рефераты конспекты курсовые дипломные лекции шпоры

- Раздел Философия
- /
- ТЕХНОЛОГІЯ ПРОЕКТУВАННЯ ТА АДМІНІСТРУВАННЯ БАЗ ДАНИХ І СХОВИЩ ДАНИХ
Реферат Курсовая Конспект
ТЕХНОЛОГІЯ ПРОЕКТУВАННЯ ТА АДМІНІСТРУВАННЯ БАЗ ДАНИХ І СХОВИЩ ДАНИХ
ТЕХНОЛОГІЯ ПРОЕКТУВАННЯ ТА АДМІНІСТРУВАННЯ БАЗ ДАНИХ І СХОВИЩ ДАНИХ - раздел Философия, Університет Банківської Справи Націо...
УНІВЕРСИТЕТ БАНКІВСЬКОЇ СПРАВИ
НАЦІОНАЛЬНОГО БАНКУ УКРАЇНИ (м. КИЇВ)
ЛЬВІВСЬКИЙ ІНСТИТУТ БАНКІВСЬКОЇ СПРАВИ
ОПОРНИЙ КОНСПЕКТ ЛЕКЦІЙ
з дисципліни
ТЕХНОЛОГІЯ ПРОЕКТУВАННЯ ТА АДМІНІСТРУВАННЯ
БАЗ ДАНИХ І СХОВИЩ ДАНИХ
для бакалаврів усіх форм навчання спеціальності
6.050100 "Економічна кібернетика"
Укладач:
Доц. каф. ЕК
Вєніков Д.П.
Львів - 2012
ВСТУП
Основою сучасної інформаційної технології як такої, в цілому, є концепції баз даних (БД). Відповідно до цієї концепції, дані організовані в БД із наступною метою:
1)адекватного відображення реального світу;
2)задоволення інформаційних потреб користувачів.
Дані, для того щоб ними користуватися, необхідно: визначити, вирізнити, структурувати, систематизувати і організувати їх зберігання та доступ до них.
Збільшення об'єму і структурної складності збережених даних, розширення кола користувачів інформаційних систем висунуло вимогу створення зручних загальносистемних засобів інтеграції збережених даних і керування ними. Це привело до появи промислових систем керування базами даних (СКБД) - спеціалізованих програмних засобів, призначених для організації і ведення БД.
Завдяки досягненням в області штучного інтелекту з'являються системи, що базуються на використанні знань. Систему, яка забезпечує створення, ведення і застосування баз знань, можна розглядати як інструментальну систему або як прикладну систему з конкретною прикладною базою знань.
Існує тісний взаємозв'язок між технологією баз даних і систем баз даних - з одного боку, і технологією систем баз знань з іншого. Виникла тенденція "інтелектуалізації" систем БД. На зовнішньому рівні їх архітектури реалізують різноманітні семантичні моделі даних, створюють "дружні" інтерфейси для користувачів, хоча традиційні СКБД є необхідною складовою частиною інструментарію керування даними в системах баз знань.
В лекційному курсі приведені основи організації баз даних і знань на концептуальному, фізичному та логічному рівнях, а також особливості керування ними.
1. ВИЗНАЧЕННЯ І КЛАСИФІКАЦІЯ БД ЯК ІНФОРМАЦІЙНОЇ СИСТЕМИ
Діяльність людини та особливо, розвиток сучасної цивілізації постійно пов'язана зі:
1) сприйняттям,
2) накопиченням інформації про навколишнє середовище,
3) відбором і обробкою інформації при розв'язуванні різних задач,
4) обміном нею з іншими людьми.
Вони є первинними при прийнятті будь яких рішень – від мистецтво до виробництва, особливо – при прийнятті рішень в керуванні економікою.
З часом комплекс цих операцій, методи і засоби їхньої формалізації, систематизації та реалізації послужили основою для створення спеціалізованих інформаційних систем – баз даних. Основне призначення БД - інформаційне забезпечення користувача, тобто надання йому необхідних даних із визначеної предметної області. Завдяки появі комп’ютерів стало можливим створення спеціалізованих інформаційних систем – автоматизованих банків даних (АБД).
Функціонування АБД пов'язано з накопиченням і обробкою інформації. Під інформацією розуміється сукупність знань про фактичні данні і залежності між ними. У комп’ютерах поняття інформації і даних часто ототожнюються. Але якщо бути точними, то дані - це інформація, подана у формі, необхідній для введення її в комп’ютери , збереження, обробки і видачі споживачам.
Дані – це форма організації та представлення інформації. Дані – це та частина інформації, яка може бути виділена з загального кола знань експліцитно, тобто точно та явно, і формалізована в певній системі знаків.
В процесі розвитку АБД можна виділити два покоління з точку зору способів організації та представлення даних:
1-е покоління - інформаційні системи, які базуються на автономних файлах. Це системи з простою архітектурою й обмеженим набором можливостей. Вони складаються із набору автономних файлів і комплексу прикладних програм, призначених для обробки саме цих файлів і видачі документів строго визначеного кола і структури.
Приклад: список студентів з переліком тільки їх П,І.Б., але без визначення і фіксації в цьому списку власне понять і визначень „прізвище”, „ім’я” як операційної величини.
Такі системи мають ряд серйозних недоліків, що обмежують їхнє широке застосування: високу надлишковість даних, складність ведення і спільної обробки файлів, залежність програм від даних і ін. Програми в цьому випадку писались тільки під ці конкретні дані. Або навпаки, можна сказати що файлові БД створювались під певні алгоритми цих програм.
2-е покоління - банки даних. Це системи з високим ступенем інтеграції даних і автоматизації керування ними. Вони орієнтовані на колективне користування й, в основному, позбавлені недоліків, властивих АБД 1-го покоління.
Пояснення – на прикладі загального списку студентів і списку хворих студентів.
Інформація, яка вводиться в АБД і видається системою користувачу, представляється у вигляді документів.
Документ - це об'єкт в матеріальний паперовій або електронній формі, який містить інформацію, що має відповідно до чинного законодавства правове значення, і призначений для прийняття рішень по діяльності. Джерелом інформації в АБД є люди і датчики, споживачами - люди (користувачі), або кінцеві користувачі (КК).
Звертання користувачів до АБД здійснюється у вигляді запитів. Запит - це формалізоване повідомлення, що надходить на вхід системи. Він включає умову на пошук даних, а також вказівку про те, що необхідно проробити зі знайденими даними.
Основні етапи роботи АБД складають:
1) Інтерпретація введених запитів,
2) виконання дій, зазначених у них,
3) формування повідомлень і документів,
4) виведення повідомлень і документів.
У цілому під автоматизованою інформаційною системою розуміється сукупність інформаційних масивів, технічних, програмних і мовних засобів, призначених для збору, збереження, пошуку, обробки і видачі даних за запитами користувачів. Інформаційні масиви в даному випадку включають власне значення інформації та опис (семантичний) цієї інформації.
Використання БД може здійснюватися одним із двох способів:
1. Автономне функціонування системи, при якому БД не входить до складу інших систем і використовується самостійно. Прикладом можуть служити такі БД, як документальні (бібліотечні) інформаційно-пошукові системи, а також системи резервування авіа - і залізничних квитків типу "Сирена" і "Експрес", у яких відповіддю на запит пасажира є документ у вигляді квитка або повідомлення про відсутність вільних місць.
2. Використання БД у якості складової частини іншої автоматизованої системи. У цьому випадку вихідні дані можуть використовуватися не тільки кінцевими користувачами, але й іншими компонентами цієї автоматизованої системи з метою подальшої обробки і застосування у виробничому процесі. Так, у навчальних системах БД містить досліджуваний матеріал, набір питань, задач і відповідей, у САПР - нормативно-довідкову інформацію, зведення про ДСТ і інші дані, в АСУ - всю інформацію, необхідну для керування підприємством, тобто для аналізу, оцінки, прогнозування, виробітку рішень, планування, контролю виконання.
Інформаційні системи можна класифікувати за рядом ознак. В основу класифікації, приведеної на рис. 1.1, покладені найбільш істотні ознаки, що характеризують можливості й особливості сучасних БД.
Документальні інформаційно-пошукові системи (ДІПС) призначені для збереження і обробки документальних даних – тобто адрес збереження документів, а не самих документі та їх інформації. Такі дані подаються в неструктурованому вигляді. Прикладом ДІПС є бібліотечні, бібліографічні БД. На відміну від систем цього класу фактографічні інформаційно-пошукові системи (ФІПС) зберігають і оброблюють фактографічну інформацію - структуровані дані у вигляді чисел і текстів. Над такими даними можна виконувати різні операції. Більшість перших БД являють собою системи класу ФІПС.
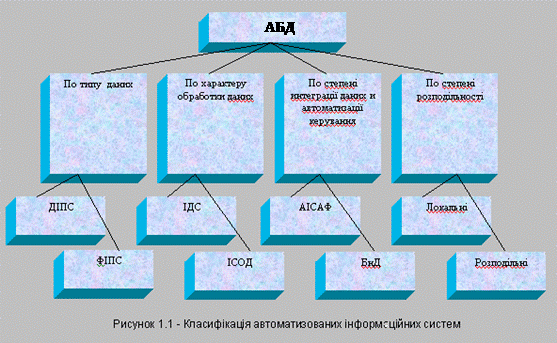 |
Друга ознака класифікації поділяє інформаційні системи на дві групи: до першої відносяться інформаційно-довідкові системи (ІДС), наприклад – телефонний довідник, які виконують пошук і виведення інформації без її обробки. Автоматизовані інформаційні системи обробки даних (АБДОД, ІСОД), що відносяться до другої групи, об'єднують у собі інформаційно-довідкову систему і систему обробки даних. Обробка знайдених даних виконується комплексом прикладних програм. Більшість АБД побудована за принципом ІСОД.
Ступінь інтеграції даних і автоматизації керування ними є найважливішою ознакою класифікації БД. У ранніх системах - БД на автономних файлах (АБД АФ) - принцип інтеграції даних практично не використовувався, а рівень автоматизації керування файлами був порівняно низьким. Такі системи застосовуються і в даний час; вони ефективні у випадку вузького, спеціалізованого використання невеликим колом осіб. Високий ступінь інтеграції мають сучасні банки даних (БнД). У порівнянні з АБД на автономних файлах у БнД збережена інформація зосереджена в єдиному інтегрованому інформаційному просторі - базі даних (БД), а процес маніпулювання даними автоматизований і уніфікований в певних межах.
В даному випадку зосередження в єдиному інформаційному просторі (масиві) відбувається не просто за рахунок механічного об’єднання значень даних, а за рахунок її інтеграції – тобто використання і фіксації єдиних правил ідентифікації, опису, представлення такої інформації та встановлення логічних зв’язків між описами даних як єдиного цілого об’єкту на базі відділення власне значень даних від їх структури та семантичного (змістовного ) визначення та явного опису і фіксації таких визначень в БД.
Приклад: зберігається не просто напис прізвища „Івченко”, а й визначення того, що цей набір символів, ця одиниця даних є одним з значень класу даних, визначених як ‹ПРИЗВІЩЕ›.
Остання із приведених ознак класифікації враховує розподільність компонентів БД: локальна система розміщення на одному комп’ютері, у той час як розподілена система функціонує в середовищі обчислювальної мережі і розподілена по її вузлах (серверах і робочих станціях).
Контрольні запитання.
1. Дайте визначення автоматизованої інформаційної системи.
2. За якими ознаками класифікують автоматизовані інформаційні системи?
3. Які недоліки мають автоматизовані інформаційні системи на автономних файлах?
4. Які автоматизовані інформаційні системи мають найбільшу ступінь інтеграції?
2. АВТОМАТИЗОВАНІ БАНКИ ДАНИХ
Автоматизований банк даних (БнД) - це організаційно-технічна (людино-машинна) система, що представляє собою сукупність інформаційної бази, колективу фахівців і комплексу програмних і технічних засобів забезпечення її функціонування, призначена для збереження, пошуку і видачі інформації у вигляді, зручному для користувачів.
На загальній схемі структури автоматизованого банку даних (рис.1.2) прийняті такі позначення: БД - база даних; ПП - прикладні програми користувачів банку даних; СКБД - система керування базою даних, тобто комплекс програмних засобів, який забезпечує завантаження інформації в базу даних, реорганізацію та ведення бази, пошук та перетворення інформації для забезпечення роботи програм користувачів банку даних. Розглянемо більш детально структурні складові частини цього автоматизованого банку даних.
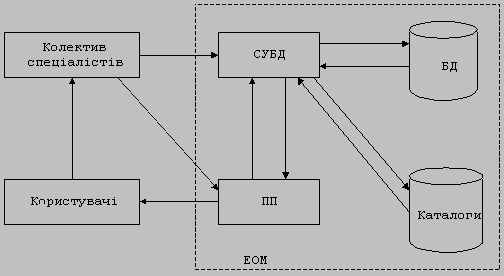
Рисунок 1.2 - Структура автоматизованого банку даних
2.1. Основні поняття й визначення бази і банків даних
Сучасні автори часто вживають терміни - "банк даних" й "база даних" як синоніми, однак у загальногалузевих керівних матеріалах по створенню банків даних Державного комітету з науці й техніці (ГКНТ), виданих в 1982 р., ці поняття розрізняються. Там приводяться наступні визначення банку даних, бази даних і СУБД:
Банк даних (Бнд) - це система спеціальним образом організованих даних - баз даних, програмних, технічних, язикових, організаційно-методичних засобів, призначених для забезпечення централізованого нагромадження й колективного багатоцільового використання даних.
База даних (БД) - іменована сукупність даних, що відбиває стан об'єктів й їхніх відносин і розглянутої предметної області.
Під предметною областю розуміють один або кілька об'єктів керування (або певні їхні частини), інформація яких моделюється за допомогою БД і використається для рішення різних функціональних завдань.
Система керування базами даних (СУБД) - сукупність мовних і програмних засобів, призначених для створення, ведення й спільного використання БД багатьма користувачами. У ній можна виділити:
- ядро СУБД, що забезпечує організацію уведення, обробки й зберігання даних,
- компоненти, які забезпечують налагодження системи, засобу тестування,
- утиліти, які забезпечують виконання допоміжних функцій (наприклад, ведення журналу статистики роботи системи й ін.).
Дуже важливим завданням СУБД є забезпечення незалежності даних. Практично одна й та сама СУБД може бути використана для ведення абсолютно різних файлів, які використаються для рішення різнопланових, не зв'язаних між собою завдань керування. Всі функції СУБД можна об'єднати в такі групи:
1. Керування даними. Завданнями керування даних є підготовка даних й їхній контроль, внесення даних у базу, структуризація даних, забезпечення цілісності, таємності даних.
2. Доступ до даних. Пошук і селекція даних, перетворення даних у форму, зручну для подальшого використання.
3. Організація й ведення зв'язку з користувачем. Ведення діалогу, видача діагностичних повідомлень про помилки в роботі з БД і т.д.
Для обробки запитів до БД розробляють програми, які становлять прикладне програмне забезпечення. Програми, за допомогою яких користувачі працюють із базою даних, називаються додатками. У загальному випадку з однією базою даних можуть працювати безліч різних додатків. Наприклад, якщо база даних моделює деяке підприємство, то для роботи з нею може бути створене додаток, що обслуговує підсистему обліку кадрів, інший додаток може бути присвячено роботі підсистеми розрахунку заробітної плати співробітників, третій додаток працює як підсистема складського обліку, четвертий додаток присвячений плануванню виробничого процесу.
При розгляді додатків, що працюють із однією базою даних, передбачається, що вони можуть працювати паралельно й незалежно друг від друга, і саме СУБД покликана забезпечити роботу безлічі додатків з єдиною базою даних таким чином, щоб кожне з них виконувалося коректно, але враховувало всі зміни в базі даних, внесені іншими додатками.
2.2. ЗАГАЛЬНА ПОБУДОВА І ХАРАКТЕРИСТИКИ БАЗИ ДАНИХ.
Відомі два підходи до організації інформаційних масивів: файлова організація та організація у вигляді бази даних. Файлова організація передбачає спеціалізацію та збереження інформації, орієнтованої, як правило, на одну прикладну задачу, та забезпечується прикладним програмістом. Така організація дозволяє досягнути високої швидкості обробки інформації, але характеризується рядом недоліків.
Характерна риса файлового підходу - вузька спеціалізація як обробних програм, так і файлів даних, що служить причиною великої надлишковості, тому що ті самі елементи даних зберігаються в різних системах. Оскільки керування здійснюється різними особами (групами осіб), відсутня можливість виявити порушення суперечливості збереженої інформації. Розроблені файли для спеціалізованих прикладних програм не можна використовувати для задоволення запитів користувачів, які перекривають дві і більше області. Крім того, файлова організація даних внаслідок відмінностей структури записів і форматів передання даних не забезпечує виконання багатьох інформаційних запитів навіть у тих випадках, коли всі необхідні елементи даних містяться в наявних файлах. Тому виникає необхідність відокремити дані від їхнього опису, визначити таку організацію збереження даних з обліком існуючих зв'язків між ними, яка б дозволила використовувати ці дані одночасно для багатьох застосувань. Вказані причини обумовили появу баз даних.
База даних може бути визначена як структурна сукупність даних, що підтримуються в активному стані та інформаційно відображає властивості об'єктів зовнішнього (реального) світу.
В базі даних містяться не тільки дані, але й описи даних, і тому інформація про форму зберігання вже не схована в сполученні "файл-програма", вона явним чином декларується в базі.
 |
База даних орієнтована на інтегровані запити, а не на одну програму, як у випадку файлового підходу, і використовується для інформаційних потреб багатьох користувачів. В зв'язку з цим бази даних дозволяють в значній мірі скоротити надлишковість інформації. Перехід від структури БД до потрібної структури в програмі користувача відбувається автоматично за допомогою СКБД.
 |

