенства следует
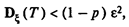
откуда при заданных р и и при известной зависимости D (Т) можно найти предельно необходимое Т.
Известно, что истинная дисперсия выборочного распределения для расчетного среднего обратно пропорциональна суммарному числу наблюдений Т, т.е.

где d не зависит от Т.
В начале имитационного процесса требуемое число наблюдений определить обычно не удается, поскольку d неизвестно. Поэтому, как правило, эксперимент проводят в два этапа.
На первом этапе число испытаний выбирается относительно небольшим, в результате определяется величина d. После этого можно уже определить, сколько дополнительных наблюдений необходимо, чтобы была достигнута требуемая точность.
Предельное число наблюдений Т0 определяется формулой T0 = d/[(1 – p)2].
При любом числе наблюдений больше Т0 обеспечивается требуемая точность.
Примеры
Пример 1. Моделирование объема спроса на автомашины.
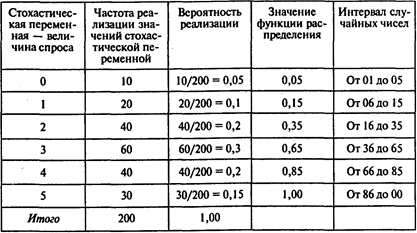
Наблюдения за объемом продаж автомобилей в салоне «ЛОГОВАЗ» в течение 200 дней показали, что величина спроса изменяется от 0 до 5 автомобилей в день. Частота реализации значений стохастической переменной приведена во втором столбце таблицы:
Постройте модель, позволяющую имитировать значение величины спроса.
Решение. Построим функцию распределения величины спроса и интервалы случайных чисел для значений стохастической переменной. Соответствующие значения указаны в четвертом и пятом столбцах вышеприведенной таблицы.
Сымитируем спрос на автомашины в салоне «ЛОГОВАЗ» в течение 10 последующих дней (случайные числа из таблицы случайных чисел (Приложение 2) выбираем, начиная из верхнего левого угла и двигаясь вниз в первом столбце):

В результате получаем: 39 — спрос за 10 дней; 39/10 = 3,9 — средний ежедневный спрос.
Оценка 3,9 средней величины спроса, полученная в результате имитационного эксперимента, существенно отличается от значения 2,95 — математического ожидания этой случайной величины. Однако эта разница уменьшается с ростом числа испытаний.
Пример 2. Моделирование очереди на разгрузку.
Груженые баржи, отправляемые вниз по Волге из индустриальных центров, достигают Астрахани. Число барж, ежедневно входящих в док, колеблется от 0 до 5. Вероятность прихода 0, 1,..., 5 барж показана в таблице:

В этой же таблице указаны интегральные вероятности и соответствующие интервалы случайных чисел для каждого возможного значения.
Аналогичная информация дана о числе разгружаемых барж:
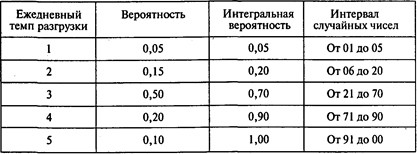
Постройте модель, позволяющую имитировать очередь на разгрузку.
Решение. Проведем эксперимент, имитирующий очередь на разгрузку барж в порту Астрахани:
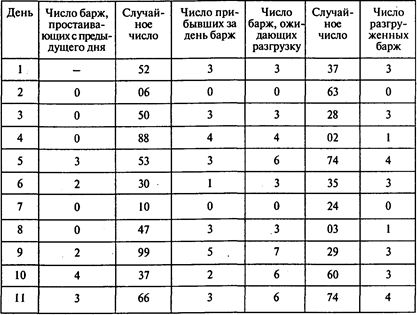
Окончание таблицы
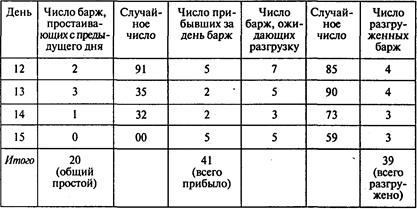
В результате эксперимента получены:
оценка среднего числа барж, простаивающих в течение суток, равная 20/15;
оценка среднего числа барж, прибывающих в течение суток, равная 41/15;
оценка среднего числа барж, разгруженных в течение суток, равная 39/15.
Пример 3. Имитация стратегии резервирования.
Магазин электрооборудования продает электрические дрели. В течение 300 дней директор магазина Проводков регистрировал дневной спрос на дрели. Распределение вероятностей величины спроса показано в таблице:
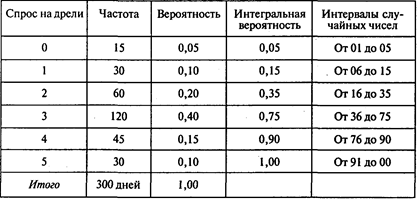
Когда Проводков делает заказ, чтобы возобновить свои запасы электрических дрелей, его выполнение происходит с лагом в 1, 2 или 3 дня. Это означает, что время восстановления запаса подчиняется вероятностному распределению. В следующей таблице указаны сроки, вероятности сроков выполнения заказов и интервалы случайных чисел, которые удалось определить на основе информации о 50 заказах:

Стратегия резервирования, которую хочет имитировать Проводков, — делать заказ в объеме 10 дрелей при запасе на складе 5 шт. Проводков оценил, что каждый заказ на дрели обходится ему в 10 руб., хранение каждой дрели — в 5 руб. в день, одна упущенная продажа — в 80 руб. Цель эксперимента — оценить величину средних ежедневных затрат для этой стратегии управления запасами.
Решение. Реализуется четырехшаговый процесс имитации:
1. Каждый имитируемый день начинается с проверки, поступил ли сделанный заказ. Если заказ выполнен, то текущий запас увеличивается на величину заказа (в данном случае — на 10 единиц).
2. Путем выбора случайного числа генерируется дневной спрос для соответствующего распределения вероятностей.
3. Рассчитывается итоговый запас, равный исходному запасу за вычетом величины спроса. Если запас недостаточен для удовлетворения дневного спроса, спрос удовлетворяется, насколько это возможно. Фиксируется число нереализованных продаж.
4. Определяется, снизился ли запас до точки восстановления (в примере — 5 единиц). Если да, причем не ожидается поступления заказа, сделанного ранее, то делается заказ.
Первый эксперимент Проводкова (объем заказа — 10 шт., точка восстановления запаса — 5 шт.; СЧ — случайное число):
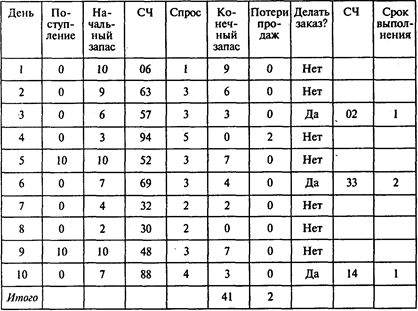
Результат имитационного эксперимента:
конечный суммарный запас — 41 единица;
средний конечный запас 41/10 =4,1 единицы;
число упущенных продаж — 2;
среднее число упущенных продаж 2/10 = 0,2 шт. в день;
среднее число заказов 3/10 = 0,3 заказа в день.
Определим три составляющие затрат:
Ежедневные затраты на заказы = Затраты на один заказ х Среднее число заказов в день = 10 • 0,3 = 3 руб.
Ежедневные затраты на хранение = Затраты на хранение одной единицы в течение дня х Средняя величина конечного запаса = 5 • 4,1 = 20,5 руб.
Ежедневные упущенные продажи = Прибыль от упущенной продажи х Среднее число упущенных продаж в день = 80 • 0,2 = 16 руб.
Таким образом,
Общие ежедневные затраты = Затраты на заказы + Затраты на хранение + Упущенные продажи = 3 + 20,5 + 16 = 39,5 руб.
– Конец работы –
Используемые теги: общее, Понятие, имитационного, моделирования, экономических, процессов0.092
Если Вам нужно дополнительный материал на эту тему, или Вы не нашли то, что искали, рекомендуем воспользоваться поиском по нашей базе работ: Общее понятие имитационного моделирования экономических процессов
Что будем делать с полученным материалом:
Если этот материал оказался полезным для Вас, Вы можете сохранить его на свою страничку в социальных сетях:
| Твитнуть |
Хотите получать на электронную почту самые свежие новости?

Подпишитесь на Нашу рассылку
Реклама





Информация в виде рефератов, конспектов, лекций, курсовых и дипломных работ имеют своего автора, которому принадлежат права. Поэтому, прежде чем использовать какую либо информацию с этого сайта, убедитесь, что этим Вы не нарушаете чье либо право.
© copyright 1999 - 2024 allRefs.net. Все права защищены. Страница сгенерирована за: 0.223 сек.
Новости и инфо для студентов