СКБД- це складна програмна система накопичення та з наступним маніпулюванням даними, що представляють інтерес для користувача. Кожній прикладній програмі СКБД надає інтерфейс з базою даних та має засоби безпосереднього доступу до неї. Таким чином, СКБД відіграє центральну роль в функціонуванні автоматизованого банку даних.
 |
Архітектурно СКБД складається з двох великих компонент (рис.1.3). За допомогою мови опису даних (МОД) створюються описи елементів, груп та записів даних, а також взаємозв'язки між ними, які, як правило, задаються у вигляді таблиць. В залежності від конкретної реалізації СКБД мову опису даних підрозділяють на мову опису схеми бази даних (МОС) та мову опису підсхем бази даних (МОП). Слід особливо зазначити, що МОД дозволяє створити не саму базу даних, а лише її опис.
Для виконання операцій з базою даних в прикладних програмах використовується мова маніпулювання даними (ММД). Фактична структура фізичного зберігання даних відома тільки СКБД.
З метою забезпечення зв'язків між програмами користувачів і СКБД (що особливо важливо при мультипрограмному режимі роботи операційної системи) в СКБД виділяють особливу складову - резидентний модуль системи керування базами даних. Цей модуль значно менший від всієї СКБД , тому на час функціонування автоматизованого банку інформації він може постійно знаходитись в основній пам'яті комп’ютерів та забезпечувати взаємодію всіх складових СКБД і програм, які до неї звертаються.
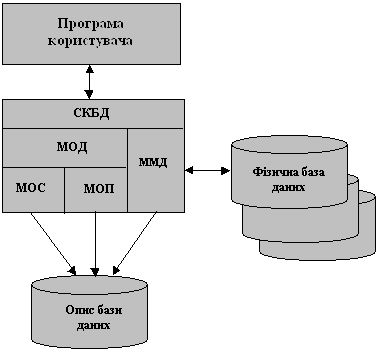
Рис. 1.3. Архітектура СКБД
Приведена структура притаманна усім СКБД, котрі розрізняються обмеженнями та можливостями по виконанню відповідних функцій. Отже, процес порівняння і оцінки таких систем для одного конкретного застосування зводиться до співставлення можливостей наявних СУБД з вимогами користувачів.
Будь-який аналіз, необхідний для проведення оцінки і вибору СКБД, повинен починатись з ретельного вивчення потреб користувачів. При цьому виконується опис зв'язків між елементами даних в базі даних. Також для оцінки експлуатаційних характеристик визначаються вимоги до часу виконання кожної трансакції. Під трансакцією розуміється повідомлення, яке передається від прикладної програми до СКБД. Трансакція ініціює в останній роботу певного виду чи окрему операцію по обробці даних.
За допомогою мови опису даних адміністратор БД описують для СКБД вміст та структуру бази даних. При розгляданні МОД слід з'ясувати її власні характеристики (наприклад, простоту використання та наочність), а також проаналізувати обмеження СКБД на дані (наприклад, типи даних чи можливості по обмеженню доступу).
Засоби маніпулювання даними визначають методи доступу до бази даних та мову (мови), за допомогою якої відбувається цей доступ. Мова маніпулювання даними є засобом, який застосовується користувачами чи прикладними програмістами для виконання операцій над базою даних. При порівнянні можливостей СКБД з сучасними принципами обробки даних важливе значення має зв'язок ММД з існуючими мовами програмування. Простота її вивчення і використання розширює можливості розробки банку даних з конкретною СКБД. Ступінь процедурності ММД визначає міру незалежності програм від даних. Чим менш процедурна мова, тим менша ймовірність зміни програм, написаних з її використанням, при включенні нових методів доступу і навіть нових структур даних в СКБД.
Нарешті, засоби маніпулювання даними визначають можливості паралельної обробки. Для збереження цілісності бази даних в умовах її одночасного використання декількома прикладними програмами звичайно вводяться обмеження на доступ для всіх, крім одного, з процесів, які виконуються одночасно. Наприклад, якщо програма поновлює запис бази даних, то їй може надаватись доступ до поля, що змінюється, до запису чи до всього фізичного файлу, в який цей запис входить.
Основна мета застосування баз даних - забезпечити незалежність логічної бази даних та прикладних програм від методів зберігання фізичної бази даних. При цьому способи доступу значно впливають на експлуатаційні характеристики банку даних.
Не менш важливу роль відіграють засоби копіювання та відновлення бази даних. Найбільш суттєвим тут є наявність автоматичного режиму ведення журналу фіксування роботи з базою даних. Наявність стандартних програм СКБД таких, як програма перезавантаження бази даних і програма обробки журналу, спрощують процес відновлення бази даних після апаратурних збоїв.
Серед інших стандартних програм слід відзначити програми завантаження бази даних, трасування роботи з базою даних для полегшення налагодження, а також накопичення і аналізу статистики по експлуатаційних характеристиках. Якщо база даних призначена для використання прикладними програмами, які функціонують в діалоговому режимі, то особливу роль в складі СКБД відіграють засоби передачі даних.
Концепція баз даних припускає інтеграцію даних, що раніше зберігалися окремо. Незалежно від того, охоплює чи не охоплює така інтеграція централізацію фізичних даних, вона припускає ріст спільного використання даних різними прикладними програмами та зменшення надлишковості зберігання одних і тих же даних. Для створення цим процесам сприятливих умов потрібне централізоване керування вмістом баз даних. Об'єктами централізованого керування є форма елементів даних і структури баз даних, а не власне значення самих елементів даних. Функція керування формою та вмістом бази даних називається адмініструванням даних.
Керування вмістом бази даних відбувається шляхом збору і ведення точної та повної інформації про дані. Ця інформація, яку часто називають метаданими, включає опис смислу елементів даних, методів їх використання, джерел, фізичних характеристик, а також різних правил та обмежень. Метадані дозволяють проводити аналіз запитів по нових даних, проектування і програмування нових прикладних систем, супроводження існуючих систем та документування всіх етапів розвитку бази даних. Дані про базу даних, чи метадані, можливо розбити на три класи: семантична інформація, фізичні характеристики та інформація про використання. Засобами автоматизації формування та використання метаданих являються словники даних (системи словників-довідників даних). Перерахуємо їхні основні функції:
1) встановлення зв'язку між користувачами БД;
2) здійснення простого та ефективного керування елементами даних при вводі в систему як нових елементів, так і при зміні опису існуючих;
3) зменшення надлишковості;
4) усунення протиріччя даних;
5) централізація керування елементами даних з метою спрощення проектування БД та її розширення.
Для створення ефективного і зручного словника даних необхідно при зборі інформації про дані встановити правила присвоєння елементам імен, добитися однозначного тлумачення різними користувачами призначення джерел і угод по присвоєнню імен, сформулювати прийнятні для усіх користувачів описи елементів даних і виявити синоніми, усунути багатозначність (омонімію, полісемію). Вказаний процес виконується ітераційно і зв'язаний з усуненням конфліктних ситуацій.
В процесі роботи з словником даних є можливість отримати в алфавітному порядку лістинг найменувань типів всіх статей (з зазначенням частоти їх використання в системі, статусу кожної статті та числа структур кожного виду).
Словник даних використовується кінцевими користувачами при роботі з системою на мові запитів, прикладними програмістами - при написанні програм, системними програмістами - в процесі розвитку системи. Словник в умовах організації інформації у вигляді баз даних вводиться до складу опису баз даних та використовується СКБД при роботі компілювальних і інтерпретувальних програм.
З розвитком системи необхідно проводити контроль логічності та повноти даних, які оброблюються в системі. Цей контроль полягає в перевірці за допомогою словника даних відповідності потоків і елементів даних, потоків і джерел даних, процесів обробки та елементів даних.
Особливо важливий словник даних при взаємодії декількох систем обробки даних, при побудові розподілених банків даних, при використанні програм, які виконані в інших організаціях. В останньому випадку словарні статті вилучають з написаних програм, встановлюють синонімічні зв'язки їх зі статтями словника системи і переводять їх в формат, прийнятий в системі.
Контрольні запитання.
1. Назвіть основні складові частини автоматизованого банку інформації.
2. Які функції виконує СКБД в банках даних?
3. Яке призначення словника даних?
4. Чим відрізняються МОД та ММД?
5. В чому проявляється інтегрований характер бази даних?
2.3. ВИМОГИ ДО БАНКІВ ДАНИХ
Різноманіття інформаційних потреб висувають до банків даних підвищені вимоги. До основних вимог відносяться:
1) Адекватність інформації стану предметної області. БнД є інформаційною моделлю предметної області і, як відзначалося вище, інформація, яка зберігається в ньому, повинна повно і точно відображати її об'єкти, їхні властивості і відношення між об'єктами. Відступ від принципу адекватності робить систему марною і навіть небезпечною, неприпустимою для використання. У свою чергу, вимога адекватності породжує ряд нових вимог до системи таких, як необхідність постійного внесення змін у дані і періодичної зміни організації даних.
2) Надійність функціонування - одна з найважливіших вимог, які висуваються до будь-якої системи.
3) Швидкодія і продуктивність. Ці дві близькі одна до одної вимоги відображають часові потреби користувачів. Перша з них визначається часом відповіді (реакції) системи на запит, який відраховується з моменту введення запиту до моменту початку видачі знайдених даних. Цей час залежить не тільки від швидкодії комп’ютерів , але і від способів фізичної організації даних, методів доступу, способів пошуку, складності запиту й інших чинників. Друга вимога визначається кількістю запитів, які відпрацьовуються в одиницю часу.
4) Простота і зручність використання. Ця вимога висувається до БнД з боку всіх без винятку категорій користувачів, особливо кінцевих. Складність запитів, відсутність сервісу формують у психології користувача небажання працювати з інформаційною системою.
5) Масовість використання. Сучасна інформаційна система повинна забезпечувати колективний доступ користувачів, при якому вони можуть одночасно і незалежно звертатися до баз даних для одержання необхідних даних.
6) Захист інформації. Система повинна забезпечувати захист збережених у ній даних і програм як від випадкових спотворень і знищення, так і від навмисних, несанкціонованих дій користувачів.
7) Можливість розширення. Архітектура системи повинна допускати розширення її можливостей шляхом модифікації або заміни існуючих програмних модулів, додаванням нових компонентів, а також шляхом реорганізації інформаційних масивів.
Контрольні запитання.
1. Які вимоги до БнД відображають часові потреби користувачів?
2. Як Ви розумієте адекватність інформації стану предметної області?
3. Якими шляхами може бути розширена БнД?
4. Які типи захисту інформації повинні бути передбачені в БнД?
2.5. ПРИНЦИПИ ПОБУДОВИ БАНКІВ ДАНИХ
У основі побудови БнД лежать наукові принципи, на основі яких розроблюють високоякісні системи, які відповідають сучасним вимогам. Вибір принципів побудови БнД і їхнє втілення в конкретній системі складають основу проектування.
З множини використовуваних принципів виділимо найбільш істотні (рис.1.5.): принцип інтеграції даних і принцип централізації керування ними. Обидва принципи відображають суть банку даних: інтеграція є основою організації БнД, централізація керування - основою організації і функціонування системи керування базами даних (СКБД). Інші принципи в тій або іншій мірі пов'язані з першими. Окремі з них є їхнім результатом або одним із можливих шляхів реалізації. Так, інтеграція даних припускає взаємозалежність (зв'язність) даних; зв'язність, у свою чергу разом із принципом композиції дозволяє звести надлишковість даних до мінімуму.
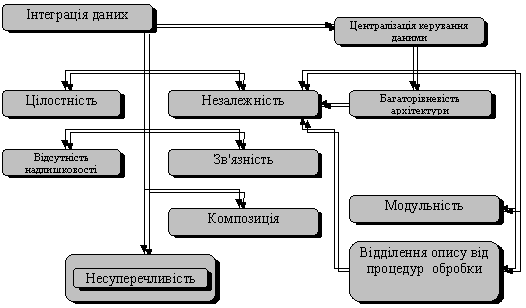
Рисунок 1.5 - Основні принципи побудови банків інформації
Суть, принципу інтеграції даних полягає в об'єднанні окремих, взаємно не зв'язаних даних у єдине ціле, в ролі якого виступає база даних. В результаті вказаного користувачу і його прикладним програмам всі дані представляються єдиним інформаційним масивом. При цьому полегшуються пошук взаємозалежних даних і їхня спільна обробка, зменшується надлишковість даних, спрощується процес ведення БнД.
Інтеграцію даних необхідно розглядати на двох рівнях - логічному і фізичному. На логічному рівні множина структур даних відображається в єдину структуру даних, на фізичному рівні автономні файли об'єднуються в базу даних.
Принцип цілісності даних відображає вимогу адекватності збереженої в БнД інформації стану предметної області: у будь-який момент часу дані повинні в точності відповідати властивостям і характеристикам об'єктів. Порушення цілісності виникає внаслідок спотворення або навіть руйнації (стирання) усіх або частини даних, а також як результат запису в базу даних невірної інформації. Підтримка цілісності досягається за рахунок контролю вхідної інформації, періодичної перевірки збережених у БнД даних, застосуванням спеціальної системи відновлення даних, а також іншими заходами.
Під незалежністю даних будемо розуміти незалежність прикладних програм від збережених даних, при якій будь-які зміни в організації даних не вимагають корекції цих програм. Одним із шляхів досягнення незалежності є введення додаткових рівнів абстрагування даних (принцип багаторівневості). Замість двох традиційних рівнів, передбачених базовим програмним забезпеченням і стандартними мовами програмування, - логічного і фізичного - в архітектурі БнД використовується принцип трирівневої організації даних: логічний рівень ділиться на два - зовнішній (рівень користувача) і концептуальний (загальний системний рівень даних).
Інший шлях досягнення незалежності даних - передача СКБД частини функцій, що раніше покладалися на прикладні програми. Маються на увазі функції, зв'язані з організацією доступу до БнД. При цьому прикладна програма ніяк не зв'язана ні з БнД, ні з методом доступу. Вона лише формує і передає ядру інформацію, необхідну для пошуку даних.
Незалежність даних досягається також застосуванням і дотриманням принципу відділення опису БнД від процедур обробки даних. Нарешті, істотним чинником забезпечення незалежності варто вважати реляційний підхід до побудови БнД - розробку бази даних на основі реляційної моделі даних і використання методів і засобів реляційної алгебри в процесі обробки БнД. Найбільший ефект досягається раціональним сполученням усіх зазначених шляхів.
Відсутність надлишковості - це стан даних, коли кожний елемент присутній у БнД в єдиному екземплярі. Надлишковість може мати місце як на логічному рівні, коли в структурі даних повторюються ті самі типи даних, так і на фізичному рівні, коли дані зберігаються в двох або більше екземплярах. Принцип інтеграції дозволяє звести надлишковість до мінімуму.
Під несуперечливістю розуміється смислова відповідність між даними. Це такий стан бази даних, при якому збережені в ній дані не суперечать один одному. Розрізняють два аспекти несуперечливості: смислова відповідність різнотипних даних і ідентичність (рівність) дублюючих даних.
Принцип зв'язності даних полягає в тому, що дані в БнД взаємозалежні, і зв'язки відбивають відношення між об'єктами предметної області. Множина типів даних і множина зв'язків утворять логічну структуру даних. Наявність зв'язків між записами в БнД дозволяє зменшувати надлишковість, спростити і прискорити пошук даних.
Принцип централізації керування полягає в передачі усіх функцій керування даними єдиному комплексу керуючих програм - системі керування базами даних. Як було зазначено вище, всі операції, пов'язані з доступом до БнД, виконуються не прикладними програмами, а централізовано - ядром СКБД - на підставі інформації, яку отримують з цих програм. Дотримання цього принципу дозволяє автоматизувати роботу з базами даних і тим самим істотно підвищити ефект, який отримують від застосування інформаційної системи.
Відділення опису даних від процедур їхньої обробки припускає, що опис даних виключається з прикладних програм, складається і транслюється окремо від них і зберігається в базі даних (або поза нею у виді окремого файлу). Виведення цих описів за рамки прикладної програми робить її більш незалежною від БнД, полегшує процес програмування, зменшує розміри необхідної для програми пам'яті, підвищує гнучкість маніпулювання даними.
На основі зазначених вище принципів формується архітектура БнД - концепція взаємозв'язку логічних, фізичних і програмних компонентів системи.
Контрольні запитання.
1. Назвіть основні принципи побудови банків інформації.
2. Для чого необхідно забезпечити відокремлення опису даних від процедур
їхньої обробки?
4. Покажіть взаємозв'язок основних принципів побудови банків даних.
5. В чому полягає відмінність функцій прикладного програміста і аналітика?
3. ТЕХНОЛОГІЯ ПРОЕКТУВАННЯ БД
3.1. Трирівнева модель системи керування базою даних. Фізична і логічна незалежність.
Термінологія в СУБД, та й самі терміни "база даних" і "банк даних" частково
запозичені з фінансової діяльності. Це запозичення - не випадкове і обгрунтовується тим, що робота з інформацією і робота із грошовими масами багато в чому схожі, оскільки і там і там відсутня персоніфікація об'єкта обробки: дві банкноти достоїнством у сто карбованців настільки ж не відрізняються одна від одної і взаємозамінні, як два однакових байти (природно, за винятком серійних номерів). Ви можете покласти гроші на деякий рахунок і надати можливість вашим родичам або колегам використовувати них для інших цілей. Ви можете доручити банкові оплачувати ваші витрати з вашого рахунка або одержати їх готівкою в іншом банку, і це будуть вже інші грошові купюри, але їхня цінність буде еквівалентна тієї, котру ви мали, коли клали них на ваш рахунок.
У процесі досліджень як саме повинна бути оргнізована СУБД, пропонувалися різні способи реалізації. Самим життєздатним з них виявилася запропонована американським комітетом зі стандартизації ANSІ (Amerіcan Natіonal Standards Іnstіtute) трьох-рівнева система організації БД, зображена на мал. 3.1.
 |
Рис. 3.1. Трирівнева модель системи керування базою даних
1. Рівень зовнішніх моделей - самий верхній рівень, де кожна модель має своє "бачення" даних. Цей рівень визначає точку зору на БД окремих додатків. Кожен додаток бачить і обробляє тільки ті дані, що необхідні саме цьому додаткові. Наприклад, система
розподілу робіт використовує зведення про кваліфікації співробітника, але її не цікавлять зведення про оклад, домашню адресу і телефон співробітника, і навпаки, саме ці зведення використовуються в підсистемі відділу кадрів.
2. Концептуальний рівень - центральна керуюча ланка, де база даних представлена в найбільш загальному виді, що інтегрує дані, використовувані всіма додатками, що працюють з даною базою даних. Фактично концептуальний рівень відбиває узагальнену модель предметної області (певної сукупності об'єктів реального світу або певної сукупності представлень об’єкту), для якої створювалася база даних. Як будь-яка модель, концептуальна модель відбиває тільки істотні, з погляду використання в додатках, особливості об'єктів реального світу.
3. Фізичний рівень - власне дані, розташовані у файлах або в сторінкових структурах, розташованих на зовнішніх носіях інформації. Ця архітектура дозволяє забезпечити логічну (між рівнями 1 і 2) і фізичну (між рівнями 2 і 3) незалежність при роботі з даними.
Логічна незалежність припускає можливість зміни одного додатка без коректування інших додатків, що працюють з цією же базою даних. Фізична незалежність припускає можливість переносу збереженої інформації з одних носіїв на інші при збереженні працездатності всіх додатків, що працюють з даною базою даних. Це саме те, чого не вистачало при використанні файлових систем. Виділення концептуального рівня дозволило розробити апарат централізованого керування базою даних.
 |
3.2. ІНФОЛОГІЧНА МОДЕЛЬ ДАНИХ. ОСНОВНІ ПОНЯТТЯ.
Проектування бази даних треба починати з аналізу предметної області і виявлення вимог до неї окремих користувачів (співробітників організації, для яких створюється база даних). Об'єднуючи власні уявлення про зміст бази даних, отримані в результаті опитування користувачів, і свої уявлення про дані, що можуть знадобитися в майбутніх прикладних додатках, створюється узагальнений неформальний опис утворюваної бази даних.

Рисунок 3.2. Рівні моделей даних
Цей опис, виконаний із використанням природної мови, математичних формул, таблиць, графіків і інших засобів, зрозумілих усім людям, що працюють над проектуванням бази даних, називають інфологічною моделлю даних (рис.3.2).
Основна відмінна характеристика ІМ. Така модель цілком незалежна від фізичних параметрів середовища збереження даних. Інфологічна модель не повинна змінюватися доти, поки якісь зміни в реальному світі не приведуть до зміни в ній деякого визначення, щоб ця модель продовжувала відображувати предметну область.
Якщо весь час виникає потреба змінювати ІМ при появі нових прикладних додатків – це свідчить про невдалий початковий вибір її побудови або дуже обмежений, вузько скерований підхід до цього.
Інші моделі, показані на рис.3.2, є комп'ютерно-оріентованими. З їхньою допомогою СКБД дає можливість програмам і користувачам здійснювати доступ до збережених даних лише за їхніми іменами, не турбуючись про фізичне розташування цих даних. Потрібні дані відшукуються СКБД на запам'ятовувальних пристроях, по фізичній моделі даних. Оскільки зазначений доступ здійснюється за допомогою конкретної СКБД, то моделі повинні бути описані мовою опису даних цієї СКБД.
Такий опис, утворений по інфологічній моделі даних, називають даталогічною моделлю даних.
Трирівнева архітектура (інфологічний, даталогічний і фізичний рівні) дозволяє забезпечити незалежність збережених даних від програм, в яких вони використовуються. Можна при необхідності переписати збережені дані на інші носії інформації і (або) реорганізувати їхню фізичну структуру. Можна підключити до системи будь-яке число нових користувачів (нових додатків), доповнивши, якщо треба, даталогічну модель. Зазначені зміни фізичної і даталогічної моделей не будуть помічені користувачами системи, так само як не будуть помічені і нові користувачі. Поява нового користувача БД (см. Рис.3.3) з своїми інформаційними потребами і представленням задачі розширює вихідну модель.
Отже, незалежність даних забезпечує можливість розвитку системи баз даних без руйнування існуючих додатків.
Контрольні запитання.
1. Охарактеризуйте аналіз предметної області як перший етап проектування бази даних.
2. Три фази аналізу предметної області.
3. Перелічіть задачі етапу аналiзу концептуальних вимог та iнформацiйних потреб.
4. Назвіть задачі етапу виявлення iнформацiйних об'єктiв та зв'язкiв мiж ними.
3.3. Класифікація моделей даних.
Одними з основних у концепції баз даних є узагальнені категорії "дані" і "модель даних".
Поняття "дані" у концепції баз даних - це набір конкретних значень, параметрів, що характеризують об'єкт, умову, ситуацію або будь-які інші фактори. Приклади даних:
Петров Микола Степанович, $30 і т.д.
Дані не мають визначену структуру, дані стають інформацією тоді, коли користувач задає їм визначену структуру призначення, тобто , усвідомлює їхній значеннєвий зміст. Тому центральним поняттям в області баз даних є поняття моделі. Не існує однозначного визначення цього терміна, у різних авторів ця абстракція визначається з деякими розходженнями, але, проте,можна виділити щось загальне в цих визначеннях.
Модель даних - це деяка абстракція, що, будучи застосовна до конкретних даних, дозволяє користувачам і розроблювачам трактувати їх уже як інформацію, тобто зведення, що містять не тільки дані, але і взаємозв'язок між ними.
Відповідно до розглянутого раніше трьох-рівневої архітектури ми маємо справу з поняттям моделі даних стосовно кожного рівня. І дійсно, фізична модель даних оперує категоріями, що стосуються організації зовнішньої пам'яті і структур збереження, використовуваних у даному операційному середовищі та на даному носії.
В даний момент як фізичні моделі використовуються різні методи розміщення даних, засновані на файлових структурах: це організація файлів прямого і послідовного доступу, індексних файлів і інвертованих файлів, файлів, що використовують різні методи хешування, взаємозалежних файлів. Крім того, сучасні СУБД широко використовують сторінкову організацію даних. Фізичні моделі даних, засновані на сторінковій організації, є найбільш перспективними.
На мал. 3.3 представлена класифікація моделей даних.
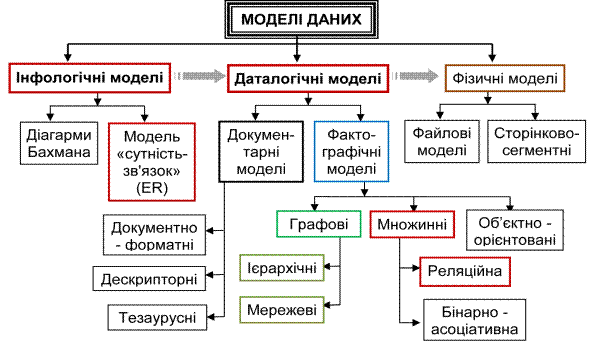 |
Рис. 3.3. Класифікація моделей даних
Найбільший інтерес викликають моделі даних, використовувані на концептуальному
рівні. Стосовно них зовнішні моделі називаються підсхемами і використовують ті ж абстрактні категорії, що і концептуальні моделі даних.
Вищий рівень абстракції при проектуванні БД визначає модель, що повинна виражати інформацію про предметну область у виді, незалежному від використовуваної СУБД. Ці моделі називаються інфологічними, або семантичними. Вони відбивають у природній і зручній для розробників і інших користувачів формі інформаційно-логічний рівень абстрагування, зв'язаний з фіксацією й описом об'єктів предметної області, їх властивостей та їх взаємозв'язків.
Інфологічні моделі даних використовуються на ранніх стадіях проектування для опису структур даних у процесі розробки додатка, а датологічні моделі вже підтримуються конкретної СУБД.
Документарні моделі даних відповідають уявленню про слабо структуровану інформацію, орієнтовану в основному на вільні формати документів, текстів природною мовою.
Дескрипторні моделі - найпростіші з документальних моделей, вони широко використовувалися на ранніх стадіях використання документальних баз даних. У цих моделях кожному документові відповідав дескриптор - описувач. Цей дескриптор мав тверду структуру й описував документ відповідно до тих характеристик, що потрібні для роботи з документами в розроблювальної документальної БД. Наприклад, для БД, що містить опис патентів, дескриптор містив назву області, до якого відносився патент,
номер патенту, дату видачі патенту і ще ряд ключових параметрів, що заповнювалися для кожного патенту. Обробка інформації в таких базах даних велася винятково по дескрипторах, тобто по тим параметрам, що характеризували патент, а не по самому тексті патенту.
Тезаурусні моделі засновані на принципі організації словників, містять в заданій граматиці визначені язикові конструкції і принципи їхньої взаємодії. Ці моделі ефективно використовуються в системах-перекладачах, особливо багатомовних перекладачах. Принцип збереження інформації в цих системах і підкоряється тезаурусним моделям.
3.4. Вимоги й підходи до інфологічного проектування
Метою інфологічного проектування є створення структурованої інформаційної моделі Предметної Області, для якої буде розроблятися БД.
При проектуванні на інфологічному рівні створюється інформаційно-логічна модель (ИЛМ), що повинна відповідати таким вимогам:
- забезпечення найбільш природних для людини способів збору й подання тієї інформації, що передбачається зберігати в створюваній базі даних;
- коректність схеми БД, тобто адекватне відображення модельованої ПО;
- простота й зручність використання на наступних етапах проектування, тобто ІЛМ може легко відображатися на моделі БД, які підтримуються відомими СУБД (мережні, ієрархічні, реляційні й ін.);
- ІЛМ повинна бути описана мовою, зрозумілим проектувальникам БД, програмістам, адміністраторові й майбутнім користувачам.
Суть інфологічного моделювання складається у виділенні сутностей (інформаційних об'єктів ПО), які підлягають зберіганню в БД, а також у визначенні характеристик (атрибутів) об'єктів і взаємозв'язків між ними.
Існує два підходи до інфологічного проектування: аналіз об'єктів і синтез атрибутів. Підхід, що базується на аналізі об'єктів, називається спадаючим, а на синтезі атрибутів – висхідним
3.5. Аналіз предметної області
Першим етапом проектування бази даних будь-якого типу є аналiз предметної областi, що закiнчується побудовою iнформацiйної структури (концептуальної схеми). На даному етапi аналiзуються запити користувачiв, вибираються iнформацiйнi об'єкти та їх характеристики i на основi проведеного аналiзу формується структура предметної областi, яка не залежить вiд програмного та технiчного середовища, в якому буде реалiзуватися база даних. Аналіз предметної області доцільно розбити на три фази:
1. аналіз концептуальних вимог та iнформацiйних потреб;
2. виявлення iнформацiйних об’єктів та зв’язків між ними;
3. побудова концептуальної моделі предметної області та проектування концептуальної схеми бази даних.
На етапі аналізу концептуальних вимог та iнформацiйних потреб необхідно вирішити такі задачі:
1) аналiз вимог користувача до бази даних (концептуальних вимог);
2) виявлення задач, що мають мiсце, при обробцi iнформацiї, яка повинна бути представлена у базi даних (аналiз додаткiв);
3) виявлення перспективних задач (перспективних додаткiв);
4) документування результатiв аналiзу.

Рис.3.4.
Вимогами користувачiв до бази даних, що розробляється є, в загальному випадку, список запитiв з вказанням їх iнтенсивностi та об'ємiв даних. Цi вказiвки опрацьовуються в дiалозi з майбутнiм користувачем бази даних. Тут же з'ясовуються вимоги до вводу, вiдновлення та корегування iнформацiї. Вимоги користувачiв уточнюються та доповнюються при аналiзi перспективних додаткiв, що мають мiсце.
3.4. Основні моменти аналізу предметної області
Розглянемо основні моменти аналізу предметної області на прикладі такої предметної галузі як читальний зал.
Так, виходячи із специфіки діяльності читального залу, необхідно:
1. забезпечити облік книг, що є в наявності,
2. виконувати швидкий пошук творів, що входять до складу тих чи інших книг.
3. вести картотеку користувачів, що дозволяло б оперативно здійснювати з ними зв'язок.
4. виявляти користувачів, які порушили строки повернення книги,
5. вести картотеку творів, що є в наявності в читальному залі.
Тоді в базу даних доцільно включити інформацію про:
1. книги, що є в читальному залі;
2. твори, що входять до складу тих чи інших книг;
3. користувачів, що користуються послугами читального залу.
При цьому, розроблювана база даних повинна забезпечити такі функції:
1. Ведення картотеки користувачів.
В інформацію про користувачів доцільно включити такі дані:
Þ прізвище, ім'я та по батькові;
Þ адреса;
Þ номер телефону;
Þ паспортні дані;
Þ освіта;
Þ професія.
2. Облік книг, що є в читальному залі чи якими в даний момент користуються, повинен враховувати такі дані:
Þ назва книги;
Þ автор книги;
Þ рік видання;
Þ видавництво;
Þ кількість сторінок;
Þ предметна область.
3. Ведення картотеки творів, які містяться в даній книзі, включає таку інформацію:
Þ назва;
Þ автор;
Þ дата написання.
4. Виявлення боржників, що не повернули книгу протягом дня.
5. Формування даних про повернення книги.
На цьому можна умовно вважати завершеною 1-у фазу аналізу предметної області.
Контрольні запитання.
1. Що Ви розумієте під інфологічною моделлю даних?
2. Що таке даталогічна модель даних?
3. Що Ви розумієте під фізичною моделлю даних?
4. Що є метою інфологічного моделювання?
5. Дайте визначення основних конструктивних елементів інфологічної моделі даних (сутність, екземпляр сутності, атрибут, ключ, зв'язок).
6. В чому полягає принцип трирівневої організації даних?
4. МОДЕЛЬ «СУТНІСТЬ – ЗВ’ЯЗОК» (ER-МОДЕЛЬ)
ПРЕДМЕТНОЇ ОБЛАСТІ
4.1. Основні елементи моделі «сутність-зв'язок»
Мета інфологічного моделювання - забезпечення найбільш природних для людини засобів збору й подання інформації, що буде зберігатися в створюваній базі даних. Тому інфологічну модель даних намагаються будувати за аналогією з природною мовою (остання не може бути використаною у чистому вигляді через складність комп'ютерної обробки текстів і неоднозначності будь-якої природної мови).
Таким чином, інфологічна модель відображає реальний світ у деякій зрозумілій людині концепції, цілком незалежній від параметрів середовища збереження даних. Існує безліч підходів до побудови таких моделей: графові моделі, семантичні мережі, модель "сутність-зв'язок" і т.д. Найбільш популярною серед них виявилася модель "сутність-зв'язок".
Основними конструктивними елементами інфологічних моделей є сутності, зв'язки між ними та їхні властивості (атрибути).
Сутність - будь-який помітний об'єкт з нашої точки зору розгляду певної предметної галузі (об'єкт, що ми можемо відрізнити від іншого), інформацію про який необхідно зберегти в базі даних. Сутностями можуть бути люди, місця, літаки, рейси, колір і т.д. Можна сказати, що сутність – це про що ми збираємо інформацію для опису предметної області та вирішення певного круга задач.
Слід розрізняти такі поняття, як тип сутності і екземпляр сутності. Поняття типу сутності відноситься до набору однорідних особистостей, предметів, подій або ідей. Екземпляр сутності відноситься до конкретної речі в наборі. Наприклад, типом сутності може бути МІСТО, а екземпляром - Москва, Київ і т.д. Таким чином, одному типу сутності може відповідати множина конкретних сутностей – його екземплярів. Аналог – тип запису і екземпляри запису.
Атрибут - пойменована характеристика сутності. Його найменування повинно бути унікальним для конкретного типу сутності, але може бути однаковим для різноманітного типу сутностей (наприклад, КОЛІР може бути визначений для багатьох сутностей: СОБАКА, АВТОМОБІЛЬ, ДІМ і т.д.).
Атрибути використовуються для визначення того, яка інформація повинна бути зібрана про сутність ( в рамках певної предметної галузі та певних задач). Прикладами атрибутів для сутності АВТОМОБІЛЬ є ТИП, МАРКА, НОМЕРНИЙ ЗНАК, КОЛІР і т.д. Тут також існує розходження між типом і екземпляром. Тип атрибута КОЛІР має багато екземплярів або значень: Червоний, Синій, Банановий, Біла ніч і т.д.. Проте кожному екземпляру сутності присвоюється тільки одне значення атрибута.

| Атр1.1 |
| Атр1.2 |
| Атр1.2 |
| … |
| Атр1. n |
| Атр3.1 |
| Атр3.2 |
| Атр3.2 |
| … |
| Атр3. k |
| Атр n.1 |
| Атр n.2 |
| Атр n.2 |
| … |
| Атр n. z |
| Атр2.1 |
| Атр2.2 |
| Атр2.2 |
| … |
| Атр2.m |
Абсолютне розходження між типами сутностей і атрибутами відсутнє. Атрибут є таким тільки в зв'язку з типом сутності. У іншому контексті атрибут може виступати як самостійна сутність. Наприклад, для автомобільного заводу КОЛІР - це тільки атрибут продукту виробництва, а для лакофарбової фабрики КОЛІР - тип сутності.
Якби призначенням бази даних було тільки збереження окремих, не пов'язаних між собою даних, то її структура могла б бути дуже простою. Проте одне з основних вимог до організації бази даних - це забезпечення можливості знаходження одних сутностей за значеннями інших, для чого необхідно встановити між ними визначені зв'язки.
Зв'язок - асоціювання двох або більше сутностей. Асоціювання визначається розробником за певними семантичними зв’язками між сутностями в рамках певного розгляду предметної області для певних задач (додатків).
Оскільки в реальних базах даних нерідко присутні сотні або навіть тисячі сутностей, то теоретично між ними може бути встановлене більше мільйона зв'язків. Наявність такої множини зв'язків і визначає складність інфологічних моделей.
| Атр n.1 |
| Атр n.2 |
| Атр n.2 |
| … |
| Атр n. z |
| Атр1.1 |
| Атр1.2 |
| Атр1.2 |
| … |
| Атр1. n |
| Атр2.1 |
| Атр2.2 |
| Атр2.2 |
| … |
| Атр2.m |
| Атр3.1 |
| Атр3.2 |
| Атр3.2 |
| … |
| Атр3. k |
Ключ - мінімальний набір атрибутів, за значеннями яких можна однозначно знайти необхідний екземпляр сутності. Мінімальність означає, що видалення із набору будь-якого атрибута не дозволяє ідентифікувати сутність по тих атрибутах, що залишилися.
 Друга фаза аналізу предметної області складається з розробки її інформаційної структури (або концептуальної схеми) представленої на Рис.4.1.
Друга фаза аналізу предметної області складається з розробки її інформаційної структури (або концептуальної схеми) представленої на Рис.4.1.
4.2. Основні риси моделі "сутність-зв'язок" (ER-моделі).
Розглянемо деякі риси моделі "сутність-зв'язок" (ER-моделі).
В звичайних випадках для побудови концептуальної схеми використовують традицiйнi методи агрегації та узагальнення. При агрегації декілька iнформацiйних об’єктів (елементів даних) об'єднується в один у відповідності з семантичними зв'язками мiж об'єктами.
Головні поняття ER-моделі : є сутність, зв'язок і атрибут. У діаграмах ER-моделі сутність подається у вигляді прямокутника, що містить ім'я сутності. При цьому ім'я сутності - це ім'я типу, а не деякого конкретного екземпляра цього типу. Для кращого розуміння ім'я сутності може супроводжуватися прикладами конкретних об'єктів цього типу. Сутність АЕРОПОРТ із об'єктами Шереметьєво і Хітроу зображена на рис.2.8.

Кожний екземпляр сутності повинен відрізнятися від будь-якого іншого екземпляра тієї ж сутності (ця вимога до певної міри аналогічна вимозі відсутності кортежів-дублікатів у реляційних таблицях).
Зв'язок - це асоціація, що графічно зображується та установлюється між двома сутностями. Ця асоціація завжди є бінарною і може існувати між двома різними сутностями або між сутністю і нею ж самою (рекурсивний зв'язок).
Моделювання предметної області базується на використанні графічних діаграм, що включають невелике число різнорідних компонентів.
При побудові інфологічних моделей можна використовувати мову ER-діаграм (від англ. Entity-Relationship, "сутність-зв'язок"). В них сутності зображуються позначеними прямокутниками, асоціації - позначеними ромбами або шестикутниками, атрибути - позначеними овалами, а зв'язки між ними - ненаправленими ребрами, над якими може проставлятися ступінь зв'язку (1 або буква, що заміняє слово "БАГАТО") і необхідне пояснення.
На використанні різновидів ER-моделі реалізується більшість сучасних підходів до проектування баз даних. Модель була запропонована Ченом (Chen) у 1976 р.
У зв'язку з наочністю уявлення концептуальних схем баз даних ER-моделі знайшли широке застосування в системах CASE, що підтримують автоматизоване проектування реляційних баз даних.
У будь-якому зв'язку виділяються два кінці (відповідно до існуючої пари сутностей, що зв'язуються), на кожному з яких вказується ім'я кінця зв'язку, ступінь кінця зв'язку (скільки екземплярів даної сутності зв'язується), обов'язковість зв'язку (тобто чи будь-який екземпляр даної сутності повинен брати участь у даному зв'язку).
Зв'язок подається у вигляді лінії, що зв'язує дві сутності або веде від сутності до неї ж самої. Якщо для цієї сутності в зв'язку можуть використовуватися багато (many) екземплярів сутності, про це в місці "стикування" зв'язку із сутністю вказує три-точковий вхід у прямокутник сутності. Якщо в зв'язку може брати участь тільки один екземпляр сутності вказується одно-точковий вхід.
Обов'язковий кінець зв'язку зображується суцільною лінією, а необов'язковий - переривчастою лінією.
Розглянемо приклад зв'язку між сутностями КВИТОК і ПАСАЖИР (рис.2.9).
 |
Рис. 4.3. Зображення зв’язку між сутностями КВИТОК та ПАСАЖИР
При цьому кінець зв'язку з ім'ям "Для" дозволяє зв'язувати з одним пасажиром більше одного квитка, причому кожний квиток повинен бути пов'язаний із яким-небудь пасажиром. Кінець зв'язку з ім'ям "Має" означає, що кожний квиток може належати тільки одному пасажиру, причому пасажир зобов'язаний мати не менше одного квитка. Трактування зображеної діаграми (рис.2.9) таке: { ? }
Þ Кожний КВИТОК призначений для одного і тільки одного ПАСАЖИРА;
Þ Кожний ПАСАЖИР може мати один або більше КВИТКІВ.
На рис.4.4 приведено приклад зображення рекурсивного зв'язку, що зв'язує сутність ЛЮДИНА з нею ж самою.
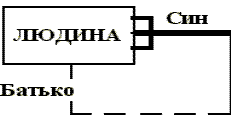
Рис. 4.5 - Зображення рекурсивного зв'язку
Кінець зв'язку з ім'ям СИН визначає той факт, що в одного батька може бути більше ніж один син. Кінець зв'язку з ім'ям БАТЬКО означає, що не в кожної людини можуть бути СИНИ.
Трактування зображеної діаграми (рис.4.5 ) таке:
Þ Кожна ЛЮДИНА є сином одного і тільки одного ЧОЛОВІКА;
Þ Кожна ЛЮДИНА може бути батьком для одного або більше ЛЮДЕЙ.
Атрибутом сутності є будь-яка деталь, що служить для уточнення, ідентифікації, класифікації, числової характеристики або вираження стану сутності. Імена атрибутів заносяться в прямокутник, що зображує сутність, під ім'ям сутності і зображуються малими буквами, можливо, із прикладами.
Наприклад, унікальним ідентифікатором сутності є атрибут, комбінація атрибутів, комбінація зв'язків або комбінація зв'язків і атрибутів, що унікально відрізняє будь-який екземпляр сутності від інших екземплярів сутності того ж типу.
Таким чином, зв'язки можуть представлятися рiзними способами, з яких ми будемо використовувати тiльки два: дiаграма ER-екземплярiв i дiаграма ER-типiв. Дiаграми ER-екземплярiв вiдображають зв'язки мiж екземплярами сутностей. Дiаграми ER-типiв вiдображають зв'язки мiж типами сутностей.
Отже, першою задачею, яку необхiдно розв'язати при розробцi ER-моделi, є формування сутностей, що необхiднi для описання предметної областi. Iншими словами, необхiдно вказати тi типи об'єктiв (тобто набори подiбних об'єктiв), про якi в системi повинна накопичуватися iнформацiя. Це означає, що за пiдсумками аналiзу предметної областi потрiбно мати повну або достатньо повну уяву про реалiзованi в системi запити.
Разом з тим необхiдно врахувати, що при квалiфiкованiй експлуатації системи у бiльшостi випадкiв у користувача виникає бажання розширити систему запитiв. У зв'язку з цим, при розробцi ER-схеми, з одного боку зручно твердо прив'язатися до обраної в результатi аналiзу предметної областi системи запитiв, а з iншого боку, бажано розглядати задачу в бiльш широкому планi, з врахуванням перспектив подальшого нарощування можливостей системи.
Приведемо приклад для таких об'єктiв: КНИГА, ТВІР, КОРИСТУВАЧ, РОЗДІЛ. Для кожної сутностi необхiдно обрати атрибут, що її однозначно iдентифiкує або сукупнiсть атрибутiв, якi будуть виступати ключем вiдповiдного вiдношення. Необхiдно врахувати, що ключ повинен не тiльки виконувати задачу iдентифiкацiї, але i по можливостi, включати в свiй склад мiнімальне число атрибутiв. У зв'язку з цим в процесi проектування вибранi в якостi ключiв атрибути можуть переглядатися. Наприклад, виберемо в якостi ключових такi атрибути:
Пр.24
КНИГА --> Cod_book (шифр книги);
ТВІР --> Cod_book (шифр книги), Name_tvir (назва твору);
РОЗДІЛ --> Cod_rozdil (код предметної області).
Необхідність введення складеного ключа для сутності ТВІР обумовлено тим, що в читальному залі може бути кілька однакових творів, написаних одним автором, але входять вони до складу різних книг.
Тепер виявимо залежностi, що iснують мiж визначеними нами сутностями, а також визначимо характеристики кожного зв'язку. Зв’язок КНИГА – ТВІР :
Пр.25
Книга маєТвір
Книга 1 *--------------------------------------------------------------- Твір2
Книга 2 *--------------------------------------------------------------- Твір 3
Книга 3 *-------------------------------------------------------------- Твір 4
. . . . . .
Книга n *-------------------------------------------------------------- Твір n
КП: ОБОВ'ЯЗКОВИЙ ТИП ЗВ'ЯЗКУ Б:Б КП: ОБОВ'ЯЗКОВИЙ
Рисунок 4.6 – Зображення зв’язку КНИГА – ТВІР
З рис.4.6 видно, що клас приналежності обох сутностей є обов'язковим, оскільки книги та твори, яких немає в читальному залі не повинні заноситись в базу даних.
Тип зв'язку – Б:Б : декілька творів можуть входити до складу однієї книги, та один і той самий твір може знаходитись в декількох книгах.
Зв’язок КНИГА – РОЗДІЛ приведено на рис.4.7.
Пр.26
Книга належить Розділ
Книга 1 *-------------------------------------------------Розділ 1
Книга 2 * .
Книга 3 *-------------------------------------------------Розділ 2
. . . . . .
Книга n *-------------------------------------------------Розділ n
КП: ОБОВ'ЯЗКОВИЙ ТИП ЗВ'ЯЗКУ Б:1 КП: ОБОВ'ЯЗКОВИЙ
Рисунок 4.7 - Зображення зв’язку КНИГА – РОЗДІЛ
З рис.4.7 видно, що клас належності обох сутностей є обов'язковим, оскільки книги, яких немає в читальному залі не повинні заноситись в базу даних, та розділи з предметних областей, що не мають книг, не заносять до бази даних. Хоча це спірно…
Тут тип зв'язку – Б:1 : декілька творів можуть входити до складу одного предметного розділу, але одна книга не може міститися в більше ніж одному розділі.
Розмірковуючи аналогічним чином побудуємо ER-модель предметної області "Читальний зал". В якості сутностей оберемо такі об'єкти предметної області (з перерахуванням ключових атрибутів кожної сутності):
Пр.28
КНИГА <Cod_book (шифр книги) >, Cod_client, Publisher, Year_publish, Page.
ТВІР <Cod_book (шифр книги), Name_tvir (назва твору) >, Author, Data_write.
РОЗДІЛ Cod_rozdil (код предметної області) , Name_rozdil.
КОРИСТУВАЧ Cod_client (шифр користувача) , FIO, Address, Telephone, №_pasp, Culture, Profession.
Характеристики зв'язків виділених сутностей приведені в табл.4.1,
Пр.29
Таблиця 4.1 - Характеристики зв’язків предметної області "Читальний зал"
| Ім'я Сутностi 1 | Ім'я сутностi 2 | Ім'я зв’язку | Тип зв'язку | Клас належностi |
| Книга | Розділ | Належить | N : 1 | Обов'язк., Обов'язк. |
| Книга | Твір | Має | N : M | Обов'язк., Обов'язк. |
| Книга | Користувач | Читає | N : 1 | Необов'язк., Необов'язк. |
Контрольні запитання.
1. Як використовують мову ER-діаграм при побудові інфологічних моделей?
2. Як використовують ER-діаграми при моделюванні предметної області?
3. Визначте головні поняття ER-моделі (сутність, зв'язок, атрибут).
4. Наведіть приклад рекурсивного зв'язку сутності.
5. Як Ви розумієте поняття "атрибут сутності"?
6. Назвіть основні етапи розробки ER-моделі.
7. Які Вам відомі складні елементи моделі?
6. МОВИ ІНФОЛОГІЧНОГО МОДЕЛЮВАННЯ
6.1. Мова ER-діаграм
Для підвищення ілюстративності аналізованих зв'язків застосовується мова інфологічного моделювання (МІМ), у якій сутності й асоціації подають пропозиціями виду:
СУТНІСТЬ (атрибут 1, атрибут 2, ... , атрибут n)
АСОЦІАЦІЯ [СУТНІСТЬ S1, СУТНІСТЬ S2, ...] (атрибут 1, атрибут2, ... , атрибут n)
де S - ступінь зв'язку, а атрибути, що входять у ключ, повинні бути відмічені за допомогою підкреслення.
Для виявлення зв'язків між сутностями необхідно, як мінімум, визначити самі сутності. Але це не проста задача, тому що в різних предметних областях один і той же об'єкт може бути сутністю, атрибутом або асоціацією.
Мова ER-діаграм, використовує для зображення наступні позначки (мал. 6.1).

Рис. 6.1. Елементи розширеної мови ER-діаграм
Тут Позначення (або Сутність, що позначає) - це зв'язок виду "багато-до-одного" або "один-до-одного" між двома сутностями й відрізняється від характеристики тим, що не залежить від позначуваної сутності.
Приклад Позначення: службовці мають незалежне існування (якщо віддаляється відділ, то із цього не треба, що також повинні бути вилучені службовці такого відділу). Тому вони не можуть бути характеристиками відділів і названі позначеннями.
Існування характеристики повністю залежить від сутності, що харатеризується: жінки втрачають статусу дружин, якщо вмирає їхній чоловік.
Для опису характеристики використається вид:
ХАРАКТЕРИСТИКА (атрибут 1, атрибут 2, ...)
{СПИСОК ХАРАКТЕРИЗУЕМЫХ СУТНОСТЕЙ}.
Опис Позначення зовні відрізняється від опису характеристики тільки тим, що позначувані сутності полягає не у фігурні дужки, а у квадратні:
ПОЗНАЧЕННЯ (атрибут 1, атрибут 2, ...)[СПИСОК ПОЗНАЧУВАНИХ СУТНОСТЕЙ].
Як правило, позначення не розглядаються як повноправні сутності, хоча це не привело б до якої-небудь помилки. Позначення й характеристики не є повністю незалежними сутностями, оскільки вони припускають наявність деякої іншої сутності, що буде "позначатися" або "характеризуватися".
6.2. Технологія побудови ІЛМ на прикладі ER-моделі
Розглянемо приклад побудови інфологічної моделі бази даних "Харчування".
Інформація буде використатися кухарем і керівником невеликого підприємства громадського харчування, а також його відвідувачами. В БД повинна зберігатися інформація про блюда (мал. 6.2), їх щоденному споживанні, продуктах, з яких готуються ці блюда, та постачальників цих продуктів.
Первинна інформація про дану предметну галузь та її конкретний об’єкт – це рецепт, який визначає як продукти, так і технологію.
|
Рис. 6.2. Приклад опису об’єкта предметної галузі - кулинарного рецепта
За допомогою опитування вказаних користувачів БД виділені наступні об'єкти й характеристики проектованої бази:
1. Блюда, для опису яких потрібні дані, що входять у їхні кулінарні рецепти:
- номер блюда (наприклад, із книги кулінарних рецептів),
- назва блюда,
- вид блюда (закуска, суп, гаряче й т.п.),
- рецепт (технологія готування блюда),
- вихід (вага порції),
- назва, калорійність і вага кожного продукту, що входить у блюдо.
2. Постачальники продуктів (для кожного): найменування, адреса, назва продукту, що поставляє, дата поставки й ціна на момент поставки.
3. Витрата (щоденне споживання блюд): блюдо, кількість порцій, дата.
Аналіз об'єктів дозволяє виділити:
Стрижні: Блюда, Продукти й Міста;
Асоціації: Склад (зв'язує Блюда із Продуктами) і
Поставки (зв'язує Постачальників із Продуктами);
Позначення: Постачальники;
Характеристики: Рецепти й Витрата.
Отримана ER-діаграма моделі показана на Рис.6.3.
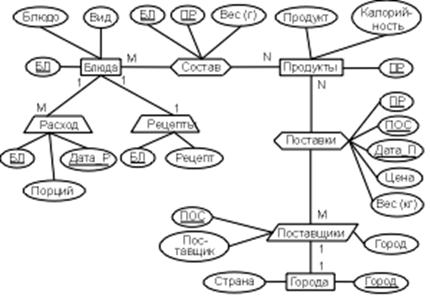 |
Рис.6.3.
Опис складу моделі має такий вигляд:
Блюда (БЛ, Блюдо, Вид)
Продукти (ПР, Продукт, Калорійність)
Постачальники (ПОС, Місто, Постачальник) [Місто]
Склад [Блюда M, Продукти N] (БЛ, ПР, Вага (г))
Поставки [Постачальники M, Продукти N] (ПОС, ПР, Дата_П, Ціна, Вага (кг))
Міста (Місто, Країна)
Рецепти (БЛ, Рецепт) {Блюда}
Витрата (БЛ, Дата_Р, Порцій) {Блюда}
У цих моделях Блюдо, Продукт і Постачальник - найменування, а БЛ, ПР і ПОС - цифрові коди блюд, продуктів й організацій, що поставляють ці продукти.
5. КЛАСИФІКАЦІЯ СУТНОСТЕЙ І ЗВ'ЯЗКІВ
КЛАСИ СУТНОСТЕЙ
Стрижнева сутність (стрижень) - це незалежна сутність. Асоціативна сутність (асоціація) - це зв'язок типу Б:Б між двома або більше… - вони можуть брати участь у других асоціаціях і позначеннях так само, як стрижневі сутності;Файлова модель.
У файлових системах реалізується модель типуплоский файл. При цій моделі інформаційна база (ІБ) є сукупністю не пов'язаних між собою файлів… Опис логічної організації даних файлової моделі. При описі логічної… Для кожного поля задається скорочене позначення - ім'я поля (ідентифікатор поля всередині запису), формат поля - тип…Структури даних.
Структури файлової моделі даних. Ці структури даних є базовими для файлової моделі даних, але використовуються і в ряді СУБД, що робить ці поняття універсальними. Основні первинні типи структур даних - поле, запис, файл.
Розглянемо ці структури даних на прикладі опису об’єкту «УГОДА»:
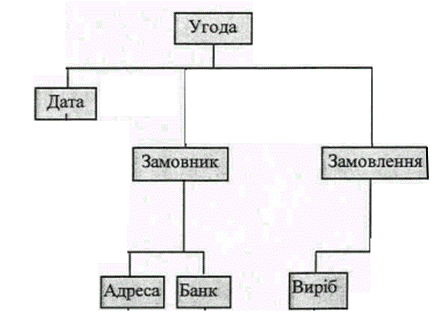 |
Рис. 1.6.а
Деталізуємо і уточнюємо концептуальну модель:
 |
Рис.1.6.б
Поле - це елементарна одиниця логічної організації даних, яка відповідає окремій, неподільній одиниці інформації - реквізиту.
Запис — це сукупність полів, що відповідають логічно пов'язаним реквізитам. Структура запису визначається складом і послідовністю полів, які в неї входять, кожне з яких містить елементарне дане. Запис є основною структурною одиницею обробки даних і одиницею обміну між оперативною і зовнішньою пам'яттю.
Файл - це сукупність однакових за структурою примірників записів зі значеннями окремих полів. Примірник (екземпляр) запису є реалізацією запису, що містить конкретні значення полів.
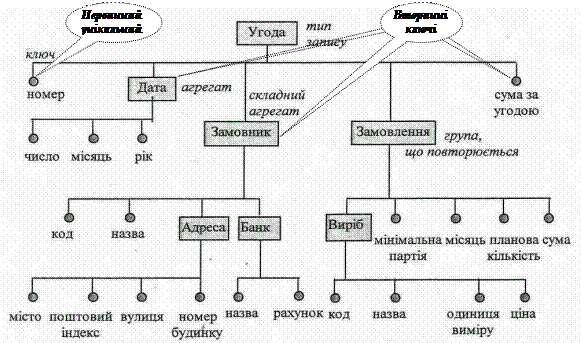
Рис. 1.6.в
Кожний примірник запису однозначно ідентифікується унікальним ключем запису. Загалом ключі запису бувають двох видів: первинний (унікальний) і вторинний ключ.
Первинний ключ (ПК) — це одне або кілька полів, які однозначно ідентифікують запис. Якщо первинний ключ складається з одного поля, він називається простим, якщо з кількох - складним ключем.
Вторинний ключ (ВК), на відміну від первинного, - це таке поле, значення якого може повторюватись у кількох записах файлу, тобто він не є унікальним. Якщо за значенням первинного ключа може бути знайдений лише один примірник запису, то за вторинним - кілька.
На рис. 1.6.г наведено приклад структури запису, що містить інформацію про угоду із замовниками на постачання товарів.
 |
Рис. 1.6.г Приклад структури запису документа «Угода»
Структури даних у моделях. До типових структур даних відносяться:
елемент даних, агрегат даних, запис, база даних тощо.
Елемент даних - це мінімальна пойменована структурна одиниця даних (аналог поля у файлових системах).
Агрегат даних - це пойменована підмножина елементів данихабо інших агрегатів усередині запису.
Запис - це складний агрегат, який не входить до складу інших агрегатів. Він
характеризується структурою взаємозв'язків її елементів й агрегатів. Таким чином,
структура запису може матиієрархічний характер.
Усі примірники запису однакової структури створюютьтип запису. Запис конкретного типу єоб'єктом у моделі даних.
12.1. Моделі даних - основні визначення.
Основою організації бази даних є модель даних, яка визначає правила, відповідно до яких структуруються дані. За допомогою моделі даних описується взаємозв'язок між елементами даних.
Модель даних - це сукупність взаємопов'язаних структур даних і операцій над ними.
Вид моделі і типи структур даних, що використовуються в ній, відображаютьконцепцію організації та обробки даних, яка є основою СУБД, що підтримує модель.
Модель даних може включати кілька типів записів (об'єктів). Між об'єктами моделі даних встановлюються зв'язки. Зв'язки між двома типами записів (об'єктами моделі) визначаються груповими відношеннями між їх примірниками. Групове відношення (набір) - це строго ієрархічне відношення між записами двох типів: головним записом набору і підпорядкованими записами набору.
Сукупність взаємопов'язаних конкретних об'єктів моделі для деякої предметної області утворює базу даних.
Найбільш поширені такі моделі даних:файлова, ієрархічна, мережна, реляційна.
Перші дві з них використовують графові моделі для представлення інформації про об'єкти.
12.2. Ієрархічна модель даних
Деревоподібна (ієрархічна) структура (рис.3.1), або дерево, - це зв'язний неорієнтований граф, що не містить циклів, тобто петель з замкнутих шляхів.
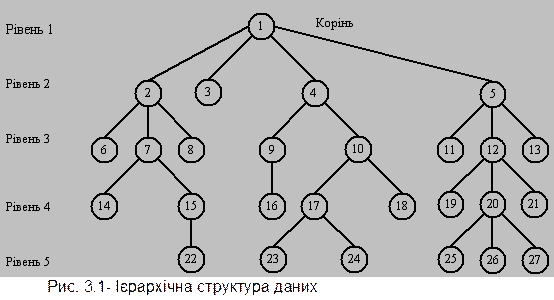
Як правило, при роботі з деревом виділяють будь-яку конкретну верхівку (початок), визначають її як коріння дерева. В цю верхівку не заходить жодне ребро. В цьому випадку дерево стає орієнтованим. Орієнтація на кореневому дереві визначається або від коріння, або до коріння.
Кореневе дерево можна визначити наступним чином:
1) є єдиний особливий вузол, який називається корінням, в який не
заходить жодне ребро;
2) в усі інші вузли заходить тільки одне ребро, а виходить довільна (0,
1, 2, ... , n) кількість ребер;
3) не існує циклів.
В програмуванні використовується інше визначення дерева, яке дозволяє розглядати дерево як рекурсивну структуру.
Рекурсивне дерево визначається як кінцева множина T, яка складається з одного або більш вузлів, таких, що:
1) існує один спеціально виділений вузол, який називається корінням дерева;
2) інші вузли розбиті на m > 0 підмножин T1,T2, ... , Tm, що не перетинаються, кожна з яких в свою чергу є деревом. T1,T2, ... , Tm, називаються піддеревами.
З визначення випливає, що будь-який вузол дерева є корінням деякого піддерева, що міститься в повному дереві. Число піддерев вузла називають ступенем вузла.
Вузол називається кінцевим, якщо він має нульову ступінь. Інколи кінцеві вузли називають листками, а ребра - гілками. Кожний вузол, крім кореневого, зв'язаний з одним вузлом на більш високому рівні ієрархії і називається вихідним. Кожний вузол може бути зв'язаний з одним або декількома вузлами на більш низькому рівні і називається породженим.
Якщо кожний вузол має однакову кількість гілок, причому процес включення нових гілок іде зверху вниз, а на кожному рівні дерева - зліва направо, то таке дерево називається збалансованим (рис.3.2, а). Для збалансованих дерев фізична організація даних суттєво спрощується. До особливої категорії дерев відносять двійкове (бінарне) дерево. Це дерево має не більш як дві гілки, які виходять з одного вузла. Двійкові дерева можуть бути як збалансованими, так і незбалансованими (рис.3.2, б).

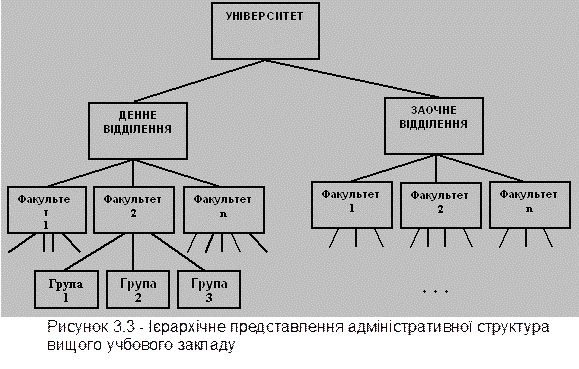
Прикладом простого ієрархічного подання може служити адміністративна структура вищого учбового закладу (рис.3.3): університет - відділення - факультет - група (студентська).
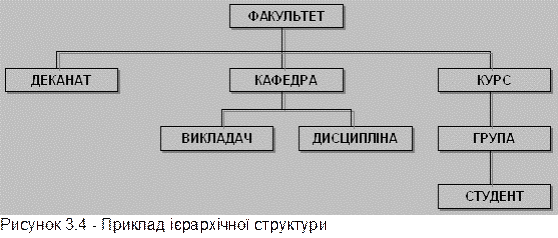
Пошук даних у ієрархічній структурі виконується завжди по одній із гілок, починаючи з кореневого елемента, тобто необхідно зазначити зазначений повний шлях руху по гілках. Так, для пошуку і вибірки одного або декількох екземплярів запису типу СТУДЕНТ (див. рис.3.4) необхідно вказати кореневий елемент ФАКУЛЬТЕТ і елементи КУРС, ГРУПА. У операційній системі MS-DOS для пошуку файлу використовується такий же принцип - вказуються послідовно ім'я диска, ім'я каталогу, ім'я підкаталогів, ім'я файлу.
Нижче приведений приклад графічного представлення ІМ тематичних збірників видавництв, вид деякої конкретної бази даних і опис схеми ІМ у системі ІMS фірми ІBM.
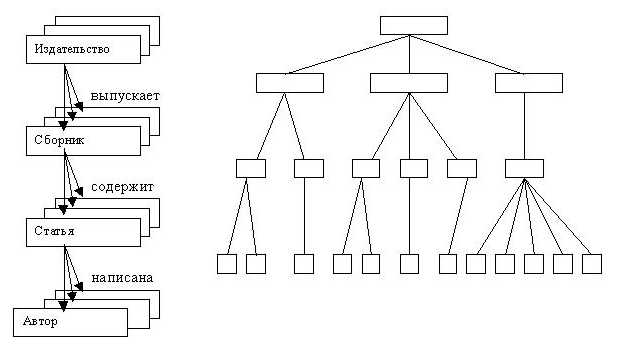
На рис.3.5 приведений приклад типу набору, представленого у вигляді діаграми Бахмана. Діаграму назвали за іменем вченого, який вперше їх застосував для опису відношень між даними при розробці СКБД IDS.
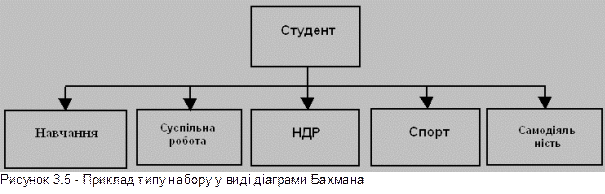
Рисунок 3.5 - Приклад типу набору у виді діаграми Бахмана
На такій діаграмі кожний прямокутник представляє собою тип запису , а стрілка - відношення "один до багатьох" між типами запису. У прикладі на рис.3.5 тип запису СТУДЕНТ є записом-власником, а типи записів НАВЧАННЯ, СУСПІЛЬНА РАБОТА, НДР, СПОРТ і САМОДІЯЛЬНІСТЬ - записами-членами. Тип набору названий ім'ям СНСНСС по перших літерах імен усіх типів запису, що беруть участь у наборі (наборові можна було надати і будь-яке інше ім'я).
У цілому приведений тип набору призначений для того, щоб відобразити зв'язок між загальними даними про студента, що знаходяться в типі запису СТУДЕНТ, і даними, що характеризують різні сторони діяльності студента у вузі. При традиційному підході всі ці данні можна було б помістити в один загальний запис. Оскільки не кожний студент бере участь, наприклад, у спорті або самодіяльності, то прийшлося б вибрати запис з змінною довжиною або запис із фіксованою довжиною, причому в останньому випадку частина пам'яті витрачалася б даремно. Ієрархічна структура усуває труднощі, що виникають при цьому, тому що в будь-якому екземплярі типу набору з записом-власником можна асоціювати стільки записів-членів, скільки необхідно для конкретного екземпляра.
Повна схема бази даних формується в загальному випадку з множини різних типів набору і типів запису.
Ієрархічна деревоподібна структура, що орієнтована від коріння, задовольняє такі умови:
1) ієрархія завжди починається з кореневого вузла;
2) на першому рівні може знаходитися тільки один вузол - кореневий;
3) на нижніх рівнях знаходяться породжені (залежні) вузли;
4) кожний породжений вузол, який знаходиться на рівні і, зв'язаний тільки з одним вхідним вузлом, який знаходиться на рівні (і-1) ієрархії дерева;
5) кожний вхідний вузол може мати один або декілька породжених вузлів, які називаються подібними;
6) доступ до кожного породженого вузла виконується через відповідний йому вхідний вузол;
8) існує єдиний ієрархічний шлях доступу до будь-якого вузла, починаючи від кореневого вузла дерева.
Приклади типових операторів маніпулювання ієрархічно-організованими даними:
Þ Пошук заданого дерево БД;
Þ Перехід від одного дерева до іншого;
Þ Перехід від одного запису до іншого в середині дерева;
Þ Перехід від одного запису до іншого в порядку обходу ієрархії;
Þ Установлення нового запис у зазначену позицію;
Þ Видалення поточного запис.
Перевагами деревовидної моделі є:
1) наявність функціональних систем керування базами даних, які підтримують дану модель,
2) простота сприйняття користувачами принципу ієрархії;
3) забезпечення деякого рівня незалежності даних;
4) простота оцінки операційних характеристик системи завдяки апріорно заданим взаємозв'язкам.
До недоліків ієрархічних структур відносять:
1) надлишковість зберігання інформації, так як ієрархічні структури не підтримують взаємозв'язки Б:Б;
2) строгу ієрархічну впорядкованість, яка ускладнює процедури включення та вилучення записів;
3) вилучення вихідних вузлів призводить до вилучення відповідних їм породжених, що вимагає особливої обережності;
4) ускладнюється доступ до даних, які лежать на більш низьких рівнях ієрархії, оскільки кореневий вузол завжди є головним, а доступ до любого породженого вузла може здійснюватись через вихідний.
Розглянемо в якості прикладу задачу. Нехай необхідно побудувати ієрархічну базу даних, до якої входить інформація про викладачів, студентів та дисципліни в таких взаємозв'язках:
О : Б
ВИКЛАДАЧ  ДИСЦИПЛІНА
ДИСЦИПЛІНА
О : Б
СТУДЕНТ  ДИСЦИПЛІНА,
ДИСЦИПЛІНА,
де  - відношення ОДИН - ДО -БАГАТЬОХ.
- відношення ОДИН - ДО -БАГАТЬОХ.
Ця інформація в ієрархічній моделі може бути представлена різними способами. Один з варіантів показаний на рис.3.6.

Кореневим вузлом є об'єкт СТУДЕНТ. Для кожного студента при даному представленні є екземпляр кореневого вузла.
Об'єкти ВИКЛАДАЧ, ДИСЦИПЛІНА об'єднані в породжуваний вузол ДИСЦИПЛІНА + ВИКЛАДАЧ. В кожний момент часу база даних, що задана моделлю рис.3.6, може мати записи для N студентів. На рис.3.7 показаний екземпляр запису бази даних для студента Собка Н.Ю.

Побудована модель дозволяє виконати такі операції, як оперативна видача інформації про здачу іспитів студентами з різних дисциплін (отримати кількісну та якісну оцінки). Можна відмітити, що дані про викладачів та назви дисциплін в базі даних (див. рис.3.6) повторюються в екземплярі породжуваного вузла стільки разів, скільки студентів навчається у даного викладача.
В той же час, якщо необхідно отримати інформацію про те, які викладачі по дисципліні "Схемотехніка" приймають іспити, то прийдеться переглянути всі записи породжуваних вузлів всіх екземплярів кореневого вузла. При такій постановці задачі більше підходить модель, яка представлена на рис.3.8, де кореневим вузлом є об'єкт ВИКЛАДАЧ, а об'єкти СТУДЕНТ та ДИСЦИПЛІНА об'єднані в породжуваний вузол СТУДЕНТ + ДИСЦИПЛІНА.
В моделі на рис.3.8 даними, що дублюються, є відомості про студентів.

Рисунок 3.8 - Альтернативне представлення бази даних СТУДЕНТ- ДИСЦИПЛІНА
На прикладах (див. рис.3.6 та рис.3.8) проілюструємо проблеми, які пов'язані з операціями включення та влучення даних.
З принципу ієрархії випливає, що екземпляр породжуваного вузла не може існувати при відсутності відповідного йому екземпляра вихідного вузла. Таким чином, неможливо без використання будь-яких інших методів включити в базу даних, представлену на рис.3.6, відомості про викладача, який не приймає іспити або заліки. Одним з методів реалізації такого включення є формування "пустих" екземплярів, які приводять до додаткових затрат зовнішньої пам'яті комп’ютерів і до необхідності строгого обліку таких записів.
При вилученні екземплярів вихідного вузла автоматично вилучаються всі екземпляри породжені вузлом. Наприклад, в базі даних, модель якої приведена на рис.3.8, вилучення екземпляра ВИКЛАДАЧ потягне за собою і вилучення всіх екземплярів про студентів, які навчаються в даного викладача. Вказане повністю неприпустиме при розв'язку, наприклад, задачі оцінки якості навчання студентів.
В ієрархічних базах даних проблеми, пов'язані з операціями включення нових записів і вилучення старих, а також проблеми часткового дублювання інформації виникають в результаті того, що відношення БАГАТО-ДО-БАГАТЬОХ безпосередньо не підтримується, що і є основним недоліком ієрархічних моделей.
Контрольні запитання.
1. В чому полягають особливості структурної організації ієрархічних моделей даних?
2. Чим обумовлено широке використання збалансованих дерев?
3. Перерахуйте типові оператори маніпулювання ієрархічними даними.
4. Перерахуйте основні переваги та недоліки ієрархічних моделей даних.
МЕРЕЖНА МОДЕЛЬ ДАНИХ
Відзначимо, що СКБД, в основі якої використовується мережна модель бази даних, називається СУБД мережного типу. В 1971 році був опублікований… В основі мережної моделі даних лежать мережні структури. Розглянемо мережні… Мережна структура відрізняється від ієрархічної тим, що в ній будь-який елемент може зв'язуватися з будь-яким іншим…СТУДЕНТСЬКИЙ_КОЛЕКТИВ та УЧБОВА_ГРУПА,
КІМНАТА_В_ГУРТОЖИТКУ та СТУДЕНТ.
Взаємозв'язок між цими об'єктами показаний на рис.3.9, звідки можна побачити, що дана схема не є ієрархічною, оскільки породжений елемент СТУДЕНТ має два вихідних.

На рисунку 3.9 представлена мережна структура, в якій між двома об'єктами присутні два види взаємозв'язку:
ОДИН-ДО-БАГАТЬОХ (наприклад, між об'єктами НАВЧАЛЬНА_ГРУПА-СТУДЕНТ
та
БАГАТО-ДО-ОДНОГО (СТУДЕНТ-КІМНАТА_В_ГУРТОЖИТКУ).
Цей вид зв'язку закладено в ієрархічних структурах при умові, що дані зв'язки ОДИН-ДО-БАГАТЬОХ 1:N існують відповідно між вихідними та породженими, а зв'язок БАГАТО-ДО-ОДНОГО N:1- між породженими та вихідними вузлами. Виконання цієї умови для відповідних вузлів мережної схеми говорить про просту мережну структуру. Складною мережною структурою називають схему, в якій присутній хоча б один зв'язок БАГАТО-ДО-БАГАТЬОХ – N:N.
На рис.3.11 показаний приклад складної мережної структури та можливі взаємозв'язки між об'єктами. В цьому прикладі вузол ВИКЛАДАЧ може мати декілька породжених, тому що викладач веде заняття більш ніж з одним студентом. А кожен студент навчається більш ніж у одного викладача.
 |
Рис. 3.11 - Складна мережна структура
Розділення мережних структур на два типи (складні та прості) необхідно хоча б тому, що структури, побудовані з використанням зв'язку БАГАТО-ДО-БАГАТЬОХ, вимагають для їх реалізації використання більш складних методів. Крім того, деякі системи керування базами даних можуть підтримувати прості мережні структури, але не можуть підтримувати складні. Наприклад, СКБД DMS, DBMS, СЕКТОР дозволяють описувати прості мережні структури. Реалізація складних мережних структур можлива і в цих системах керування базами даних шляхом приведення Їх до простішого вигляду.
Будь-яку мережну структуру можливо привести до простішого вигляду, якщо ввести надлишковість (рис.3.12). Якщо надлишковість, яка при цьому виникає, є допустимою, то такий шлях дозволяє підтримувати мережні структури даних за допомогою СКБД, які орієнтовані на ієрархічну організацію даних.
?
Рисунок 3.12-Представлення простої мереженої структури:
а, б - у вигляді одного дерева;
в - у вигляді суми дерев
Мережна структура даних базується також на використанні представлення даних у виді графа. C точки зору теорії графів мережній структурі відповідає довільний граф: в ієрархічних структурах запис-нащадок повинна мати в точності одного предка; у мережній структурі даних нащадок може мати будь-як число предків. Вершини графа використовуються для інтерпретації типів об'єктів. Дуги графа використовуються для інтерпретації типів зв'язків між типами об'єктів. Таке зображення структури БД називається діаграмою Бохмана.
Мережна БД складається з набору записів і набору зв'язків між цими записами. Тип зв'язку визначається для двох типів записів: предка і нащадка. Екземпляр типу зв'язку (у деякій літературі набір) складається з одного екземпляра типу запису предка й упорядкованого набору екземплярів типу запису нащадка.
 |
Якщо повернутися до приклада з виданням тематичних збірників і спробувати розширити його, щоб він більш повно відповідав реальним взаєминам, то схема мережної моделі і відповідний опис її мовою CODASYL будуть виглядати в такий спосіб.

Бази даних, яки описуються мережною моделлю, складаються з декількох областей (рис.3.13). Кожна область складається з записів, які в свою чергу складаються з полів.

Рисунок 3.13 - Структура мережної бази даних
Фактичне об'єднання записів (з різних областей) в логічну структуру можливе не тільки по областях, але й за допомогою так названих наборів. Термін набір є основною конструкцією мови системи баз даних КОДАСІЛ.
З точки зору теорії графів:Набір - це пойменоване дворівневе дерево, яке дозволяє формувати багаторівневі дерева та прості мережні структури. Таким чином, база даних КОДАСІЛ складається з деякої кількості наборів.
Використовуючи дворівневі дерева зв'язків, адміністратор БД може конструювати достатньо складні структури даних.
З точки зору БД: Набір - це екземпляр пойменованої сукупності записів. Для кожного типу набору кожний тип запису може бути оголошений його власником. Кожний набір повинен мати один екземпляр власника запису та будь-яку кількість екземплярів кожного типу запису - членів набору. Більш строго, набір - пойменована сукупність записів, у якому запису одного типу з'являються власниками набору, у записі інших типів - членами цього набору.
Наприклад, набір можна використовувати для об'єднання записів про студентів однієї групи (див. рис.3.10).
Перерахуємо властивості, що притаманні набору (Пр.7):
а) набір - це пойменована сукупність зв'язаних записів;
б) в кожному екземплярі набору присутній тільки один екземпляр власника;
в) екземпляр набору може мати нуль, один або декілька записів-членів;
г) набір вважається пустим, якщо жодний з екземплярів запису-члена не має зв'язків з відповідним екземпляром запису - володаря;
д) екземпляр набору існує після запам'ятовування запису-володаря;
е) тип набору є логічний взаємозв'язок ОДИН-ДО-БАГАТЬОХ між володарем та членом набору.
ж) кожному типу набору надається ім'я, що дозволяє одній і тій самій парі типів об'єктів брати участь у декількох взаємозв'язках.(примерз рис.3.7: студент може входити не тільки в набір «ГРУПА», але й в набір «ПРОФКОМ»).
Логічний взаємозв'язок ОДИН-ДО-БАГАТЬОХ між володарем та членом набору показаний на (рис.3.14);
 |
Рисунок 3.14 - Тип набору "Склад групи"
Необхідно розрізняти тип та екземпляр набору. Але спочатку пояснимо різницю між поняттями тип та екземпляр запису.
СТУДЕНТ є типом запису, а рядок символів "Захаров Іван Вікторович, член профкому, кімн. 638" - екземпляром типу запису СТУДЕНТ. Іншими словами, в базі даних можуть зберігатися один чи декілька екземплярів запису деякого типу.
Подібне відношення існує і між типом набору та екземпляру. У прикладі на рис.3.14 наведений тип набору СКЛАД ГРУПИ, а на рис.3.15 - його екземпляр, який вміщує екземпляр типу запису-володаря ГРУПА "832 група, куратор Іванов І.П., каф. кібернетики" та N екземплярів типу запису-члена: "1013 Захаров І.П., староста групи", "201К Кирилова О.Б.", ... , "426Х Харламов О.М."
Запис-член 1 Запис-член 2 Запис-член N


Екз. типу запису-володоря. Екземпляри типу запису-члена СТУДЕНТ.
Рисунок 3.15. - Екземпляр набору СКЛАД_ГРУПИ
Таким чином, екземпляр типу набору складається з одного екземпляру типу запису-володаря, нуля чи більше екземплярів типу запису-членів даного типу набору. Між екземпляром типу запису-володаря та екземпляром типу запису-члена існує взаємозв'язок ОДИН-ДО-БАГАТЬОХ. Певний екземпляр типу запису-члена в екземплярі даного типу набору не може одночасно належати більш ніж одному екземпляру типу запису-володаря. Іншими словами, унікальність володаря типу набору є обов'язковою.
В моделі даних, що являє собою взаємозв'язок ОДИН-ДО-БАГАТЬОХ, тип запису-володаря має від 0 до N екземплярів типу запису-члена. В свою чергу тип запису-члена в іншому наборі може мати роль типу запису-володаря. Запис-володар даного набору може грати дану роль у декількох наборах. Така структура є ієрархією. Отже, ієрархічна модель даних є окремим випадком мережної моделі.
12.4. Переваги і відмінності мережної моделі.
Таким чином, в ієрархічних моделях будь-який об’єкт може підпорядковуватися лише одному об’єкту вищестоящого рівня. У мережних моделях - будь-який об’єкт (запис, файл) може бути підпорядкований кільком об’єктам.
Мережні моделі даних порівняно з ієрархічними є більш універсальним засобом відображення структури інформації для різних предметних областей. Взаємозв’язки даних більшості предметних областей мають мережний характер, що обмежує використовування СУБД з ієрархічною моделлю даних. Мережні моделі дозволяють відображати також ієрархічні взаємозв’язки даних.
У мережних моделях безпосередній доступ за ключем може забезпечуватись до будь-якого об’єкта незалежно від рівня, на якому він перебуває в моделі. Можливий також доступ за зв’язками до будь-якої точки доступу.
Приклади типових операторів маніпулювання мережними даними: (Пр.6)
1) пошук конкретного запису в наборі однотипних записів;
2) перехід від предка до першого нащадка за деяким зв'язком;
3) перехід до наступного нащадка в деякому зв'язку;
4) перехід від нащадка до предка за деяким зв'язком;
5) створення нового запису;
6) знищення запису;
7) модифікація запису;
8) включення в зв'язок;
9) виключення зі зв'язку;
10) перестановка в інший зв'язок і т.д.
Суттєва відмінність між мережною та ієрархічною моделями даних полягає в тому, що в мережній моделі кожний запис може брати участь в будь-якій кількості наборів. Розглянемо мережну моделі, що представляється двома типами наборів (Пр.8):
ВЧИТЕЛЬ_ВИКЛАДАЄ_ДИСЦИПЛІНУ
Та
СТУДЕНТ_НАВЧАЄТЬСЯ_ ДИСЦИПЛІНІ,
На рис.3.16 представлена дана мережна модель, де запис-член ДИСЦИПЛІНА входить до обох типів наборів та є зв'язкою цих наборів. Крім того, будь-який запис мережної моделі може мати роль як володаря, так і члену набору.
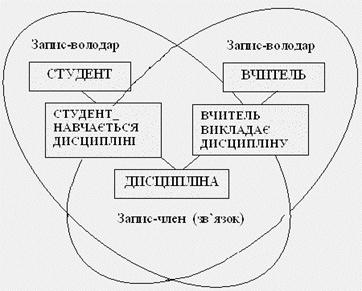
Рисунок 3.16 - Представлення відношення M:N у мережній моделі
До переваг мережних структур слід віднести наявність СКБД, які успішно реалізують таку організацію, а також простоту реалізації зв'язків "багато до багатьох", які часто зустрічаються в реальному світі. Недолік таких структур полягає в їх складності по відношенню до ієрархічних структур. Прикладному програмісту часто необхідно знати логічну структуру бази даних. При реорганізації бази даних не виключається в ряді випадків втрата незалежності даних.
Схематичну відмінність у топології ієрархічної і мережної моделей проілюстровано на рис. 3.17.
|

Домен
Кортеж
Рис.2.14. Відношення - двомірна таблиця
Умови і вимоги до побудови таблиць РБД
1. У кожної таблиці є унікальне ім'я, що визначає її вміст.
2. У кожного стовпця в таблиці є своє ім'я, що звичайно служить заголовком стовпця.
3. Всі стовпці в одній таблиці повинні мати унікальні імена, однак дозволяється привласнювати однакові імена стовпцям, розташованим в різних таблицях.
4. Стовпці таблиці упорядковані зліва направо, і їхній порядок визначається при формуванні таблиці.
5. На відміну від стовпців, рядки таблиці не мають визначеного порядку. Це значить, що якщо послідовно виконати два однакових запити для відображення вмісту таблиці, то немає гарантії, що обидва рази рядка будуть перераховані в тому самому порядку.
6. Як правило, не вказується максимально допустиме число стовпців у таблиці, однак майже у всіх комерційних СКБД ця межа існує і, як правило, складає приблизно 255 стовпців.
7. Стандарти реляційних баз даних не накладають обмежень на кількість рядків у таблиці, і в багатьох СКБД розмір таблиць обмежений лише вільним дисковим простором комп'ютера.У таблиці може міститися будь-яка кількість рядків.
8. Цілком припустиме існування таблиці з нульовою кількістю рядків. Така таблиця називається порожньою. Порожня таблиця зберігає структуру, визначену її стовпцями, просто в ній не містяться дані. У будь-якій таблиці завжди є як мінімум один стовпець. Тобто, таблиця існує, коли задан хоч один стовбець, а точніше – його ім’я.
9. У таблиці не можуть бути визначені множинні елементи, група або група, що повторюється, як у розглянутих вище мережних та ієрархічних моделях.
Стовпець відповідає деякому елементу даних - атрибуту, який є найпростішою структурою даних. Стовпці відношення називаються атрибутами і мають свої імена. Кожний стовпець таблиці повинен мати ім’я відповідного елемента даних (атрибута).
Масив значень, що можуть міститися в стовпці, називається доменом цього стовпця. Стовпець таблиці зі множиною значень відповідного атрибута називається доменом,
Рядки таблиці зі значеннями різних атрибутів. утворюють данні різного формату і різного типу. Рядки таблиці називаються кортежами. Кортеж – це множина значень всіх атрибутів що визначає певний екземпляр об’єкта.
За допомогою відношень (таблиць) зручно зберігати дані про об’єкти реального світу і моделювати зв’язки між ними.
5.2. ХАРАКТЕРИСТИКИ ВІДНОШЕННЯ
Ступінь відношення - це число його атрибутів. Відношення ступеня один називають унітарним, ступеня два - бінарним, ступеня три - тернарним, ... , а ступеня n – n-арним.
Кардинальне число або потужність відношення - це число його кортежів. Кардинальне число відношення змінюється в часі на відміну від його ступеня.
Список імен атрибутів відношення утворює схему відношення. Опис кожного відношення складається з імені відношення, за яким в круглих дужках перераховується список атрибутів. Цей опис називають інтенсіоналом або схемою відношення.
Схема наведеного відношення «Студент» така::
Пр.30-1
Студент (Прізвище _ та _ ініціали, Курс, Група, Спеціальність)
Під описом конкретного об’єкта розуміють деяке заповнення кортежів відношення, яке називають екстенсіоналом.
Відношення називаються еквівалентними, якщо вони відрізняються тільки порядком чергування атрибутів.
Кожне відношення має ключ, тобто атрибут, за допомогою якого однозначно ідентифікується окремий об’єкт. Один або кілька атрибутів, значення яких однозначно ідентифікують рядок таблиці, є ключем таблиці. За допомогою ключа здійснюється групування кортежів і встановлюється зв’язок між об’єктами відношення.
У відношенні «Студент» на роль ключа претендує атрибут «Прізвищ _ та _ ініціали».
Визнч.2. Реляційна база даних - це набір взаємопов’язаних двовимірних таблиць-відношень (об’єктів моделі).
Кожне відношення (таблиця) вкомп’ютері (на фізичному рівні) зображується у вигляді файлу. Кожний рядок відношення - кортеж на фізичному рівні відповідає запису. Співвідношення між різними поняттями реляційної бази даних можна показати таким чином:
| Відношення | 
| Таблиця | Файл | |
| ¯ | ¯ | ¯ | ||
| кортеж | рядок | запис | ||
| ¯ | ¯ | ¯ | ||
| атрибут | стовпець | поле |
Рис. 2.15. Співвідношення між поняттями реляційної бази даних
Наприклад, реляційну базу даних задач бухобліку утворюють дані первинних документів (таблиць) - накладних, товарно-транспортних накладних, рахунків-фактур тощо.
| Відношення | Таблиця | Файл | ||
| ¯ | ¯ | ¯ | ||
| кортеж | рядок | запис | ||
| ¯ | ¯ | ¯ | ||
| атрибут | стовпець | Поле |

Типи даних РБД. Як правило, в сучасних реляційних БД допускається збереження символьних, числових даних, бітових рядків, спеціалізованих числових даних (таких як "гроші"), а також спеціальних "темпоральних" даних (дата, час, часовий інтервал), такі специфічні як графічні (малюнки, фото, креслення).
Найменша одиниця даних реляційної моделі - це окреме атомарне (неподільне)для даної моделі значення даних. Так, в одній предметній області прізвище, ім'я і по-батькові можуть розглядатися як єдине значення, а в інший - як три різних значення.
Важливою вимогою до таблиць (відношень) реляційної моделі є нормалізація даних, що представлені таблицею. Первинно нормалізована таблиця містить рядки, в яких для кожного атрибута може бути лише одне значення. Приклад: людина з двома іменами.
Сукупність нормалізованих відношень (реляційних таблиць), що логічно взаємопов’язані і відображають певну предметну область, утворюють р е л я ц і й н у б а з у д а н и х (РБД).
(Зв’язки між двома логічно пов’язаними таблицями в реляційній моделі встановлюються за рівністю значень однакових атрибутів таблиць-відношень.)
5.2. Загальна структура реляційної моделі.
Згідно Дейту реляційна модель складається з трьох частин, що описують різні аспекти реляційного підходу: структурної частини, маніпуляційної частинита цілісної частини(Рис.2.13).
 |
Рис.2-13. Структура реляційної моделі (за Дейлом)
У структурній частині моделі фіксується, що єдиною структурою даних, яка використовується в реляційних БД, є нормалізоване n-арне відношення.
В маніпуляційній частини моделі стверджується два фундаментальних механізми маніпулювання реляційними БД - реляційна алгебра і реляційне числення.
Перший механізм базується в основному на класичній теорії множин (з деякими уточненнями), а другий - на класичному логічному апараті числення предикатів першого порядку.
У цілісній частині реляційної моделі даних фіксуються дві базові вимоги цілісності, що повинні підтримуватися в будь-якій реляційній СКБД.
Перша вимога називається вимогою цілісності сутностей. Об'єкту або сутності реального світу в реляційній БД відповідають кортежі відношень. Конкретно вимога полягає в тому, що будь-який кортеж будь-якого відношення відрізняється від будь-якого іншого кортежу цього відношення, тобто іншими словами, будь-яке відношення повинно мати первинний ключ. Має відрізняться на значення хоч 1-го атрибута.
Друга вимога називається вимогою цілісності по посиланнях.
Вимога цілісності по посиланнях, або вимога зовнішнього ключа полягає в тому, що для кожного значення зовнішнього ключа, який з'являється у відношенні, до якого посилаються, повинний існувати кортеж із таким же значенням первинного ключа. Так, наприклад, якщо для студента зазначений номер кімнати у гуртожитку, то ця кімната повинна існувати. Тобто, має бути таблиця (відношення) списку кімнат, де існує атрибут «№ кімнати» і існує саме це значення номеру кімнати.
Таким чином, що при дотриманні нормалізації відношень складні сутності реального світу представляються в реляційній БД у виді декількох кортежів декількох відношень.
Переваги реляційної бази :
1. незалежність від фізичного рівня представлення;
2. зручність і розуміння організації даних користувачами;
3. максимальна гнучкість при обробці непередбачених запитів;
4. можливість розширення бази приєднанням нових елементів, записів без зміни при цьому існуючих підсхем та прикладних програм.
5.3. ДВАНАДЦЯТЬ ПРАВИЛ КОДДА ДЛЯ РЕЛЯЦІЙНОЇ БАЗИ
Кодд у 1985 році сформулював 12 правил, яким повинна задовольняти будь-яка база даних, що претендує на тип реляційної. З того часу дванадцять правил Кодда вважаються визначенням реляційної СУБД.
(Пр.30) Дванадцять правил Кодда, яким повинна відповідати реляційна СКБД:
1. Правило інформації. Вся інформація в базі даних повинна бути надана винятково на логічному рівні і тільки одним способом - у вигляді значень, що містяться в таблицях.
2. Правило гарантованого доступу. Логічний доступ до всіх і кожного елемента даних (атомарного значення) у реляційній базі даних повинний забезпечуватися шляхом використання комбінації імені таблиці, первинного ключа та імені стовпця.
3. Правило підтримки недійсних значень. У реляційній базі даних повинна бути реалізована підтримка недійсних значень, що відрізняються від рядка символів нульової довжини, рядка символів пропусків, будь-якого іншого числа і використовуватися для представлення відсутніх даних незалежно від типу цих даних.
4. Правило динамічного каталогу, основаного на реляційній моделі. Опис бази даних на логічному рівні необхідно представити в тому ж вигляді, що й основні дані, щоб користувачі, які мають відповідні права, могли працювати з нею за допомогою тієї ж реляційної мови, яку вони застосовують для роботи з основними даними.
5. Правило вичерпної підмови даних. Реляційна система може підтримувати різні мови і режими взаємодії з користувачем (наприклад, режим питань і відповідей). Однак повинна існувати принаймні одна мова, оператори якої підтримують такі елементи:
1) визначення даних;
2) визначення представлень;
3) обробку даних (інтерактивну і програмну);
4) умови цілісності;
5) ідентифікацію прав доступу;
6) границі транзакцій (початок, завершення і скасування).
6. Правило відновлення представлень. Усі представлення, які теоретично можна обновити, повинні бути доступні для відновлення.
7. Правило додавання, відновлення і вилучення. Можливість працювати з відношенням як з одним операндом повинна існувати не тільки при читанні даних, але і при доповненні, відновленні і вилученні даних.
8. Правило незалежності фізичних даних. Прикладні програми й утиліти для роботи з даними повинні на логічному рівні залишатися недоторканими при будь-яких змінах методів збереження даних чи методів доступу до них.
9. Правило незалежності логічних даних. Прикладні програми й утиліти для роботи з даними повинні на логічному рівні залишатися недоторканими при внесенні в базові таблиці будь-яких змін, які теоретично дозволяють зберегти недоторканими дані, що містяться в цих таблицях.
10. Правило незалежності умов цілісності. Повинна існувати можливість визначати умови цілісності, специфічні для конкретної реляційної бази даних, на підмові реляційної бази даних і зберігати їх у каталозі, а не в прикладній програмі.
11. Правило незалежності поширення. Реляційна СКБД не повинна залежати від потреб конкретного клієнта.
12. Правило одиничності. Якщо в реляційній системі є низькорівнева мова (що обробляє один запис за один раз), то повинна бути відсутня можливість використання її для того, щоб обійти правила й умови цілісності, виражені на реляційній мові високого рівня (що обробляє кілька записів за один раз).
Правило 2 вказує на роль первинних ключів при пошуку інформації в базі даних. Ім'я таблиці дозволяє знайти необхідну таблицю, ім'я стовпця дозволяє знайти необхідний стовпець, а первинний ключ дозволяє знайти рядок, який містить шуканий елемент даних.
Правило 3 вимагає, щоб відсутні дані можна було представити за допомогою недійсних значень (NULL).
Правило 4 говорить, що реляційна база даних повинна сама себе описувати. Іншими словами, база даних повинна містити набір системних таблиць, що описують структуру самої бази даних.
Правило 5 вимагає, щоб СКБД використовувала мову реляційної бази даних, наприклад SQL, хоча явно SQL у правилі не згадують. Така мова повинна підтримувати всі основні функції СКБД - створення бази даних, читання і введення даних, реалізацію захисту бази даних і т.д.
Правило 6 дозволяє показувати різним користувачам різні фрагменти структури бази даних.
Правило 7 акцентує увагу на тому, що бази даних по своїй природі орієнтовані на множини. Воно вимагає, щоб операції доповнення, вилучення і відновлення можна було виконувати над множинами рядків. Це правило призначене для того, щоб заборонити реалізації, у яких підтримуються тільки операції над одним рядком.
Правила 8 і 9 стверджують, що конкретні способи реалізації чи збереження доступу, які використовуються в СКБД, і навіть зміни структури таблиць бази даних не повинні впливати на можливість користувача працювати з даними.
Правило 10 вимагає, щоб мова бази даних підтримувала обмежувальні умови, які накладаються на дані, що вводяться, і на дії, що можуть бути виконані над даними.
Правило 11 говорить, що мова бази даних повинна забезпечувати можливість роботи з розподіленими даними, розташованими на інших комп'ютерних системах.
І, нарешті, Правило 12 запобігає використанню інших можливостей для роботи з базою даних, крім мови бази даних, оскільки це може порушити її цілісність.
Контрольні запитання.
1. Назвіть 12 правил Кодда, які повинна задовольняти реляційна база даних.
2. Як визначається степінь та кардинальне число відношення?
3. Чи існують в сучасних СКБД обмеження на розміри відношень?
4. Перерахуйте переваги та недоліки реляційних моделей даних.
5.5. ОСНОВИ РЕЛЯЦІЙНОЇ АЛГЕБРИ
Операції з даними в реляційній моделі
Операції з даними в реляційній базі даних включають операції над рядками (кортежами відношень) та операції над відношеннями.
Операції, що виконуються на рівні кортежів:
- вставка (додається новий рядок),
- вилучення(знищується рядок),
- поновлення (здійснюються зміни значень атрибутів у рядках).
Основною одиницею обробки даних у реляційній моделі є відношення (файл). Ефективність реляційної системи управління базою даних визначається здатністю виконувати над відношеннями операції алгебри відношень.
Реляційна модель баз даних надає можливість маніпулювати над доменами відношень. Для цих цілей існує два види апаратів маніпулювання відношеннями: реляційна алгебра (алгебра відношень) і реляційне обчислення (обчислення відношень).
Алгеброю відношень називають систему операцій маніпулювання відношеннями, кожний оператор якого в якості операнда (операндів) використовує одне чи більше відношень і утворює нове відношення за попередньо обумовленим правилом.
Реляційне обчислення дозволяє шляхом використання обчислення предикатів та кванторів змінних описувати відношення та операції над ними в вигляді аналітичного виразу або формули.
В реляційній алгебрі використовують п'ять основних операцій:
1. об'єднання,
2. різниця(віднімання),
Декартовий добуток,
5. селекція. Об'єднання. Об'єднання відношень R і S (позначаться R U S) представляє собою… Нехай задано два відношення , представлені таблицями 4.5, 4.6. Виконаємо над ними операцію об'єднання.СТУДЕНТ-ВИКЛАДАЧ
Напівскладеним називається ключ, що містить декілька атрибутів, між якими на відміну від повністю складеного ключа існує залежність Б:1(БАГАТО-ДО-ОДНОГО). Тут атрибути в ключі впорядковуються за принципом: кожний наступний уточнює попередній. У відношенні СТУДЕНТ-УСПІШНІСТЬ використовувався напівскладений ключ F, D.
Взаємозв'язок таблиць є найважливішим елементом реляційної моделі даних. Вона підтримується зовнішніми ключами (foreign key).
Розглянемо приклад, у якому база даних зберігає інформацію про рядових співробітників (таблиця Співробітник) і керівниках (таблиця Керівник) у деякій організації (рис.4.4).
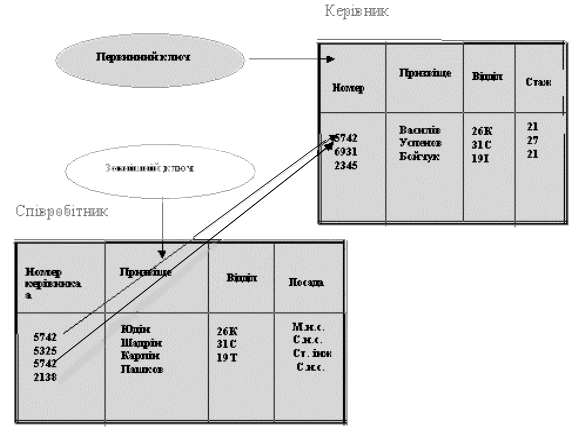 |
Рис. 4.4 - Схематичне представлення зовнішнього ключа
Первинний ключ таблиці Керівник - стовпець Номер (наприклад, табельний номер). Стовпець Прізвище не може виконувати роль первинного ключа, тому що в одній організації можуть працювати два керівники з однаковими прізвищами. Будь-який співробітник підпорядковується єдиному керівнику, що повинно бути відображено в базі даних. Таблиця Співробітник містить стовпець Номер керівника, і значення в цьому стовпці вибираються зі стовпця Номер таблиці Керівник (див. рис.4.4). Стовпець Номер Керівника є зовнішнім ключем для таблиці Співробітник.
Контрольні запитання.
1. Які основні вимоги висуваються до ключів?
2. Які типи відношень між атрибутами характерні для різних типів ключів?
3. В яких випадках застосовуються зовнішні ключі?
4. Коли ключ включає всі атрибути відношення?
7.7. РОЗРОБКА УНІВЕРСАЛЬНОГО ВІДНОШЕННЯ
Основна (друга) фаза аналiзу предметної областi складається з:
Пр.17-А
1. Вибору iнформацiйних об'єктiв;
2. Завдання необхiдних властивостей для кожного об'єкта;
3. Виявлення зв'язкiв мiж об'єктами;
4. Виявлення обмежень, що накладаються на iнформацiйнi об'єкти;
5. Визначення типів зв'язкiв мiж ними;
6. Визначення характеристик iнформацiйних об'єктiв.
При виборi iнформацiйних об'єктiв бажано намагатися вiдповiсти на такi питання:
Пр.17
1. На якi класи можна розбити данi, що пiдлягають збереженню у базi даних?
2. Яке iм'я можна присвоїти кожному класу даних?
3. Якi найбiльш цiкавi характеристики (з точки зору користувача) кожного класу даних можна видiлити?
4. Якi iмена можна присвоїти вибраним наборам характеристик?
Видiлення iнформацiйних об'єктiв - процес iтеративний. Вiн здiйснюється на основi аналiзу iнформацiйних потокiв та iнтерв'ювання споживачiв.
Характеристики iнформацiйних об'єктiв визначаються тими ж методами. Завдання необхiдних властивостей для кожного об'єкта це фактично перелік властивостей необхідних для планованого класу задач,і, відповідно, - визначенного кола користувачів.
Введемо ряд позначень, якi будуть використовуватися у ходi подальшого викладення матерiалу.
R - є вiдношення над множинами D1, D2, ... ,Ds, якщо воно є множиною упорядкованих n-кортежiв вигляду :
{d1n, d2n, d3n, … , dsn } .
D1,D2, ..., Ds - називаються доменами вiдношення R.
Вiдношення може бути подане у виглядi файлу або таблицi, стовпцями яких є елементи доменiв, а рядками - кортежi.
Кожен кортеж вiдображає один екземпляр iнформацiйного об'єкту. Iмена стовпцiв (поле запису) - називаються атрибутами, а iндивiдуальнi значення елементiв - значеннями атрибутiв.
Кожен атрибут вiдображає вiдповiдну характеристику iнформацiйного об'єкту.
Пр.19A
| D1 | D2 | D3 | … | … | |
| R1 | { d11 | d21 | d31 | … | ds1 } |
| R2 | { d12 | d22 | d32 | … | ds2 } |
| R3 | { d13 | d23 | d33 | … | ds3} |
| … | … | … | … | … | … |
| … | … | … | … | … | … |
| Rn | { d1n | d2n | d3n | … | dsn } |
Число стовпцiв у вiдношеннi називається ступенем вiдношення S, а число кортежiв - потужнiстю вiдношення n. У процесi експлуатацiї бази даних ступiнь відношення змiнюється значно рiдше, ніж його потужнiсть.
Атрибут, або набір атрибутів, який можна використати для однозначності iдентифiкацiї конкретного кортежу, називається первинним ключем (у випадку набору атрибутiв - складений ключ).
Можливi випадки, коли вiдношення може вмiщувати декiлька унiкальних ключiв. Тодi один з них вибирається в якостi первинного, а iншi отримують назву можливих ключiв.
Атрибути, що представляють копiї ключiв iнших вiдношень, називаються зовнішніми ключами.
Атрибут, або набiр атрибутів, що використовуються для бiльш швидкого пошуку називається другорядним iндексом.
Універсальним називається вiдношення, що вмiщує в себе всi атрибути, якi будуть використовуватися в базi даних. Для невеликих баз даних унiверсальне вiдношення може служити вiдправною точкою при їх проектуваннi.
Розглянемо порядок роботи унiверсального відношення при створеннi бази даних для читального залу.
Враховуючи аналіз предметної області, в універсальне відношення потрібно включити атрибути, що описують такі інформаційні об'єкти:
КНИГА, ТВІР, КОРИСТУВАЧ, РОЗДІЛ.
Складемо перелік найбільш суттєвих характеристик кожного інформаційного об'єкта.
Пр.19
КНИГА (шифр книги, рік видання; видавництво, що надрукувало книгу; кількість сторінок, що включає книга ).
ТВІР (назва твору, що входить до складу книги; автор твору; дата створення).
КОРИСТУВАЧ (код користувача, що служить для його швидкої ідентифікації; прізвище, ім'я та по батькові користувача; домашня адреса; номер телефону, домашнього або службового; паспортні дані; освіта; професія).
РОЗДІЛ (код предметної області, назва предметної області).
Пр.19Б
КНИГА
| Шифр | Рік видання | Вид-во | Стор. | … | … |
ТВІР
| Назва | Автор | Дата | … | … |
КОРИСТУВАЧ
| Код кн. | ПІБ | Адр. | Тел.№ | Паспорт | Освіт. | Проф. | … | … |
РОЗДІЛ
| Код п.о. | Назва п.о. | … | … |
Перерахунок (перелік) вибраних для універсального відношення атрибутів приведено в таблиці 2.1.
Пр.20
Таблиця 2.1 - Початковий перелік атрибутів для формування
Універсального відношення бази даних читального залу.
| Шифр книги | Cod_book | Кожна книга має унікальний шифр. |
| Код розділу | Cod_rozdil | Кожен предметний розділ має унікальний шифр |
| Назва розділу | Name_rozdil | Назва предметного розділу |
| Назва твору | Name | Кожен твір має назву |
| Автор | Author | Письменник, що написав твір. |
| Дата створення | Data_write | Дата, коли письменник закінчив писати твір. |
| Дата видання | Year_publish | Дата, коли книгу надрукували. |
| Видавництво | Publisher | Видавництво, що надрукувало книгу. |
| Кількість сторінок | Page | Кількість сторінок, що займає книга. |
| Код користувача | Cod_client | Код користувача книги. |
| Користувач | FIO | Прізвище, ім'я та по батькові. |
| Адреса | Address | Адреса користувача. |
| Телефон | Telephone | Номер телефону користувача. |
| <Паспорт | №_pasp< | Паспортні дані користувача. |
| Освіта | Culture | Освіта, яку має користувач. |
| Професія | Profession | Професія користувача. |
Оскільки всі перераховані в таблиці атрибути є незалежними, тобто значення одних з них не можуть бути обчислені за значеннями інших, то всі вони можуть бути включені в склад універсального відношення, яке при цьому приймає вигляд:
Пр.21
R (Cod_book, Name, Author, Cod_rozdil, Name_rozdil, Data_write, Publisher, Year_publish, Page, Cod_client, FIO, Address, Telephone, №_pasp, Culture, Profession).
Контрольні запитання.
1. Визначте принципи вибору інформаційних об'єктів.
2. Дайте визначення понять: домен, елемент домену, кортеж відношення.
3. У чому полягає різниця між ступенем відношення та його потужністю?
4. Що таке універсальне відношення?
5. Наведіть приклад роботи універсального відношення при створенні бази
даних.
8. НОРМАЛІЗАЦІЯ СХЕМ БАЗ ДАНИХ
Нормалізація - це розбивка таблиці на дві або більше, які характеризуються кращими властивостями при доповненні, зміні і вилученні даних. Кінцева мета нормалізації зводиться до отримання такого проекту бази даних, у котрому кожний факт з'являється лише в одному місці, тобто виключена надлишковість інформації. Це робиться не стільки з метою економії пам'яті, скільки для виключення можливої суперечливості збережених даних.
Кожна таблиця в реляційній БД задовольняє умову, у відповідності з якою у позиції на перетині кожного рядка і стовпця таблиці завжди знаходиться єдине атомарне значення і ніколи не може бути множини таких значень. Будь-яка таблиця, що задовольняє цю умову, називається нормалізованою.
Кожній нормальній формі відповідає деякий визначений набір обмежень. Відношення знаходиться в деякій нормальній формі, якщо задовольняється властивий їй набір обмежень.
Кожна нормальна форма є більш обмеженою і більш бажаною, ніж попередня. Це пов'язано з тим, що в (N + 1)-ій нормальній формі вилучаються деякі небажані властивості, які характерні N-ій нормальній формі. Теорія нормалізації грунтується на наявності тієї або іншої залежності між полями таблиці.
Основні властивості нормальних форм:
1. кожна наступна нормальна форма в деякому змісті краще попередньої;
2. при переході до наступної нормальної форми властивості попередніх нормальних властивостей зберігаються.
Найбільш важливі нормальні форми відношень грунтуються на фундаментальному понятті функціональної залежності з теорії реляційних баз даних .
Визначення 1. Функціональна залежність.
У відношенні R атрибут Y функціонально залежить від атрибута X (X і Y можуть бути складовими) у тому і тільки в тому випадку, якщо кожному значенню X відповідає в точності одне значення Y: X -> Y.
Визначення 2. Повна функціональна залежність.
Функціональна залежність X -> Y називається повною, якщо атрибут Y не залежить функціонально від будь-якої підмножини X.
Визначення 3. Транзитивна функціональна залежність.
Функціональна залежність називається транзитивною, якщо з функціональних залежностей X -> Y та Y -> Z випливає, що X -> Z.
Наприклад, Вінниця входить до Поділля, а Поділля - до України. Для даного прикладу має місце транзитивна залежність ВІННИЦЯ -> УКРАЇНА.
Визначення 4. Неключовий атрибут.
Неключовим атрибутом називається будь-який атрибут відношення, що не входить до складу первинного ключа.
Визначення 5. Взаємно незалежні атрибути.
Два або більше атрибути взаємно незалежні, якщо жодний із цих атрибутів не є функціонально залежним від інших.
Відношення R задано в першій нормальній формі, якщо воно задано у вигляді множини своїх кортежів, які не повторюються.
Для того, щоб представити відношення в першій нормальній формі необхідно над його кортежами виконати операцію проекції для видалення рядків, які повторюються.
Відношення R задано в другій нормальній формі, якщо воно, по-перше, є відношенням у першій нормальній формі і, по-друге, кожний його атрибут, який не є основним атрибутом, функціонально повно залежить від будь-якого можливого ключа цього відношення.
Нехай задано відношення
ФАКУЛЬТЕТ (НАЙМЕНУВАННЯ, ПІБ ДЕКАНА, ТЕЛЕФОН).
Відношення ФАКУЛЬТЕТ задано в другій нормальній формі, тому що: { ? }
у відношенні ФАКУЛЬТЕТ атрибут ТЕЛЕФОН, який не є основним, повністю залежить від будь-якого можливого ключа: НАЙМЕНУВАННЯ, ПІБ ДЕКАНА.
У загальному випадку, якщо всі можливі ключі відношення містять по одному атрибуту, то це відношення задане в другій нормальній формі, тому що в цьому випадку всі атрибути, які не є основними, функціонально повно залежать від можливих ключів. Однак це твердження не завжди справедливе, якщо ключ відношення R є складовим.
Розглянемо відношення:
СТУДЕНТ - КУРС_ПРОЕКТ (НОМЕР_ЗАЛІКОВОЇ_КНИЖКИ, КОД_ПРЕДМЕТУ, ПРІЗВИЩЕ_СТУДЕНТА, НОМЕР_ГРУПИ, ВИКЛАДАЧ, ПРОЦЕНТ_ВИКОНАННЯ).
Припустимо, що в одній групі можуть навчаються однофамільці. Тоді для цього відношення можливий тільки один ключ: НОМЕР_ЗАЛІКОВОЇ_КНИЖКИ, КОД_ПРЕДМЕТУ. Виходячи з прийнятого припущення, атрибут ПРІЗВИЩЕ_СТУДЕНТА не входить у ключ. Тоді атрибут НОМЕР_ЗАЛІКОВОЇ_КНИЖКИ не визначається значенням атрибута ПРІЗВИЩЕ_СТУДЕНТА, тобто атрибути ПРІЗВИЩЕ_СТУДЕНТА і НОМЕР_ГРУПИ не є основними, але функціонально залежать від основного атрибута НОМЕР_ЗАЛІКОВОЇ_КНИЖКИ, що входить у складовий ключ. Функціональні залежності між атрибутами цього відношення показані на рис.4.7.

Рисунок 4.7 - Функціональна залежність
Розщепивши вихідне відношення на два нових у другій нормальній формі, можна усунути надлишковість (рис. 4.8). При виконанні цієї операції розбивки на два відношення враховано те, що атрибути, які функціонально залежать від одного основного атрибута разом із ним утворять одне відношення з єдиним ключем НОМЕР_ЗАЛІКОВОЇ_КНИЖКИ, а інші атрибути, які функціонально повно залежать від складового ключа, залишено у вихідній схемі.

Розглянемо приклад схеми відношення:
СПІВРОБІТНИКИ - ВІДДІЛИ - ПРОЕКТИ
(СПІВРОБ_НОМЕР, СПІВРОБ_ЗАРП, ВІДДІЛ_НОМЕР, ПРО_НОМЕР, СПІВРОБ_ЗАВДАННЯ)
У відношенні використані скорочення : СПІВРОБ - співробітник, ЗАРП - зарплата, ПРО - проект.
Первинний ключ:
СПІВРОБ_НОМЕР, ПРО_НОМЕР.
Функціональні залежності:
СПІВРОБ_НОМЕР -> СПІВРОБ_ЗАРП
СПІВРОБ_НОМЕР -> ВІДДІЛ_НОМЕР
ВІДДІЛ_НОМЕР -> СПІВРОБ_ЗАРП
СПІВРОБ_НОМЕР, ПРО_НОМЕР -> СПІВРОБ_ЗАВДАННЯ.
Хоча первинним ключем є складовий атрибут СПІВРОБ_НОМЕР, ПРО_НОМЕР, атрибути СПІВРОБ_ЗАРП і ВІДДІЛ_НОМЕР функціонально залежать від частини первинного ключа, тобто атрибута СПІВРОБ_НОМЕР.
В результаті, неможливо вставити у відношення СПІВРОБІТНИКИ - ВІДДІЛИ - ПРОЕКТИ кортеж, що описує співробітника, який ще не виконує ніякого проекту (первинний ключ не може містити невизначене значення). При видаленні кортежу не тільки руйнується зв'язок даного співробітника з даним проектом, але втрачається інформація про те, в якому відділі він працює. При переводі співробітника в інший відділ необхідно модифікувати всі кортежі, які описують цього співробітника, або одержимо неузгоджений результат. Такі неприємні явища називаються аномаліями схеми відношення. Вони усуваються шляхом нормалізації.
Виконаємо декомпозицію відношення СПІВРОБІТНИКИ - ВІДДІЛИ в два відношення СПІВРОБІТНИКИ - ВІДДІЛИ і СПІВРОБІТНИКИ - ПРОЕКТИ:
СПІВРОБІТНИКИ - ВІДДІЛИ (СПІВРОБ_НОМЕР, СПІВРОБ_ЗАРП, ВІДДІЛ_НОМЕР)
Первинний ключ:
СПІВРОБ_НОМЕР
Функціональні залежності:
СПІВРОБ_НОМЕР -> СПІВРОБ_ЗАРП
СПІВРОБ_НОМЕР -> ВІДДІЛ_НОМЕР
ВІДДІЛ_НОМЕР -> СПІВРОБ_ЗАРП
СПІВРОБІТНИКИ - ПРОЕКТИ (СПІВРОБ_НОМЕР, ПРО_НОМЕР, СПІВРОБ_ЗАВДАННЯ)
Первинний ключ:
СПІВРОБ_НОМЕР, ПРО_НОМЕР
Функціональна залежність: СПІВРОБ_НОМЕР, ПРО_НОМЕР -> СПІВРОБ_ЗАВДАННЯ
Кожне з цих двох відношень знаходиться в 2НФ і в них усунуті відзначені вище аномалії.
Відношення R знаходиться в третій нормальній формі (3НФ) у тому і тільки в тому випадку, якщо знаходиться в 2НФ і кожний неключовий атрибут нетранзитивно залежить від первинного ключа.
Наприклад, відношення:
ГУРТОЖИТОК (ПІБ_СТУДЕНТА, НОМЕР_ГРУПИ, НОМЕР_КІМНАТИ, СТАРОСТА_КІМНАТИ)
знаходиться у другій нормальній формі, але не в третій, тому що атрибут СТАРОСТА_КІМНАТИ залежить від атрибута НОМЕР_КІМНАТИ, який у свою чергу залежить від атрибута ПІБ_СТУДЕНТА і, отже, СТАРОСТА_КІМНАТИ транзитивно залежить від ПІБ_СТУДЕНТА. Це відношення можна привести до необхідної форми шляхом його розщеплення на два:
СТУДЕНТ-ГУРТОЖИТОК (ПІБ_СТУДЕНТА, НОМЕР_ГРУПИ, НОМЕР_КІМНАТИ)
та
КІМНАТА -ГУРТОЖИТОК (НОМЕР_КІМНАТИ, СТАРОСТА_КІМНАТИ)
Залежності між атрибутами вихідного й отриманих відношень подані на рис.4.9, звідки видно, що отримані відношення більш доцільніші від вихідного.
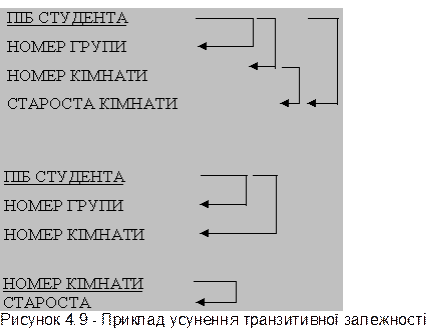
Так, інформація про старосту кімнати може знадобитися незалежно від інформації про студентів, що проживають у цій кімнаті.
Нехай маємо відношення
(ФІРМА, СКЛАД, ОБ'ЄМ )
Для даного відношення характерні такі аномалії :
1. Якщо в даний момент відсутня фірма, яка отримує товар зі складу, то в базу даних неможливо ввести інформацію про об'єм складу.
2. Якщо фірма перестає отримувати товар зі складу, то данні про склад та його об'єм не можна зберігати в базі даних.
3. Якщо об'єм складу змінився, то необхідно переглянути всі рядки відношення і змінити кортежі для форм, пов'язаних зі складом.
Причиною аномалій для даного відношення є наявність транзитивного зв'язку між атрибутами.
Для усунення аномалій розіб'ємо вихідне відношення на два:
ЗБЕРІГАННЯ (ФІРМА, СКЛАД) та
ОБ'ЄМ (СКЛАД, ОБ'ЄМ).
На практиці в більшості випадків три нормальні форми схем відношень є достатніми і приведенням до третьої нормальної форми процес проектування реляційної бази даних, як правило, закінчується. Однак іноді корисно продовжити процес нормалізації.
Розглянемо наступний приклад схеми відношення:
СПІВРОБІТНИКИ - ПРОЕКТИ (СПІВРОБІТНИКА_НОМЕР, СПІВРОБІТНИКА_ПРИЗВІЩЕ, ПРОЕКТУ_НОМЕР, СПІВРОБІТНИКА_ЗАВДАННЯ)
Можливі ключі (важливо, що на цій стадії нормалізації до уваги приймається існування можливих ключів):
СПІВРОБІТНИКА_НОМЕР, ПРОЕКТУ_НОМЕР
СПІВРОБІТНИКА_ПРИЗВІЩЕ, ПРОЕКТУ_НОМЕР.
Функціональні залежності:
СПІВРОБІТНИКА_НОМЕР -> СПІВРОБІТНИКА_ПРИЗВІЩЕ;
СПІВРОБІТНИКА_НОМЕР -> ПРОЕКТУ_НОМЕР;
СПІВРОБІТНИКА_ПРИЗВІЩЕ -> СПІВРОБІТНИКА_НОМЕР;
СПІВРОБІТНИКА_ПРИЗВІЩЕ -> ПРОЕКТУ_НОМЕР;
СПІВРОБІТНИКА_НОМЕР, ПРОЕКТУ_НОМЕР -> СПІВРОБІТНИКА_ЗАВДАННЯ;
СПІВРОБІТНИКА_ПРИЗВІЩЕ, ПРОЕКТУ_НОМЕР -> СПІВРОБІТНИКА_ЗАВДАННЯ.
У цьому прикладі припускаємо, що особа співробітника повністю визначається як його номером, так і прізвищем.
Незалежно від того, який із можливих ключів обраний у якості первинного ключа, ця схема знаходиться в 3НФ. Однак той факт, що є функціональні залежності атрибутів відношення від атрибута, що є частиною первинного ключа, приводить до аномалій. Наприклад, для того, щоб змінити ПРИЗВІЩЕ співробітника з даним номером погодженим способом, буде потрібно модифікувати всі кортежі, які включають його номер. Введемо визначення.
Детермінантомназивається будь-який атрибут, від котрого функціонально повно залежить деякий інший атрибут.
Нормальна форма Бойса-Кодда. Відношення R знаходиться в нормальній формі Бойса-Кодда (БКНФ) у тому і тільки в тому випадку, якщо кожний детермінант є можливим ключем.
Зауважимо, що якщо у відношенні є тільки один можливий ключ (який є первинним ключем), то це визначення стає еквівалентним визначенню третьої нормальної форми.
Очевидно, що ця вимога не виконана для відношення СПІВРОБІТНИКИ - ПРОЕКТИ. Можна виконати його декомпозицію до відношень СПІВРОБІТНИКИ і СПІВРОБІТНИКИ - ПРОЕКТИ:
СПІВРОБІТНИКИ (СПІВРОБІТНИКА_НОМЕР, СПІВРОБІТНИКА_ПРИЗВІЩЕ).
Можливі ключі:
СПІВРОБІТНИКА_НОМЕР;
СПІВРОБІТНИКА_ПРИЗВІЩЕ.
Функціональні залежності:
СПІВРОБІТНИКА_НОМЕР -> СПІВРОБІТНИКА_ПРИЗВІЩЕ;
СПІВРОБІТНИКА_ПРИЗВІЩЕ -> СПІВРОБІТНИКА_НОМЕР.
СПІВРОБІТНИКИ-ПРОЕКТИ (СПІВРОБІТНИКА_НОМЕР, ПРОЕКТУ_НОМЕР, СПІВРОБІТНИКА_ЗАВДАННЯ).
Можливий ключ:
СПІВРОБІТНИКА_НОМЕР, ПРОЕКТУ_НОМЕР.
Функціональні залежності:
СПІВРОБІТНИКА_НОМЕР, ПРОЕКТУ_НОМЕР -> СПІВРОБІТНИКА_ЗАВДАННЯ.
Можлива альтернативна декомпозиція, якщо вибрати за основу СПІВРОБІТНИКА_ПРИЗВІЩЕ. В обох випадках отримані відношення СПІВРОБІТНИКИ і СПІВРОБІТНИКИ - ПРОЕКТИ знаходяться в БКНФ, і їм не властиві відзначені аномалії.
Розглянемо відношення
R (МІСТО, АДРЕСА, ІНДЕКС).
Атрибут ІНДЕКС визначає індекс відділення зв'язку, яке обслуговує адресатів деякої вулиці міста, АДРЕСА - назву вулиці і номеру будинку. При цьому будемо припускати, що кортеж (С, S, Z) належить деякому відношенню зі схемою відношення R, якщо тільки в місті С є будинок за адресою S і Z є відповідним поштовим індексом. У цьому випадку мають місце такі функціональні залежності:
МІСТО, АДРЕСА -> ІНДЕКС;
ІНДЕКС -> МІСТО.
Іншими словами, повна адреса (назва міста і адреса в місті) визначає поштовий індекс, а поштовий індекс, у свою чергу, визначає назву міста, але не визначає адресу, тому що одне відділення зв'язку обслуговує багато будинків на різних вулицях. Таким чином, в якості основного ключа можна вибрати одне з двох множин атрибутів:
МІСТО, АДРЕСА і AДРЕСА, ІНДЕКС .
Схема відношення R (МІСТО, АДРЕСА, ІНДЕКС) не знаходиться в нормальній формі Бойса-Кода, так як має місце залежність ІНДЕКС -> МІСТО. Декомпозицією відношення його можна привести до нормальної форми Бойса-Кода.
Розглянемо приклад схеми відношення:
ПРОЕКТИ ( ПРОЕКТУ_НОМЕР, ПРОЕКТУ_СПІВРОБ, ПРОЕКТУ_ЗАВДАННЯ).
Відношення ПРОЕКТИ містить номера проектів, кожний проект - список співробітників, які можуть виконувати проект, і список завдань, які передбачаються проектом. Співробітники можуть брати участь у декількох проектах, і різні проекти можуть включати однакові завдання.
Кожний кортеж відношення зв'язує деякий проект із співробітником, який бере участь у цьому проекті, і з завданням, яке співробітник виконує в рамках даного проекту (припускаємо, що будь-який співробітник, який бере участь у проекті, виконує всі завдання, передбачені цим проектом). Через сформульовані вище умови єдиним можливим ключем відношення є складовий атрибут
ПРОЕКТ_НОМЕР, ПРОЕКТ_СПІВРОБ, ПРОЕКТ_ЗАВДАННЯ
і немає ніяких інших детермінантів. Отже, відношення ПРОЕКТИ знаходиться в БКНФ. Але при цьому воно має аномалії: якщо, наприклад, деякий співробітник приєднується до даного проекту, необхідно вставити у відношення ПРОЕКТИ стільки кортежів, скільки завдань у ньому передбачено.
У відношенні R (A, B, C) існує багатозначна залежність (multi-valued dependence - MVD) (R.A ->-> R.B) в тому і тільки в тому випадку, якщо множина значень B, що відповідає парі значень A і C, залежить тільки від A і не залежить від С.
У відношенні ПРОЕКТИ існують наступні дві багатозначні залежності:
ПРОЕКТ_НОМЕР ->-> ПРОЕКТ_СПІВРОБ;
ПРОЕКТ_НОМЕР ->-> ПРОЕКТУ_ЗАВДАННЯ.
Неважко показати, що в загальному випадку у відношенні R (A, B, C) існує багатозначна залежність A ->-> B у тому і тільки в тому випадку, коли існує багатозначна залежність A ->-> C.
Відношення R знаходиться в четвертій нормальній формі (4НФ) у тому і тільки в тому випадку, якщо у випадку існування багатозначної залежності A ->-> B всі інші атрибути R функціонально залежать від A.
У нашому прикладі можна виконати декомпозицію відношення ПРОЕКТИ на два відношення ПРОЕКТИ-СПІВРОБІТ і ПРОЕКТИ-ЗАВДАННЯ:
ПРОЕКТИ-СПІВРОБІТ (ПРОЕКТ_НОМЕР, ПРОЕКТ_СПІВРОБІТ);
ПРОЕКТИ-ЗАВДАННЯ (ПРОЕКТ_НОМЕР, ПРОЕКТ_ЗАВДАННЯ).
Обидва ці відношення знаходяться в 4НФ. Розглянемо ще один приклад. Нехай задано відношення– Конец работы –
Используемые теги: технологія, Проектування, адміністрування, баз, даних, сховищ, даних0.088
Если Вам нужно дополнительный материал на эту тему, или Вы не нашли то, что искали, рекомендуем воспользоваться поиском по нашей базе работ: ТЕХНОЛОГІЯ ПРОЕКТУВАННЯ ТА АДМІНІСТРУВАННЯ БАЗ ДАНИХ І СХОВИЩ ДАНИХ
Что будем делать с полученным материалом:
Если этот материал оказался полезным для Вас, Вы можете сохранить его на свою страничку в социальных сетях:
| Твитнуть |
Хотите получать на электронную почту самые свежие новости?

Подпишитесь на Нашу рассылку
Реклама





Информация в виде рефератов, конспектов, лекций, курсовых и дипломных работ имеют своего автора, которому принадлежат права. Поэтому, прежде чем использовать какую либо информацию с этого сайта, убедитесь, что этим Вы не нарушаете чье либо право.
© copyright 1999 - 2024 allRefs.net. Все права защищены. Страница сгенерирована за: 0.192 сек.
Новости и инфо для студентов